A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 10
Issue 5
Volume 10
Issue 5
IEEE/CAA Journal of Automatica Sinica
| Citation: | Z. Y. Qin, X. K. Lu, X. S. Nie, D. F. Liu, Y. L. Yin, and W. G. Wang, “Coarse-to-fine video instance segmentation with factorized conditional appearance flows,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 5, pp. 1192–1208, May 2023. doi: 10.1109/JAS.2023.123456

|
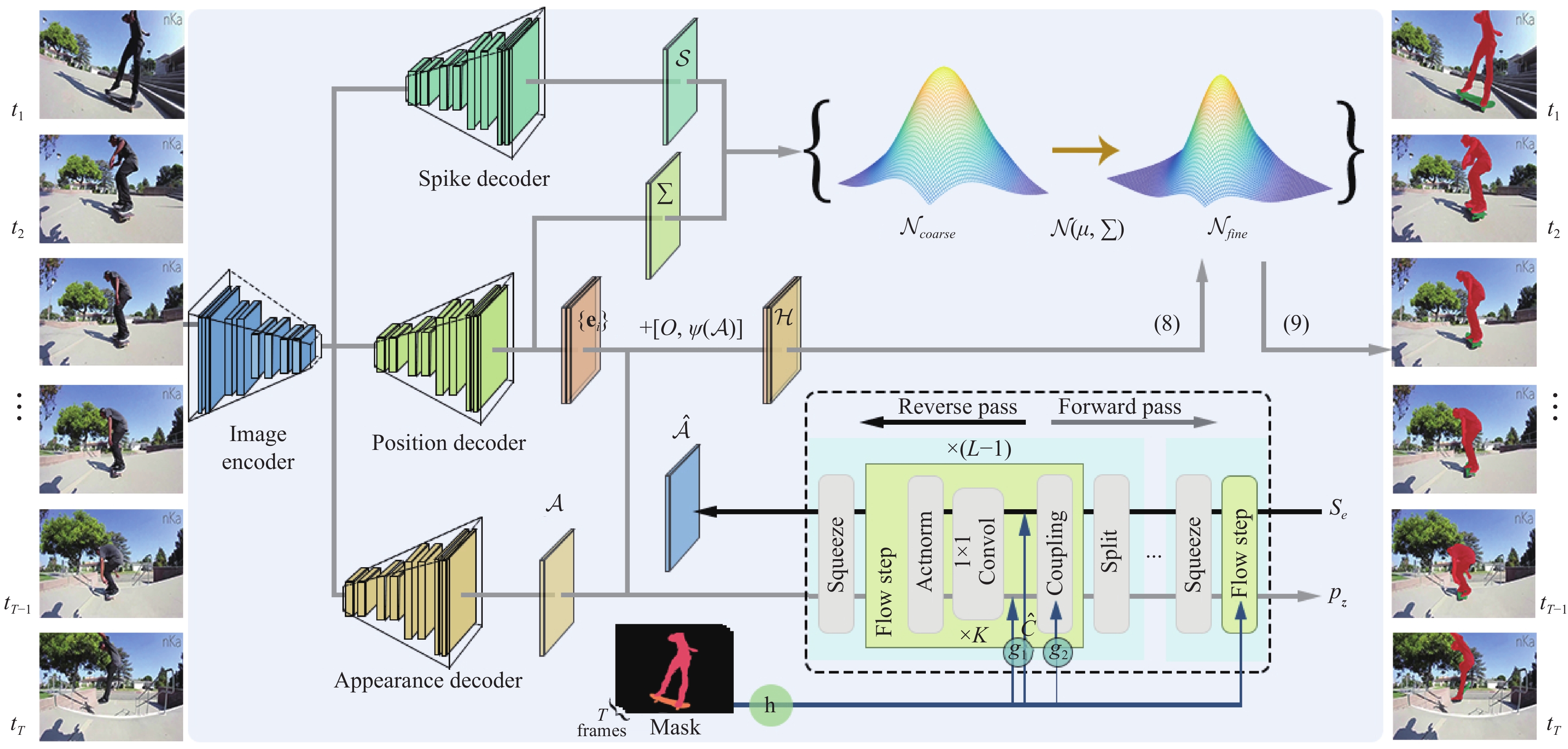
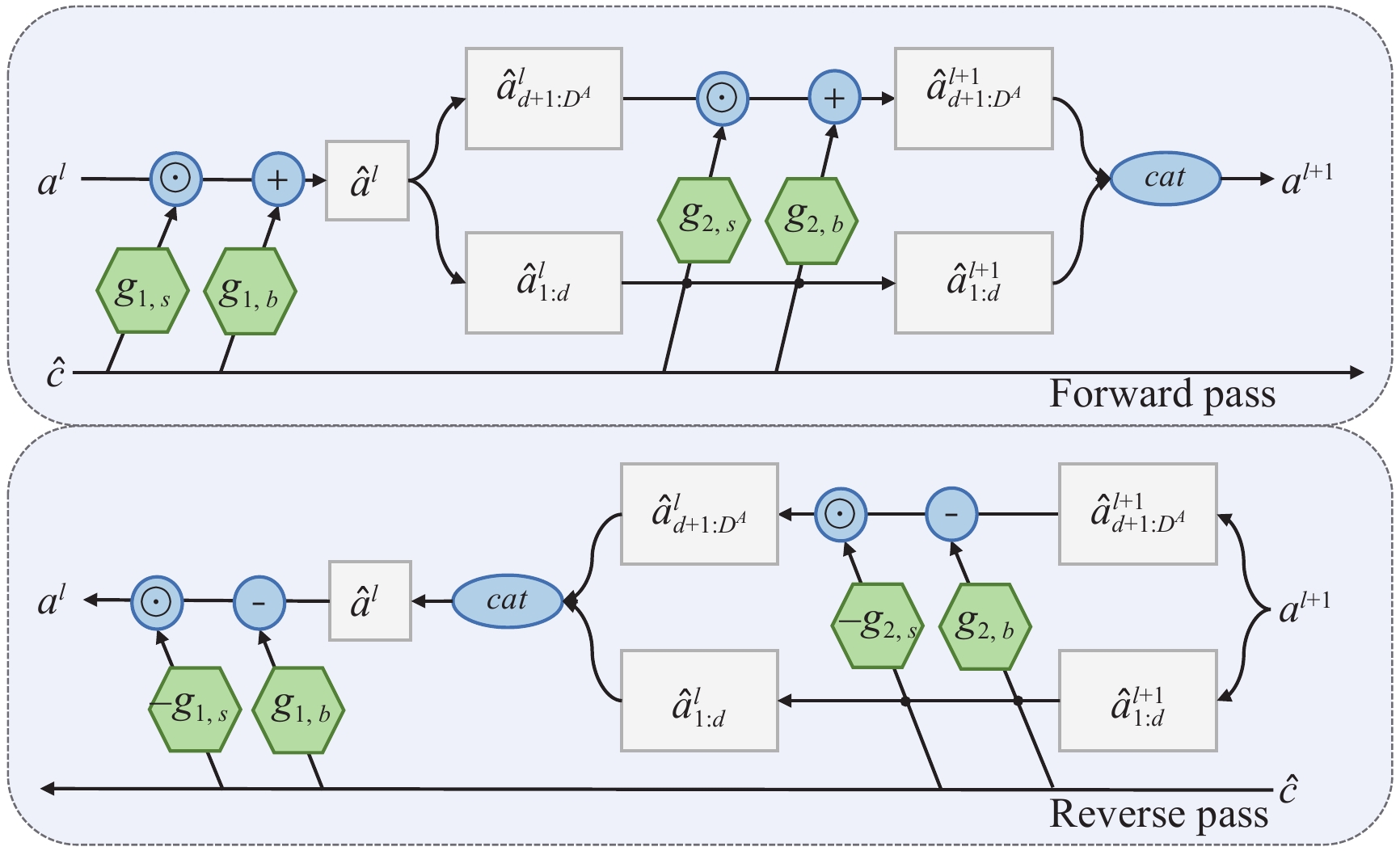
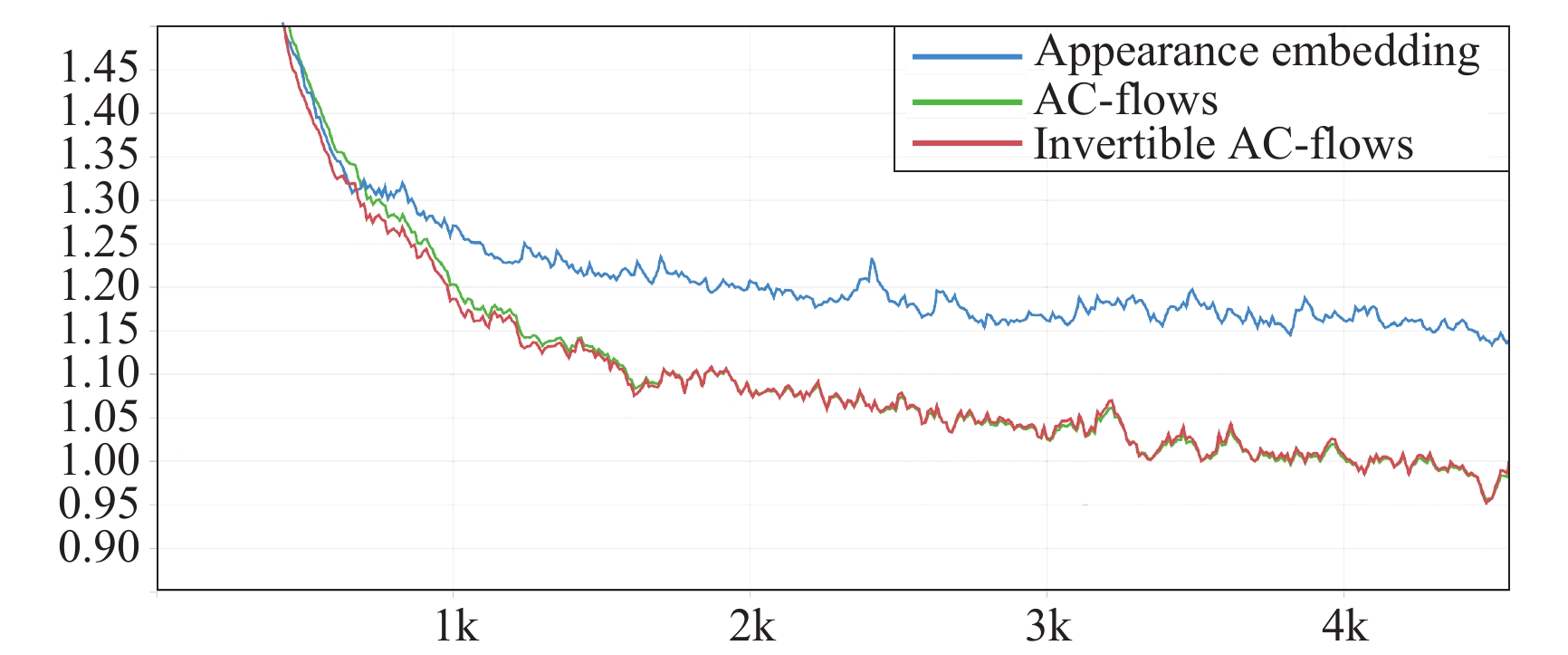
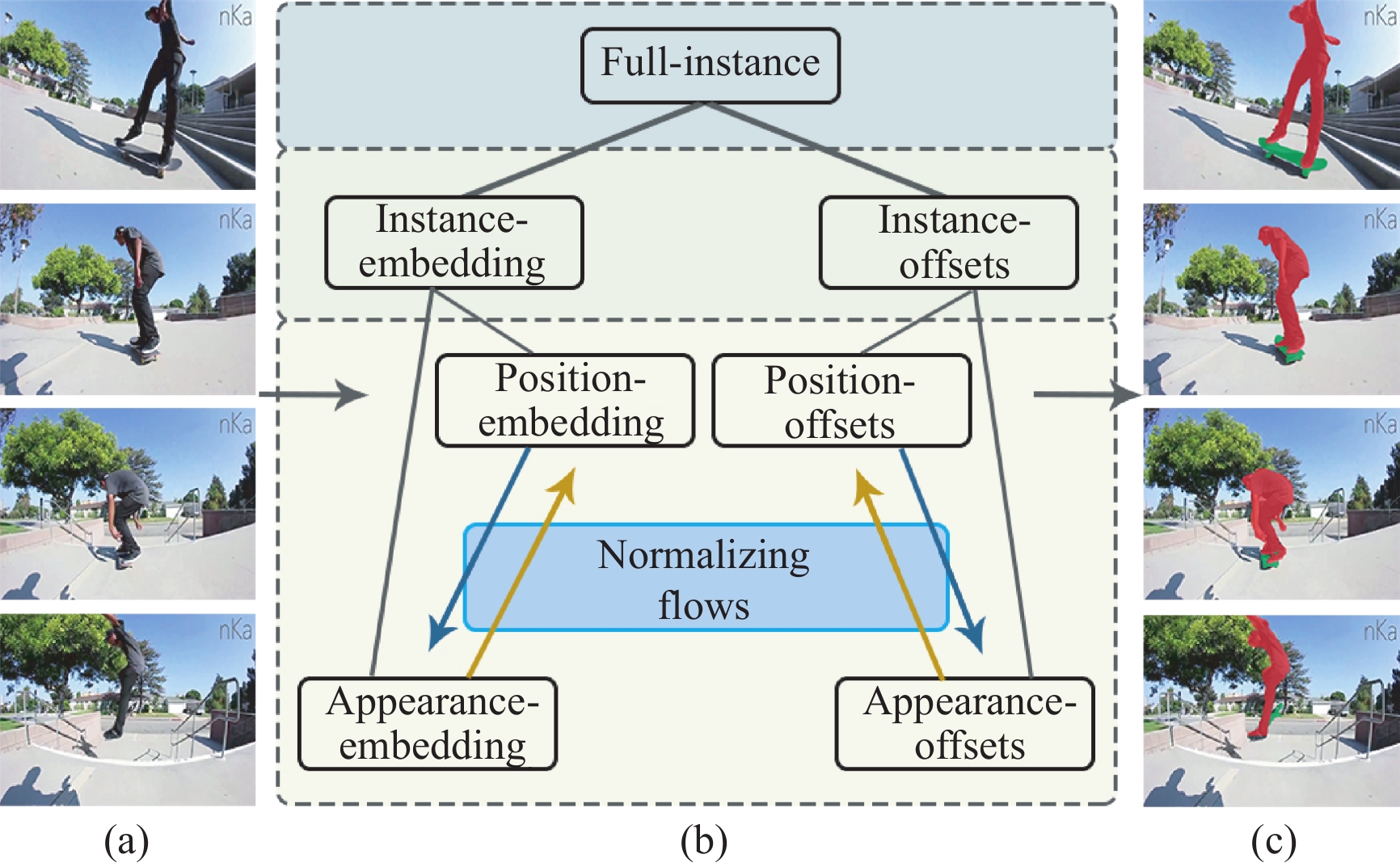
We introduce a novel method using a new generative model that automatically learns effective representations of the target and background appearance to detect, segment and track each instance in a video sequence. Differently from current discriminative tracking-by-detection solutions, our proposed hierarchical structural embedding learning can predict more high-quality masks with accurate boundary details over spatio-temporal space via the normalizing flows. We formulate the instance inference procedure as a hierarchical spatio-temporal embedded learning across time and space. Given the video clip, our method first coarsely locates pixels belonging to a particular instance with Gaussian distribution and then builds a novel mixing distribution to promote the instance boundary by fusing hierarchical appearance embedding information in a coarse-to-fine manner. For the mixing distribution, we utilize a factorization condition normalized flow fashion to estimate the distribution parameters to improve the segmentation performance. Comprehensive qualitative, quantitative, and ablation experiments are performed on three representative video instance segmentation benchmarks (i.e., YouTube-VIS19, YouTube-VIS21, and OVIS) and the effectiveness of the proposed method is demonstrated. More impressively, the superior performance of our model on an unsupervised video object segmentation dataset (i.e., DAVIS19) proves its generalizability. Our algorithm implementations are publicly available at
.

| [1] |
P. L. Huang, J. Han, N. Liu, J. Ren, and D. Zhang, “Scribble-supervised video object segmentation,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 2, pp. 339–353, 2021.
|
| [2] |
Z. Feng, L. Yan, Y. Xia, and B. Xiao, “An adaptive padding correlation filter with group feature fusion for robust visual tracking,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 10, pp. 1845–1860, 2022. doi: 10.1109/JAS.2022.105878
|
| [3] |
J. H. White and R. W. Beard, “An iterative pose estimation algorithm based on epipolar geometry with application to multi-target tracking,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 4, pp. 942–953, 2020. doi: 10.1109/JAS.2020.1003222
|
| [4] |
T. Zhou, F. Porikli, D. J. Crandall, L. Van Gool, and W. Wang, “A survey on deep learning technique for video segmentation,” IEEE Trans. Pattern Anal. Mach. Intell., 2022,
|
| [5] |
L. Yang, Y. Fan, and N. Xu, “Video instance segmentation,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2019, pp. 5188–5197.
|
| [6] |
Y. Liu, B. Jiang, and J. Xu, “Axial assembled correspondence network for few-shot semantic segmentation,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 3, pp. 702–712, 2023.
|
| [7] |
Y. Cui, L. Yan, Z. Cao, and D. Liu, “TF-Blender: Temporal feature blender for video object detection,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2021, pp. 8138–8147.
|
| [8] |
C. Wang, W. Pedrycz, Z. Li, and M. Zhou, “Residual-driven fuzzy cmeans clustering for image segmentation,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 4, pp. 876–889, 2020.
|
| [9] |
K. Liu, Z. Ye, H. Guo, D. Cao, L. Chen, and F.-Y. Wang, “Fiss GAN: A generative adversarial network for foggy image semantic segmentation,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 8, pp. 1428–1439, 2021. doi: 10.1109/JAS.2021.1004057
|
| [10] |
S. Yang, Y. Fang, X. Wang, Y. Li, C. Fang, Y. Shan, B. Feng, and W. Liu, “Crossover learning for fast online video instance segmentation,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2021, pp. 8043–8052.
|
| [11] |
J. Cao, R. M. Anwer, H. Cholakkal, F. S. Khan, Y. Pang, and L. Shao, “Sipmask: Spatial information preservation for fast image and video instance segmentation,” in Proc. Eur. Conf. Comput. Vis., 2020, pp. 1–18.
|
| [12] |
Y. Wang, Z. Xu, X. Wang, C. Shen, B. Cheng, H. Shen, and H. Xia, “End-to-end video instance segmentation with transformers,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2021, pp. 8741–8750.
|
| [13] |
J. Luiten, P. H. S. Torr, and B. Leibe, “Video instance segmentation 2019: A winning approach for combined detection, segmentation, classification and tracking,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. Workshops, 2019, pp. 709–712.
|
| [14] |
G. Bertasius and L. Torresani, “Classifying, segmenting, and tracking object instances in video with mask propagation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2020, pp. 9739–9748.
|
| [15] |
W. Wang, J. Shen, R. Yang, and F. Porikli, “Saliency-aware video object segmentation,” IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), vol. 40, no. 1, pp. 20–33, 2017.
|
| [16] |
Z. Qin, X. Lu, X. Nie, X. Zhen, and Y. Yin, “Learning hierarchical embeddings for videoinstance segmentation,” in Proc. ACM Inter. Conf. on Multimedia, 2021, pp. 1884–1892.
|
| [17] |
J. Ma, L. Tang, F. Fan, J. Huang, X. Mei, and Y. Ma, “SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 7, pp. 1200–1217, 2022. doi: 10.1109/JAS.2022.105686
|
| [18] |
Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2021, pp. 10012–10022.
|
| [19] |
C. Lin, Y. Hung, R. Feris, and L. He, “Video instance segmentation tracking with a modified VAE architecture,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2020, pp. 13147–13157.
|
| [20] |
J. Qi, Y. Gao, Y. Hu, X. Wang, X. Liu, X. Bai, S. Belongie, A. Yuille, H. Torr, and S. Bai, “Occluded video instance segmentation: A benchmark,” Int. Journal of Computer Vision, vol. 130, no. 8, 2022.
|
| [21] |
L. Tang, Y. Deng, Y. Ma, J. Huang, and J. Ma, “SuperFusion: A versatile image registration and fusion network with semantic awareness,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 12, pp. 2121–2137, 2022. doi: 10.1109/JAS.2022.106082
|
| [22] |
W. Wang, J. Liang, and D. Liu, “Learning equivariant segmentation with instance-unique querying,” in Proc. Adv. Neural Inf. Process. Syst., 2022.
|
| [23] |
W. Wang, J. Shen, F. Porikli, and R. Yang, “Semi-supervised video object segmentation with super-trajectories,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 4, pp. 985–998, 2018.
|
| [24] |
M. Dong, J. Wang, Y. Huang, D. Yu, K. Su, K. Zhou, J. Shao, S. Wen, and C. Wang, “Temporal feature augmented network for video instance segmentation,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. Workshops, 2019, pp. 721–724.
|
| [25] |
E. Mohamed, M. Ewaisha, M. Siam, H. Rashed, S. K. Yogamani, and A. E. Sallab, “InstanceMotSeg: Real-time instance motion segmentation for autonomous driving,” arXiv preprint arXiv: 2008.07008, 2020.
|
| [26] |
Q. Feng, Z. Yang, P. Li, Y. Wei, and Y. Yang, “Dual embedding learning for video instance segmentation,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. Workshops, 2019, pp. 717–720.
|
| [27] |
D. Kim, S. Woo, J. Lee, and I. S. Kweon, “Video panoptic segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2020, pp. 9859–9868.
|
| [28] |
X. Liu, H. Ren, and T. Ye, “Spatio-temporal attention network for video instance segmentation,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. Workshops, 2019, pp. 725–727.
|
| [29] |
L. Ke, X. Li, M. Danelljan, Y.-W. Tai, C.-K. Tang, and F. Yu, “Prototypical cross-attention networks for multiple object tracking and segmentation,” in Proc. Int. Conf. Neural Inf. Process. Syst., 2021, pp. 1192–1203.
|
| [30] |
Y. Fang, S. Yang, X. Wang, Y. Li, C. Fang, Y. Shan, B. Feng, and W. Liu, “Instances as queries,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2021, pp. 6910–6919.
|
| [31] |
A. S. Chakravarthy, W.-D. Jang, Z. Lin, D. Wei, S. Bai, and H. Pfister, “Object propagation via inter-frame attentions for temporally stable video instance segmentation,” 2021,
|
| [32] |
J. Wu, Y. Jiang, S. Bai, W. Zhang, and X. Bai, “SeqFormer: Sequential transformer for video instance segmentation,” in Proc. Eur. Conf. Comput. Vis. Springer, 2022, pp. 553–569.
|
| [33] |
K. He, G. Gkioxari, P. Dollár, and R. B. Girshick, “Mask R-CNN,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2017, pp. 2961–2969.
|
| [34] |
J. Wu, J. Cao, L. Song, Y. Wang, M. Yang, and J. Yuan, “Track to detect and segment: An online multi-object tracker,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2021, pp. 12352–12361.
|
| [35] |
D. Liu, Y. Cui, W. Tan, and Y. Chen, “SG-Net: Spatial granularity network for one-stage video instance segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2021, pp. 9816–9825.
|
| [36] |
T. Wang, N. Xu, K. Chen, and W. Lin, “End-to-end video instance segmentation via spatial-temporal graph neural networks,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2021, pp. 10777–10786.
|
| [37] |
Y. Fu, L. Yang, D. Liu, T. S. Huang, and H. Shi, “CompFeat: Comprehensive feature aggregation for video instance segmentation,” in Proc. AAAI Conf. Artif. Intell., vol. 1361–1369, 2021.
|
| [38] |
J. Cao, Y. Pang, R. M. Anwer, H. Cholakkal, F. S. Khan, and L. Shao, “SipMaskv2: Enhanced fast image and video instance segmentation,” IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), vol. 45, no. 3, pp. 3798–3812, 2023.
|
| [39] |
S. Hwang, M. Heo, S. W. Oh, and S. J. Kim, “Video instance segmentation using inter-frame communication transformers,” in Proc. Adv. Neural Inf. Process. Syst., vol. 34, pp. 13352–13363, 2021.
|
| [40] |
S. Yang, X. Wang, Y. Li, Y. Fang, J. Fang, W. Liu, X. Zhao, and Y. Shan, “Temporally efficient vision transformer for video instance segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2022, pp. 2885–2895.
|
| [41] |
J. Wu, S. Yarram, H. Liang, T. Lan, J. Yuan, J. Eledath, and G. Medioni, “Efficient video instance segmentation via tracklet query and proposal,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2022, pp. 959–968.
|
| [42] |
A. Athar, S. Mahadevan, A. Osep, L. Leal-Taixé, and B. Leibe, “Stem-seg: Spatio-temporal embeddings for instance segmentation in videos,” in Proc. Eur. Conf. Comput. Vis., 2020, pp. 158–177.
|
| [43] |
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. C. Courville, and Y. Bengio, “Generative adversarial networks,” arXiv preprint arXiv: 1406.2661, 2014.
|
| [44] |
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv: 1312.6114, 2013.
|
| [45] |
L. Dinh, D. Krueger, and Y. Bengio, “Nice: Non-linear independent components estimation,” arXiv preprint arXiv: 1410.8516, 2014.
|
| [46] |
L. Dinh, J. Sohl-Dickstein, and S. Bengio, “Density estimation using real NVP,” arXiv preprint arXiv: 1605.08803, 2016.
|
| [47] |
D. P. Kingma and P. Dhariwal, “Glow: Generative flow with invertible 1x1 convolutions,” in Proc. Adv. Neural Inf. Process. Syst., 2018, pp. 10236–10245.
|
| [48] |
J. Ho, X. Chen, A. Srinivas, Y. Duan, and P. Abbeel, “Flow++: Improving flow-based generative models with variational dequantization and architecture design,” in Proc. Int. Conf. Mach. Learn., 2019.
|
| [49] |
G. Papamakarios, E. T. Nalisnick, D. J. Rezende, S. Mohamed, and B. Lakshminarayanan, “Normalizing flows for probabilistic modeling and inference,” J. Mach. Learn. Res., vol. 22, no. 57, pp. 1–64, 2021.
|
| [50] |
L. Ardizzone, C. Lüth, J. Kruse, C. Rother, and U. Köthe, “Guided image generation with conditional invertible neural networks,” ArXiv, vol. abs/1907.02392, 2019.
|
| [51] |
C. Winkler, D. E. Worrall, E. Hoogeboom, and M. Welling, “Learning likelihoods with conditional normalizing flows,” arXiv preprint arXiv: 1912.00042, 2019.
|
| [52] |
A. Lugmayr, M. Danelljan, L. V. Gool, and R. Timofte, “SRFlow: Learning the super-resolution space with normalizing flow,” in Proc. Eur. Conf. Comput. Vis., 2020, pp. 715–732.
|
| [53] |
V. Wolf, A. Lugmayr, M. Danelljan, L. Van Gool, and R. Timofte, “DeFlow: Learning complex image degradations from unpaired data with conditional flows,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2021, pp. 94–103.
|
| [54] |
A. Abdelhamed, M. A. Brubaker, and M. S. Brown, “Noise Flow: Noise modeling with conditional normalizing flows,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2019, pp. 3165–3173.
|
| [55] |
Y. Liu, Z. Qin, S. Anwar, P. Ji, D. Kim, S. Caldwell, and T. Gedeon, “Invertible denoising network: A light solution for real noise removal,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2021, pp. 13365–13374.
|
| [56] |
A. Zanfir, E. G. Bazavan, H. Xu, W. T. Freeman, R. Sukthankar, and C. Sminchisescu, “Weakly supervised 3D human pose and shape reconstruction with normalizing flows,” in Proc. Eur. Conf. Comput. Vis., 2020, pp. 465–481.
|
| [57] |
A. Pumarola, S. Popov, F. Moreno-Noguer, and V. Ferrari, “C-Flow: Conditional generative flow models for images and 3d point clouds,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2020, pp. 7949–7958.
|
| [58] |
G. Yang, X. Huang, Z. Hao, M. Liu, S. J. Belongie, and B. Hariharan, “PointFlow: 3d point cloud generation with continuous normalizing flows,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2019, pp. 4541–4550.
|
| [59] |
H.-J. Chen, K.-M. Hui, S.-Y. Wang, L.-W. Tsao, H.-H. Shuai, and W.-H. Cheng, “Beautyglow: On-demand makeup transfer framework with reversible generative network,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., pp. 10042–10050, 2019.
|
| [60] |
J. Kim, S. Kim, J. Kong, and S. Yoon, “Glow-TTS: A generative flow for text-to-speech via monotonic alignment search,” ArXiv, vol. abs/2005.11129, 2020.
|
| [61] |
P. Jaini, I. Kobyzev, Y. Yu, and M. Brubaker, “Tails of Lipschitz triangular flows,” in Proc. Int. Conf. Mach. Learn., 2020, pp. 4673–4681.
|
| [62] |
Kirichenko, Izmailov, and A. G. Wilson, “Why normalizing flows fail to detect out-of-distribution data,” Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 33, pp. 20578–20589, 2020.
|
| [63] |
Y. Wang, R. Wan, W. Yang, H. Li, L.-P. Chau, and A. Kot, “Low-light image enhancement with normalizing flow,” in Proc. AAAI Conf. Artif. Intell., vol. 36, no. 3, 2022, pp. 2604–2612.
|
| [64] |
W. Wang, J. Shen, and F. Porikli, “Saliency-aware geodesic video object segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2015, pp. 3395–3402.
|
| [65] |
K. Fragkiadaki, G. Zhang, and J. Shi, “Video segmentation by tracing discontinuities in a trajectory embedding,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2012, pp. 1846–1853.
|
| [66] |
L. Chen, J. Shen, W. Wang, and B. Ni, “Video object segmentation via dense trajectories,” IEEE Trans. Multim., vol. 17, no. 12, pp. 2225–2234, 2015. doi: 10.1109/TMM.2015.2481711
|
| [67] |
Y. Jun Koh and C.-S. Kim, “Primary object segmentation in videos based on region augmentation and reduction,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2017, pp. 7417–7425.
|
| [68] |
S. Li, B. Seybold, A. Vorobyov, A. Fathi, Q. Huang, and C.-C. J. Kuo, “Instance embedding transfer to unsupervised video object segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 6526–6535.
|
| [69] |
P. Tokmakov, K. Alahari, and C. Schmid, “Learning motion patterns in videos,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2017, pp. 3386–3394.
|
| [70] |
J. Cheng, Y.-H. Tsai, S. Wang, and M.-H. Yang, “SegFlow: Joint learning for video object segmentation and optical flow,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2017, pp. 686–695.
|
| [71] |
M. Faisal, I. Akhter, M. Ali, and R. Hartley, “Exploiting geometric constraints on dense trajectories for motion saliency,” arXiv preprint arXiv: 1909.13258, 2019.
|
| [72] |
H. Li, G. Chen, G. Li, and Y. Yu, “Motion guided attention for video salient object detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2019, pp. 7274–7283.
|
| [73] |
T. Zhou, S. Wang, Y. Zhou, Y. Yao, J. Li, and L. Shao, “Motion-attentive transition for zero-shot video object segmentation,” in Proc. AAAI Conf. Artif. Intell., vol. 34, no. 7, 2020, pp. 13066–13073.
|
| [74] |
W. Wang, J. Shen, H. Sun, and L. Shao, “Video co-saliency guided co-segmentation,” IEEE Trans. Circuits Syst. Video Technol. (TCSVT), vol. 28, no. 8, pp. 1727–1736, 2017.
|
| [75] |
H. Song, W. Wang, S. Zhao, J. Shen, and K.-M. Lam, “Pyramid dilated deeper convlstm for video salient object detection,” in Proc. Eur. Conf. Comput. Vis., 2018, pp. 715–731.
|
| [76] |
D. J. Rezende and S. Mohamed, “Variational inference with normalizing flows,” in Proc. Int. Conf. Mach. Learn., vol. 37, 2015, pp. 1530–1538.
|
| [77] |
J. Yu and M. B. Blaschko, “Learning submodular losses with the Lovász hinge,” in Proc. Int. Conf. Mach. Learn., 2015, pp. 1623–1631.
|
| [78] |
L. Yang, Y. Wang, X. Xiong, J. Yang, and A. K. Katsaggelos, “Efficient video object segmentation via network modulation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 6499–6507.
|
| [79] |
N. Wojke, A. Bewley, and D. Paulus, “Simple online and realtime tracking with a deep association metric,” in Proc. IEEE Int. Conf. Image Process., 2017, pp. 3645–3649.
|
| [80] |
P. Voigtlaender, Y. Chai, F. Schroff, H. Adam, B. Leibe, and L. Chen, “FEELVOS: Fast end-to-end embedding learning for video object segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2019, pp. 9481–9490.
|
| [81] |
M. Li, S. Li, L. Li, and L. Zhang, “Spatial feature calibration and temporal fusion for effective one-stage video instance segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2021, pp. 11215–11224.
|
| [82] |
H. Lin, R. Wu, S. Liu, J. Lu, and J. Jia, “Video instance segmentation with a propose-reduce paradigm,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2021, pp. 1739–1748.
|
| [83] |
H. W. Kuhn, “The hungarian method for the assignment problem,” Naval Res. Logist. Quart, vol. 2, no. 1–2, pp. 83–97, 1955. doi: 10.1002/nav.3800020109
|
| [84] |
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 770–778.
|
| [85] |
L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, and L. V. Gool, “Temporal segment networks: Towards good practices for deep action recognition,” in Proc. Eur. Conf. Comput. Vis., 2016, pp. 20–36.
|
| [86] |
C. Ventura, M. Bellver, A. Girbau, A. Salvador, F. Marqués, and X. Giró-i-Nieto, “RVOS: End-to-end recurrent network for video object segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2019, pp. 5277–5286.
|
| [87] |
W. Wang, H. Song, S. Zhao, J. Shen, S. Zhao, S. C. H. Hoi, and H. Ling, “Learning unsupervised video object segmentation through visual attention,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2019, pp. 3064–3074.
|
| [88] |
D. Cho, S. Hong, S. Kang, and J. Kim, “Key instance selection for unsupervised video object segmentation,” arXiv preprint arXiv: 1906.07851, 2019.
|
| [89] |
W. Wang, X. Lu, J. Shen, D. J. Crandall, and L. Shao, “Zero-shot video object segmentation via attentive graph neural networks,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2019, pp. 9236–9245.
|
| [90] |
S. Caelles, J. Pont-Tuset, F. Perazzi, A. Montes, K.-K. Maninis, and L. Van Gool, “The 2019 davis challenge on VOS: Unsupervised multiobject segmentation,” arXiv preprint arXiv: 1905.00737, 2019.
|
| [91] |
D. Munoz, N. Vandapel, and M. Hebert, “Onboard contextual classification of 3-d point clouds with learned high-order Markov random fields,” in Proc. IEEE Int. Conf. Robotics & Automation, 2009, pp. 2009–2016.
|
| [92] |
S. Caelles, A. Montes, K. Maninis, Y. Chen, L. V. Gool, F. Perazzi, and J. Pont-Tuset, “The 2018 DAVIS challenge on video object segmentation,” arXiv preprint arXiv: 1803.00557, 2018.
|
| [93] |
W. Wang, J. Shen, X. Lu, S. C. H. Hoi, and H. Ling, “Paying attention to video object pattern understanding,” IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), vol. 43, no. 7, pp. 2413–2428, 2021. doi: 10.1109/TPAMI.2020.2966453
|
| [94] |
F. Perazzi, J. Pont-Tuset, B. McWilliams, L. V. Gool, M. H. Gross, and A. Sorkine-Hornung, “A benchmark dataset and evaluation methodology for video object segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 724–732.
|
| [95] |
J. Pont-Tuset, F. Perazzi, S. Caelles, P. Arbelaez, A. Sorkine-Hornung, and L. V. Gool, “The 2017 DAVIS challenge on video object segmentation,” arXiv preprint arXiv: 1704.00675, 2017.
|
Figures(8) / Tables(7)






 DownLoad:
DownLoad: