A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 12
Issue 12
Volume 12
Issue 12
IEEE/CAA Journal of Automatica Sinica
| Citation: | L. Wang, L. Jia, and R. Zhang, “Input-output data driven intelligent H∞ fault-tolerant tracking control for Industrial process in Industry 5.0,” IEEE/CAA J. Autom. Sinica, vol. 12, no. 12, pp. 2624–2626, Dec. 2025. doi: 10.1109/JAS.2025.125465

|

| [1] |
H. W. Lin, B. Zhao, D. R. Zhao, and C. Alippi, “Data-based fault tolerant control for affine nonlinear systems through particle swarm optimized neural networks,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 4, pp. 954–964, Jul. 2020. doi: 10.1109/JAS.2020.1003225
|
| [2] |
C. X. Mu, Y. Zhang, G. B. Cai, R. J. Liu, and C. Y. Sun, “A data-based feedback relearning algorithm for uncertain nonlinear systems,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 5, pp. 1288–1303, May 2023. doi: 10.1109/JAS.2023.123186
|
| [3] |
M. Yin, A. Lannelli, and R. S. Smith, “Maximum likelihood estimation in data-driven modeling and control,” IEEE/CAA J. Autom. Sinica, vol. 68, no. 1, pp. 317–328, Dec. 2021.
|
| [4] |
H. Y. Fang, M. G. Zhang, S. P. He, X. L. Luan, F. Liu, and Z. T. Ding, “Solving the zero-sum control problem for tidal turbine system: An online reinforcement learning approach,” IEEE Trans. Cybern., vol. 53, no. 12, pp. 7635–7647, Jul. 2022.
|
| [5] |
P. N. Dao and M. H. Phung, “Nonlinear robust integral based actor-critic reinforcement learning control for a perturbed three-wheeled mobile robot with mecanum wheels,” Computers and Electrical Engineering, vol. 121, p. 109870, Jun. 2025. doi: 10.1016/j.compeleceng.2024.109870
|
| [6] |
X. Shi, Y. Li, C. Du, et al., “Reinforcement learning-based optimal control for Markov jump systems with completely unknown dynamics,” Automatica, vol. 171, p. 111886, Apr. 2025. doi: 10.1016/j.automatica.2024.111886
|
| [7] |
X. Y. Li, Q. W. Luo, L. M. Wang, R. D. Zhang, and F. R. Gao, “Off-policy reinforcement learning-based novel model-free minmax fault-tolerant tracking control for industrial processes,” J. Process Control, vol. 115, pp. 145–156, Jul. 2022. doi: 10.1016/j.jprocont.2022.05.006
|
| [8] |
B. Kiumarsi, F. L. Lewis, and F. R. Gao, “H∞ control of linear discrete-time systems: Off-policy reinforcement learning,” Automatica, vol. 78, pp. 144–152, Apr. 2017. doi: 10.1016/j.automatica.2016.12.009
|
| [9] |
S. Sign, T. Jaakkola, L. L. Littman, and C. Szepesvári, “Convergence results for single-step on-policy reinforcement-learning algorithms,” Machine Learning, vol. 38, pp. 287–3086, Mar. 2007.
|
| [10] |
J. N. Li, T. Y. Chai, F. L. Frank, Z. T. Zheng, and Y. Yi, “Off-policy interleaved Q-learning: Optimal control for affine nonlinear discrete-time systems,” IEEE Trans. Neural Networks and Learning Systems, vol. 30, no. 5, pp. 1308–1320, Sep. 2018.
|
| [11] |
W. Xin, H. Y. Shi, C. L. Su, X. Y. Jiang, P. Li, and P. Li, “Novel data-driven two-dimensional Q-learning for optimal tracking control of batch process with unknown dynamics,” ISA Trans., vol. 125, pp. 10–21, Jun. 2022. doi: 10.1016/j.isatra.2021.06.007
|
| [12] |
Y. Q. Wang, D. H. Zhou, and F. R. Gao, “Iterative learning model predictive control for multi-phase batch processes,” Industrial & Engineering Chemistry Research, vol. 45, no. 26, pp. 9050–9060, 2006.
|
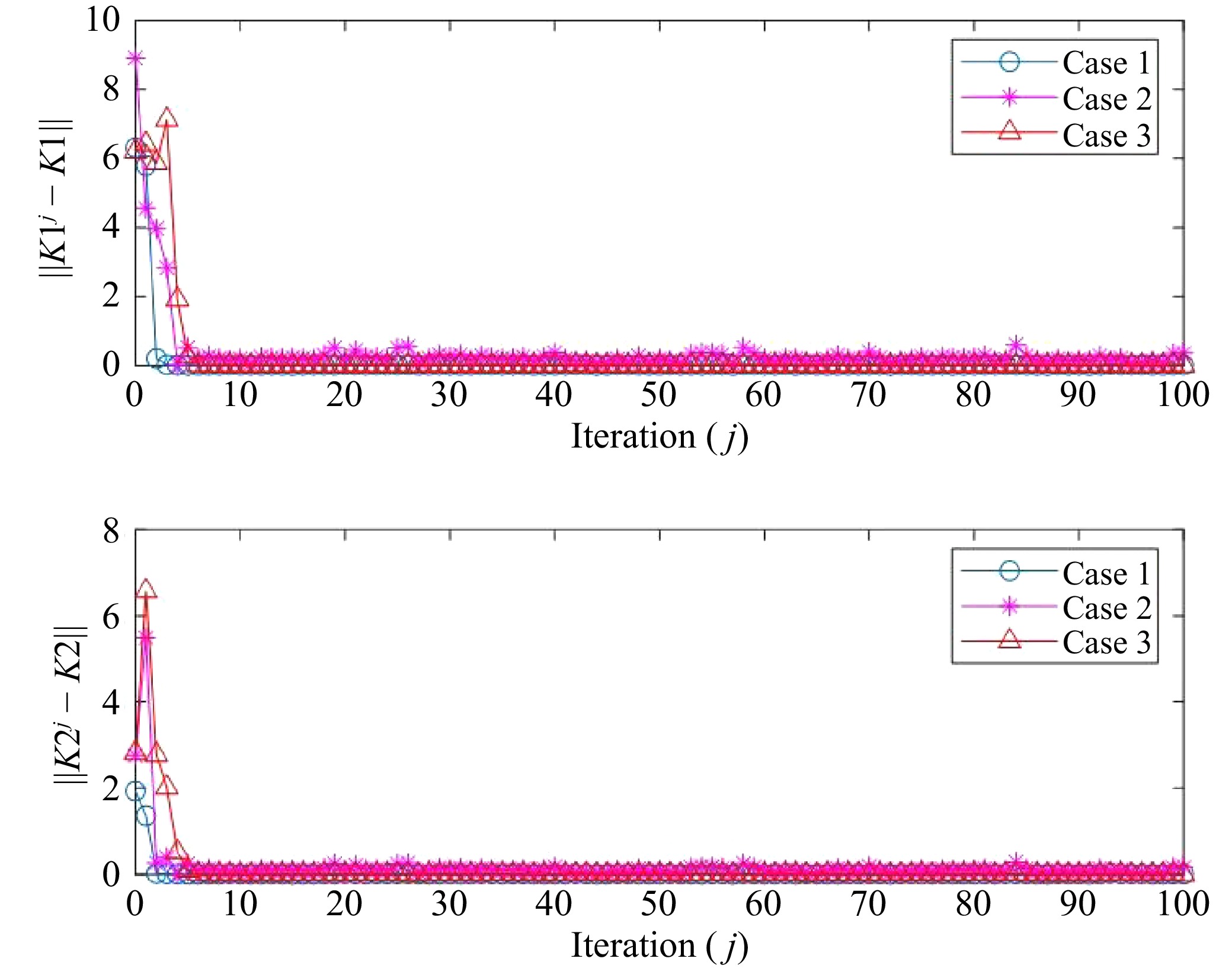
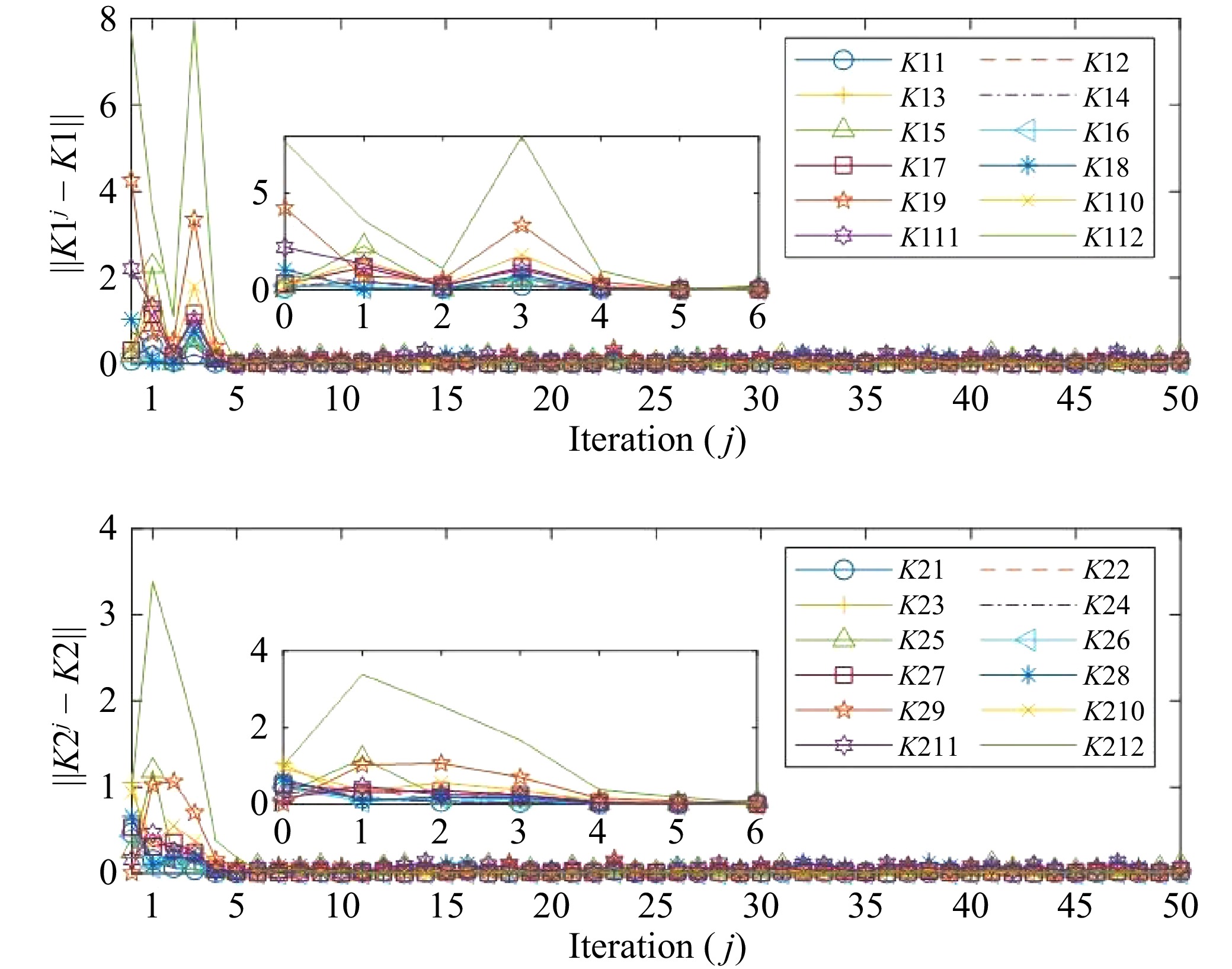
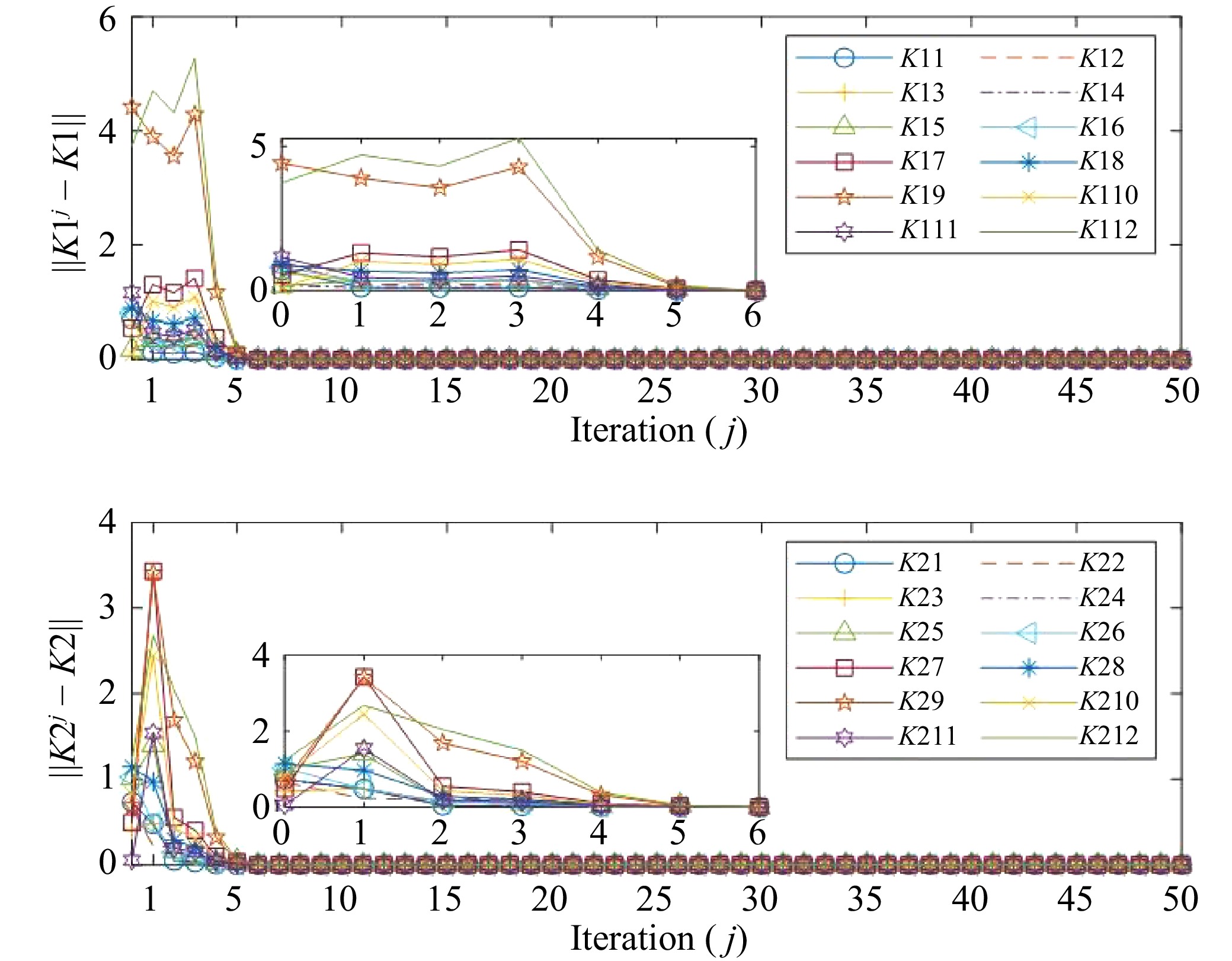
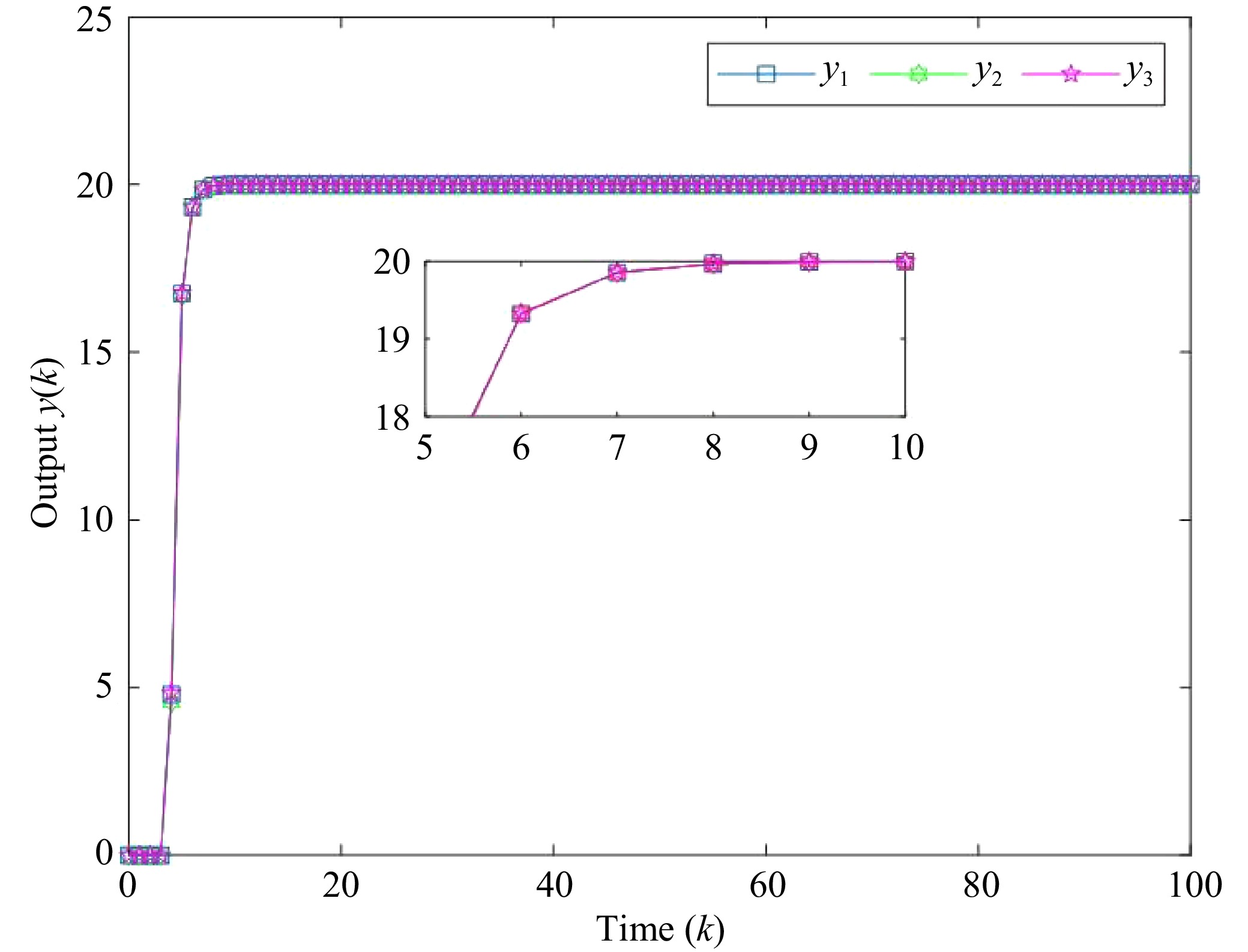
Figures(4)






 DownLoad:
DownLoad: