A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 10
Issue 5
Volume 10
Issue 5
IEEE/CAA Journal of Automatica Sinica
| Citation: | T. Y. Wu, S. Z. He, J. P. Liu, S. Q. Sun, K. Liu, Q.-L. Han, and Y. Tang, “A brief overview of ChatGPT: The history, status quo and potential future development,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 5, pp. 1122–1136, May 2023. doi: 10.1109/JAS.2023.123618

|
ChatGPT, an artificial intelligence generated content (AIGC) model developed by OpenAI, has attracted worldwide attention for its capability of dealing with challenging language understanding and generation tasks in the form of conversations. This paper briefly provides an overview on the history, status quo and potential future development of ChatGPT, helping to provide an entry point to think about ChatGPT. Specifically, from the limited open-accessed resources, we conclude the core techniques of ChatGPT, mainly including large-scale language models, in-context learning, reinforcement learning from human feedback and the key technical steps for developing ChatGPT. We further analyze the pros and cons of ChatGPT and we rethink the duality of ChatGPT in various fields. Although it has been widely acknowledged that ChatGPT brings plenty of opportunities for various fields, mankind should still treat and use ChatGPT properly to avoid the potential threat, e.g., academic integrity and safety challenge. Finally, we discuss several open problems as the potential development of ChatGPT.

| [1] |
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Q. Zhou, W. Li, and J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” J. Mach. Learn. Res., vol. 21, no. 1, p. 140, Jan. 2020.
|
| [2] |
H. Y. Du, Z. H. Li, D. Niyato, J. W. Kang, Z. H. Xiong, X. M. Shen, and D. I. Kim, “Enabling AI-generated content (AIGC) services in wireless edge networks,” arXiv preprint arXiv: 2301.03220, 2023.
|
| [3] |
Y. Ming, N. N. Hu, C. X. Fan, F. Feng, J. W. Zhou, and H. Yu, “Visuals to text: A comprehensive review on automatic image captioning,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 8, pp. 1339–1365, Aug. 2022. doi: 10.1109/JAS.2022.105734
|
| [4] |
C. Q. Zhao, Q. Y. Sun, C. Z. Zhang, Y. Tang, and F. Qian, “Monocular depth estimation based on deep learning: An overview,” Sci. China Technol. Sci., vol. 63, no. 9, pp. 1612–1627, Jun. 2020. doi: 10.1007/s11431-020-1582-8
|
| [5] |
J. Lü, G. H. Wen, R. Q. Lu, Y. Wang, and S. M. Zhang, “Networked knowledge and complex networks: An engineering view,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 8, pp. 1366–1383, Aug. 2022. doi: 10.1109/JAS.2022.105737
|
| [6] |
A. Creswell, T. White, V. Dumoulin, K. Arulkumaran, B. Sengupta, and A. A. Bharath, “Generative adversarial networks: An overview,” IEEE Signal Process. Mag., vol. 35, no. 1, pp. 53–65, Jan. 2018. doi: 10.1109/MSP.2017.2765202
|
| [7] |
J. Chen, K. L. Wu, Y. Yu, and L. B. Luo, “CDP-GAN: Near-infrared and visible image fusion via color distribution preserved GAN,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 9, pp. 1698–1701, Sept. 2022. doi: 10.1109/JAS.2022.105818
|
| [8] |
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” in Proc. 38th Int. Conf. Machine Learning, 2021, pp. 8748–8763.
|
| [9] |
L. Yang, Z. L. Zhang, Y. Song, S. D. Hong, R. S. Xu, Y. Zhao, W. T. Zhang, B. Cui, and M.-H. Yang, “Diffusion models: A comprehensive survey of methods and applications,” arXiv preprint arXiv: 2209.00796, 2022.
|
| [10] |
C. C. Leng, H. Zhang, G. R. Cai, Z. Chen, and A. Basu, “Total variation constrained non-negative matrix factorization for medical image registration,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 5, pp. 1025–1037, May 2021. doi: 10.1109/JAS.2021.1003979
|
| [11] |
S. Reed, K. Zolna, E. Parisotto, S. G. Colmenarejo, A. Novikov, G. Barth-Maron, M. Gimenez, Y. Sulsky, J. Kay, J. T. Springenberg, T. Eccles, J. Bruce, A. Razavi, A. Edwards, N. Heess, Y. T. Chen, R. Hadsell, O. Vinyals, M. Bordbar, and N. de Freitas, “A generalist agent,” arXiv preprint arXiv: 2205.06175, 2022.
|
| [12] |
Y. Liu, Y. Shi, F. H. Mu, J. Cheng, and X. Chen, “Glioma segmentation-oriented multi-modal MR image fusion with adversarial learning,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 8, pp. 1528–1531, Aug. 2022. doi: 10.1109/JAS.2022.105770
|
| [13] |
J. Gusak, D. Cherniuk, A. Shilova, A. Katrutsa, D. Bershatsky, X. Y. Zhao, L. Eyraud-Dubois, O. Shlyazhko, D. Dimitrov, I. Oseledets, and O. Beaumont, “Survey on large scale neural network training,” arXiv preprint arXiv: 2202.10435, 2022.
|
| [14] |
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with CLIP latents,” arXiv preprint arXiv: 2204.06125, 2022.
|
| [15] |
U. Singer, A. Polyak, T. Hayes, X. Yin, J. An, S. Y. Zhang, Q. Y. Hu, H. Yang, O. Ashual, O. Gafni, D. Parikh, S. Gupta, and Y. Taigman, “Make-a-video: Text-to-video generation without text-video data,” arXiv preprint arXiv: 2209.14792, 2022.
|
| [16] |
W. X. Jiao, W. X. Wang, J.-T. Huang, X. Wang, and Z. P. Tu, “Is ChatGPT a good translator? Yes with GPT-4 as the engine,” arXiv preprint arXiv: 2301.08745, 2023.
|
| [17] |
OpenAI, “Gpt-4 technical report,” 2023. [Online]. Available: https://cdn.openai.com/papers/gpt-4.pdf.
|
| [18] |
A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,” 2018.
|
| [19] |
M. Khosla, A. Anand, and V. Setty, “A comprehensive comparison of unsupervised network representation learning methods,” arXiv preprint arXiv: 1903.07902, 2019.
|
| [20] |
Q. Y. Sun, C. Q. Zhao, Y. Ju, and F. Qian, “A survey on unsupervised domain adaptation in computer vision tasks,” Sci. Sinica Technol., vol. 52, no. 1, pp. 26–54, 2022.
|
| [21] |
C. Ieracitano, A. Paviglianiti, M. Campolo, A. Hussain, E. Pasero, and F. C. Morabito, “A novel automatic classification system based on hybrid unsupervised and supervised machine learning for electrospun nanofibers,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 1, pp. 64–76, Jan. 2021. doi: 10.1109/JAS.2020.1003387
|
| [22] |
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” OpenAI Blog, vol. 1, no. 8, pp. 9, 2019.
|
| [23] |
Y. Zhang and Q. Yang, “A survey on multi-task learning,” IEEE Trans. Knowl. Data Eng., vol. 34, no. 12, pp. 5586–5609, Dec. 2022. doi: 10.1109/TKDE.2021.3070203
|
| [24] |
Y. Q. Wang, Q. M. Yao, J. T. Kwok, and L. M. Ni, “Generalizing from a few examples: A survey on few-shot learning,” ACM Comput. Surv., vol. 53, no. 3, p. 63, May 2021.
|
| [25] |
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” in Proc. 34th Int. Conf. Neural Information Processing Systems, Vancouver, Canada, 2020, pp. 1877–1901.
|
| [26] |
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in Proc. 34th Int. Conf. Machine Learning, Sydney, Australia, 2017, pp. 1126–1135.
|
| [27] |
J. Beck, R. Vuorio, E. Z. Liu, Z. Xiong, L. Zintgraf, C. Finn, and S. Whiteson, “A survey of meta-reinforcement learning,” arXiv preprint arXiv: 2301.08028, 2023.
|
| [28] |
Q. X. Dong, L. Li, D. M. Dai, C. Zheng, Z. Y. Wu, B. B. Chang, X. Sun, J. J. Xu, L. Li, and Z. F. Sui, “A survey on in-context learning,” arXiv preprint arXiv: 2301.00234, 2022.
|
| [29] |
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe, “Training language models to follow instructions with human feedback,” arXiv preprint arXiv: 2203.02155, 2022.
|
| [30] |
C. W. Qin, A. Zhang, Z. S. Zhang, J. A. Chen, M. Yasunaga, and D. Y. Yang, “Is ChatGPT a general-purpose natural language processing task solver?” arXiv preprint arXiv: 2302.06476, 2023.
|
| [31] |
C. Stokel-Walker and R. Van Noorden, “What ChatGPT and generative AI mean for science,” Nature, vol. 614, no. 7947, pp. 214–216, Feb. 2023. doi: 10.1038/d41586-023-00340-6
|
| [32] |
C. Stokel-Walker, “ChatGPT listed as author on research papers: Many scientists disapprove,” Nature, vol. 613, no. 7945, pp. 620–621, Jan. 2023. doi: 10.1038/d41586-023-00107-z
|
| [33] |
C. X. Zhai, Statistical Language Models for Information Retrieval. Hanover, USA: Now Publishers Inc., 2008, pp. 1–141.
|
| [34] |
Y. Bengio, R. Ducharme, and P. Vincent, “A neural probabilistic language model,” in Proc. 13th Int. Conf. Neural Information Processing Systems, Denver, USA, 2000, pp. 893–899.
|
| [35] |
R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, and Kuksa, “Natural language processing (almost) from scratch,” J. Mach. Learn. Res., vol. 12, pp. 2493–2537, Nov. 2011.
|
| [36] |
Y. M. Ju, Y. Z. Zhang, K. Liu, and J. Zhao, “Generating hierarchical explanations on text classification without connecting rules,” arXiv preprint arXiv: 2210.13270, 2022.
|
| [37] |
M. J. Zhu, Y. X. Weng, S. Z. He, K. Liu, and J. Zhao, “Learning to answer complex visual questions from multi-view analysis,” in Proc. 7th China Conf. Knowledge Graph and Semantic Computing, Qinhuangdao, China, 2022, pp. 154–162.
|
| [38] |
T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” in Proc. 1st Int. Conf. Learning Representations, Scottsdale, USA, 2013.
|
| [39] |
T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” in Proc. 26th Int. Conf. Neural Information Processing Systems, Lake Tahoe, USA, 2013, pp. 3111–3119.
|
| [40] |
T. Mikolov, M. Karafiat, L. Burget, J. Cernocký, and S. Khudanpur, “Recurrent neural network based language model,” in Proc. 11th Annu. Conf. Int. Speech Communication Association, Makuhari, Japan, 2010, pp. 1045–1048.
|
| [41] |
M. Sundermeyer, R. Schlueter, and H. Ney, “LSTM neural networks for language modeling,” in Proc. 13th Annu. Conf. Int. Speech Communication Association, Portland, USA, 2012, pp. 194–197.
|
| [42] |
X. Qiu, T. X. Sun, Y. G. Xu, Y. F. Shao, N. Dai, and X. J. Huang, “Pre-trained models for natural language processing: A survey,” Sci. China Technol. Sci., vol. 63, no. 10, pp. 1872–1897, Sept. 2020. doi: 10.1007/s11431-020-1647-3
|
| [43] |
M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, “Deep contextualized word representations,” in Proc. Conf. North American Chapter of the Association for Computational Linguistics, New Orleans, USA, 2018, pp. 2227–2237.
|
| [44] |
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proc. Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, USA, 2019, pp. 4171–4186.
|
| [45] |
M. Lewis, Y. H. Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V. Stoyanov, and L. Zettlemoyer, “BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension,” in Proc. 58th Annu. Meeting of the Association for Computational Linguistics, 2020, pp. 7871–7880.
|
| [46] |
Y. H. Liu, M. Ott, N. Goyal, J. F. Du, M. Joshi, D. Q. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “RoBERTa: A robustly optimized BERT pretraining approach,” arXiv preprint arXiv: 1907.11692, 2019.
|
| [47] |
Z. Z. Lan, M. D. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut, “ALBERT: A lite BERT for self-supervised learning of language representations,” in Proc. 8th Int. Conf. Learning Representations, Addis Ababa, Ethiopia, 2020.
|
| [48] |
V. Sanh, L. Debut, J. Chaumond, and T. Wolf, “DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter,” arXiv preprint arXiv: 1910.01108, 2019.
|
| [49] |
X. Q. Jiao, Y. C. Yin, L. F. Shang, X. Jiang, X. Chen, L. L. Li, F. Wang, and Q. Liu, “TinyBERT: Distilling BERT for natural language understanding,” in Proc. Findings of the Association for Computational Linguistics, 2020, pp. 4163–4174.
|
| [50] |
Y. M. Cui, W. X. Che, T. Liu, B. Qin, and Z. Q. Yang, “Pre-training with whole word masking for Chinese BERT,” IEEE/ACM Trans. Audio,Speech,Lang. Process., vol. 29, pp. 3504–3514, Nov. 2021. doi: 10.1109/TASLP.2021.3124365
|
| [51] |
W. J. Liu, P. Zhou, Z. Zhao, Z. R. Wang, Q. Ju, H. T. Deng, and P. Wang, “K-BERT: Enabling language representation with knowledge graph,” in Proc. 34th AAAI Conf. Artificial Intelligence, New York, USA, 2019, pp. 2901–2908.
|
| [52] |
A. Rogers, O. Kovaleva, and A. Rumshisky, “A primer in BERTology: What we know about how BERT works,” Trans. Assoc. Comput. Linguist., vol. 8, pp. 842–866, 2020.
|
| [53] |
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. 31st Int. Conf. Neural Information Processing Systems, Long Beach, USA, 2017, pp. 6000–6010.
|
| [54] |
W. Q. Ren, Y. Tang, Q. Y. Sun, C. Q. Zhao, and Q.-L. Han, “Visual semantic segmentation based on few/zero-shot learning: An overview,” arXiv preprint arXiv: 2211.08352, 2022.
|
| [55] |
S. Smith, M. Patwary, B. Norick, P. LeGresley, S. Rajbhandari, J. Casper, Z. Liu, S. Prabhumoye, G. Zerveas, V. Korthikanti, E. Zhang, R. Child, R. Y. Aminabadi, J. Bernauer, X. Song, M. Shoeybi, Y. X. He, M. Houston, S. Tiwary, and B. Catanzaro, “Using DeepSpeed and megatron to train megatron-turing NLG 530B, a large-scale generative language model,” arXiv preprint arXiv: 2201.11990, 2022.
|
| [56] |
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. Von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill, E. Brynjolfsson, S. Buch, D. Card, R. Castellon, N. Chatterji, A. Chen, K. Creel, J. Q. Davis, D. Demszky, C. Donahue, M. Doumbouya, E. Durmus, S. Ermon, J. Etchemendy, K. Ethayarajh, L. Fei-Fei, C. Finn, T. Gale, L. Gillespie, K. Goel, N. Goodman, S. Grossman, N. Guha, T. Hashimoto, P. Henderson, J. Hewitt, D. E. Ho, J. Hong, K. Hsu, J. Huang, T. Icard, S. Jain, D. Jurafsky, P. Kalluri, S. Karamcheti, G. Keeling, F. Khani, O. Khattab, P. W. Koh, M. Krass, R. Krishna, R. Kuditipudi, A. Kumar, F. Ladhak, M. Lee, T. Lee, J. Leskovec, I. Levent, X. L. Li, X. C. Li, T. Y. Ma, A. Malik, C. D. Manning, S. Mirchandani, E. Mitchell, Z. Munyikwa, S. Nair, A. Narayan, D. Narayanan, B. Newman, A. Nie, J. C. Niebles, H. Nilforoshan, J. Nyarko, G. Ogut, L. Orr, I. Papadimitriou, J. S. Park, C. Piech, E. Portelance, C. Potts, A. Raghunathan, R. Reich, H. Y. Ren, F. Rong, Y. Roohani, C. Ruiz, J. Ryan, C. Ré, D. Sadigh, S. Sagawa, K. Santhanam, A. Shih, K. Srinivasan, A. Tamkin, R. Taori, A. W. Thomas, F. Tramèr, R. E. Wang, W. Wang, B. H. Wu, J. J. Wu, Y. H. Wu, S. M. Xie, M. Yasunaga, J. X. You, M. Zaharia, M. Zhang, T. Y. Zhang, X. K. Zhang, Y. H. Zhang, L. Zheng, K. Zhou, and P. Liang, “On the opportunities and risks of foundation models,” arXiv preprint arXiv: 2108.07258, 2021.
|
| [57] |
J. Wei, X. Z. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” arXiv preprint arXiv: 2201.11903, 2022.
|
| [58] |
J. Huang and K. C.-C. Chang, “Towards reasoning in large language models: A survey,” arXiv preprint arXiv: 2212.10403, 2022.
|
| [59] |
T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa, “Large language models are zero-shot reasoners,” arXiv preprint arXiv: 2205.11916, 2022.
|
| [60] |
Z. S. Zhang, A. Zhang, M. Li, and A. Smola, “Automatic chain of thought prompting in large language models,” arXiv preprint arXiv: 2210.03493, 2022.
|
| [61] |
D. Zhou, N. Scharli, L. Hou, J. Wei, N. Scales, X. Z. Wang, D. Schuurmans, C. Cui, O. Bousquet, Q. Le, and E. Chi, “Least-to-most prompting enables complex reasoning in large language models,” arXiv preprint arXiv: 2205.10625, 2022.
|
| [62] |
X. Z. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” arXiv preprint arXiv: 2203.11171, 2022.
|
| [63] |
Y. X. Weng, M. J. Zhu, F. Xia, B. Li, S. Z. He, K. Liu, and J. Zhao, “Large language models are reasoners with self-verification,” arXiv preprint arXiv: 2212.09561, 2022.
|
| [64] |
H. W. Chung, L. Hou, S. Longpre, B. Zoph, Y. Tay, W. Fedus, Y. X. Li, X. Z. Wang, M. Dehghani, S. Brahma, A. Webson, S. S. Gu, Z. Y. Dai, M. Suzgun, X. Y. Chen, A. Chowdhery, A. Castro-Ros, M. Pellat, K. Robinson, D. Valter, S. Narang, G. Mishra, A. Yu, V. Zhao, Y. P. Huang, A. Dai, H. K. Yu, S. Petrov, E. H. Chi, J. Dean, J. Devlin, A. Roberts, D. Zhou, Q. V. Le, and J. Wei, “Scaling instruction-finetuned language models,” arXiv preprint arXiv: 2210.11416, 2022.
|
| [65] |
D. Goldwasser and D. Roth, “Learning from natural instructions,” Mach. Learn., vol. 94, no. 2, pp. 205–232, Feb. 2014. doi: 10.1007/s10994-013-5407-y
|
| [66] |
J. Wei, M. Bosma, V. Y. Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, and Q. V. Le, “Finetuned language models are zero-shot learners,” in Proc. 10th Int. Conf. Learning Representations, 2022.
|
| [67] |
R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction. 2nd ed. MIT Press, 2018.
|
| [68] |
L. Xue, C. Y. Sun, D. Wunsch, Y. J. Zhou, and F. Yu, “An adaptive strategy via reinforcement learning for the prisoner’s dilemma game,” IEEE/CAA J. Autom. Sinica, vol. 5, no. 1, pp. 301–310, Jan. 2018. doi: 10.1109/JAS.2017.7510466
|
| [69] |
D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepel, T. Lillicrap, K. Simonyan, and D. Hassabis, “A general reinforcement learning algorithm that masters chess, shogi, and go through self-play,” Science, vol. 362, no. 6419, pp. 1140–1144, Dec. 2018. doi: 10.1126/science.aar6404
|
| [70] |
O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D. H. Choi, R. Powell, T. Ewalds, Georgiev, J. Oh, D. Horgan, M. Kroiss, I. Danihelka, A. Huang, L. Sifre, T. Cai, J. Agapiou, M. Jaderberg, A. S. Vezhnevets, R. Leblond, T. Pohlen, V. Dalibard, D. Budden, Y. Sulsky, J. Molloy, T. L. Paine, C. Gulcehre, Z. Y. Wang, T. Pfaff, Y. H. Wu, R. Ring, D. Yogatama, D. Wünsch, K. McKinney, O. Smith, T. Schaul, T. Lillicrap, K. Kavukcuoglu, D. Hassabis, C. Apps, and D. Silver, “Grandmaster level in StarCraft II using multi-agent reinforcement learning,” Nature, vol. 575, no. 7782, pp. 350–354, Oct. 2019. doi: 10.1038/s41586-019-1724-z
|
| [71] |
Y. B. Jin, X. W. Liu, Y. C. Shao, H. T. Wang, and W. Yang, “High-speed quadrupedal locomotion by imitation-relaxation reinforcement learning,” Nat. Mach. Intell., vol. 4, no. 12, pp. 1198–1208, Dec. 2022. doi: 10.1038/s42256-022-00576-3
|
| [72] |
A. Ecoffet, J. Huizinga, J. Lehman, K. O. Stanley, and J. Clune, “First return, then explore,” Nature, vol. 590, no. 7847, pp. 580–586, Feb. 2021. doi: 10.1038/s41586-020-03157-9
|
| [73] |
R. F. Wu, Z. K. Yao, J. Si, and H. H. Huang, “Robotic knee tracking control to mimic the intact human knee profile based on actor-critic reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 1, pp. 19–30, Jan. 2021.
|
| [74] |
S. K. Gottipati, B. Sattarov, S. F. Niu, Y. Pathak, H. R. Wei, S. C. Liu, K. J. Thomas, S. Blackburn, C. W. Coley, J. Tang, S. Chandar, S. Chandar, and Y. Bengio, “Learning to navigate the synthetically accessible chemical space using reinforcement learning,” in Proc. 37th Int. Conf. Machine Learning, 2020, pp. 344.
|
| [75] |
J. K. Wang, C.-Y. Hsieh, M. Y. Wang, X. R. Wang, Z. X. Wu, D. J. Jiang, B. B. Liao, X. J. Zhang, B. Yang, Q. J. He, D. S. Cao, and T. J. Hou, “Multi-constraint molecular generation based on conditional transformer, knowledge distillation and reinforcement learning,” Nat. Mach. Intell., vol. 3, no. 10, pp. 914–922, Oct. 2021. doi: 10.1038/s42256-021-00403-1
|
| [76] |
Y. N. Wan, J. H. Qin, X. H. Yu, T. Yang, and Y. Kang, “Price-based residential demand response management in smart grids: A reinforcement learning-based approach,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 1, pp. 123–134, Jan. 2022. doi: 10.1109/JAS.2021.1004287
|
| [77] |
W. Z. Liu, L. Dong, D. Niu, and C. Y. Sun, “Efficient exploration for multi-agent reinforcement learning via transferable successor features,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 9, pp. 1673–1686, Sept. 2022. doi: 10.1109/JAS.2022.105809
|
| [78] |
J. Y. Weng, H. Y. Chen, D. Yan, K. C. You, A. Duburcq, M. H. Zhang, Y. Su, H. Su, and J. Zhu, “Tianshou: A highly modularized deep reinforcement learning library,” J. Mach. Learn. Res., vol. 23, no. 267, pp. 1–6, Aug. 2022.
|
| [79] |
J. Schulman, S. Levine, P. Moritz, M. Jordan, and P. Abbeel, “Trust region policy optimization,” in Proc. 32nd Int. Conf. Int. Conf. Machine Learning, Lille, France, 2015, pp. 1889–1897.
|
| [80] |
T. Haarnoja, A. Zhou, K. Hartikainen, G. Tucker, S. Ha, J. Tan, V. Kumar, H. Zhu, A. Gupta, P. Abbeel, and S. Levine, “Soft actor-critic algorithms and applications,” arXiv preprint arXiv: 1812.05905, 2018.
|
| [81] |
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv: 1707.06347, 2017.
|
| [82] |
S. Fujimoto, H. Van Hoof, and D. Meger, “Addressing function approximation error in actor-critic methods,” in Proc. 35th Int. Conf. Machine Learning, Stockholm, Sweden, 2018, pp. 1582–1591.
|
| [83] |
X. Y. Chen, C. Wang, Z. J. Zhou, and K. W. Ross, “Randomized ensembled double q-learning: Learning fast without a model,” in Proc. 9th Int. Conf. Learning Representations, 2021.
|
| [84] |
P. F. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” in Proc. 31st Int. Conf. Neural Information Processing Systems, Long Beach, USA, 2017, pp. 4302–4310.
|
| [85] |
W. B. Knox and P. Stone, “TAMER: Training an agent manually via evaluative reinforcement,” in Proc. 7th IEEE Int. Conf. Development and Learning, Monterey, USA, 2008, pp. 292–297.
|
| [86] |
J. MacGlashan, M. K. Ho, R. Loftin, B. Peng, G. Wang, D. L. Roberts, M. E. Taylor, and M. L. Littman, “Interactive learning from policy-dependent human feedback,” in Proc. 34th Int. Conf. Machine Learning, Sydney, Australia, 2017, pp. 2285–2294.
|
| [87] |
G. Warnell, N. R. Waytowich, V. Lawhern, and P. Stone, “Deep TAMER: Interactive agent shaping in high-dimensional state spaces,” in Proc. 32nd AAAI Conf. Artificial Intelligence, New Orleans, USA, 2018, pp. 1545–1554.
|
| [88] |
A. Glaese, N. McAleese, M. Trębacz, J. Aslanides, V. Firoiu, T. Ewalds, M. Rauh, L. Weidinger, M. Chadwick, P. Thacker, L. Campbell-Gillingham, J. Uesato, P.-S. Huang, R. Comanescu, F. Yang, A. See, S. Dathathri, R. Greig, C. Chen, D. Fritz, J. S. Elias, R. Green, S. Mokrá, N. Fernando, B. X. Wu, R. Foley, S. Young, I. Gabriel, W. Isaac, J. Mellor, D. Hassabis, K. Kavukcuoglu, L. A. Hendricks, and G. Irving, “Improving alignment of dialogue agents via targeted human judgements,” arXiv preprint arXiv: 2209.14375, 2022.
|
| [89] |
D. Cohen, M. Ryu, Y. Chow, O. Keller, I. Greenberg, A. Hassidim, M. Fink, Y. Matias, I. Szpektor, C. Boutilier, and G. Elidan, “Dynamic planning in open-ended dialogue using reinforcement learning,” arXiv preprint arXiv: 2208.02294, 2022.
|
| [90] |
J. Kreutzer, S. Khadivi, E. Matusov, and S. Riezler, “Can neural machine translation be improved with user feedback?” in Proc. Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, USA, 2018, pp. 92–105.
|
| [91] |
S. Kiegeland and J. Kreutzer, “Revisiting the weaknesses of reinforcement learning for neural machine translation,” in Proc. Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021, pp. 1673–1681.
|
| [92] |
W. C. S. Zhou and K. Xu, “Learning to compare for better training and evaluation of open domain natural language generation models,” in Proc. 34th AAAI Conf. Artificial Intelligence, New York, USA, 2020, pp. 9717–9724.
|
| [93] |
E. Perez, S. Karamcheti, R. Fergus, J. Weston, D. Kiela, and K. Cho, “Finding generalizable evidence by learning to convince Q&A models,” in Proc. Conf. Empirical Methods in Natural Language Processing and the 9th Int. Joint Conf. Natural Language Processing, Hong Kong, China, 2019, pp. 2402–2411.
|
| [94] |
A. Madaan, N. Tandon, P. Clark, and Y. M. Yang, “Memory-assisted prompt editing to improve GPT-3 after deployment,” in Proc. Conf. Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 2022, pp. 2833–2861.
|
| [95] |
C. Lawrence and S. Riezler, “Improving a neural semantic parser by counterfactual learning from human bandit feedback,” in Proc. 56th Annu. Meeting of the Association for Computational Linguistics, Melbourne, Australia, 2018, pp. 1820–1830.
|
| [96] |
N. Stiennon, L. Ouyang, J. Wu, D. M. Ziegler, R. Lowe, C. Voss, A. Radford, D. Amodei, and P. F. Christiano, “Learning to summarize with human feedback,” in Proc. 34th Neural Information Processing Systems, 2020, pp. 3008–3021.
|
| [97] |
P. Liang, R. Bommasani, T. Lee, D. Tsipras, D. Soylu, M. Yasunaga, Y. A. Zhang, D. Narayanan, Y. H. Wu, A. Kumar, B. Newman, B. H. Yuan, B. Yan, C. Zhang, C. Cosgrove, C. D. Manning, C. Ré, D. Acosta-Navas, D. A. Hudson, E. Zelikman, E. Durmus, F. Ladhak, F. Rong, H. Y. Ren, H. X. Yao, J. Wang, K. Santhanam, L. Orr, L. Zheng, M. Yuksekgonul, M. Suzgun, N. Kim, N. Guha, N. Chatterji, O. Khattab, P. Henderson, Q. Huang, R. Chi, S. M. Xie, S. Santurkar, S. Ganguli, T. Hashimoto, T. Icard, T. Y. Zhang, V. Chaudhary, W. Wang, X. C. Li, Y. F. Mai, Y. H. Zhang, and Y. Koreeda, “Holistic evaluation of language models,” arXiv preprint arXiv: 2211.09110, 2022.
|
| [98] |
T. H. Kung, M. Cheatham, A. Medenilla, C. Sillos, L. De Leon, C. Elepaño, M. Madriaga, R. Aggabao, G. Diaz-Candido, J. Maningo, and V. Tseng, “Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models,” PLoS Digit. Health, vol. 2, no. 2, p. e0000198, 2023. doi: 10.1371/journal.pdig.0000198
|
| [99] |
Y. Q. Xie, C. Yu, T. Y. Zhu, J. B. Bai, Z. Gong, and H. Soh, “Translating natural language to planning goals with large-language models,” arXiv preprint arXiv: 2302.05128, 2023.
|
| [100] |
A. Borji, “A categorical archive of ChatGPT failures,” arXiv preprint arXiv: 2302.03494, 2023.
|
| [101] |
S. Frieder, L. Pinchetti, R.-R. Griffiths, T. Salvatori, T. Lukasiewicz, P. C. Petersen, A. Chevalier, and J. Berner, “Mathematical capabilities of ChatGPT,” arXiv preprint arXiv: 2301.13867, 2023.
|
| [102] |
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” arXiv preprint arXiv: 2302.04761, 2023.
|
| [103] |
W. X. Zhou, S. Zhang, H. Poon, and M. Chen, “Context-faithful prompting for large language models,” arXiv preprint arXiv: 2303.11315, 2023.
|
| [104] |
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Y. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y. M. Yang, S. Welleck, B. P. Majumder, S. Gupta, A. Yazdanbakhsh, and P. Clark, “Self-refine: Iterative refinement with self-feedback,” arXiv preprint arXiv: 2303.17651, 2023.
|
| [105] |
B. Paranjape, S. Lundberg, S. Singh, H. Hajishirzi, L. Zettlemoyer, and M. T. Ribeiro, “ART: Automatic multi-step reasoning and tool-use for large language models,” arXiv preprint arXiv: 2303.09014, 2023.
|
| [106] |
S. Bubeck, V. Chandrasekaran, R. Eldan, J. Gehrke, E. Horvitz, E. Kamar, P. Lee, Y. T. Lee, Y. Z. Li, S. Lundberg, H. Nori, H. Palangi, M. T. Ribeiro, and Y. Zhang, “Sparks of artificial general intelligence: Early experiments with GPT-4,” arXiv preprint arXiv: 2303.12712, 2023.
|
| [107] |
F.-Y. Wang, J. Yang, X. X. Wang, J. J. Li, and Q.-L. Han, “Chat with ChatGPT on industry 5.0: Learning and decision-making for intelligent industries,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 4, pp. 831–834, Apr. 2023. doi: 10.1109/JAS.2023.123552
|
| [108] |
F.-Y. Wang, Q. H. Miao, X. Li, X. X. Wang, and Y. L. Lin, “What does ChatGPT say: The DAO from algorithmic intelligence to linguistic intelligence,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 3, pp. 575–579, Mar. 2023. doi: 10.1109/JAS.2023.123486
|
| [109] |
Q. H. Miao, W. B. Zheng, Y. S. Lv, M. Huang, W. W. Ding, and F.-Y. Wang, “DAO to HANOI via DeSci: AI paradigm shifts from AlphaGo to ChatGPT,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 4, pp. 877–897, Apr. 2023. doi: 10.1109/JAS.2023.123561
|
| [110] |
K. Guu, K. Lee, Z. Tung, P. Pasupat, and M.-W. Chang, “Retrieval augmented language model pre-training,” in Proc. 37th Int. Conf. Machine Learning, 2020, pp. 3929–3938.
|
| [111] |
P. S. H. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-T. Yih, T. Rocktäschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Proc. 34th Advances in Neural Information Processing Systems, 2020, pp. 9459–9474.
|
| [112] |
Y. Z. Zhang, S. Q. Sun, X. Gao, Y. W. Fang, C. Brockett, M. Galley, J. F. Gao, and B. Dolan, “RetGen: A joint framework for retrieval and grounded text generation modeling,” in Proc. 36th AAAI Conf. Artificial Intelligence, 2022, pp. 11739–11747.
|
| [113] |
J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler, E. H. Chi, T. Hashimoto, O. Vinyals, P. Liang, J. Dean, and W. Fedus, “Emergent abilities of large language models,” arXiv preprint arXiv: 2206.07682, 2022.
|
| [114] |
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,” arXiv preprint arXiv: 2001.08361, 2020.
|
| [115] |
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv: 1503.02531, 2015.
|
| [116] |
S. Q. Sun, Y. Cheng, Z. Gan, and J. J. Liu, “Patient knowledge distillation for BERT model compression,” in Proc. Conf. Empirical Methods in Natural Language Processing and the 9th Int. Joint Conf. Natural Language Processing, Hong Kong, China, 2019, pp. 4323–4332.
|
| [117] |
Z. Q. Sun, H. K. Yu, X. D. Song, R. J. Liu, Y. M. Yang, and D. Zhou, “MobileBERT: A compact task-agnostic BERT for resource-limited devices,” in Proc. 58th Annu. Meeting of the Association for Computational Linguistics, 2020, pp. 2158–2170.
|
| [118] |
M. Gordon, K. Duh, and N. Andrews, “Compressing BERT: Studying the effects of weight pruning on transfer learning,” in Proc. 5th Workshop on Representation Learning for NLP, 2020, pp. 143–155.
|
| [119] |
T. L. Chen, J. Frankle, S. Y. Chang, S. J. Liu, Y. Zhang, Z. Y. Wang, and M. Carbin, “The lottery ticket hypothesis for pre-trained BERT networks,” in Proc. 34th Int. Conf. Neural Information Processing Systems, Vancouver, Canada, 2020, pp. 1328.
|
| [120] |
S. Shen, Z. Dong, J. Y. Ye, L. J. Ma, Z. W. Yao, A. Gholami, M. W. Mahoney, and K. Keutzer, “Q-BERT: Hessian based ultra low precision quantization of BERT,” in Proc. 34th AAAI Conf. Artificial Intelligence, New York, USA, 2020, pp. 8815–8821.
|
| [121] |
H. L. Bai, W. Zhang, L. Hou, L. F. Shang, J. Jin, X. Jiang, Q. Liu, M. Lyu, and I. King, “BinaryBERT: Pushing the limit of BERT quantization,” in Proc. 59th Annu. Meeting of the Association for Computational Linguistics and the 11th Int. Joint Conf. Natural Language Processing, 2020, pp. 4334–4348.
|
| [122] |
Y. Cheng, D. Wang, P. Zhou, and T. Zhang, “A survey of model compression and acceleration for deep neural networks,” arXiv preprint arXiv: 1710.09282, 2017.
|
| [123] |
M. Kosinski, “Theory of mind may have spontaneously emerged in large language models,” arXiv preprint arXiv: 2302.02083, 2023.
|
| [124] |
G. I. Parisi, R. Kemker, J. L. Part, C. Kanan, and S. Wermter, “Continual lifelong learning with neural networks: A review,” Neural Netw., vol. 113, pp. 54–71, May 2019. doi: 10.1016/j.neunet.2019.01.012
|
| [125] |
S. X. Ji, S. R. Pan, E. Cambria, Marttinen, and S. Yu, “A survey on knowledge graphs: Representation, acquisition, and applications,” IEEE Trans. Neural Netw. Learn. Syst., vol. 33, no. 2, pp. 494–514, Feb. 2022. doi: 10.1109/TNNLS.2021.3070843
|
| [126] |
Y. Y. Lan, S. Z. He, K. Liu, and J. Zhao, “Knowledge reasoning via jointly modeling knowledge graphs and soft rules,” arXiv preprint arXiv: 2301.02781, 2023.
|
| [127] |
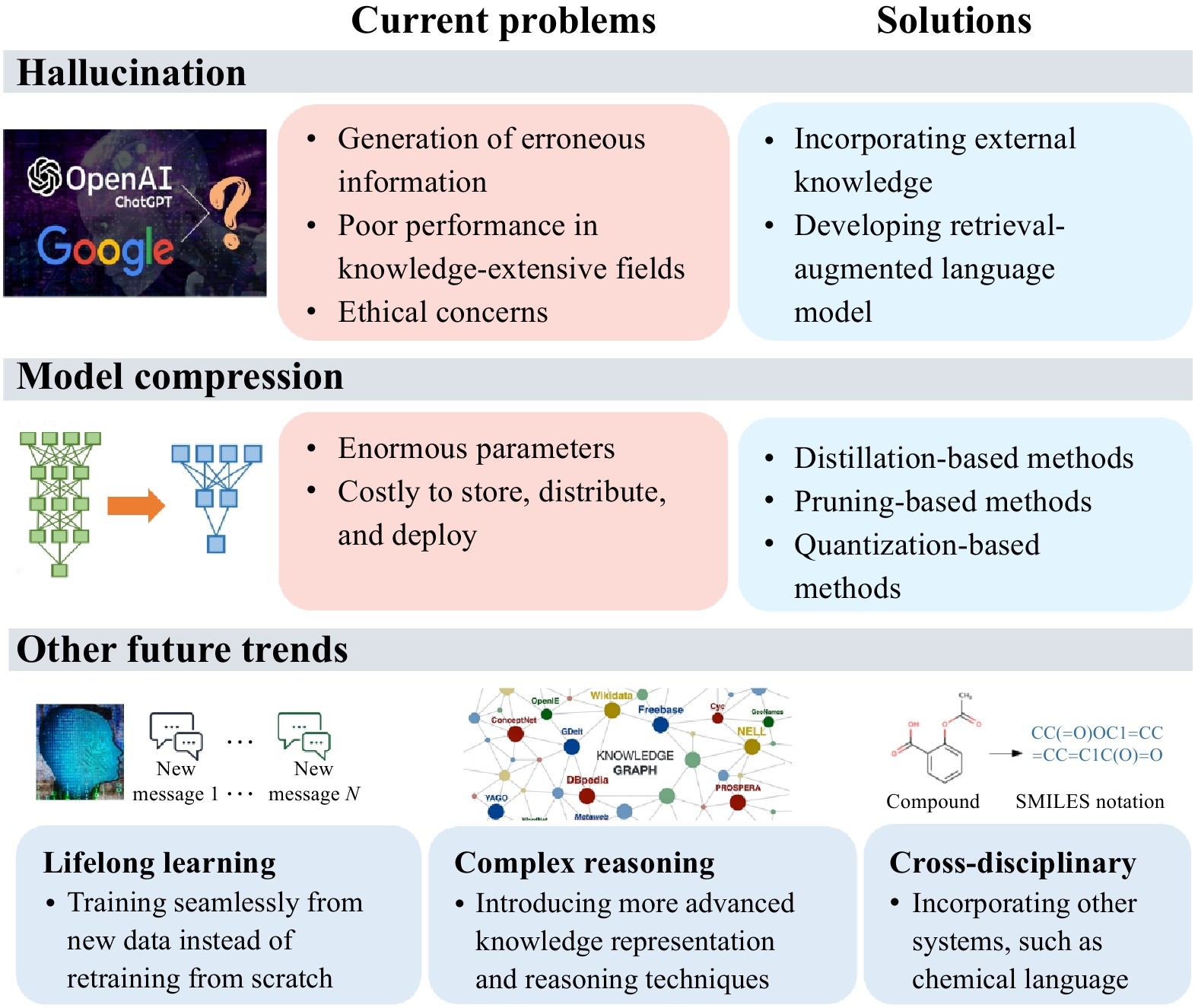
Y. J. Bang, S. Cahyawijaya, N. Lee, W. L. Dai, D. Su, B. Wilie, H. Lovenia, Z. W. Ji, T. Z. Yu, W. Chung, Q. V. Do, Y. Xu, and P. Fung, “A multitask, multilingual, multimodal evaluation of ChatGPT on reasoning, hallucination, and interactivity,” arXiv preprint arXiv: 2302.04023, 2023.
|
| [128] |
D. Weininger, “SMILEs, a chemical language and information system. 1. Introduction to methodology and encoding rules,” J. Chem. Inf. Comput. Sci., vol. 28, no. 1, pp. 31–36, 1988. doi: 10.1021/ci00057a005
|

Figures(6) / Tables(1)






 DownLoad:
DownLoad: