A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 12
Issue 12
Volume 12
Issue 12
IEEE/CAA Journal of Automatica Sinica
| Citation: | Z. Hu, Z. Peng, Z. Bi, Q. Shen, Z. Liu, J. Lou, and X. Luo, “Advancing healthcare with large language models: Techniques and application,” IEEE/CAA J. Autom. Sinica, vol. 12, no. 12, pp. 2371–2398, Dec. 2025. doi: 10.1109/JAS.2025.125540

|

| [1] |
X. Gao, W. Chen, L. Guo, T. Zhang, and H. Zhao, “Asymptomatic infection of COVID-19 and its challenge to epidemic prevention and control,” Chin. J. Epidemiol., vol. 41, no. 12, pp. 1985–1988, Dec. 2020. doi: 10.3760/cma.j.cn112338-20200427-00659
|
| [2] |
J. Anibal, H. Huth, M. Li, L. Hazen, V. Daoud, D. Ebedes, Y. M. Lam, H. Nguyen, P. V. Hong, M. Kleinman, et al., “Voice EHR: Introducing multimodal audio data for health,” Front. Digit. Health, vol. 6, p. 1448351, Jan. 2025. doi: 10.3389/fdgth.2024.1448351
|
| [3] |
T.-C. Lee, K. Staller, V. Botoman, M. P. Pathipati, S. Varma, and B. Kuo, “ChatGPT answers common patient questions about colonoscopy,” Gastroenterology, vol. 165, no. 2, pp. 509–511.e7, Aug. 2023. doi: 10.1053/j.gastro.2023.04.033
|
| [4] |
E. Smyrnakis, D. Symintiridou, M. Andreou, M. Dandoulakis, E. Theodoropoulos, S. Kokkali, C. Manolaki, D. I. Papageorgiou, C. Birtsou, A. Paganas, et al., “Primary care professionals’ experiences during the first wave of the COVID-19 pandemic in Greece: A qualitative study,” BMC Fam. Pract., vol. 22, no. 1, p. 174, Sep. 2021. doi: 10.1186/s12875-021-01522-9
|
| [5] |
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al., “Language models are few-shot learners,” in Proc. 34th Int. Conf. Neural Information Processing Systems, Vancouver, Canada, 2020, pp. 159.
|
| [6] |
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. 31st Int. Conf. Neural Information Processing Systems, Long Beach, USA, 2017, pp. 6000−6010.
|
| [7] |
Y. Li, Z. Li, K. Zhang, R. Dan, S. Jiang, and Y. Zhang, “ChatDoctor: A medical chat model fine-tuned on a large language model meta-AI (llama) using medical domain knowledge,” Cureus, vol. 15, no. 6, p. e40895, Jun. 2023.
|
| [8] |
J. Li, S. Zhong, and K. Chen, “MLEC-QA: A Chinese multi-choice biomedical question answering dataset,” in Proc. Conf. Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 2021, pp. 8862−8874, DOI: 10.18653/v1/2021.emnlp-main.698.
|
| [9] |
C. Basu, H. Garg, A. McIntosh, S. Sablak, and J. R. Wullert Ⅱ, “Using weak supervision and data augmentation in question answering,” arXiv preprint arXiv: 2309.16175, 2023, DOI: 10.48550/arXiv.2309.16175.
|
| [10] |
J. W. Ayers, A. Poliak, M. Dredze, E. C. Leas, Z. Zhu, J. B. Kelley, D. J. Faix, A. M. Goodman, C. A. Longhurst, M. Hogarth, et al., “Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum,” JAMA Intern. Med., vol. 183, no. 6, pp. 589–596, Apr. 2023. doi: 10.1001/jamainternmed.2023.1838
|
| [11] |
J. Haltaufderheide and R. Ranisch, “The ethics of ChatGPT in medicine and healthcare: A systematic review on large language models (LLMs),” NPJ Digit. Med., vol. 7, no. 1, p. 183, Jul. 2024. doi: 10.1038/s41746-024-01157-x
|
| [12] |
N. Neveditsin, P. Lingras, and V. Mago, “Clinical insights: A comprehensive review of language models in medicine,” PLoS Digit. Health, vol. 4, no. 5, p. e0000800, May 2025. doi: 10.1371/journal.pdig.0000800
|
| [13] |
H. Yu, L. Fan, L. Li, J. Zhou, Z. Ma, L. Xian, W. Hua, S. He, M. Jin, Y. Zhang, et al., “Large language models in biomedical and health informatics: A review with bibliometric analysis,” J. Healthc. Inform. Res., vol. 8, no. 4, pp. 658–711, Sep. 2024. doi: 10.1007/s41666-024-00171-8
|
| [14] |
Z. Guo, A. Lai, J. H. Thygesen, J. Farrington, T. Keen, and K. Li, “Large language models for mental health applications: Systematic review,” JMIR Ment. Health, vol. 11, p. e57400, Oct. 2024. doi: 10.2196/57400
|
| [15] |
H. R. Lawrence, R. A. Schneider, S. B. Rubin, M. J. Matarić, D. J. McDuff, and M. J. Bell, “The opportunities and risks of large language models in mental health,” JMIR Ment. Health, vol. 11, p. e59479, Jul. 2024. doi: 10.2196/59479
|
| [16] |
V. Viswanathan, K. Gashteovski, C. Lawrence, T. Wu, and G. Neubig, “Large language models enable few-shot clustering,” Trans. Assoc. Comput. Linguist., vol. 12, pp. 321–333, Apr. 2024. doi: 10.1162/tacl_a_00648
|
| [17] |
K. Lee, D. Ippolito, A. Nystrom, C. Zhang, D. Eck, C. Callison-Burch, and N. Carlini, “Deduplicating training data makes language models better,” in Proc. 60th Annu. Meeting of the Association for Computational Linguistics, Dublin, Ireland, 2022, pp. 8424−8445, DOI: 10.18653/v1/2022.acl-long.577.
|
| [18] |
M. Li, Y. Zhang, Z. Li, J. Chen, L. Chen, N. Cheng, J. Wang, T. Zhou, and J. Xiao, “From quantity to quality: Boosting LLM performance with self-guided data selection for instruction tuning,” in Proc. Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Mexico City, Mexico, 2024, pp. 7602−7635.
|
| [19] |
J. Yuan, R. Tang, X. Jiang, and X. Hu, “LLM for patient-trial matching: Privacy-aware data augmentation towards better performance and generalizability,” arXiv preprint arXiv: 2303.16756, 2023.
|
| [20] |
K. Yang, Y. Ding, H. Jiang, H. Zhao, and G. Luo, “A two-stage data cleansing method for bridge global positioning system monitoring data based on bi-direction long and short term memory anomaly identification and conditional generative adversarial networks data repair,” Struct. Control Health Monit., vol. 29, no. 9, p. e2993, May 2022.
|
| [21] |
X. Shen, S. Ma, P. J. Caraballo, P. Vemuri, and G. J. Simon, “A novel method for handling missing not at random data in the electronic health records,” in Proc. IEEE 10th Int. Conf. Healthcare Informatics, Rochester, USA, 2022, pp. 21−26, DOI: 10.1109/ICHI54592.2022.00015.
|
| [22] |
N. S. Pagad, P. N, K. K. Almuzaini, M. Maheshwari, D. Gangodkar, P. Shukla, and M. Alhassan, “Clinical text data categorization and feature extraction using medical-fissure algorithm and neg-seq algorithm,” Comput. Intell. Neurosci., vol. 2022, p. 5759521, Mar. 2022.
|
| [23] |
Q. Jin, W. Ma, W. Zhang, H. Wang, Y. Geng, Y. Geng, Y. Zhang, D. Gao, J. Zhou, L. Li, et al., “Clinical and hematological characteristics of children infected with the omicron variant of SARS-CoV-2: Role of the combination of the neutrophil: Lymphocyte ratio and eosinophil count in distinguishing severe COVID-19,” Front. Pediatr., vol. 12, p. 1305639, Jun. 2024. doi: 10.3389/fped.2024.1305639
|
| [24] |
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” J. Mach. Learn. Res., vol. 21, no. 1, p. 140, Jan. 2020.
|
| [25] |
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, R. Avila, et al., “GPT-4 technical report,” arXiv preprint arXiv: 2303.08774, 2023, DOI: 10.48550/arXiv.2303.08774.
|
| [26] |
M. Lewis, Y. Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V. Stoyanov, and L. Zettlemoyer, “BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension,” in Proc. 58th Annu. Meeting of the Association for Computational Linguistics, Online, 2019, pp. 7871−7880.
|
| [27] |
Y. Si and K. Roberts, “Three-level hierarchical transformer networks for long-sequence and multiple clinical documents classification,” arXiv preprint arXiv: 2104.08444, 2021.
|
| [28] |
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, et al., “Mistral 7B,” arXiv preprint arXiv: 2310.06825, 2023, DOI: 10.48550/arXiv.2310.06825.
|
| [29] |
D. Hendrycks and K. Gimpel, “Gaussian error linear units (GELUs),” arXiv preprint arXiv: 1606.08415, 2023.
|
| [30] |
K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification,” in Proc. IEEE Int. Conf. Computer Vision, Santiago, Chile, 2015, pp. 1026−1034.
|
| [31] |
X. Glorot and Y. Bengio, “Understanding the difficulty of training deep feedforward neural networks,” in Proc. Thirteenth Int. Conf. Artificial Intelligence and Statistics, Sardinia, Italy, 2010, pp. 249−256.
|
| [32] |
A. Sergeev and M. D. Balso, “Horovod: Fast and easy distributed deep learning in TensorFlow,” arXiv preprint arXiv: 1802.05799, 2018.
|
| [33] |
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in Proc. 3rd Int. Conf. Learning Representations, San Diego, CA, USA, 2015.
|
| [34] |
I. Loshchilov and F. Hutter, “SGDR: Stochastic gradient descent with warm restarts,” in Proc. 5th Int. Conf. Learning Representations, Toulon, France, 2017.
|
| [35] |
T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama, “Optuna: A next-generation hyperparameter optimization framework,” in Proc. 25th ACM SIGKDD Int. Conf. Knowledge Discovery & Data Mining, Anchorage, AK, USA, 2019, pp. 2623−2631, DOI: 10.1145/3292500.3330701.
|
| [36] |
J. Bergstra, D. Yamins, and D. D. Cox, “Hyperopt: A python library for optimizing the hyperparameters of machine learning algorithms,” in Proc. 12th Python in Science Conf., Austin, USA, 2013, pp. 13−19.
|
| [37] |
R. Kohavi, “A study of cross-validation and bootstrap for accuracy estimation and model selection,” in Proc. 14th Int. Joint Conf. Artificial Intelligence, Montreal, Canada, 1995, pp. 1137−1143.
|
| [38] |
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, et al., “LLaMa: Open and efficient foundation language models,” arXiv preprint arXiv: 2302.13971, 2023, DOI: 10.48550/arXiv.2302.13971.
|
| [39] |
T. L. Scao, A. Fan, C. Akiki, E. Pavlick, S. Ilić, D. Hesslow, R. Castagne, A. S. Luccioni, F. Yvon, M. Gallé, et al., “BLOOM: A 176B-parameter open-access multilingual language model,” arXiv preprint arXiv: 2211.05100, 2022, DOI: 10.48550/arXiv.2211.05100.
|
| [40] |
E. Waisberg, J. Ong, M. Masalkhi, and A. G. Lee, “Large language model (LLM)-driven chatbots for neuro-ophthalmic medical education,” Eye, vol. 38, no. 4, pp. 639–641, Sep. 2024. doi: 10.1038/s41433-023-02759-7
|
| [41] |
Gemini Team Google, “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,” arXiv preprint arXiv: 2403.05530, 2024, DOI: 10.48550/arXiv.2403.05530.
|
| [42] |
Anthropic. "The claude 3 model family: Opus, sonnet, haiku," 2024. Corpus ID: 268232499.
|
| [43] |
S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V. Lin, et al., “OPT: Open pre-trained transformer language models,” arXiv preprint arXiv: 2205.01068, 2022, DOI: 10.48550/arXiv.2205.01068.
|
| [44] |
T. Tu, S. Azizi, D. Driess, M. Schaekermann, M. Amin, P.-C. Chang, A. Carroll, C. Lau, R. Tanno, I. Ktena, et al., “Towards generalist biomedical AI,” NEJM AI, vol. 1, no. 3, p. AIoa2300138, Feb. 2024. doi: 10.1056/AIoa2300138
|
| [45] |
Y. Labrak, A. Bazoge, E. Morin, P.-A. Gourraud, M. Rouvier, and R. Dufour, “BioMistral: A collection of open-source pretrained large language models for medical domains,” in Proc. Findings of the Association for Computational Linguistics, Bangkok, Thailand, 2024, pp. 5848−5864.
|
| [46] |
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” in Proc. Tenth Int. Conf. Learning Representations, Virtual, 2022.
|
| [47] |
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for NLP,” in Proc. 36th Int. Conf. Machine Learning, Long Beach, USA, 2019, pp. 2790−2799.
|
| [48] |
Z. Hu, L. Wang, Y. Lan, W. Xu, E.-P. Lim, L. Bing, X. Xu, S. Poria, and R. Lee, “LLM-adapters: An adapter family for parameter-efficient fine-tuning of large language models,” in Proc. Conf. Empirical Methods in Natural Language Processing, Singapore, Singapore, 2023, pp. 5254−5276.
|
| [49] |
O. Rohanian, H. Jauncey, M. Nouriborji, V. Kumar, B. P. Gonalves, C. Kartsonaki, Isaric Clinical Characterisation Group, L. Merson, and D. Clifton, “Using bottleneck adapters to identify cancer in clinical notes under low-resource constraints,” in Proc. 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks, Toronto, Canada, 2023, pp. 62−78.
|
| [50] |
B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,” in Proc. Conf. Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 2021, pp. 3045−3059, DOI: 10.18653/v1/2021.emnlp-main.243.
|
| [51] |
X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,” in Proc. 59th Annu. Meeting of the Association for Computational Linguistics and the 11th Int. Joint Conf. Natural Language Processing, Online, 2021, pp. 4582−4597, DOI: 10.18653/v1/2021.acl-long.353
|
| [52] |
X. Liu, Y. Zheng, Z. Du, M. Ding, Y. Qian, Z. Yang, and J. Tang, “GPT understands, too,” AI Open, vol. 5, pp. 208–215, 2024. doi: 10.1016/j.aiopen.2023.08.012
|
| [53] |
X. Liu, K. Ji, Y. Fu, W. Tam, Z. Du, Z. Yang, and J. Tang, “P-Tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks,” in Proc. 60th Annu. Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Dublin, Ireland, 2022, pp. 61−68.
|
| [54] |
C. Liu, K. Sun, Q. Zhou, Y. Duan, J. Shu, H. Kan, Z. Gu, and J. Hu, “CPMI-ChatGLM: Parameter-efficient fine-tuning ChatGLM with Chinese patent medicine instructions,” Sci. Rep., vol. 14, no. 1, p. 6403, 2024. doi: 10.1038/s41598-024-56874-w
|
| [55] |
V. Sanh, A. Webson, C. Raffel, S. Bach, L. Sutawika, Z. Alyafeai, A. Chaffin, A. Stiegler, A. Raja, M. Dey, et al., “Multitask prompted training enables zero-shot task generalization,” in Proc. Tenth Int. Conf. Learning Representations, Virtual, 2022.
|
| [56] |
C. Song, Z. Zhou, J. Yan, Y. Fei, Z. Lan, and Y. Zhang, “Dynamics of instruction tuning: Each ability of large language models has its own growth pace,” arXiv preprint arXiv: 2310.19651, 2024.
|
| [57] |
D. Yuan, E. Rastogi, G. Naik, S. P. Rajagopal, S. Goyal, F. Zhao, B. Chintagunta, and J. Ward, “A continued pretrained LLM approach for automatic medical note generation,” in Proc. Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), Mexico City, Mexico, 2024, pp. 565−571.
|
| [58] |
C. Wu, W. Lin, X. Zhang, Y. Zhang, W. Xie, and Y. Wang, “PMC-LLaMA: Toward building open-source language models for medicine,” J. Am. Med. Inform. Assoc., vol. 31, no. 9, pp. 1833–1843, Sep. 2024. doi: 10.1093/jamia/ocae045
|
| [59] |
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-T. Yih, T. Rocktäschel, et al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Proc. 34th Int. Conf. Neural Information Processing Systems, Vancouver, Canada, 2020, pp. 793.
|
| [60] |
V. Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W.-T. Yih, “Dense passage retrieval for open-domain question answering,” in Proc. Conf. Empirical Methods in Natural Language Processing, 2020, pp. 6769−6781.
|
| [61] |
Y. Shi, S. Xu, T. Yang, Z. Liu, T. Liu, X. Li, and N. Liu, “Mkrag: Medical knowledge retrieval augmented generation for medical question answering,” AMIA Annu. Symp. Proc., vol. 2024, pp. 1011–1020, May 2025.
|
| [62] |
J. Ge, S. Sun, J. Owens, V. Galvez, O. Gologorskaya, J. C. Lai, M. J. Pletcher, and K. Lai, “Development of a liver disease-specific large language model chat interface using retrieval-augmented generation,” Hepatology, vol. 80, no. 5, pp. 1158–1168, Nov. 2024. doi: 10.1097/HEP.0000000000000834
|
| [63] |
T. Wu, S. He, J. Liu, S. Sun, K. Liu, Q.-L. Han, and Y. Tang, “A brief overview of ChatGPT: The history, status quo and potential future development,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 5, pp. 1122–1136, May 2023. doi: 10.1109/JAS.2023.123618
|
| [64] |
F. Remy, K. Demuynck, and T. Demeester, “BioLORD-2023: Semantic textual representations fusing large language models and clinical knowledge graph insights,” J. Am. Med. Inform. Assoc., vol. 31, no. 9, pp. 1844–1855, Sep. 2024. doi: 10.1093/jamia/ocae029
|
| [65] |
Y. Qin, S. Hu, Y. Lin, W. Chen, N. Ding, G. Cui, Z. Zeng, X. Zhou, Y. Huang, C. Xiao, et al., “Tool learning with foundation models,” ACM Comput. Surv., vol. 57, no. 4, p. 101, Dec. 2024. doi: 10.1145/3704435
|
| [66] |
Q. Jin, Z. Wang, Y. Yang, Q. Zhu, D. Wright, T. Huang, W. J. Wilbur, Z. He, A. Taylor, Q. Chen, et al., “AgentMD: Empowering language agents for risk prediction with large-scale clinical tool learning,” arXiv preprint arXiv: 2402.13225, 2024.
|
| [67] |
R. Srivastava, L. Bhat, S. Prasad, S. Deshpande, B. Das, and K. Jadhav, “MedPromptExtract (medical data extraction tool): Anonymization and high-fidelity automated data extraction using natural language processing and prompt engineering,” J. Appl. Lab. Med., 2025, DOI: 10.1093/jalm/jfaf034.
|
| [68] |
A. Bisercic, M. Nikolic, M. van der Schaar, B. Delibasic, P. Lio, and A. Petrovic, “Interpretable medical diagnostics with structured data extraction by large language models,” arXiv preprint arXiv: 2306.05052, 2023, DOI: 10.48550/arXiv.2306.05052.
|
| [69] |
Y. Zhu, C. Ren, S. Xie, S. Liu, H. Ji, Z. Wang, T. Sun, L. He, Z. Li, X. Zhu, et al., “REALM: RAG-driven enhancement of multimodal electronic health records analysis via large language models,” arXiv preprint arXiv: 2402.07016, 2024, DOI: 10.48550/arXiv.2402.07016.
|
| [70] |
Z. Jiang, F. F. Xu, J. Araki, and G. Neubig, “How can we know what language models know?,” Trans. Assoc. Comput. Linguist., vol. 8, pp. 423–438, 2020. doi: 10.1162/tacl_a_00324
|
| [71] |
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” in Proc. 36th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2022, pp. 1800.
|
| [72] |
T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa, “Large language models are zero-shot reasoners,” in Proc. 36th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2022, pp. 1613.
|
| [73] |
Z. Wu, A. Hasan, J. Wu, Y. Kim, J. Cheung, T. Zhang, and H. Wu, “KnowLab_AIMed at MEDIQA-CORR 2024: Chain-of-though (CoT) prompting strategies for medical error detection and correction,” in Proc. 6th Clinical Natural Language Processing Workshop, Mexico City, Mexico, 2024, pp. 353−359.
|
| [74] |
T. Kwon, K. T.-I. Ong, D. Kang, S. Moon, J. R. Lee, D. Hwang, B. Sohn, Y. Sim, D. Lee, and J. Yeo, “Large language models are clinical reasoners: Reasoning-aware diagnosis framework with prompt-generated rationales,” in Proc. Thirty-Eighth AAAI Conf. Artificial Intelligence, Vancouver, Canada, 2024, pp. 18417−18425, DOI: 10.1609/aaai.v38i16.29802.
|
| [75] |
X. Wang, J. Wei, D. Schuurmans, Q. V. Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” in Proc. Eleventh Int. Conf. Learning Representations, Kigali, Rwanda, 2023.
|
| [76] |
S. Gundabathula and S. Kolar, “PromptMind team at MEDIQA-CORR 2024: Improving clinical text correction with error categorization and LLM ensembles,” in Proc. 6th Clinical Natural Language Processing Workshop, Mexico City, Mexico, 2024, pp. 367−373.
|
| [77] |
M. M. Lucas, J. Yang, J. K. Pomeroy, and C. C. Yang, “Reasoning with large language models for medical question answering,” J. Am. Med. Inform. Assoc., vol. 31, no. 9, pp. 1964–1975, Sep. 2024. doi: 10.1093/jamia/ocae131
|
| [78] |
S. S. Nachane, O. Gramopadhye, P. Chanda, G. Ramakrishnan, K. S. Jadhav, Y. Nandwani, D. Raghu, and S. Joshi, “Few shot chain-of-thought driven reasoning to prompt LLMs for open-ended medical question answering,” in Proc. Findings of the Association for Computational Linguistics, Miami, USA, 2024, pp. 542−573.
|
| [79] |
T. H. Kung, M. Cheatham, A. Medenilla, C. Sillos, L. De Leon, C. Elepaño, M. Madriaga, R. Aggabao, G. Diaz-Candido, J. Maningo, and V. Tseng, “Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models,” PLoS Digit. Health, vol. 2, no. 2, p. e0000198, Feb. 2023. doi: 10.1371/journal.pdig.0000198
|
| [80] |
D. Jin, E. Pan, N. Oufattole, W.-H. Weng, H. Fang, and P. Szolovits, “What disease does this patient have? A large-scale open domain question answering dataset from medical exams,” Appl. Sci., vol. 11, no. 14, p. 6421, Jul. 2021. doi: 10.3390/app11146421
|
| [81] |
Q. Jin, B. Dhingra, Z. Liu, W. Cohen, and X. Lu, “PubMedQA: A dataset for biomedical research question answering,” in Proc. Conf. Empirical Methods in Natural Language Processing and the 9th Int. Joint Conf. Natural Language Processing, Hong Kong, China, 2019, pp. 2567−2577.
|
| [82] |
A. E. W. Johnson, T. J. Pollard, L. Shen, L.-W. H. Lehman, M. Feng, M. Ghassemi, B. Moody, P. Szolovits, L. A. Celi, and R. G. Mark, “MIMIC-Ⅲ, a freely accessible critical care database,” Sci. Data, vol. 3, no. 1, p. 160035, May 2016. doi: 10.1038/sdata.2016.35
|
| [83] |
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,” in Proc. 9th Int. Conf. Learning Representations, Austria, Virtual, 2021.
|
| [84] |
A. Pal, L. K. Umapathi, and M. Sankarasubbu, “MedMCQA: A large-scale multi-subject multi-choice dataset for medical domain question answering,” in Proc. Conf. Health, Inference, and Learning, Virtual. 2022, pp. 248−260.
|
| [85] |
S. L. Fleming, A. Lozano, W. J. Haberkorn, Jenelle A. Jindal, Eduardo Reis, Rahul Thapa, Louis Blankemeier, Julian Z. Genkins, E. Steinberg, A. Nayak, et al., “MedAlign: A clinician-generated dataset for instruction following with electronic medical records,” in Proc. Thirty-Eighth AAAI Conf. Artificial Intelligence, Vancouver, Canada, 2024, pp. 22021−22030, DOI: 10.1609/aaai.v38i20.30205.
|
| [86] |
A. Romanov and C. Shivade, “Lessons from natural language inference in the clinical domain,” in Proc. Conf. Empirical Methods in Natural Language Processing, Brussels, Belgium, 2018, pp. 1586−1596.
|
| [87] |
K. Singhal, S. Azizi, T. Tu, S. S. Mahdavi, J. Wei, H. W. Chung, N. Scales, A. Tanwani, H. Cole-Lewis, S. Pfohl, et al., “Large language models encode clinical knowledge,” Nature, vol. 620, no. 7972, pp. 172–180, Jul. 2023. doi: 10.1038/s41586-023-06291-2
|
| [88] |
N. Zhang, M. Chen, Z. Bi, X. Liang, L. Li, X. Shang, K. Yin, C. Tan, J. Xu, F. Huang, et al., “CBLUE: A Chinese biomedical language understanding evaluation benchmark,” in Proc. 60th Annu. Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 2022, pp. 7888−7915, DOI: 10.18653/v1/2022.acl-long.544.
|
| [89] |
J. Eckrich, J. Ellinger, A. Cox, J. Stein, M. Ritter, A. Blaikie, S. Kuhn, and C. R. Buhr, “Urology consultants versus large language models: Potentials and hazards for medical advice in urology,” BJUI Compass, vol. 5, no. 5, pp. 552–558, May 2024. doi: 10.1002/bco2.359
|
| [90] |
S. Sivarajkumar, F. Gao, P. Denny, B. Aldhahwani, S. Visweswaran, A. Bove, and Y. Wang, “Mining clinical notes for physical rehabilitation exercise information: Natural language processing algorithm development and validation study,” JMIR Med. Inform., vol. 12, p. e52289, Apr. 2024. doi: 10.2196/52289
|
| [91] |
E. C. Acikgoz, O. B. İnce, R. Bench, A. A. Boz, İ. Kesen, A. Erdem, and E. Erdem, “Hippocrates: An open-source framework for advancing large language models in healthcare,” arXiv preprint arXiv: 2404.16621, 2024.
|
| [92] |
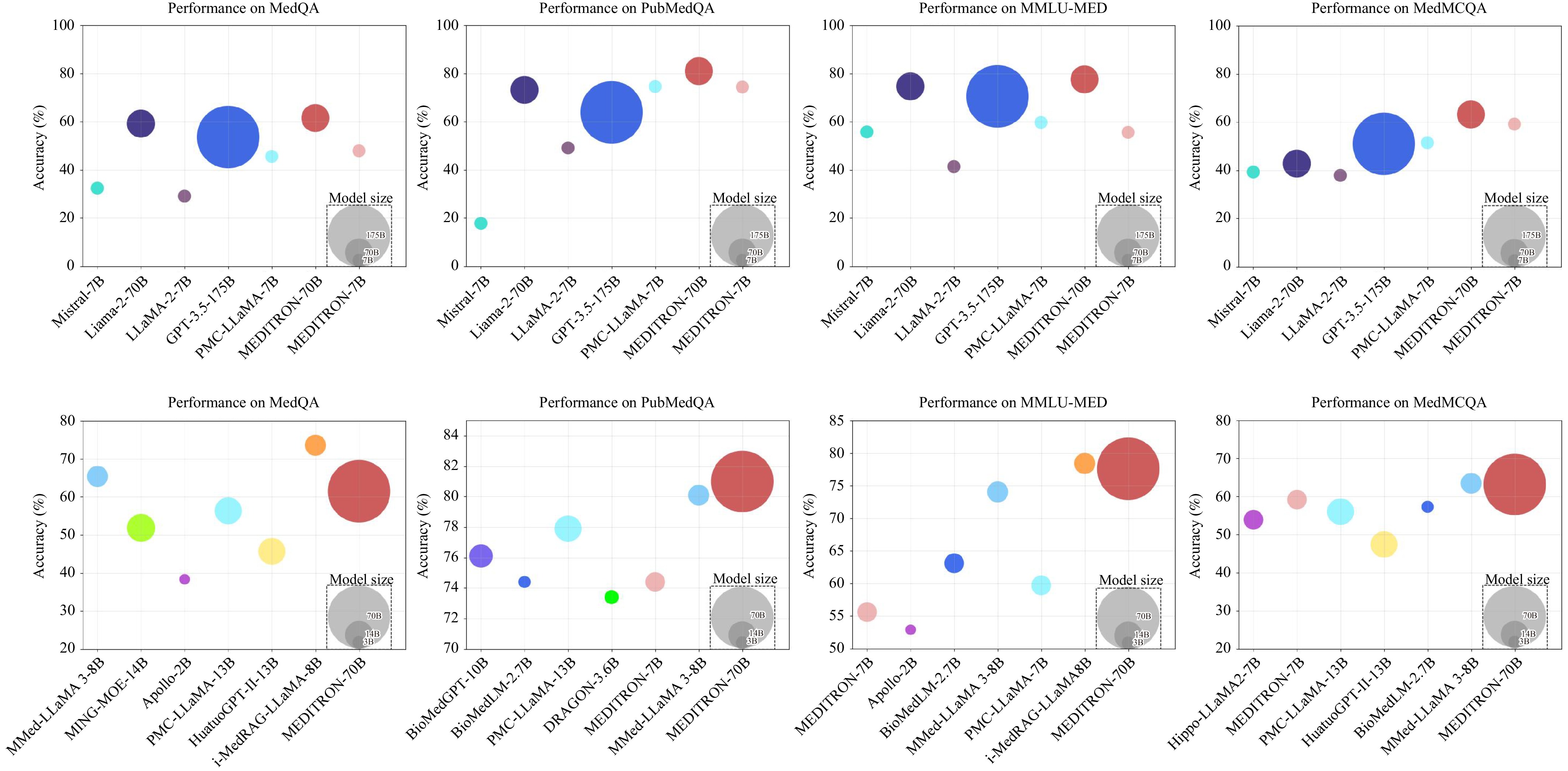
Z. Chen, A. Hernández Cano, A. Romanou, A. Bonnet, K. Matoba, F. Salvi, M. Pagliardini, S. Fan, A. Köpf, A. Mohtashami, et al., “MEDITRON-70B: Scaling medical pretraining for large language models,” arXiv preprint arXiv: 2311.16079, 2023, DOI: 10.48550/arXiv.2311.16079.
|
| [93] |
E. Bolton, A. Venigalla, M. Yasunaga, D. Hall, B. Xiong, T. Lee, R. Daneshjou, J. Frankle, P. Liang, M. Carbin, and C. D. Manning, “BioMedLM: A 2.7b parameter language model trained on biomedical text,” arXiv preprint arXiv: 2403.18421, 2024.
|
| [94] |
J. Chen, X. Wang, K. Ji, A. Gao, F. Jiang, S. Chen, H. Zhang, S. Dingjie, W. Xie, C. Kong, et al., “HuatuoGPT-Ⅱ, one-stage training for medical adaption of LLMs,” in Proc. First Conf. Language Modeling, Philadelphia, USA, 2024.
|
| [95] |
P. Qiu, C. Wu, X. Zhang, W. Lin, H. Wang, Y. Zhang, Y. Wang, and W. Xie, “Towards building multilingual language model for medicine,” Nat. Commun., vol. 15, no. 1, p. 8384, Sep. 2024. doi: 10.1038/s41467-024-52417-z
|
| [96] |
M. Yasunaga, A. Bosselut, H. Ren, X. Zhang, C. D. Manning, P. Liang, and J. Leskovec, “Deep bidirectional language-knowledge graph pretraining,” in Proc. 36th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2022, pp. 2704.
|
| [97] |
Y. Luo, J. Zhang, S. Fan, K. Yang, Y. Wu, M. Qiao, and Z. Nie, “BioMedGPT: Open multimodal generative pre-trained transformer for biomedicine,” arXiv preprint arXiv: 2308.09442, 2023, DOI: 10.48550/arXiv.2308.09442.
|
| [98] |
Y. Liao, S. Jiang, Y. Wang, and Y. Wang, “MING-MOE: Enhancing medical multi-task learning in large language models with sparse mixture of low-rank adapter experts,” arXiv preprint arXiv: 2404.09027, 2024, DOI: 10.48550/arXiv.2404.09027.
|
| [99] |
G. Xiong, Q. Jin, X. Wang, M. Zhang, Z. Lu, and A. Zhang, “Improving retrieval-augmented generation in medicine with iterative follow-up questions,” in Proc. Biocomputing: Proc. Pacific Symp., Kohala Coast, USA, 2024, pp. 199−214.
|
| [100] |
X. Wang, N. Chen, J. Chen, Y. Wang, G. Zhen, C. Zhang, X. Wu, Y. Hu, A. Gao, X. Wan, et al., “Apollo: A lightweight multilingual medical LLM towards democratizing medical AI to 6B people,” arXiv preprint arXiv: 2403.03640, 2024.
|
| [101] |
A. Krithara, A. Nentidis, K. Bougiatiotis, and G. Paliouras, “BioASQ-QA: A manually curated corpus for biomedical question answering,” Sci. Data, vol. 10, no. 1, p. 170, Mar. 2023. doi: 10.1038/s41597-023-02068-4
|
| [102] |
S. Lyu, C. Chi, H. Cai, L. Shi, X. Yang, L. Liu, X. Chen, D. Zhao, Z. Zhang, X. Lyu, et al., “RJUA-QA: A comprehensive QA dataset for urology,” arXiv preprint arXiv: 2312.09785, 2023, DOI: 10.48550/arXiv.2312.09785.
|
| [103] |
M. Luo, S. Saxena, S. Mishra, M. Parmar, and C. Baral, “BioTABQA: Instruction learning for biomedical table question answering,” in Proc. Conf. and Labs of the Evaluation Forum, Bologna, Italy, 2022, pp. 291−304.
|
| [104] |
V. Nguyen, S. Karimi, M. Rybinski, and Z. Xing, “MedRedQA for medical consumer question answering: Dataset, tasks, and neural baselines,” in Proc. 13th Int. Joint Conf. Natural Language Processing and the 3rd Conf. Asia-Pacific Chapter of the Association for Computational Linguistics, Nusa Dua, Bali, 2023, pp. 629−648, DOI: 10.18653/v1/2023.ijcnlp-main.42.
|
| [105] |
Y. Wang, H. Ivison, P. Dasigi, J. Hessel, T. Khot, K. R. Chandu, D. Wadden, K. MacMillan, N. A. Smith, I. Beltagy, and H. Hajishirzi, “How far can camels go? Exploring the state of instruction tuning on open resources,” in Proc. Thirty-Seventh Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2023, pp. 3268.
|
| [106] |
A. Mediboina, R. K. Badam, and S. Chodavarapu, “Assessing the accuracy of information on medication abortion: A comparative analysis of chatgpt and google bard AI,” Cureus, vol. 16, no. 1, p. e51544, Jan. 2024.
|
| [107] |
C. Peng, X. Yang, Z. Yu, J. Bian, W. R. Hogan, and Y. Wu, “Clinical concept and relation extraction using prompt-based machine reading comprehension,” J. Am. Med. Inform. Assoc., vol. 30, no. 9, pp. 1486–1493, Sep. 2023. doi: 10.1093/jamia/ocad107
|
| [108] |
C. Peng, X. Yang, K. E. Smith, Z. Yu, A. Chen, J. Bian, and Y. Wu, “Model tuning or prompt tuning? A study of large language models for clinical concept and relation extraction,” J. Biomed. Inform., vol. 153, p. 104630, May 2024. doi: 10.1016/j.jbi.2024.104630
|
| [109] |
C. Peng, Z. Yu, K. E. Smith, W.-H. Lo-Ciganic, J. Bian, and Y. Wu, “Improving generalizability of extracting social determinants of health using large language models through prompt-tuning,” arXiv preprint arXiv: 2403.12374, 2024, DOI: 10.48550/arXiv.2403.12374.
|
| [110] |
T. Lai, Y. Shi, Z. Du, J. Wu, K. Fu, Y. Dou, and Z. Wang, “Psy-LLM: Scaling up global mental health psychological services with AI-based large language models,” arXiv preprint arXiv: 2307.11991, 2023, DOI: 10.48550/arXiv.2307.11991.
|
| [111] |
J. Wang, Z. Yang, Z. Yao, and H. Yu, “JMLR: Joint medical LLM and retrieval training for enhancing reasoning and professional question answering capability,” arXiv preprint arXiv: 2402.17887, 2024, DOI: 10.48550/arXiv.2402.17887.
|
| [112] |
M. Cascella, J. Montomoli, V. Bellini, and E. Bignami, “Evaluating the feasibility of ChatGPT in healthcare: An analysis of multiple clinical and research scenarios,” J. Med. Syst., vol. 47, no. 1, p. 33, Mar. 2023. doi: 10.1007/s10916-023-01925-4
|
| [113] |
R. A. J. Clough, W. A. Sparkes, O. T. Clough, J. T. Sykes, A. T. Steventon, and K. King, “Transforming healthcare documentation: Harnessing the potential of AI to generate discharge summaries,” BJGP Open, vol. 8, no. 1, p. BJGPO.2023.0116, Apr. 2024. doi: 10.3399/BJGPO.2023.0116
|
| [114] |
Y. Wang, T. Fu, Y. Xu, Z. Ma, H. Xu, B. Du, Y. Lu, H. Gao, J. Wu, and J. Chen, “TWIN-GPT: Digital twins for clinical trials via large language model,” ACM Trans. Multimedia Comput. Commun. Appl., 2024, DOI: 10.1145/3674838.
|
| [115] |
S. Tayebi Arasteh, T. Han, M. Lotfinia, C. Kuhl, J. N. Kather, D. Truhn, and S. Nebelung, “Large language models streamline automated machine learning for clinical studies,” Nat. Commun., vol. 15, no. 1, p. 1603, Feb. 2024. doi: 10.1038/s41467-024-45879-8
|
| [116] |
R. Seetharaman, “Revolutionizing medical education: Can ChatGPT boost subjective learning and expression?,” J. Med. Syst., vol. 47, no. 1, p. 61, May 2023. doi: 10.1007/s10916-023-01957-w
|
| [117] |
I. Villagrán, R. Hernández, G. Schuit, A. Neyem, J. Fuentes-Cimma, C. Miranda, I. Hilliger, V. Durán, G. Escalona, and J. Varas, “Implementing artificial intelligence in physiotherapy education: A case study on the use of large language models (LLM) to enhance feedback,” IEEE Trans. Learn. Technol., vol. 17, pp. 2025–2036, Jan. 2024. doi: 10.1109/TLT.2024.3450210
|
| [118] |
A. A. Birkun and A. Gautam, “Large language model (LLM)-powered chatbots fail to generate guideline-consistent content on resuscitation and may provide potentially harmful advice,” Prehosp. Disaster Med., vol. 38, no. 6, pp. 757–763, Nov. 2023. doi: 10.1017/S1049023X23006568
|
| [119] |
C. Ahn, “Exploring ChatGPT for information of cardiopulmonary resuscitation,” Resuscitation, vol. 185, p. 109729, Apr. 2023. doi: 10.1016/j.resuscitation.2023.109729
|
| [120] |
E. Waisberg, J. Ong, M. Masalkhi, S. A. Kamran, N. Zaman, P. Sarker, A. G. Lee, and A. Tavakkoli, “GPT-4: A new era of artificial intelligence in medicine,” Ir. J. Med. Sci., vol. 192, no. 6, pp. 3197–3200, Apr. 2023. doi: 10.1007/s11845-023-03377-8
|
| [121] |
A. Paullada, I. D. Raji, E. M. Bender, E. Denton, and A. Hanna, “Data and its (dis)contents: A survey of dataset development and use in machine learning research,” Patterns, vol. 2, no. 11, p. 100336, Nov. 2021. doi: 10.1016/j.patter.2021.100336
|
| [122] |
A. Bezabih, S. Nourriz, and C. E. Smith, “Toward LLM-powered social robots for supporting sensitive disclosures of stigmatized health conditions,” arXiv preprint arXiv: 2409.04508, 2024, DOI: 10.48550/arXiv.2409.04508.
|
| [123] |
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill, et al., “On the opportunities and risks of foundation models,” arXiv preprint arXiv: 2108.07258, 2021.
|
| [124] |
D. Patterson, J. Gonzalez, U. Hölzle, Q. Le, C. Liang, L.-M. Munguia, D. Rothchild, D. R. So, M. Texier, and J. Dean, “The carbon footprint of machine learning training will plateau, then shrink,” Computer, vol. 55, no. 7, pp. 18–28, Jul. 2022.
|
| [125] |
J. Kaddour, J. Harris, M. Mozes, H. Bradley, R. Raileanu, and R. McHardy, “Challenges and applications of large language models,” arXiv preprint arXiv: 2307.10169, 2023, DOI: 10.48550/arXiv.2307.10169.
|
| [126] |
Y. Lu, M. Bartolo, A. Moore, S. Riedel, and P. Stenetorp, “Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity,” in Proc. 60th Annu. Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 2022, pp. 8086−8098.
|
| [127] |
B. Peng, J. Quesnelle, H. Fan, and E. Shippole, “YaRN: Efficient context window extension of large language models,” in Proc. Twelfth Int. Conf. Learning Representations, Vienna, Austria, 2024.
|
| [128] |
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proc. Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, USA, 2019, pp. 4171−4186.
|
| [129] |
A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,” 2018.
|
| [130] |
D. Brin, V. Sorin, A. Vaid, A. Soroush, B. S. Glicksberg, A. W. Charney, G. Nadkarni, and E. Klang, “Comparing ChatGPT and GPT-4 performance in USMLE soft skill assessments,” Sci. Rep., vol. 13, no. 1, p. 16492, Oct. 2023. doi: 10.1038/s41598-023-43436-9
|
| [131] |
K. Singhal, T. Tu, J. Gottweis, R. Sayres, E. Wulczyn, M. Amin, L. Hou, K. Clark, S. R. Pfohl, H. Cole-Lewis, et al., “Toward expert-level medical question answering with large language models,” Nat. Med., vol. 31, no. 3, pp. 943–950, Jan. 2025. doi: 10.1038/s41591-024-03423-7
|
| [132] |
M. Bachmann, I. Duta, E. Mazey, W. Cooke, M. Vatish, and G. Davis Jones, “Exploring the capabilities of ChatGPT in women’s health: Obstetrics and gynaecology,” NPJ Womens Health, vol. 2, no. 1, p. 26, Jul. 2024. doi: 10.1038/s44294-024-00028-w
|
| [133] |
D. Van Veen, C. Van Uden, L. Blankemeier, J.-B. Delbrouck, A. Aali, C. Bluethgen, A. Pareek, M. Polacin, E. P. Reis, A. Seehofnerová, et al., “Adapted large language models can outperform medical experts in clinical text summarization,” Nat. Med., vol. 30, no. 4, pp. 1134–1142, Feb. 2024. doi: 10.1038/s41591-024-02855-5
|
| [134] |
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, et al., “PaLM: Scaling language modeling with pathways,” J. Mach. Learn. Res., vol. 24, no. 1, p. 240, Jan. 2023.
|
| [135] |
S. Montagna, S. Ferretti, L. C. Klopfenstein, A. Florio, and M. F. Pengo, “Data decentralisation of LLM-based chatbot systems in chronic disease self-management,” in Proc. ACM Conf. Information Technology for Social Good, Lisbon, Portugal, 2023, pp. 205−212.
|
| [136] |
X. Bi, D. Chen, G. Chen, S. Chen, D. Dai, C. Deng, H. Ding, K. Dong, Q. Du, Z. Fu, et al., “DeepSeek LLM: Scaling open-source language models with longtermism,” arXiv preprint arXiv: 2401.02954, 2024, DOI: 10.48550/arXiv.2401.02954.
|
| [137] |
W. Wang, P. Tang, J. Lou, Y. Shao, L. Waller, Y.-A. Ko, and L. Xiong, “IGAMT: Privacy-preserving electronic health record synthesization with heterogeneity and irregularity,” in Proc. Thirty-Eighth AAAI Conf. Artificial Intelligence, Vancouver, Canada, 2024, pp. 15634−15643, DOI: 10.1609/aaai.v38i14.29491.
|
| [138] |
A. B. Abacha and D. Demner-Fushman, “A question-entailment approach to question answering,” BMC Bioinformatics, vol. 20, no. 1, p. 511, Oct. 2019. doi: 10.1186/s12859-019-3119-4
|
| [139] |
H. Rokham, G. Pearlson, A. Abrol, H. Falakshahi, S. Plis, and V. D. Calhoun, “Addressing inaccurate nosology in mental health: A multilabel data cleansing approach for detecting label noise from structural magnetic resonance imaging data in mood and psychosis disorders,” Biol. Psychiatry Cogn. Neurosci. Neuroimaging, vol. 5, no. 8, pp. 819–832, Aug. 2020.
|
| [140] |
R. Ferrod, E. Brunetti, L. D. Caro, C. D. Francescomarino, M. Dragoni, C. Ghidini, R. Marinello, and E. Sulis, “A support for understanding medical notes: Correcting spelling errors in Italian clinical records,” in Proc. Workshop on Towards Smarter Health Care: Can Artificial Intelligence Help? Co-located with 20th Int. Conf. Italian Association for Artificial Intelligence, Virtual, 2021, pp. 19−28.
|
| [141] |
H. Molavi Vardajani, A. A. Haghdoost, A. Shahravan, and M. Rad, “Cleansing and preparation of data for statistical analysis: A step necessary in oral health sciences research,” J. Oral Health Oral Epidemiol., vol. 5, no. 4, pp. 171–185, Dec. 2016.
|
| [142] |
M. Kuhn and K. Johnson, Applied Predictive Modeling. New York: Springer, 2013.
|
| [143] |
H. Zhou, “Linear discriminant analysis,” in Learn Data Mining Through Excel, H. Zhou, Ed. Berkeley: Apress, 2020, pp. 49−66.
|
| [144] |
P. J. Gemperline, “Principal component analysis,” Technometrics, vol. 45, no. 3, p. 276, 2003.
|
| [145] |
D. K. Choubey, M. Kumar, V. Shukla, S. Tripathi, and V. K. Dhandhania, “Comparative analysis of classification methods with pca and lda for diabetes,” Curr. Diabetes Rev., vol. 16, no. 8, pp. 833–850, 2020.
|
| [146] |
M. S. Ali, M. K. Islam, A. A. Das, D. U. S. Duranta, M. F. Haque, and M. H. Rahman, “A novel approach for best parameters selection and feature engineering to analyze and detect diabetes: Machine learning insights,” BioMed Res. Int., vol. 2023, no. 1, p. 8583210, May 2023. doi: 10.1155/2023/8583210
|
| [147] |
Ö. Özdemir and E. B. Sönmez, “Weighted cross-entropy for unbalanced data with application on COVID X-ray images,” in Proc. Innovations in Intelligent Systems and Applications Conf., Istanbul, Turkey, 2020, pp. 1−6.
|
| [148] |
P. J. Huber, “Robust estimation of a location parameter,” in Breakthroughs in Statistics: Methodology and Distribution, S. Kotz and N. L. Johnson, Eds. New York: Springer, 1992, pp. 492−518.
|
| [149] |
A. E. Hoerl and R. W. Kennard, “Ridge regression: Biased estimation for nonorthogonal problems,” Technometrics, vol. 42, no. 1, pp. 80–86, Mar. 2000. doi: 10.1080/00401706.2000.10485983
|
| [150] |
C. E. Hermann, J. M. Patel, L. Boyd, W. B. Growdon, E. Aviki, and M. Stasenko, “Let’s chat about cervical cancer: Assessing the accuracy of ChatGPT responses to cervical cancer questions,” Gynecol. Oncol., vol. 179, pp. 164–168, Dec. 2023. doi: 10.1016/j.ygyno.2023.11.008
|
| [151] |
E. Alsentzer, J. Murphy, W. Boag, W.-H. Weng, D. Jindi, T. Naumann, and M. McDermott, “Publicly available clinical BERT embeddings,” in Proc. 2nd Clinical Natural Language Processing Workshop, Minneapolis, USA, 2019, pp. 72−78.
|
| [152] |
Z. Yu, X. Bao, E. Chersoni, B. Portelli, S. Lee, J. Gu, and C.-R. Huang, “PolyuCBS at SMM4H 2024: LLM-based medical disorder and adverse drug event detection with low-rank adaptation,” in Proc. 9th Social Media Mining for Health Research and Applications Workshop and Shared Tasks, Bangkok, Thailand, 2024, pp. 74−78.
|
| [153] |
R. Wang, D. Tang, N. Duan, Z. Wei, X. Huang, J. Ji, G. Cao, D. Jiang, and M. Zhou, “K-adapter: Infusing knowledge into pre-trained models with adapters,” in Proc. Findings of the Association for Computational Linguistics, Online, 2021, pp. 1405−1418.
|
| [154] |
H. Yuan, Z. Yuan, and S. Yu, “Generative biomedical entity linking via knowledge base-guided pre-training and synonyms-aware fine-tuning,” in Proc. Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, United States, 2022, pp. 4038−4048.
|
| [155] |
Q. Lu, A. Wen, T. Nguyen, and H. Liu, “Enhancing clinical relevance of pretrained language models through integration of external knowledge: Case study on cardiovascular diagnosis from electronic health records,” JMIR AI, vol. 3, no. 1, p. e56932, Aug. 2024.
|
| [156] |
A. Webson and E. Pavlick, “Do prompt-based models really understand the meaning of their prompts?” in Proc. Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, USA, 2022, pp. 2300−2344, DOI: 10.18653/v1/2022.naacl-main.167.
|
| [157] |
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, et al., “Evaluating large language models trained on code,” arXiv preprint arXiv: 2107.03374, 2021.
|
| [158] |
V. Liévin, C. E. Hother, A. G. Motzfeldt, and O. Winther, “Can large language models reason about medical questions?,” Patterns, vol. 5, no. 3, p. 100943, Mar. 2024. doi: 10.1016/j.patter.2024.100943
|
| [159] |
J. Maharjan, A. Garikipati, N. P. Singh, L. Cyrus, M. Sharma, M. Ciobanu, G. Barnes, R. Thapa, Q. Mao, and R. Das, “OpenMedLM: Prompt engineering can out-perform fine-tuning in medical question-answering with open-source large language models,” Sci. Rep., vol. 14, no. 3, p. 14156, Jun. 2024.
|
| [160] |
J. Holmes, L. Zhang, Y. Ding, H. Y. Feng, Z. L. Liu, T. M. Liu, W. W. Wong, S. A. Vora, J. B. Ashman, and W. Liu, “Benchmarking a foundation large language model on its ability to relabel structure names in accordance with the american association of physicists in medicine task group-263 report,” Pract. Radiat. Oncol., vol. 14, no. 6, pp. e515–e521, Nov.−Dec. 2024. doi: 10.1016/j.prro.2024.04.017
|
| [161] |
D. F. Navarro, K. Ijaz, D. Rezazadegan, H. Rahimi-Ardabili, M. Dras, E. Coiera, and S. Berkovsky, “Clinical named entity recognition and relation extraction using natural language processing of medical free text: A systematic review,” Int. J. Med. Inf., vol. 177, p. 105122, Sep. 2023. doi: 10.1016/j.ijmedinf.2023.105122
|
| [162] |
X. Dai, S. Karimi, and N. O’Callaghan, “Identifying health risks from family history: A survey of natural language processing techniques,” arXiv preprint arXiv: 2403.09997, 2024.
|
| [163] |
C. Sun, Z. Yang, L. Wang, Y. Zhang, H. Lin, and J. Wang, “Biomedical named entity recognition using BERT in the machine reading comprehension framework,” J. Biomed. Inform., vol. 118, p. 103799, Jun. 2021. doi: 10.1016/j.jbi.2021.103799
|
| [164] |
I. C. Wiest, M.-E. Leßmann, F. Wolf, D. Ferber, M. Van Treeck, J. Zhu, M. P. Ebert, C. B. Westphalen, M. Wermke, and J. N. Kather, “Deidentifying medical documents with local, privacy-preserving large language models: The LLM-anonymizer,” NEJM AI, vol. 2, no. 4, p. AIdbp2400537, Mar. 2025. doi: 10.1056/AIdbp2400537
|
| [165] |
L. Chua, B. Ghazi, Y. Huang, P. Kamath, R. Kumar, D. Liu, P. Manurangsi, A. Sinha, and C. Zhang, “Mind the privacy unit! User-level differential privacy for language model fine-tuning,” in Proc. First Conf. Language Modeling, Philadelphia, USA, 2024.
|
| [166] |
T. Fan, Y. Kang, G. Ma, W. Chen, W. Wei, L. Fan, and Q. Yang, “FATE-LLM: A industrial grade federated learning framework for large language models,” arXiv preprint arXiv: 2310.10049, 2023.
|
| [167] |
Y. Song, J. Zhang, Z. Tian, Y. Yang, M. Huang, and D. Li, “LLM-based privacy data augmentation guided by knowledge distillation with a distribution tutor for medical text classification,” arXiv preprint arXiv: 2402.16515, 2024.
|
| [168] |
X.-Y. Liu, R. Zhu, D. Zha, J. Gao, S. Zhong, M. White, and M. Qiu, “Differentially private low-rank adaptation of large language model using federated learning,” ACM Trans. Manage. Inf. Syst., vol. 16, no. 2, p. 11, Mar. 2025.
|
| [169] |
H. Ledford, “Translational research: 4 ways to fix the clinical trial,” Nature, vol. 477, no. 7366, pp. 526–528, Sep. 2011. doi: 10.1038/477526a
|
| [170] |
C. Huguet, J. Pearse, and J. Esteve, “New tools for online teaching and their impact on student learning,” in Proc. 7th Int. Conf. Higher Education Advances, Valencia, Spain, 2021.
|
| [171] |
J. Clusmann, F. R. Kolbinger, H. S. Muti, Z. I. Carrero, J.-N. Eckardt, N. G. Laleh, C. M. L. Löffler, S.-C. Schwarzkopf, M. Unger, G. P. Veldhuizen, S. J. Wagner, and J. N. Kather, “The future landscape of large language models in medicine,” Commun. Med., vol. 3, no. 1, p. 141, Oct. 2023. doi: 10.1038/s43856-023-00370-1
|
| [172] |
M. Hasnain, “ChatGPT applications and challenges in controlling monkey pox in Pakistan,” Ann. Biomed. Eng., vol. 51, no. 9, pp. 1889–1891, May 2023. doi: 10.1007/s10439-023-03231-z
|
| [173] |
I. Gur, H. Furuta, A. V. Huang, M. Safdari, Y. Matsuo, D. Eck, and A. Faust, “A real-world WebAgent with planning, long context understanding, and program synthesis,” in Proc. Twelfth Int. Conf. Learning Representations, Vienna, Austria, 2024.
|
| [174] |
S. Biderman, H. Schoelkopf, Q. G. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raff, A. Skowron, L. Sutawika, and O. Van Der Wal, “Pythia: A suite for analyzing large language models across training and scaling,” in Proc. 40th Int. Conf. Machine Learning, Honolulu, USA, 2023, pp. 2397−2430.
|
| [175] |
S. Pal, M. Bhattacharya, S.-S. Lee, and C. Chakraborty, “A domain-specific next-generation large language model (LLM) or ChatGPT is required for biomedical engineering and research,” Ann. Biomed. Eng., vol. 52, no. 3, pp. 451–454, Mar. 2024. doi: 10.1007/s10439-023-03306-x
|
| [176] |
T. Savage, A. Nayak, R. Gallo, E. Rangan, and J. H. Chen, “Diagnostic reasoning prompts reveal the potential for large language model interpretability in medicine,” NPJ Digit. Med., vol. 7, no. 1, p. 50, Jan. 2024. doi: 10.1038/s41746-024-01042-7
|
| [177] |
J. K. Kim, M. Chua, M. Rickard, and A. Lorenzo, “ChatGPT and large language model (LLM) chatbots: The current state of acceptability and a proposal for guidelines on utilization in academic medicine,” J. Pediatr. Urol., vol. 19, no. 5, pp. 598–604, Oct. 2023. doi: 10.1016/j.jpurol.2023.05.018
|
| [178] |
J. Hoelscher-Obermaier, J. Persson, E. Kran, I. Konstas, and F. Barez, “Detecting edit failures in large language models: An improved specificity benchmark,” in Proc. Findings of the Association for Computational Linguistics, Toronto, Canada, 2023, pp. 11548−11559, DOI: 10.18653/v1/2023.findings-acl.733.
|
| [179] |
S. Chen, M. Wu, K. Q. Zhu, K. Lan, Z. Zhang, and L. Cui, “LLM-empowered chatbots for psychiatrist and patient simulation: Application and evaluation,” arXiv preprint arXiv: 2305.13614, 2023, DOI: 10.48550/arXiv.2305.13614.
|
| [180] |
W. Zhou, X. Zhu, Q.-L. Han, L. Li, X. Chen, S. Wen, and Y. Xiang, “The security of using large language models: A survey with emphasis on ChatGPT,” IEEE/CAA J. Autom. Sinica, vol. 12, no. 1, pp. 1–26, Jan. 2025. doi: 10.1109/JAS.2024.124983
|
| [181] |
R. S. Sutton and A. G. Barto, “Reinforcement learning: An introduction,” IEEE Trans. Neural Netw., vol. 9, no. 5, p. 1054, Sep. 1998.
|
| [182] |
E. Mitchell, C. Lin, A. Bosselut, C. Finn, and C. D. Manning, “Fast model editing at scale,” in Proc. Tenth Int. Conf. Learning Representations, Virtual, 2022.
|
| [183] |
X. Wang, L. Xie, C. Dong, and Y. Shan, “Real-ESRGAN: Training real-world blind super-resolution with pure synthetic data,” in Proc. IEEE/CVF Int. Conf. Computer Vision Workshops, Montreal, Canada, Virtual, 2022, pp. 1905−1914.
|
| [184] |
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al., “Training language models to follow instructions with human feedback,” in Proc. 36th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2022, pp. 2011.
|
| [185] |
Q. Miao, W. Zheng, Y. Lv, M. Huang, W. Ding, and F.-Y. Wang, “Dao to HANOI via DESCI: AI paradigm shifts from AlphaGo to ChatGpt,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 4, pp. 877–897, Apr. 2023. doi: 10.1109/JAS.2023.123561
|
| [186] |
P. F. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” in Proc. 31st Int. Conf. Neural Information Processing Systems, Long Beach, USA, 2017, pp. 4302−4310.
|
| [187] |
Y. Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnon, et al., “Constitutional AI: Harmlessness from AI feedback,” arXiv preprint arXiv: 2212.08073, 2022.
|
| [188] |
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv: 1707.06347, 2017.
|
| [189] |
R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Manning, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,” in Proc. 37th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2024, pp. 2338.
|
| [190] |
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al., “DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning,” arXiv preprint arXiv: 2501.12948, 2025.
|
| [191] |
C. Zhou, P. Liu, P. Xu, S. Iyer, J. Sun, Y. Mao, X. Ma, A. Efrat, P. Yu, L. Yu, et al., “LIMA: Less is more for alignment,” in Proc. 37th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2023, pp. 2400.
|
| [192] |
X. Li, S. Li, S. Song, J. Yang, J. Ma, and J. Yu, “PMET: Precise model editing in a transformer,” in Proc. Thirty-Eighth AAAI Conf. Artificial Intelligence, Vancouver, Canada, 2024, pp. 18564−18572, DOI: 10.1609/aaai.v38i17.29818.
|
| [193] |
K. Meng, D. Bau, A. Andonian, and Y. Belinkov, “Locating and editing factual associations in GPT,” in Proc. 36th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2022, pp. 1262.
|
| [194] |
K. Meng, A. S. Sharma, A. J. Andonian, Y. Belinkov, and D. Bau, “Mass-editing memory in a transformer,” in Proc. Eleventh Int. Conf. Learning Representations, Kigali, Rwanda, 2023.
|
| [195] |
G. K. Gangadhar and K. Stratos, “Model editing by standard fine-tuning,” in Proc. Findings of the Association for Computational Linguistics, Bangkok, Thailand, 2024, pp. 5907−5913.
|
| [196] |
Y. Yao, P. Wang, B. Tian, S. Cheng, Z. Li, S. Deng, H. Chen, and N. Zhang, “Editing large language models: Problems, methods, and opportunities,” in Proc. Conf. Empirical Methods in Natural Language Processing, Singapore, Singapore, 2023, pp. 10222−10240.
|
| [197] |
A. Gupta, D. Sajnani, and G. Anumanchipalli, “A unified framework for model editing,” in Proc. Findings of the Association for Computational Linguistics, Miami, USA, 2024, pp. 15403−15418.
|
| [198] |
J.-C. Gu, H.-X. Xu, J.-Y. Ma, P. Lu, Z.-H. Ling, K.-W. Chang, and N. Peng, “Model editing harms general abilities of large language models: Regularization to the rescue,” in Proc. Conf. Empirical Methods in Natural Language Processing, Miami, USA, 2024, pp. 16801−16819.
|
| [199] |
I. C. Wiest, D. Ferber, J. Zhu, M. Van Treeck, S. K. Meyer, R. Juglan, Z. I. Carrero, D. Paech, J. Kleesiek, M. P. Ebert, et al., “Privacy-preserving large language models for structured medical information retrieval,” npj Digit. Med., vol. 7, no. 1, p. 257, Sep. 2024. doi: 10.1038/s41746-024-01233-2
|
| [200] |
R. Tang, X. Han, X. Jiang, X. Hu, “Does synthetic data generation of LLMs help clinical text mining?” arXiv preprint arXiv: 2303.04360, 2023, DOI: 10.48550/arXiv.2303.04360.
|
| [201] |
P. H. Brekke, T. Rama, I. Pilán, Ø. Nytrø, and L. Øvrelid, “Synthetic data for annotation and extraction of family history information from clinical text,” J. Biomed. Semant., vol. 12, no. 1, p. 11, Jul. 2021. doi: 10.1186/s13326-021-00244-2
|
| [202] |
K. Sengupta and P. R. Srivastava, “Causal effect of racial bias in data and machine learning algorithms on user persuasiveness & discriminatory decision making: An empirical study,” arXiv preprint arXiv: 2202.00471, 2022.
|
| [203] |
V. C. Pezoulas, N. S. Tachos, G. Gkois, I. Olivotto, F. Barlocco, and D. I. Fotiadis, “Bayesian inference-based Gaussian mixture models with optimal components estimation towards large-scale synthetic data generation for in silico clinical trials,” IEEE Open J. Eng. Med. Biol., vol. 3, pp. 108–114, Jun. 2022. doi: 10.1109/OJEMB.2022.3181796
|
| [204] |
M. Ibrahim, Y. Al Khalil, S. Amirrajab, C. Sun, M. Breeuwer, J. Pluim, B. Elen, G. Ertaylan, and M. Dumontier, “Generative AI for synthetic data across multiple medical modalities: A systematic review of recent developments and challenges,” Comput. Biol. Med., vol. 189, p. 109834, May 2025. doi: 10.1016/j.compbiomed.2025.109834
|
| [205] |
Y. Lu, H. Wang, and W. Wei, “Machine learning for synthetic data generation: A review,” arXiv preprint arXiv: 2302.04062, 2023, DOI: 10.48550/arXiv.2302.04062.
|
| [206] |
A. Jadon and S. Kumar, “Leveraging generative AI models for synthetic data generation in healthcare: Balancing research and privacy,” in Proc. Int. Conf. Smart Applications, Communications and Networking, Istanbul, Turkiye, 2023, pp. 1−4, DOI: 10.1109/SmartNets58706.2023.10215825.
|
| [207] |
M. Guillaudeux, O. Rousseau, J. Petot, Z. Bennis, C.-A. Dein, T. Goronflot, N. Vince, S. Limou, M. Karakachoff, M. Wargny, and P.-A. Gourraud, “Patient-centric synthetic data generation, no reason to risk re-identification in biomedical data analysis,” npj Digit. Med., vol. 6, no. 1, p. 37, Mar. 2023. doi: 10.1038/s41746-023-00771-5
|
| [208] |
D. Batić, F. Holm, E. Özsoy, T. Czempiel, and N. Navab, “EndoViT: Pretraining vision transformers on a large collection of endoscopic images,” Int. J. Comput. Assist. Radiol. Surg., vol. 19, no. 6, pp. 1085–1091, Apr. 2024. doi: 10.1007/s11548-024-03091-5
|
| [209] |
M. A. Rahman, “A survey on security and privacy of multimodal LLMs - connected healthcare perspective,” in Proc. IEEE Globecom Workshops, Kuala Lumpur, Malaysia, 2023, pp. 1807−1812.
|
| [210] |
Z. Huang, F. Bianchi, M. Yuksekgonul, T. J. Montine, and J. Zou, “A visual–language foundation model for pathology image analysis using medical Twitter,” Nat. Med., vol. 29, no. 9, pp. 2307–2316, Aug. 2023. doi: 10.1038/s41591-023-02504-3
|
| [211] |
Y. Oh, S. Park, H. K. Byun, Y. Cho, I. J. Lee, J. S. Kim, and J. C. Ye, “LLM-driven multimodal target volume contouring in radiation oncology,” Nat. Commun., vol. 15, no. 1, p. 9186, Oct. 2024. doi: 10.1038/s41467-024-53387-y
|
Figures(2) / Tables(4)






 DownLoad:
DownLoad: