A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 12
Issue 12
Volume 12
Issue 12
IEEE/CAA Journal of Automatica Sinica
| Citation: | Y. Yang, H. Modares, K. G. Vamvoudakis, and F. L. Lewis, “Composite adaptive critic design,” IEEE/CAA J. Autom. Sinica, vol. 12, no. 12, pp. 2525–2540, Dec. 2025. doi: 10.1109/JAS.2025.125435

|

| [1] |
M. Xin and H. Pan, “Indirect robust control of spacecraft via optimal control solution,” IEEE Trans. Aerosp. Electron. Syst., vol. 48, no. 2, pp. 1798–1809, Apr. 2012. doi: 10.1109/TAES.2012.6178102
|
| [2] |
H. Waschl, I. Kolmanovsky, M. Steinbuch, and L. del Re, Optimization and Optimal Control in Automotive Systems. Cham, Germany: Springer, 2014.
|
| [3] |
Y. Yang, Z. Ding, R. Wang, H. Modares, and D. C. Wunsch, “Data-driven human-robot interaction without velocity measurement using off-policy reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 1, pp. 47–63, Jan. 2022. doi: 10.1109/JAS.2021.1004258
|
| [4] |
J. L. Speyer and D. H. Jacobson, Primer on Optimal Control Theory. Philadelphia, USA: Society for Industrial and Applied Mathematics, 2010.
|
| [5] |
D. Liberzon, Calculus of Variations and Optimal Control Theory: A Concise Introduction. Princeton, USA: Princeton University Press, 2012.
|
| [6] |
D. P. Bertsekas, Dynamic Programming and Optimal Control. 4th ed. Belmont, USA: Athena Scientific, 2012.
|
| [7] |
F. L. Lewis, D. Vrabie, and V. L. Syrmos, Optimal control. 3rd ed. Hoboken, USA: John Wiley & Sons, 2012.
|
| [8] |
D. Vrabie, O. Pastravanu, M. Abu-Khalaf, and F. L. Lewis, “Adaptive optimal control for continuous-time linear systems based on policy iteration,” Automatica, vol. 45, no. 2, pp. 477–484, Feb. 2009. doi: 10.1016/j.automatica.2008.08.017
|
| [9] |
H. Modares, F. L. Lewis, and M. B. Naghibi-Sistani, “Integral reinforcement learning and experience replay for adaptive optimal control of partially-unknown constrained-input continuous-time systems,” Automatica, vol. 50, no. 1, pp. 193–202, Jan. 2014. doi: 10.1016/j.automatica.2013.09.043
|
| [10] |
C. Chen, H. Modares, K. Xie, F. L. Lewis, Y. Wan, and S. Xie, “Reinforcement learning-based adaptive optimal exponential tracking control of linear systems with unknown dynamics,” IEEE Trans. Autom. Control, vol. 64, no. 11, pp. 4423–4438, Nov. 2019. doi: 10.1109/TAC.2019.2905215
|
| [11] |
D. Wang, D. Liu, Q. Wei, D. Zhao, and N. Jin, “Optimal control of unknown nonaffine nonlinear discrete-time systems based on adaptive dynamic programming,” Automatica, vol. 48, no. 8, pp. 1825–1832, Aug. 2012. doi: 10.1016/j.automatica.2012.05.049
|
| [12] |
Y. Jiang and Z. P. Jiang, “Computational adaptive optimal control for continuous-time linear systems with completely unknown dynamics,” Automatica, vol. 48, no. 10, pp. 2699–2704, Oct. 2012. doi: 10.1016/j.automatica.2012.06.096
|
| [13] |
W. Gao and Z. P. Jiang, “Adaptive dynamic programming and adaptive optimal output regulation of linear systems,” IEEE Trans. Autom. Control, vol. 61, no. 12, pp. 4164–4169, Dec. 2016. doi: 10.1109/TAC.2016.2548662
|
| [14] |
D. Wang, J. Wang, M. Zhao, P. Xin, and J. Qiao, “Adaptive multi-step evaluation design with stability guarantee for discrete-time optimal learning control,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 9, pp. 1797–1809, Sept. 2023. doi: 10.1109/JAS.2023.123684
|
| [15] |
K. G. Vamvoudakis and F. L. Lewis, “Online actor–critic algorithm to solve the continuous-time infinite horizon optimal control problem,” Automatica, vol. 46, no. 5, pp. 878–888, May 2010. doi: 10.1016/j.automatica.2010.02.018
|
| [16] |
R. Kamalapurkar, J. A. Rosenfeld, and W. E. Dixon, “Efficient model-based reinforcement learning for approximate online optimal control,” Automatica, vol. 74, pp. 247–258, Dec. 2016. doi: 10.1016/j.automatica.2016.08.004
|
| [17] |
D. Wang and X. Zhong, “Advanced policy learning near-optimal regulation,” IEEE/CAA J. Autom. Sinica, vol. 6, no. 3, pp. 743–749, May 2019. doi: 10.1109/JAS.2019.1911489
|
| [18] |
F. L. Lewis and D. Liu, Reinforcement Learning and Approximate Dynamic Programming for Feedback Control. Hoboken, USA: John Wiley & Sons, Ltd, 2012.
|
| [19] |
M. Ha, D. Wang, and D. Liu, “Discounted iterative adaptive critic designs with novel stability analysis for tracking control,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 7, pp. 1262–1272, Jul. 2022. doi: 10.1109/JAS.2022.105692
|
| [20] |
Y. Yang, D. C. Wunsch, and Y. Yin, “Hamiltonian-driven adaptive dynamic programming for continuous nonlinear dynamical systems,” IEEE Trans. Neural Netw. Learning Syst., vol. 28, no. 8, pp. 1929–1940, Aug. 2017. doi: 10.1109/TNNLS.2017.2654324
|
| [21] |
S. Bhasin, R. Kamalapurkar, M. Johnson, K. G. Vamvoudakis, F. L. Lewis, and W. E. Dixon, “A novel actor-critic-identifier architecture for approximate optimal control of uncertain nonlinear systems,” Automatica, vol. 49, no. 1, pp. 82–92, Jan. 2013. doi: 10.1016/j.automatica.2012.09.019
|
| [22] |
G. Chowdhary, T. Yucelen, M. Mühlegg, and E. N. Johnson, “Concurrent learning adaptive control of linear systems with exponentially convergent bounds,” Int. J. Adapt. Control Signal Process., vol. 27, no. 4, pp. 280–301, Apr. 2013. doi: 10.1002/acs.2297
|
| [23] |
S. K. Jha, S. B. Roy, and S. Bhasin, “Initial excitation-based iterative algorithm for approximate optimal control of completely unknown LTI systems,” IEEE Trans. Autom. Control, vol. 64, no. 12, pp. 5230–5237, Dec. 2019. doi: 10.1109/TAC.2019.2912828
|
| [24] |
B. Kiumarsi, F. L. Lewis, and Z. P. Jiang, “H∞ control of linear discrete-time systems: Off-policy reinforcement learning,” Automatica, vol. 78, pp. 144–152, Apr. 2017. doi: 10.1016/j.automatica.2016.12.009
|
| [25] |
Y. Yang, B. Kiumarsi, H. Modares, and C. Xu, “Model-free λ-policy iteration for discrete-time linear quadratic regulation,” IEEE Trans. Neural Netw. Learning Syst., vol. 34, no. 2, pp. 635–649, Feb. 2023. doi: 10.1109/TNNLS.2021.3098985
|
| [26] |
S. Adam, L. Busoniu, and R. Babuska, “Experience replay for real-time reinforcement learning control,” IEEE Trans. Syst., Man, Cybernetics, Part C (Appl. Rev.), vol. 42, no. 2, pp. 201–212, Mar. 2012. doi: 10.1109/TSMCC.2011.2106494
|
| [27] |
L. J. Lin, “Self-improving reactive agents based on reinforcement learning, planning and teaching,” Mach. Learn., vol. 8, no. 3, pp. 293–321, May 1992. doi: 10.1023/A:1022628806385
|
| [28] |
R. Liu and J. Zou, “The effects of memory replay in reinforcement learning,” in Proc. 56th Annu. Allerton Conf. Communication, Control, and Computing, Monticello, USA, 2018, pp. 478-485.
|
| [29] |
R. Kamalapurkar, B. Reish, G. Chowdhary, and W. E. Dixon, “Concurrent learning for parameter estimation using dynamic state-derivative estimators,” IEEE Trans. Autom. Control, vol. 62, no. 7, pp. 3594–3601, Jul. 2017. doi: 10.1109/TAC.2017.2671343
|
| [30] |
G. Chowdhary, “Concurrent learning for convergence in adaptive control without persistency of excitation,” Ph.D. dissertation, Georgia Institute of Technology, Atlanta, USA, 2010.
|
| [31] |
G. Chowdhary, M. Mühlegg, and E. Johnson, “Exponential parameter and tracking error convergence guarantees for adaptive controllers without persistency of excitation,” Int. J. Control, vol. 87, no. 8, pp. 1583–1603, May 2014. doi: 10.1080/00207179.2014.880128
|
| [32] |
R. Kamalapurkar, P. Walters, and W. E. Dixon, “Model-based reinforcement learning for approximate optimal regulation,” Automatica, vol. 64, pp. 94–104, Feb. 2016. doi: 10.1016/j.automatica.2015.10.039
|
| [33] |
K. G. Vamvoudakis, M. F. Miranda, and J. P. Hespanha, “Asymptotically stable adaptive–optimal control algorithm with saturating actuators and relaxed persistence of excitation,” IEEE Trans. Neural Netw. Learning Syst., vol. 27, no. 11, pp. 2386–2398, Nov. 2016. doi: 10.1109/TNNLS.2015.2487972
|
| [34] |
R. Kamalapurkar, H. Dinh, S. Bhasin, and W. E. Dixon, “Approximate optimal trajectory tracking for continuous-time nonlinear systems,” Automatica, vol. 51, pp. 40–48, Jan. 2015. doi: 10.1016/j.automatica.2014.10.103
|
| [35] |
Y. Yang, K. G. Vamvoudakis, H. Modares, Y. Yin, and D. C. Wunsch, “Hamiltonian-driven hybrid adaptive dynamic programming,” IEEE Trans. Syst., Man, Cybernetics: Syst., vol. 51, no. 10, pp. 6423–6434, Oct. 2021. doi: 10.1109/TSMC.2019.2962103
|
| [36] |
G. Chowdhary and E. Johnson, “A singular value maximizing data recording algorithm for concurrent learning,” in Proc. American Control Conf., San Francisco, USA, 2011, pp. 3547−3552.
|
| [37] |
Y. Pan and H. Yu, “Composite learning from adaptive dynamic surface control,” IEEE Trans. Autom. Control, vol. 61, no. 9, pp. 2603–2609, Sept. 2016. doi: 10.1109/TAC.2015.2495232
|
| [38] |
Y. Pan and H. Yu, “Composite learning robot control with guaranteed parameter convergence,” Automatica, vol. 89, pp. 398–406, Mar. 2018. doi: 10.1016/j.automatica.2017.11.032
|
| [39] |
K. Guo, Y. Pan, D. Zheng, and H. Yu, “Composite learning control of robotic systems: A least squares modulated approach,” Automatica, vol. 111, p. 108612, Jan. 2020. doi: 10.1016/j.automatica.2019.108612
|
| [40] |
H. Dong, Q. Hu, M. R. Akella, and H. Yang, “Composite adaptive attitude-tracking control with parameter convergence under finite excitation,” IEEE Trans. Control Syst. Technol., vol. 28, no. 6, pp. 2657–2664, Nov. 2020. doi: 10.1109/TCST.2019.2942802
|
| [41] |
H. Modares and F. L. Lewis, “Optimal tracking control of nonlinear partially-unknown constrained-input systems using integral reinforcement learning,” Automatica, vol. 50, no. 7, pp. 1780–1792, Jul. 2014. doi: 10.1016/j.automatica.2014.05.011
|
| [42] |
M. Abu-Khalaf and F. L. Lewis, “Nearly optimal control laws for nonlinear systems with saturating actuators using a neural network HJB approach,” Automatica, vol. 41, no. 5, pp. 779–791, May 2005. doi: 10.1016/j.automatica.2004.11.034
|
| [43] |
A. Al-Tamimi, F. L. Lewis, and M. Abu-Khalaf, “Discrete-time nonlinear HJB solution using approximate dynamic programming: Convergence proof,” IEEE Trans. Syst., Man, Cybernetics, Part B, vol. 38, no. 4, pp. 943–949, Aug. 2008. doi: 10.1109/TSMCB.2008.926614
|
| [44] |
F. L. Lewis, S. Jagannathan, and A. Yesildirak, Neural Network Control of Robot Manipulators and Non-linear Systems. London, UK: CRC Press, 1998.
|
| [45] |
P. A. Ioannou and J. Sun, Robust Adaptive Control. Hoboken, USA: Prentice-Hall, Inc., 1995.
|
| [46] |
N. Cho, H. S. Shin, Y. Kim, and A. Tsourdos, “Composite model reference adaptive control with parameter convergence under finite excitation,” IEEE Trans. Autom. Control, vol. 63, no. 3, pp. 811–818, Mar. 2018. doi: 10.1109/TAC.2017.2737324
|
| [47] |
C. Possieri and M. Sassano, “Data-driven policy iteration for nonlinear optimal control problems,” IEEE Trans. Neural Netw. Learning Syst., vol. 34, no. 10, pp. 7365–7376, Oct. 2023. doi: 10.1109/TNNLS.2022.3142501
|
| [48] |
K. Hornik, M. Stinchcombe, and H. White, “Universal approximation of an unknown mapping and its derivatives using multilayer feedforward networks,” Neural Networks, vol. 3, no. 5, pp. 551–560, 1990. doi: 10.1016/0893-6080(90)90005-6
|
| [49] |
B. A. Finlayson, The Method of Weighted Residuals and Variational Principles. Philadelphia, USA: Society for Industrial and Applied Mathematics, 2013.
|
| [50] |
M. M. Peet, “Exponentially stable nonlinear systems have polynomial Lyapunov functions on bounded regions,” IEEE Trans. Autom. Control, vol. 54, no. 5, pp. 979–987, May 2009. doi: 10.1109/TAC.2009.2017116
|
| [51] |
S. Basu Roy, S. Bhasin, and I. Narayan Kar, “A UGES switched MRAC architecture using initial excitation,” IFAC-PapersOnLine, vol. 50, no. 1, pp. 7044–7051, Jul. 2017. doi: 10.1016/j.ifacol.2017.08.1350
|
| [52] |
O. Djaneye-Boundjou and R. Ordóñez, “Gradient-based discrete-time concurrent learning for standalone function approximation,” IEEE Trans. Autom. Control, vol. 65, no. 2, pp. 749–756, Feb. 2020. doi: 10.1109/TAC.2019.2920087
|
| [53] |
W. Haddad and V. Chellaboina, Nonlinear Dynamical Systems and Control: A Lyapunov-Based Approach. Princeton, USA: Princeton University Press, 2008.
|
| [54] |
H. K. Khalil, Nonlinear Systems. 3rd ed. Upper Saddle River, USA: Prentice Hall, 2001.
|
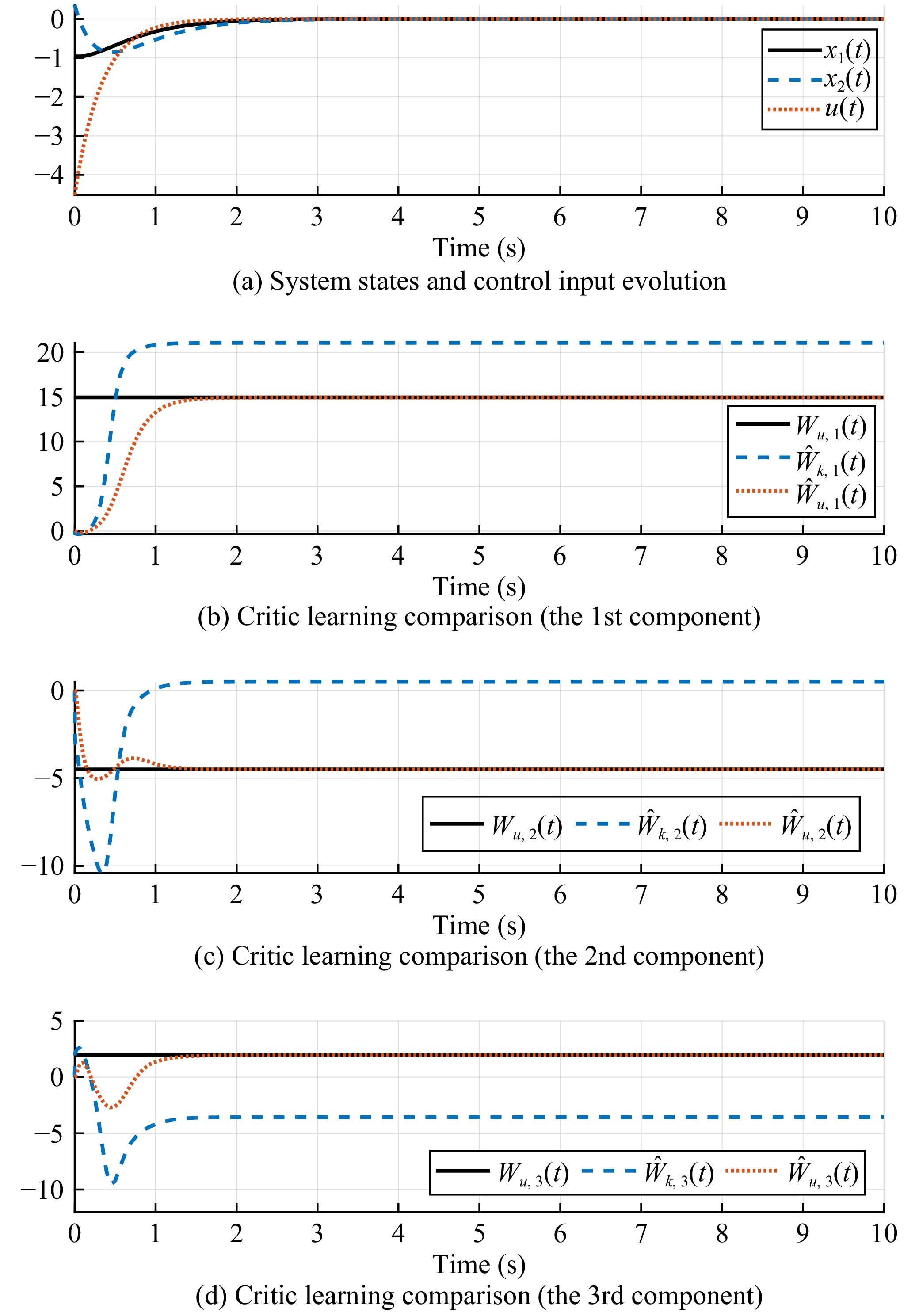
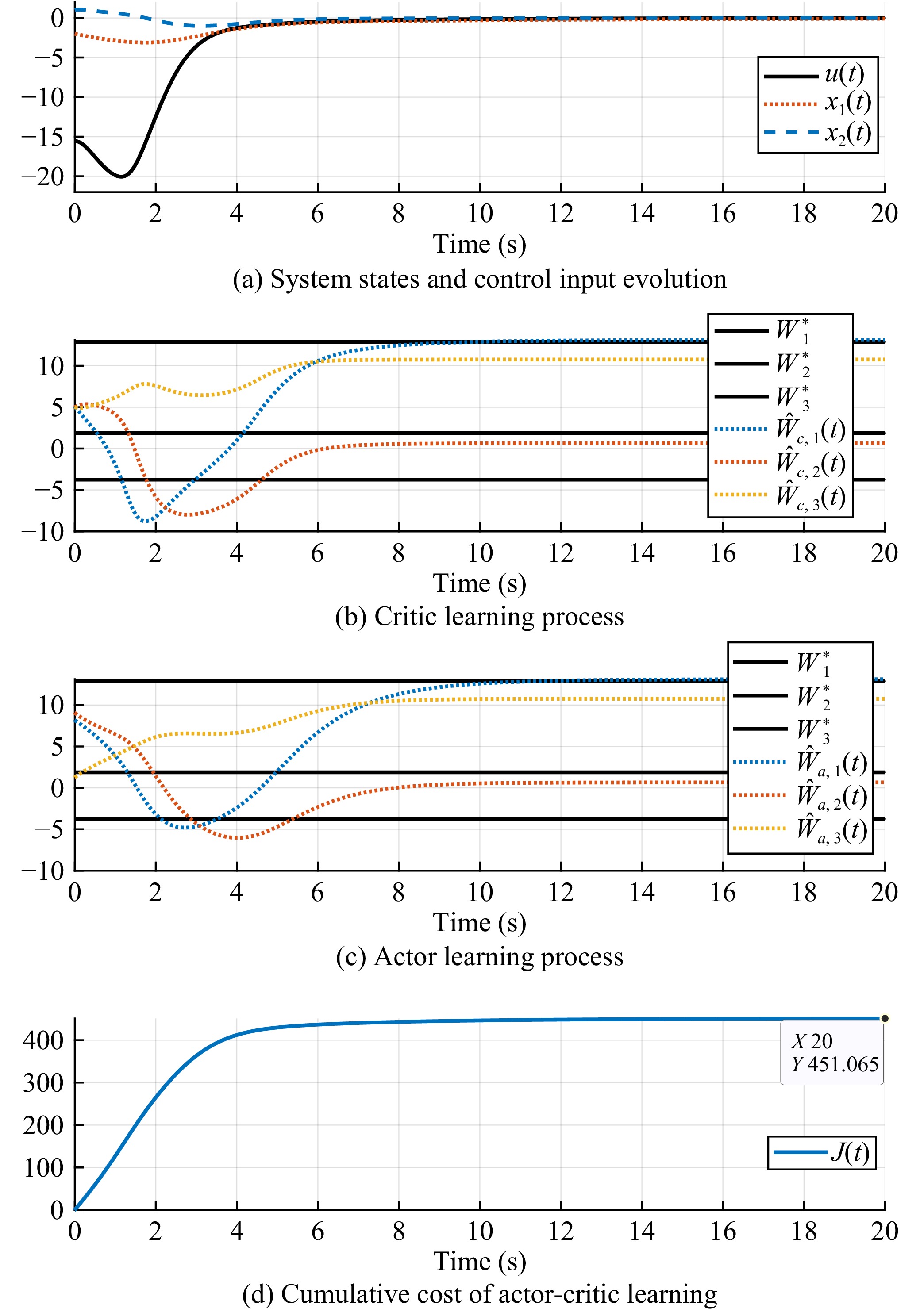
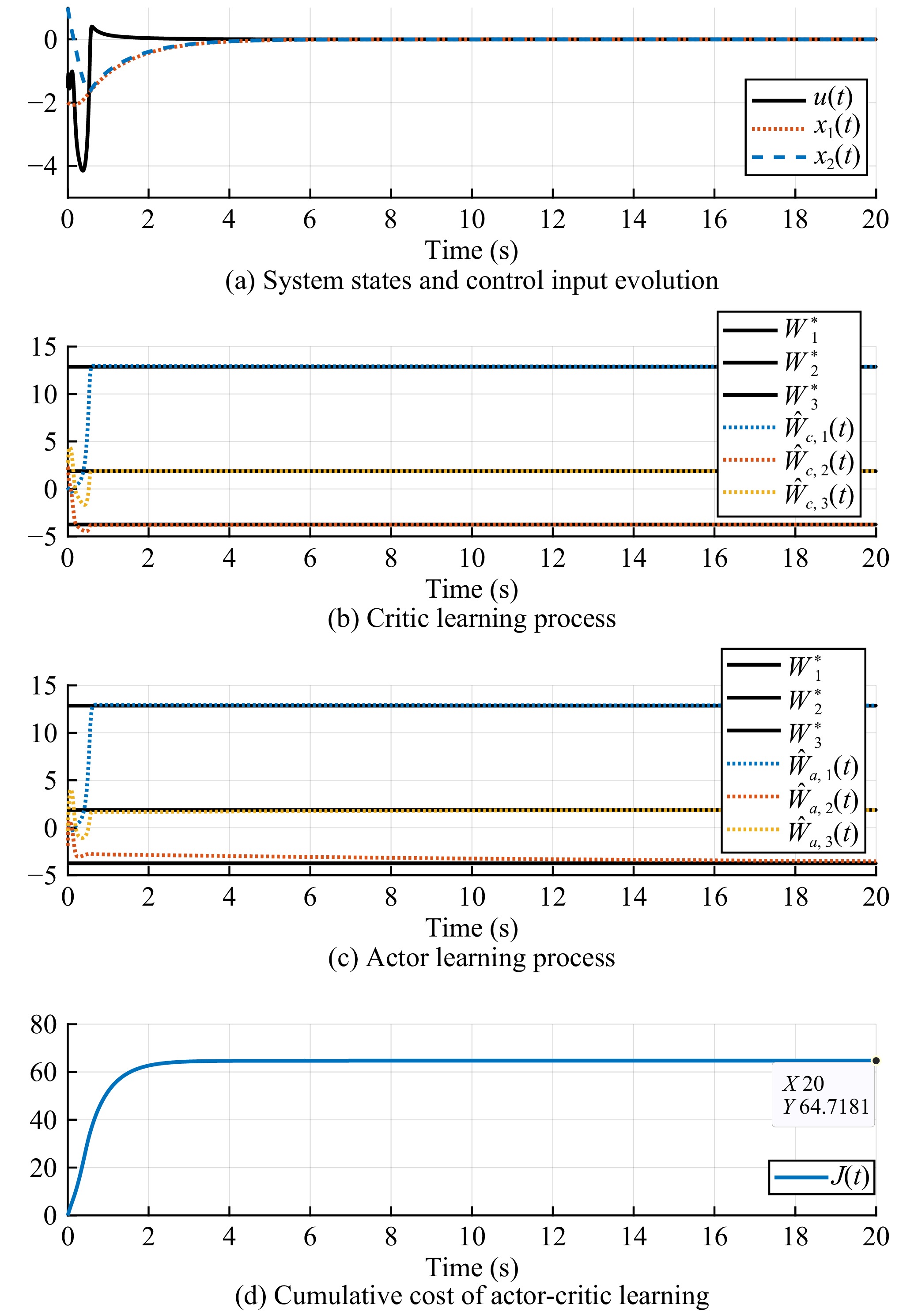
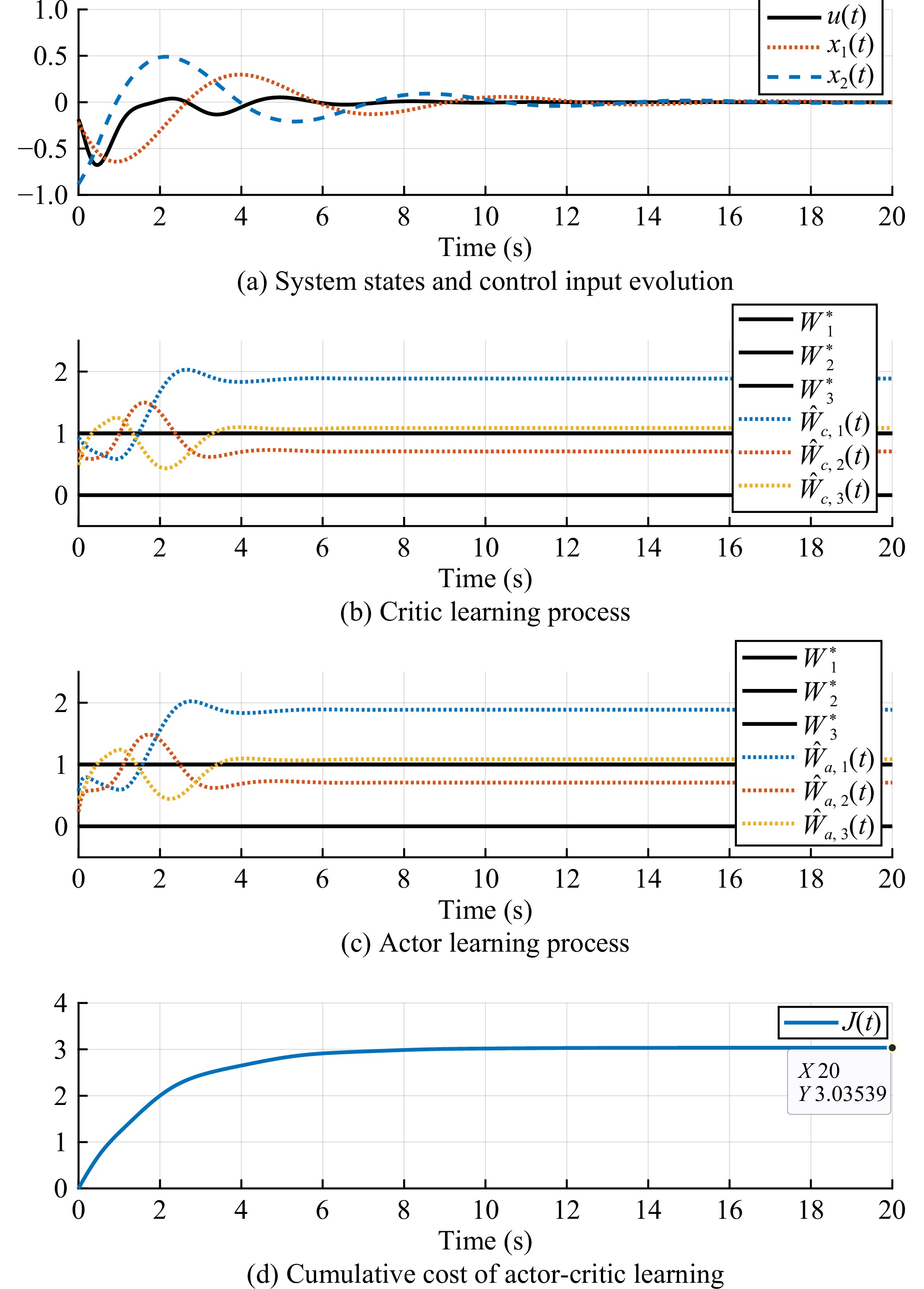
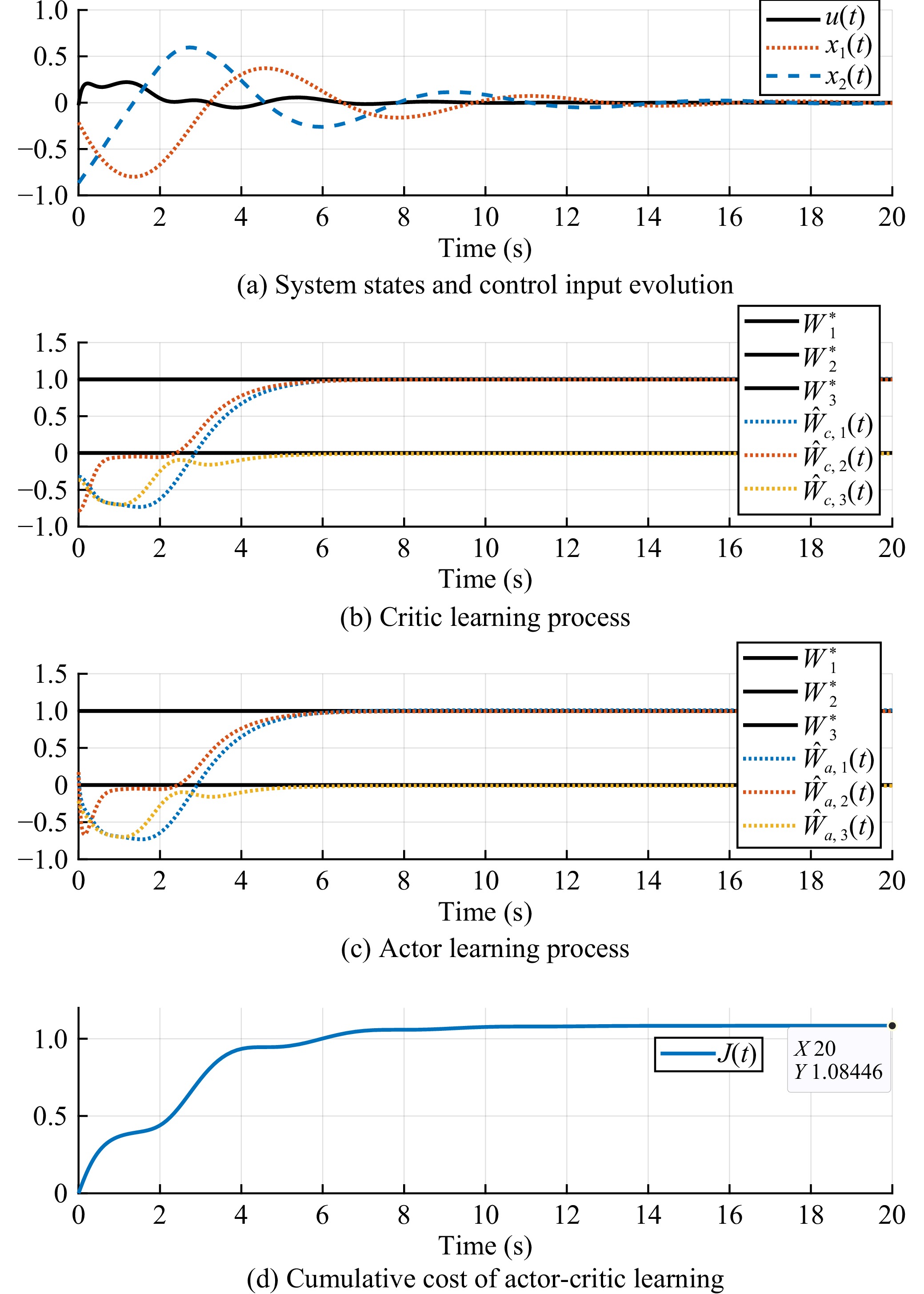
Figures(5)






 DownLoad:
DownLoad: