A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 10
Issue 5
Volume 10
Issue 5
IEEE/CAA Journal of Automatica Sinica
| Citation: | C. X. Mu, Y. Zhang, G. B. Cai, R. J. Liu, and C. Y. Sun, “A data-based feedback relearning algorithm for uncertain nonlinear systems,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 5, pp. 1288–1303, May 2023. doi: 10.1109/JAS.2023.123186

|
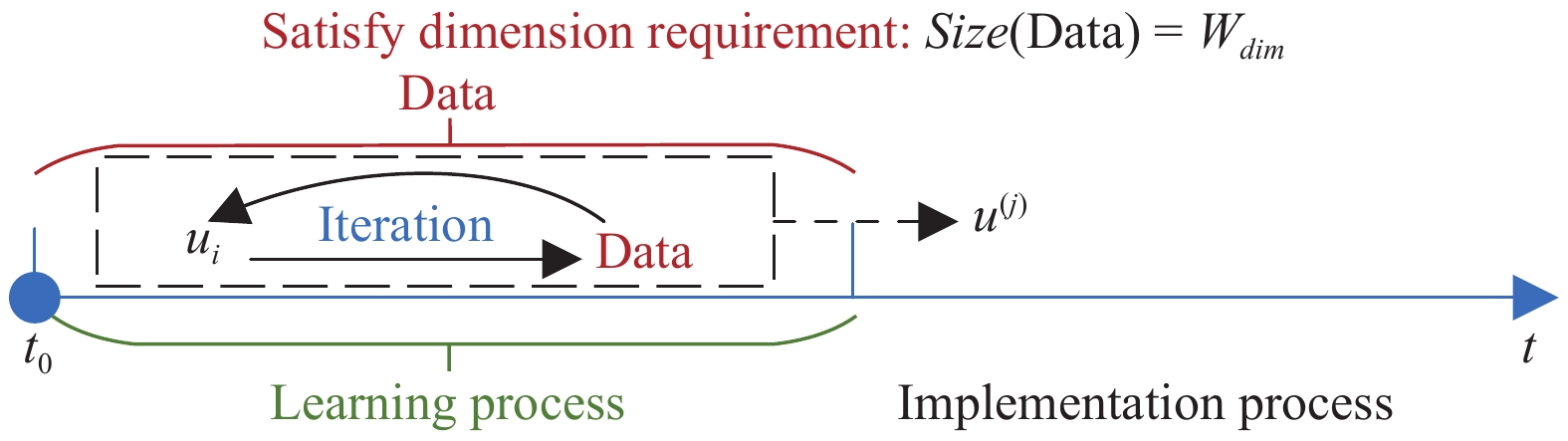
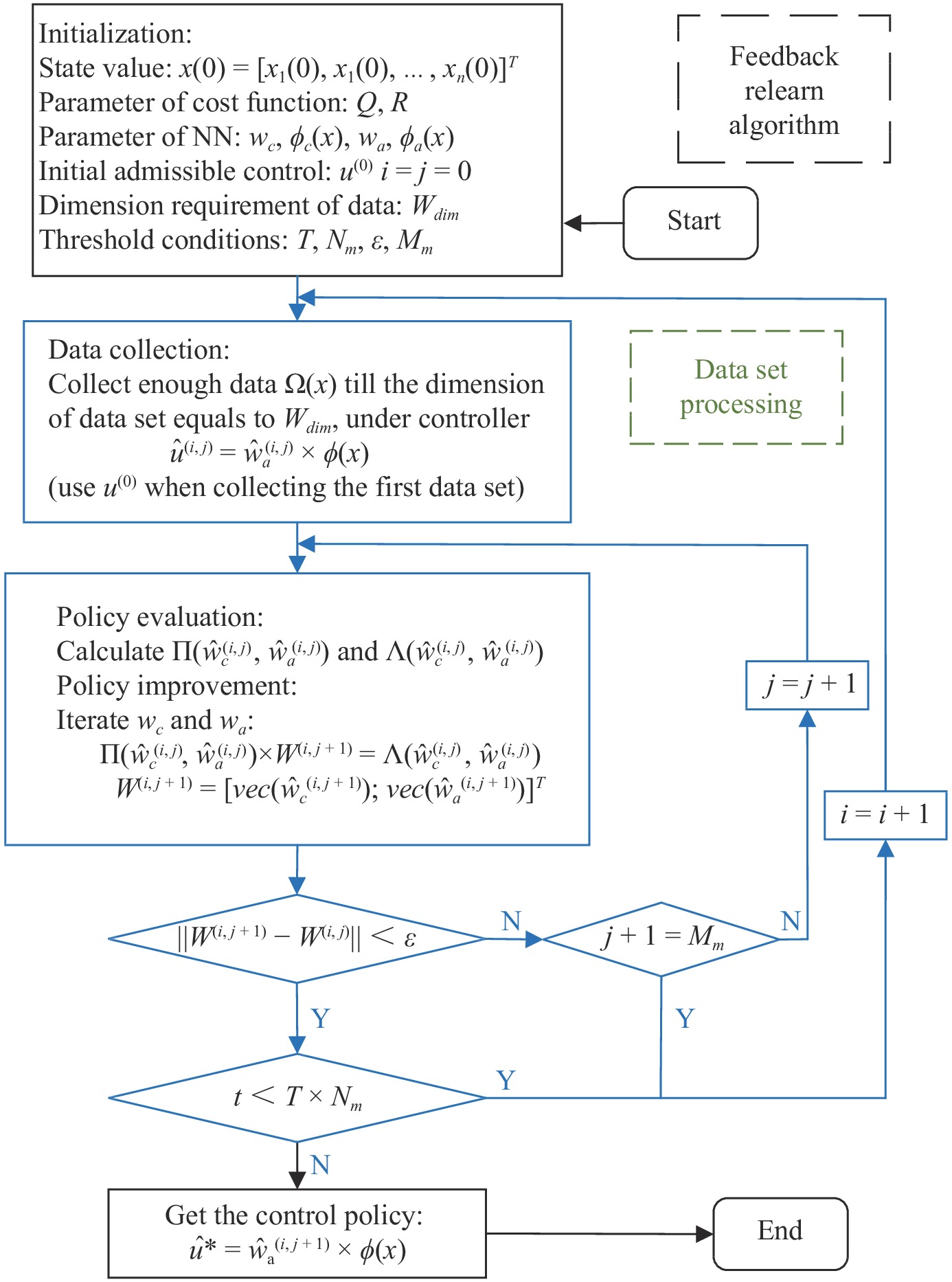
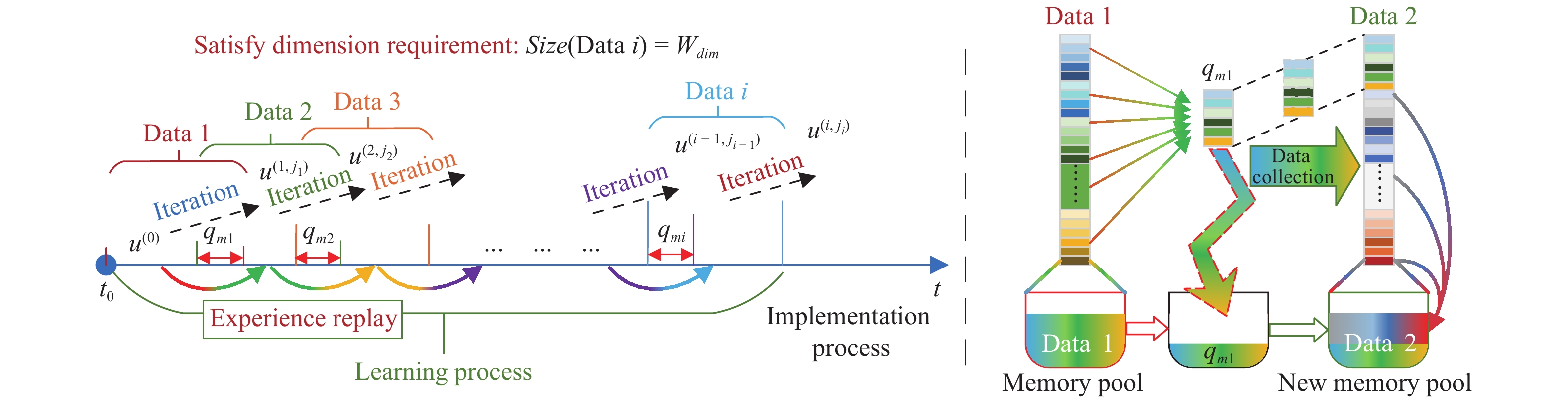
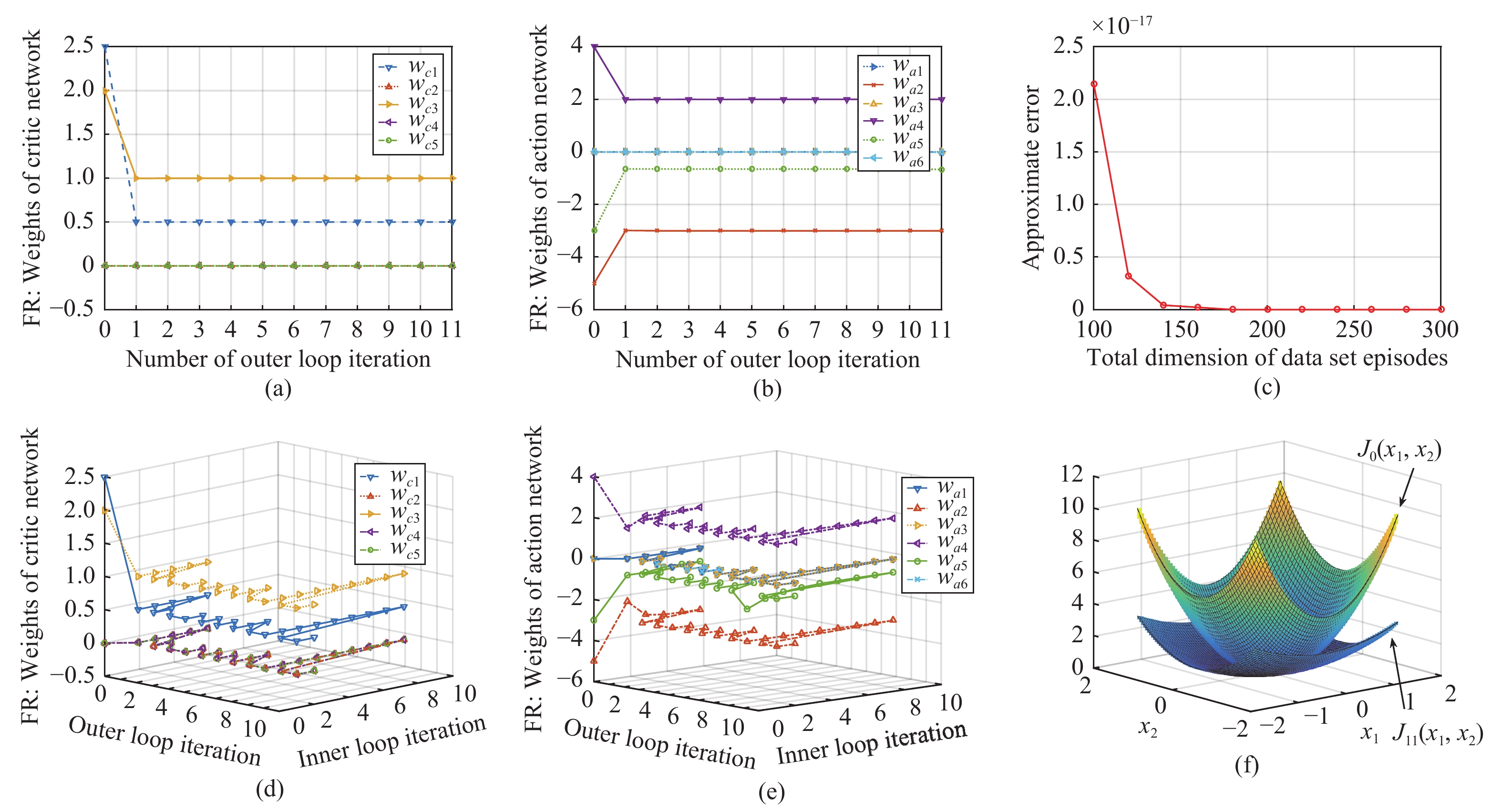
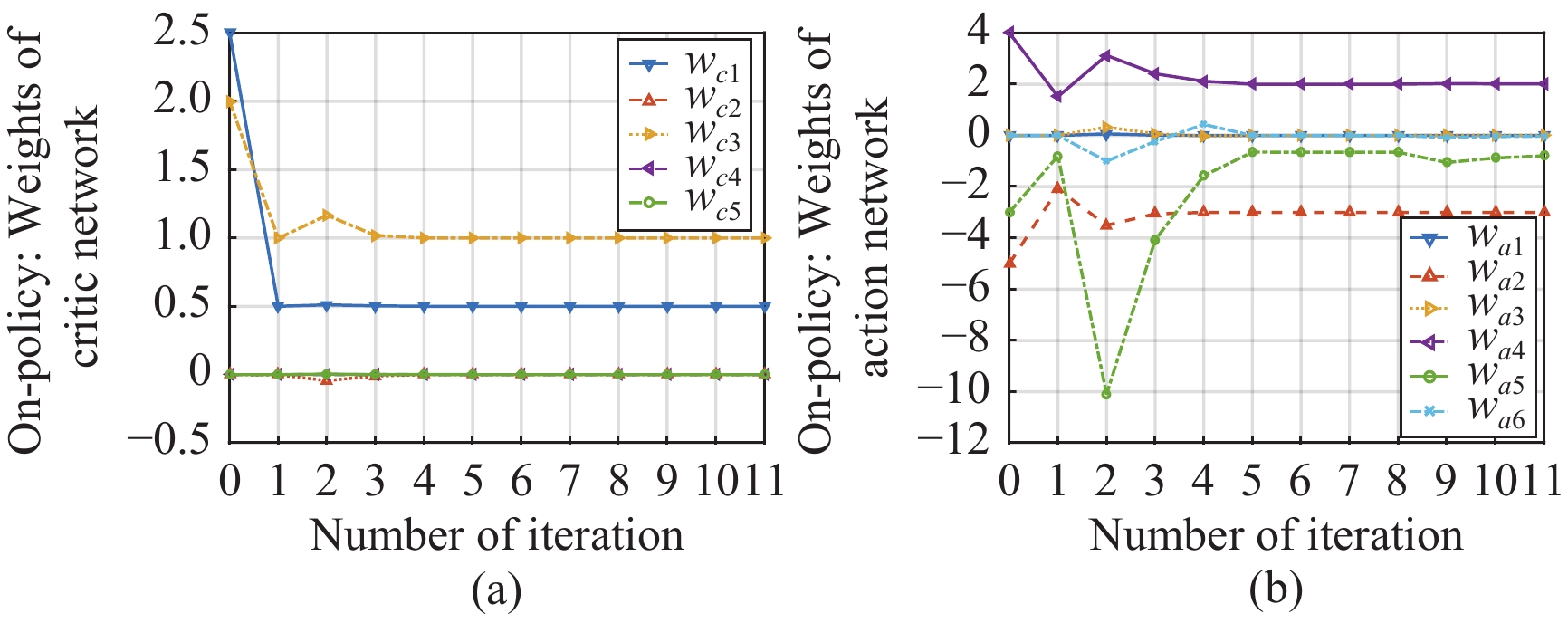
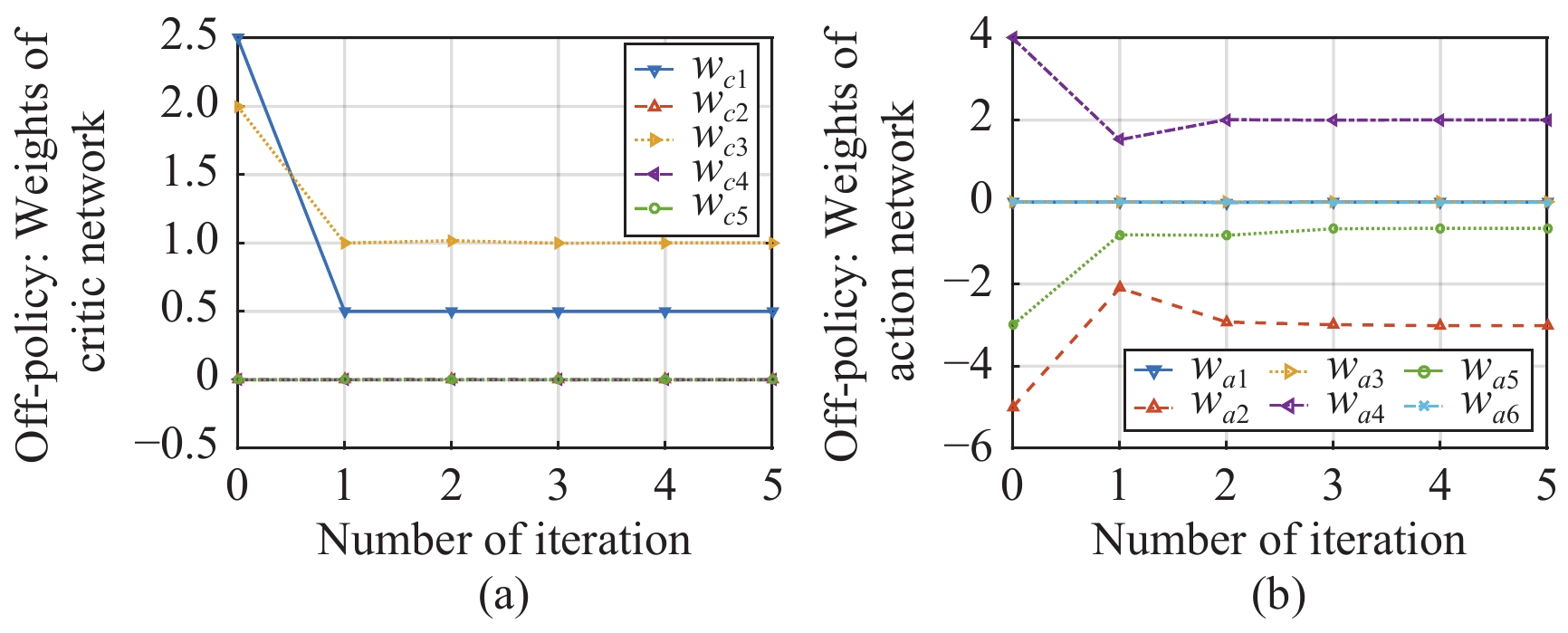
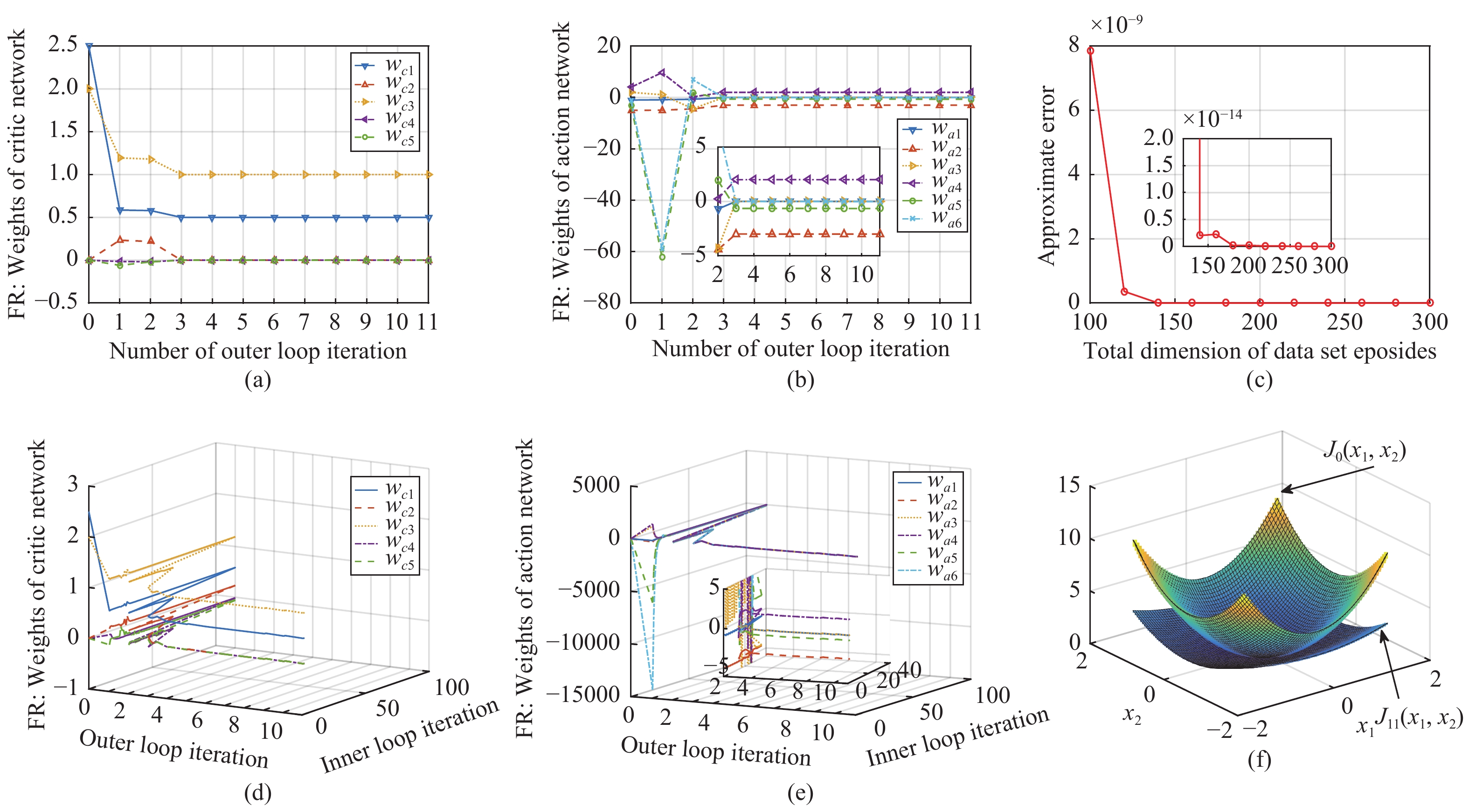
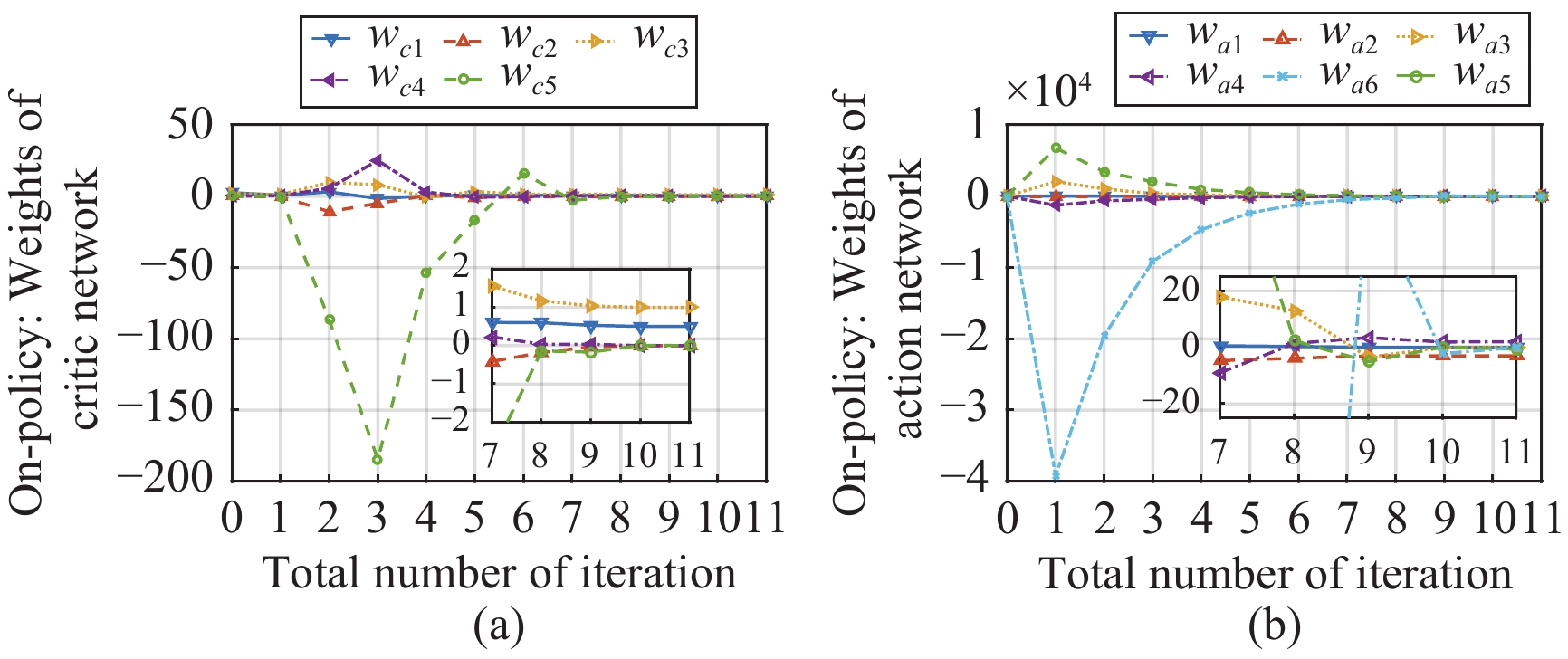
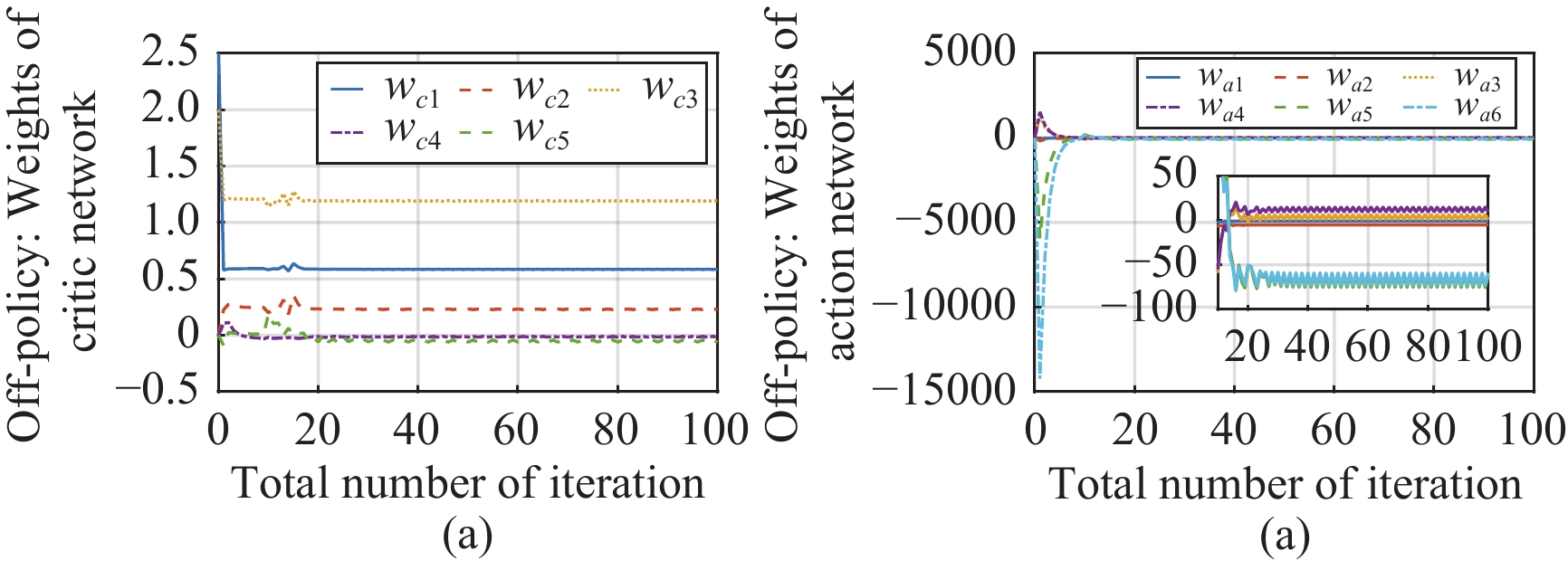
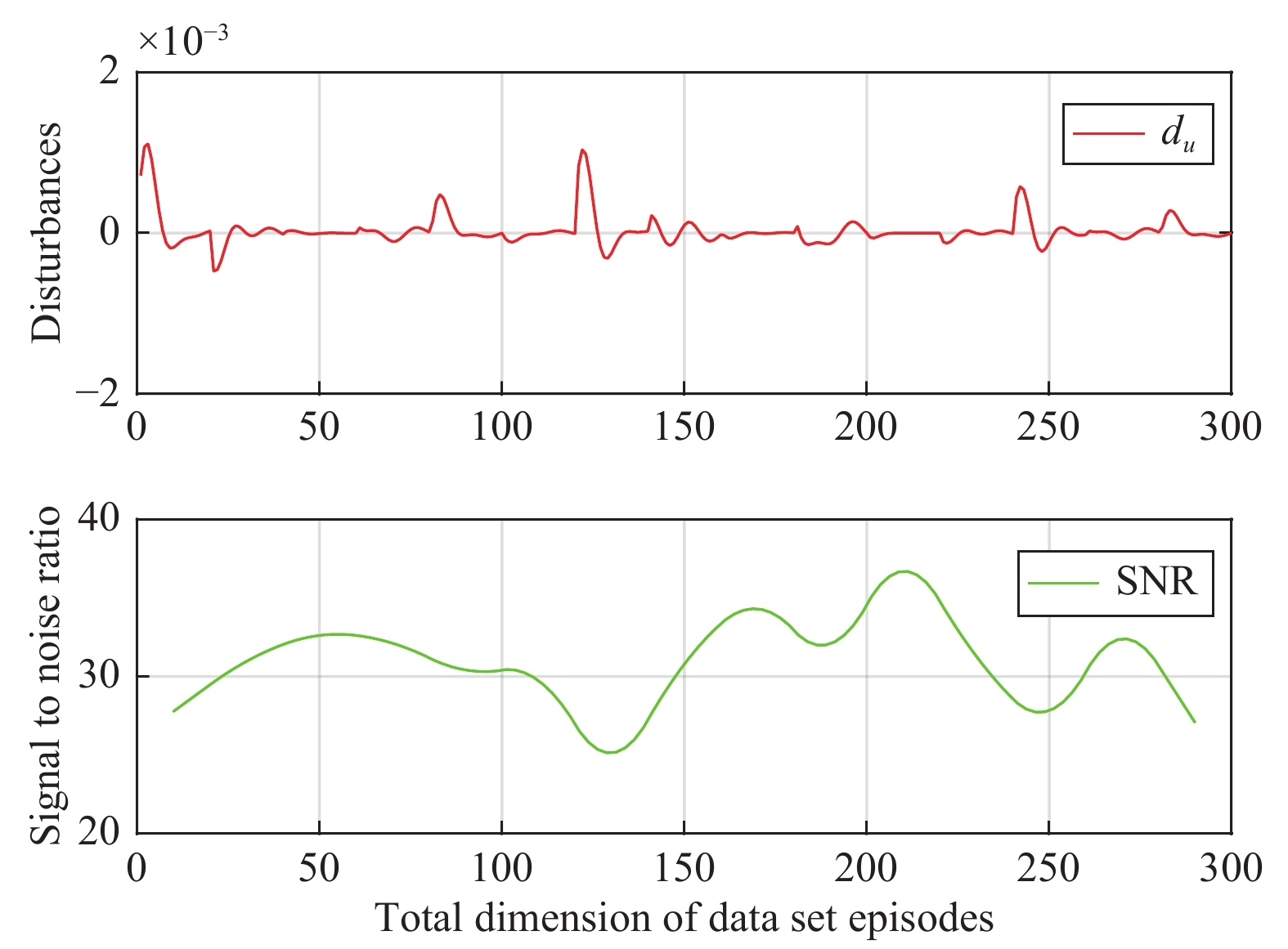
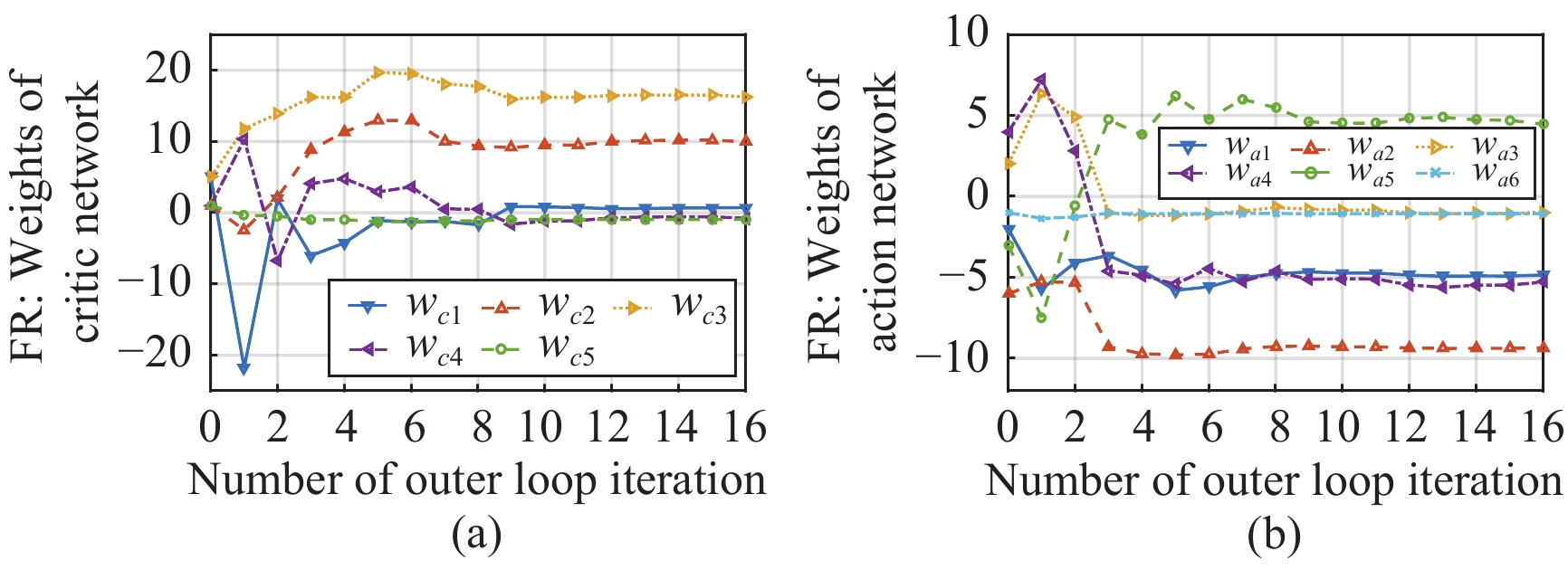
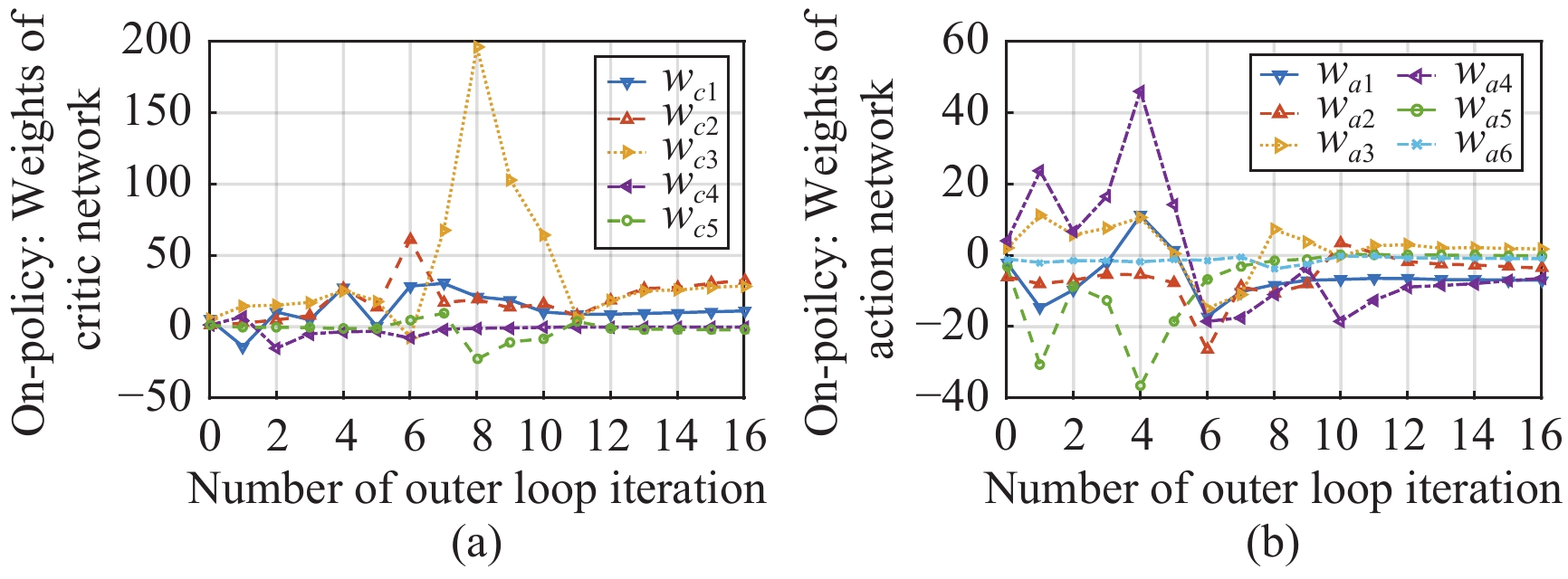
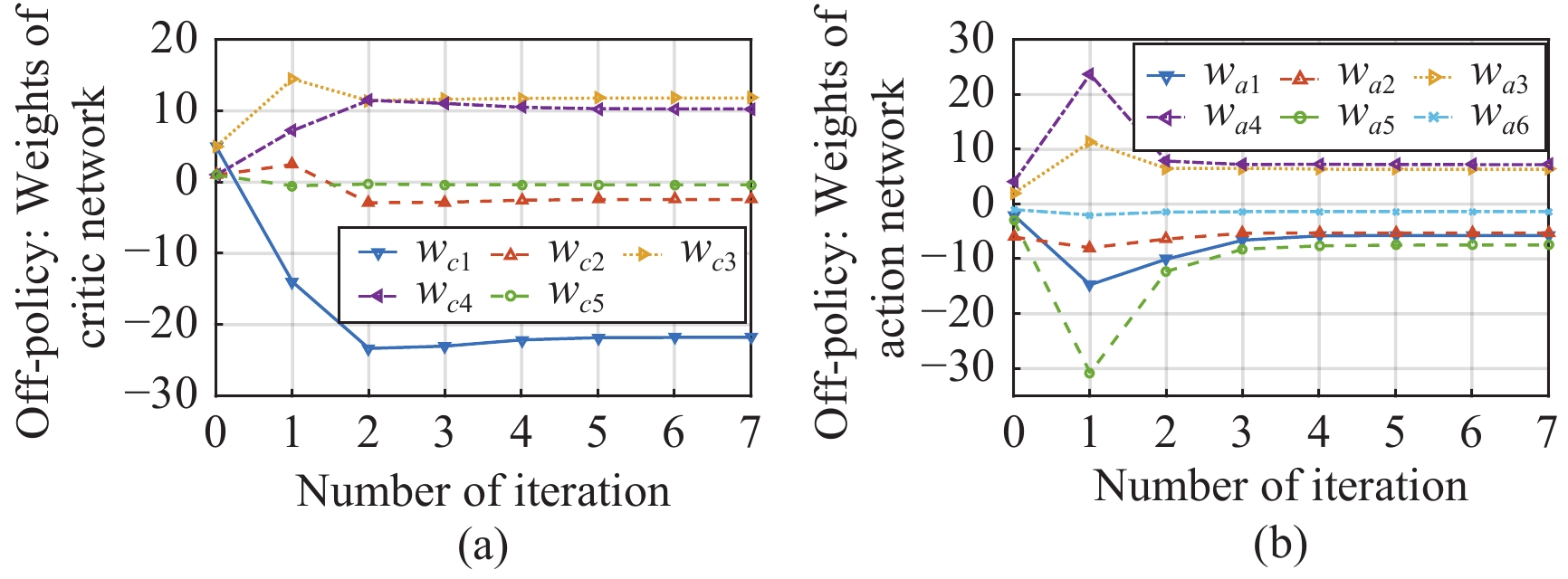
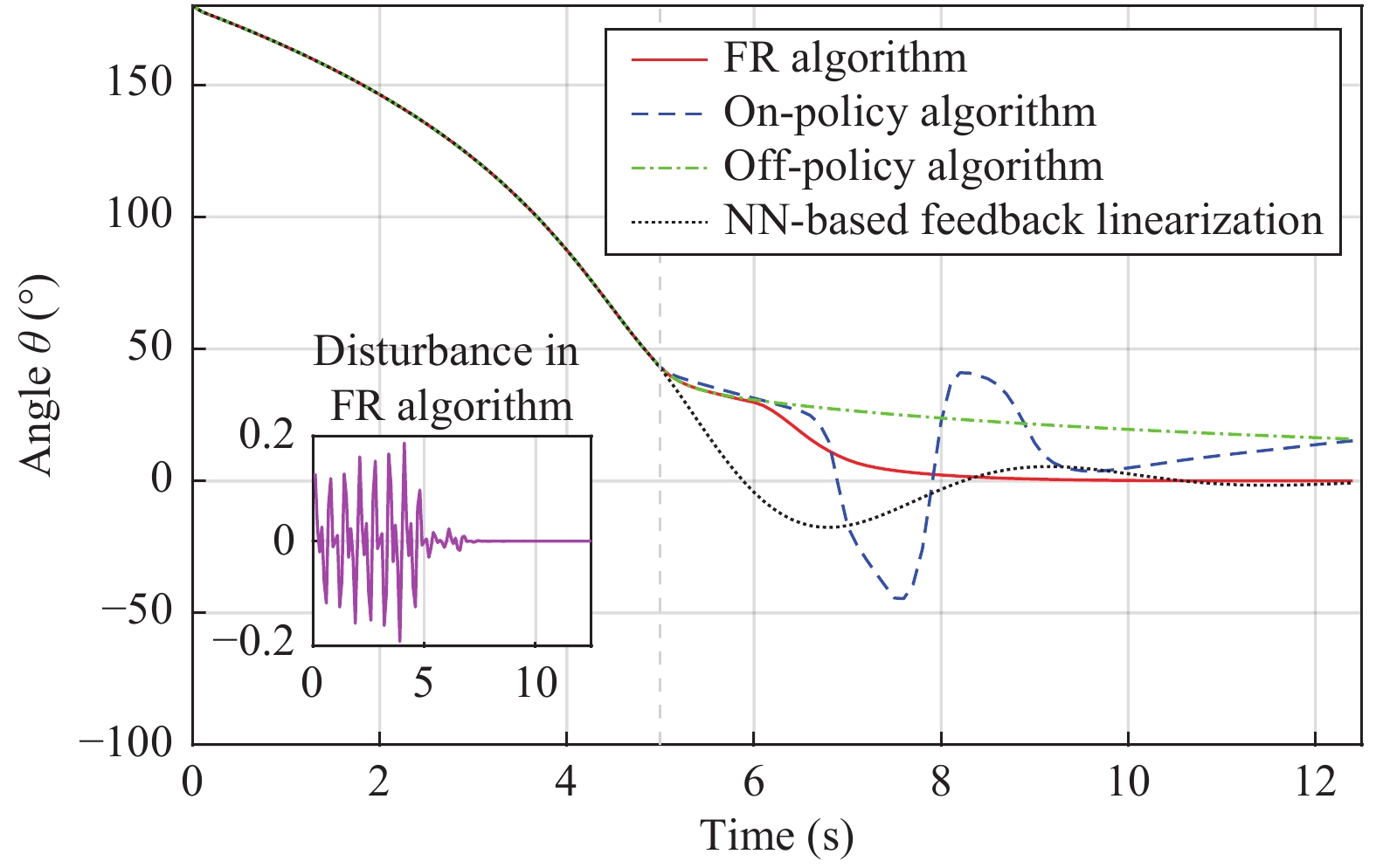
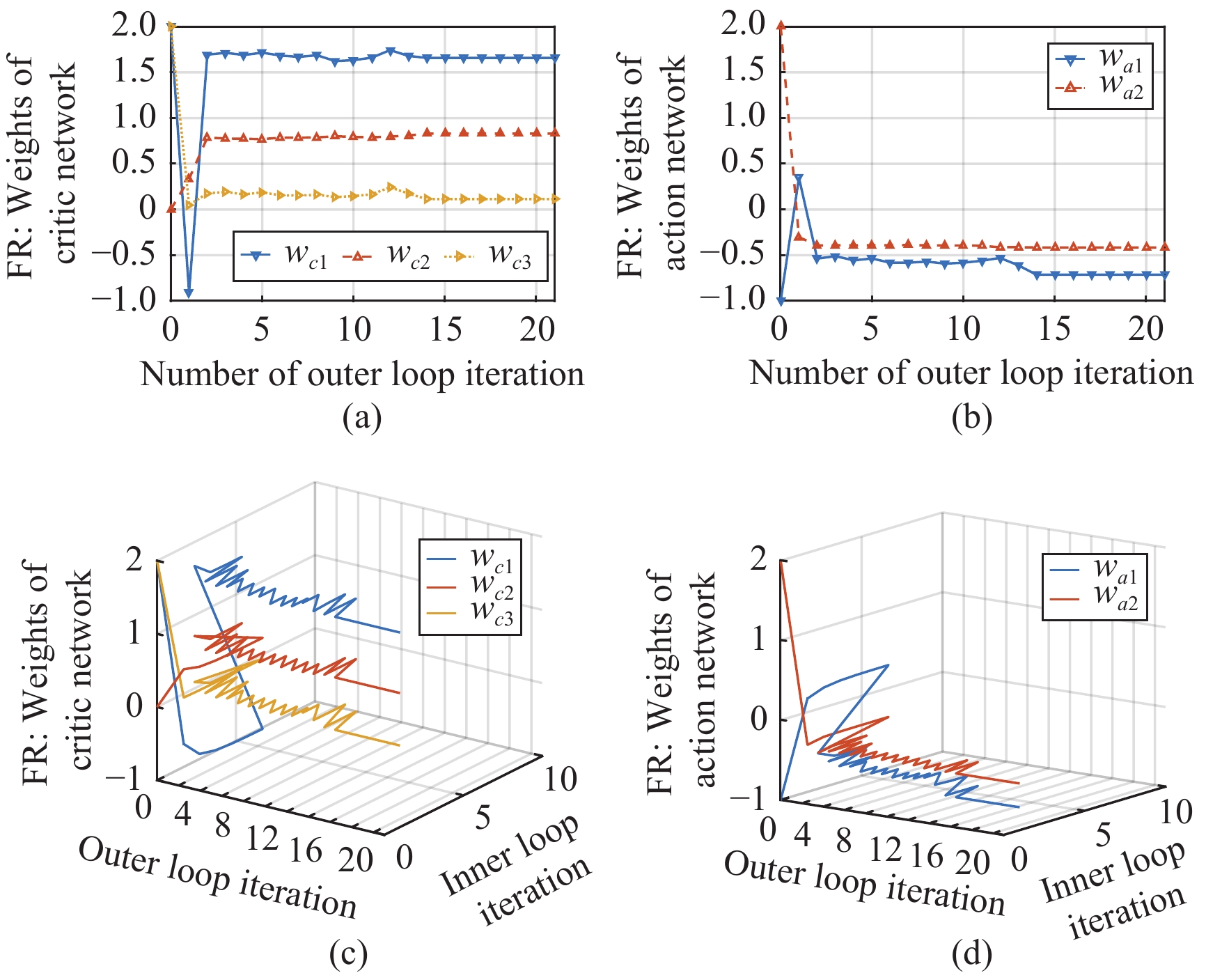
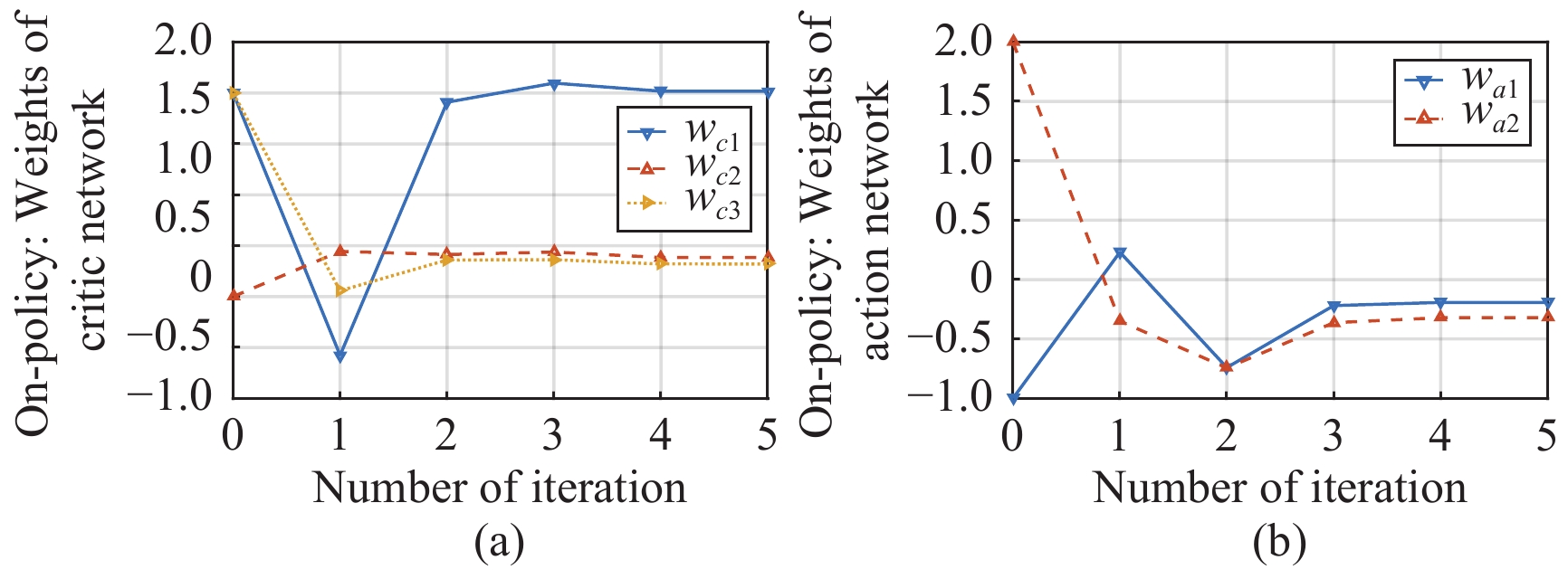
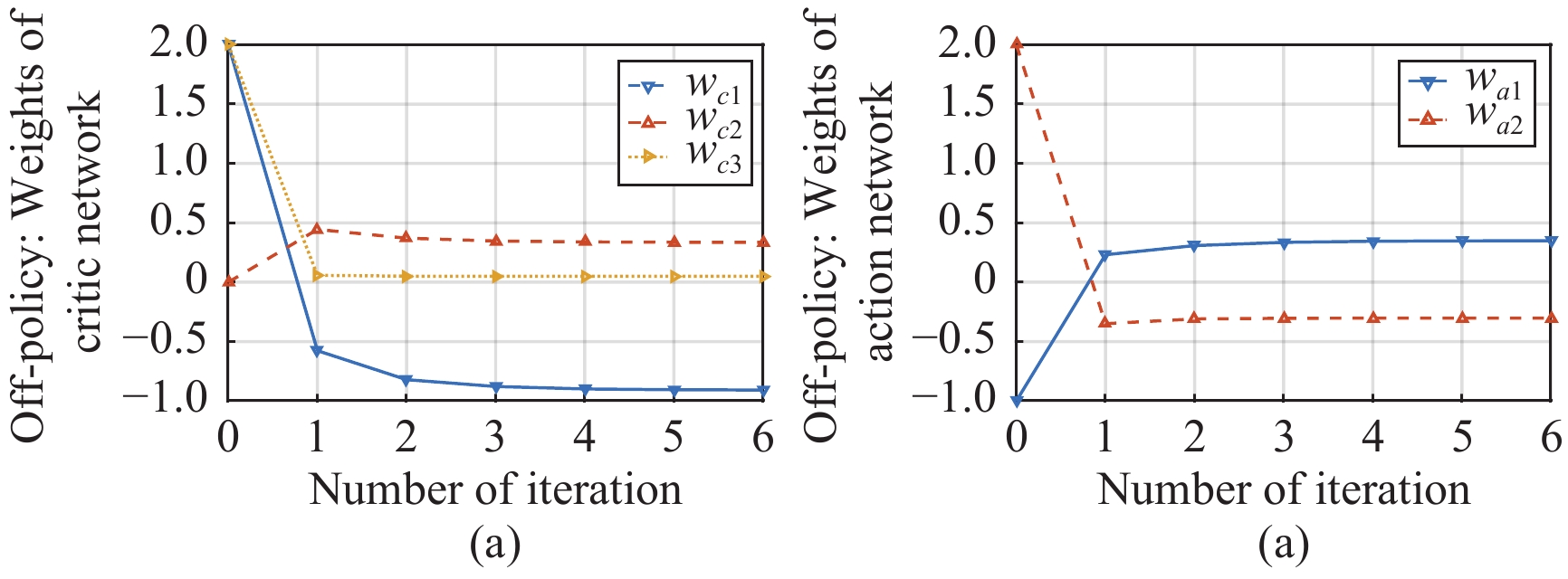
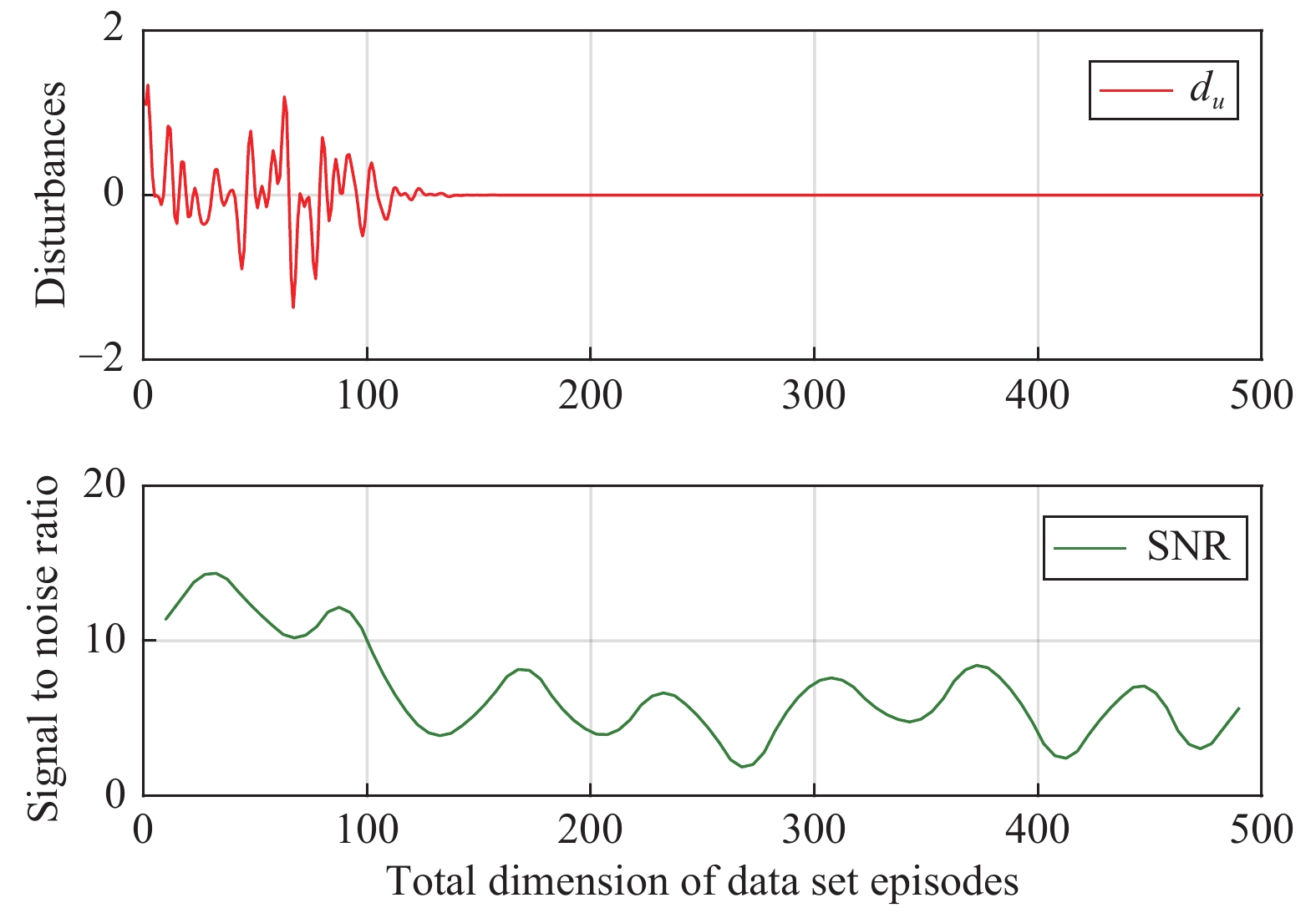
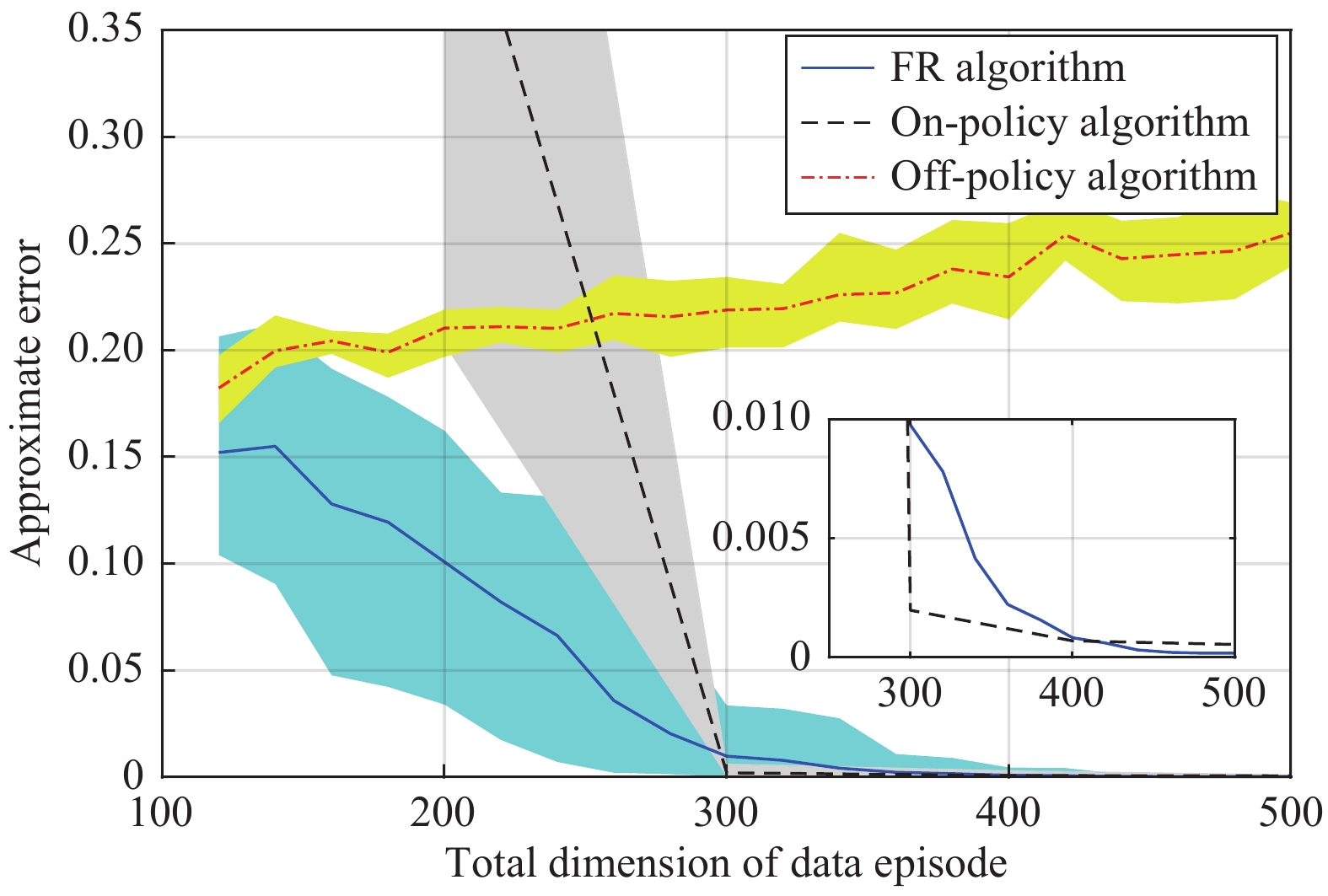
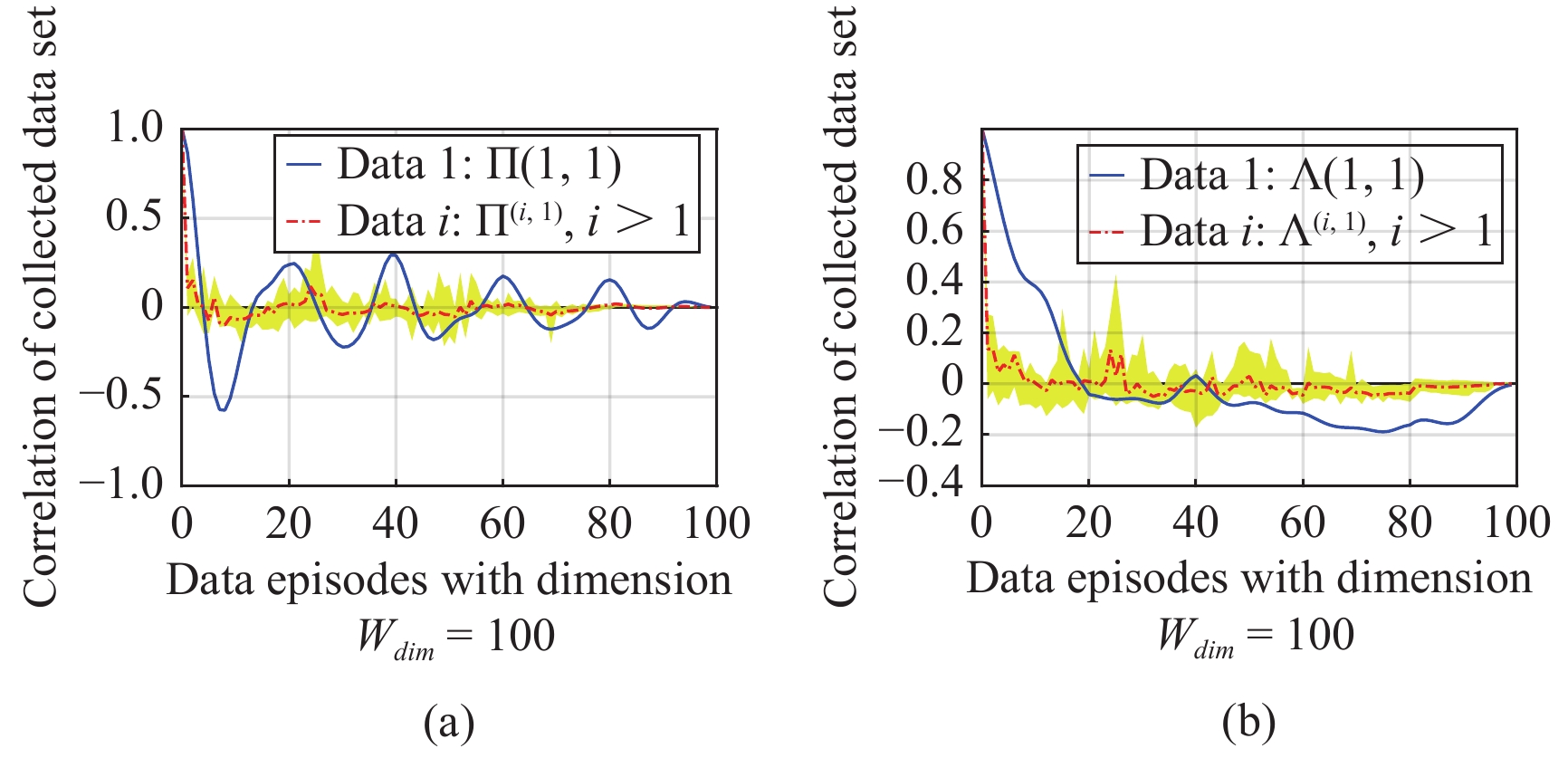
In this paper, a data-based feedback relearning algorithm is proposed for the robust control problem of uncertain nonlinear systems. Motivated by the classical on-policy and off-policy algorithms of reinforcement learning, the online feedback relearning (FR) algorithm is developed where the collected data includes the influence of disturbance signals. The FR algorithm has better adaptability to environmental changes (such as the control channel disturbances) compared with the off-policy algorithm, and has higher computational efficiency and better convergence performance compared with the on-policy algorithm. Data processing based on experience replay technology is used for great data efficiency and convergence stability. Simulation experiments are presented to illustrate convergence stability, optimality and algorithmic performance of FR algorithm by comparison.

| [1] |
R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction. Cambridge, USA: MIT press, 2018.
|
| [2] |
L. P. Kaelbling, M. L. Littman, and A. W. Moore, “Reinforcement learning: A survey,” J. Artificial Intelligence Research, vol. 4, pp. 237–285, 1996. doi: 10.1613/jair.301
|
| [3] |
M. Wiering, “Multi-agent reinforcement learning for traffic light control,” in Proc. 17th Int. Conf. Machine Learning, 2000, pp. 1151–1158.
|
| [4] |
V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing ATARI with deep reinforcement learning,” arXiv preprint arXiv: 1312.5602, 2013.
|
| [5] |
D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, et al., “Mastering the game of Go with deep neural networks and tree search,” Nature, vol. 529, p. 7587, 2016.
|
| [6] |
P. J. Werbos, “Approximate dynamic programming for real-time control and neural modeling,” in Handbook of Intelligent Control, New York, USA: Van Nostrand Reinhold, 1992, pp. 493–526.
|
| [7] |
W. Bai, Q. Zhou, T. Li, and H. Li, “Adaptive reinforcement learning neural network control for uncertain nonlinear system with input saturation,” IEEE Trans. Cybernetics, vol. 50, no. 8, pp. 3433–3443, 2020. doi: 10.1109/TCYB.2019.2921057
|
| [8] |
T. Bian, Y. Jiang, and Z. Jiang, “Adaptive dynamic programming for stochastic systems with state and control dependent noise,” IEEE Trans. Automatic Control, vol. 61, no. 12, pp. 4170–4175, 2016. doi: 10.1109/TAC.2016.2550518
|
| [9] |
O. Tutsoy, D. E. Barkana, and H. Tugal, “Design of a completely model free adaptive control in the presence of parametric, non-parametric uncertainties and random control signal delay,” ISA Trans., vol. 76, pp. 67–77, 2018. doi: 10.1016/j.isatra.2018.03.002
|
| [10] |
O. Tutsoy, “Design and comparison base analysis of adaptive estimator for completely unknown linear systems in the presence of OE noise and constant input time delay,” Asian J. Control, vol. 18, no. 3, pp. 1020–1029, 2016. doi: 10.1002/asjc.1184
|
| [11] |
L. Ren, T. Wang, Y. Laili, and L. Zhang, “A data-driven self-supervised LSTM-DeepFM model for industrial soft sensor,” IEEE Trans. Industrial Informatics, vol. 18, no. 9, pp. 5859–5869, 2022. doi: 10.1109/TⅡ.2021.3131471
|
| [12] |
O. Tutsoy and M. Brown, “Reinforcement learning analysis for a minimum time balance problem,” Trans. Institute Measurement Control, vol. 38, no. 10, pp. 1186–1200, 2016. doi: 10.1177/0142331215581638
|
| [13] |
X. Yang, H. He, and D. Liu, “Event-triggered optimal neuro-controller design with reinforcement learning for unknown nonlinear systems,” IEEE Trans. Systems,Man,Cybernetics: Systems, vol. 49, no. 9, pp. 1866–1878, 2019. doi: 10.1109/TSMC.2017.2774602
|
| [14] |
C. Mu, D. Wang, and H. He, “Data-driven finite-horizon approximate optimal control for discrete-time nonlinear systems using iterative HDP approach,” IEEE Trans. Cyber., vol. 48, no. 10, pp. 2948–2961, 2018. doi: 10.1109/TCYB.2017.2752845
|
| [15] |
J. Yi, S. Chen, X. Zhong, W. Zhou, and H. He, “Event-triggered globalized dual heuristic programming and its application to networked control systems,” IEEE Trans. Industrial Informatics, vol. 15, no. 3, pp. 1383–1392, 2019. doi: 10.1109/TII.2018.2850001
|
| [16] |
M. Imani, S. F. Ghoreishi, and U. M. Braga-Neto, “Bayesian control of large MDPs with unknown dynamics in data-poor environments,” in Proc. Advances Neural Inform. Processing Syst., 2018, pp. 8146–8156.
|
| [17] |
Y. Yin, X. Bu, P. Zhu, and W. Qian, “Point-to-point consensus tracking control for unknown nonlinear multi-agent systems using data-driven iterative learning,” Neurocomputing, vol. 488, pp. 78–87, 2022. doi: 10.1016/j.neucom.2022.02.074
|
| [18] |
Q. Wei, D. Liu, Y. Liu, and R. Song, “Optimal constrained self-learning battery sequential management in microgrid via adaptive dynamic programming,” IEEE/CAA J. Autom. Sinica, vol. 4, no. 2, pp. 168–176, 2017. doi: 10.1109/JAS.2016.7510262
|
| [19] |
Z. Shi and Z. Wang, “Optimal control for a class of complex singular system based on adaptive dynamic programming,” IEEE/CAA J. Autom. Sinica, vol. 6, no. 1, pp. 188–197, 2019. doi: 10.1109/JAS.2019.1911342
|
| [20] |
Y. Jiang and Z.-P. Jiang, Robust Adaptive Dynamic Programming. New York, USA: John Wiley & Sons, 2017.
|
| [21] |
B. Luo, H.-N. Wu, and T. Huang, “Off-policy reinforcement learning for H∞ control design,” IEEE Trans. Cyber., vol. 45, no. 1, pp. 65–76, 2015. doi: 10.1109/TCYB.2014.2319577
|
| [22] |
Q. Zhang, D. Zhao, and Y. Zhu, “Data-driven adaptive dynamic programming for continuous-time fully cooperative games with partially constrained inputs,” Neurocomputing, vol. 238, pp. 377–386, 2017. doi: 10.1016/j.neucom.2017.01.076
|
| [23] |
B. Luo and H.-N. Wu, “Computationally efficient simultaneous policy update algorithm for nonlinear H∞ state feedback control with galerkin’s method,” Int. J. Robust Nonlinear Control, vol. 23, no. 9, pp. 991–1012, 2013. doi: 10.1002/rnc.2814
|
| [24] |
H. He, Z. Ni, and J. Fu, “A three-network architecture for on-line learning and optimization based on adaptive dynamic programming,” Neurocomputing, vol. 78, no. 1, pp. 3–13, 2012. doi: 10.1016/j.neucom.2011.05.031
|
| [25] |
C. Mu, Y. Zhang, Z. Gao, and C. Sun, “ADP-based robust tracking control for a class of nonlinear systems with unmatched uncertainties,” IEEE Trans. Syst.,Man,Cyber.: Syst., vol. 50, no. 11, pp. 4056–4067, 2020. doi: 10.1109/TSMC.2019.2895692
|
| [26] |
S. Adam, L. Busoniu, and R. Babuska, “Experience replay for real-time reinforcement learning control,” IEEE Trans. Systems,Man,Cybernetics,Part C (Applications and Reviews), vol. 42, no. 2, pp. 201–212, 2011.
|
| [27] |
L.-J. Lin, “Self-improving reactive agents based on reinforcement learning, planning and teaching,” Machine Learning, vol. 8, no. 3−4, pp. 293–321, 1992. doi: 10.1007/BF00992699
|
| [28] |
S. Kalyanakrishnan and P. Stone, “Batch reinforcement learning in a complex domain,” in Proc. 6th Int. Joint Conf. Autonomous Agents and Multi-Agent Systems, 2007, pp. 662–669.
|
| [29] |
H. Modares, F. L. Lewis, and M.-B. Naghibi-Sistani, “Integral reinforcement learning and experience replay for adaptive optimal control of partially-unknown constrained-input continuous-time systems,” Automatica, vol. 50, no. 1, pp. 193–202, 2014. doi: 10.1016/j.automatica.2013.09.043
|
| [30] |
P. Wawrzyński, “Real-time reinforcement learning by sequential actor-critics and experience replay,” Neural Networks, vol. 22, no. 10, pp. 1484–1497, 2009. doi: 10.1016/j.neunet.2009.05.011
|
| [31] |
J. Na, J. Zhao, G. Gao, and Z. Li, “Output-feedback robust control of uncertain systems via online data-driven learning,” IEEE Trans. Neural Networks Learning Syst., vol. 32, no. 6, pp. 2650–2662, 2021. doi: 10.1109/TNNLS.2020.3007414
|
| [32] |
F. Lin, “An optimal control approach to robust control design,” Int. J. Control, vol. 73, no. 3, pp. 177–186, 2000. doi: 10.1080/002071700219722
|
| [33] |
B. Zhao, D. Liu, and Y. Li, “Observer based adaptive dynamic programming for fault tolerant control of a class of nonlinear systems,” Information Sciences, vol. 384, pp. 21–33, 2017. doi: 10.1016/j.ins.2016.12.016
|
| [34] |
B. Luo, H.-N. Wu, T. Huang, and D. Liu, “Reinforcement learning solution for HJB equation arising in constrained optimal control problem,” Neural Networks, vol. 71, pp. 150–158, 2015. doi: 10.1016/j.neunet.2015.08.007
|
| [35] |
Y. Jiang and Z. Jiang, “Robust adaptive dynamic programming and feedback stabilization of nonlinear systems,” IEEE Trans. Neural Networks Learning Syst., vol. 25, no. 5, pp. 882–893, 2014. doi: 10.1109/TNNLS.2013.2294968
|
| [36] |
B. Kiumarsi, F. L. Lewis, and Z. P. Jiang, “H∞ control of linear discrete-time systems: Off-policy reinforcement learning,” Automatica, vol. 78, pp. 144–152, 2017. doi: 10.1016/j.automatica.2016.12.009
|
| [37] |
M. Abu-Khalaf and F. L. Lewis, “Nearly optimal control laws for nonlinear systems with saturating actuators using a neural network HJB approach,” Automatica, vol. 41, no. 5, pp. 779–791, 2005. doi: 10.1016/j.automatica.2004.11.034
|
| [38] |
G. Chowdhary, M. Liu, R. Grande, T. Walsh, J. How, and L. Carin, “Off-policy reinforcement learning with gaussian processes,” IEEE/CAA J. Autom. Sinica, vol. 1, no. 3, pp. 227–238, 2014. doi: 10.1109/JAS.2014.7004680
|
| [39] |
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” arXiv preprint arXiv: 1509.02971, 2015.
|
| [40] |
J. Foerster, N. Nardelli, G. Farquhar, T. Afouras, P. H. Torr, P. Kohli, and S. Whiteson, “Stabilising experience replay for deep multi-agent reinforcement learning,” in Proc. 34th Int. Conf. Machine Learning, 2017, pp. 1146–1155.
|
| [41] |
T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized experience replay,”arXiv preprint arXiv: 1511.05952, 2015.
|
| [42] |
V. Nevistic and J. A. Primbs, “Constrained nonlinear optimal control: A converse HJB approach,” Control and Dynamical Syst., Technical Memorandum no. CIT-CDS 96-021, 1996.
|
| [43] |
J. Si and Y.-T. Wang, “Online learning control by association and reinforcement,” IEEE Trans. Neural Networks, vol. 12, no. 2, pp. 264–276, 2001. doi: 10.1109/72.914523
|
| [44] |
H. K. Khalil, Nonlinear Systems, 3rd. Upper Saddle River, USA: Prentice Hall, 2002.
|
Figures(21) / Tables(2)






 DownLoad:
DownLoad: