A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 11
Issue 7
Volume 11
Issue 7
IEEE/CAA Journal of Automatica Sinica
| Citation: | K. Jiang, W. Liu, Y. Wang, L. Dong, and C. Sun, “Discovering latent variables for the tasks with confounders in multi-agent reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 7, pp. 1591–1604, Jul. 2024. doi: 10.1109/JAS.2024.124281

|
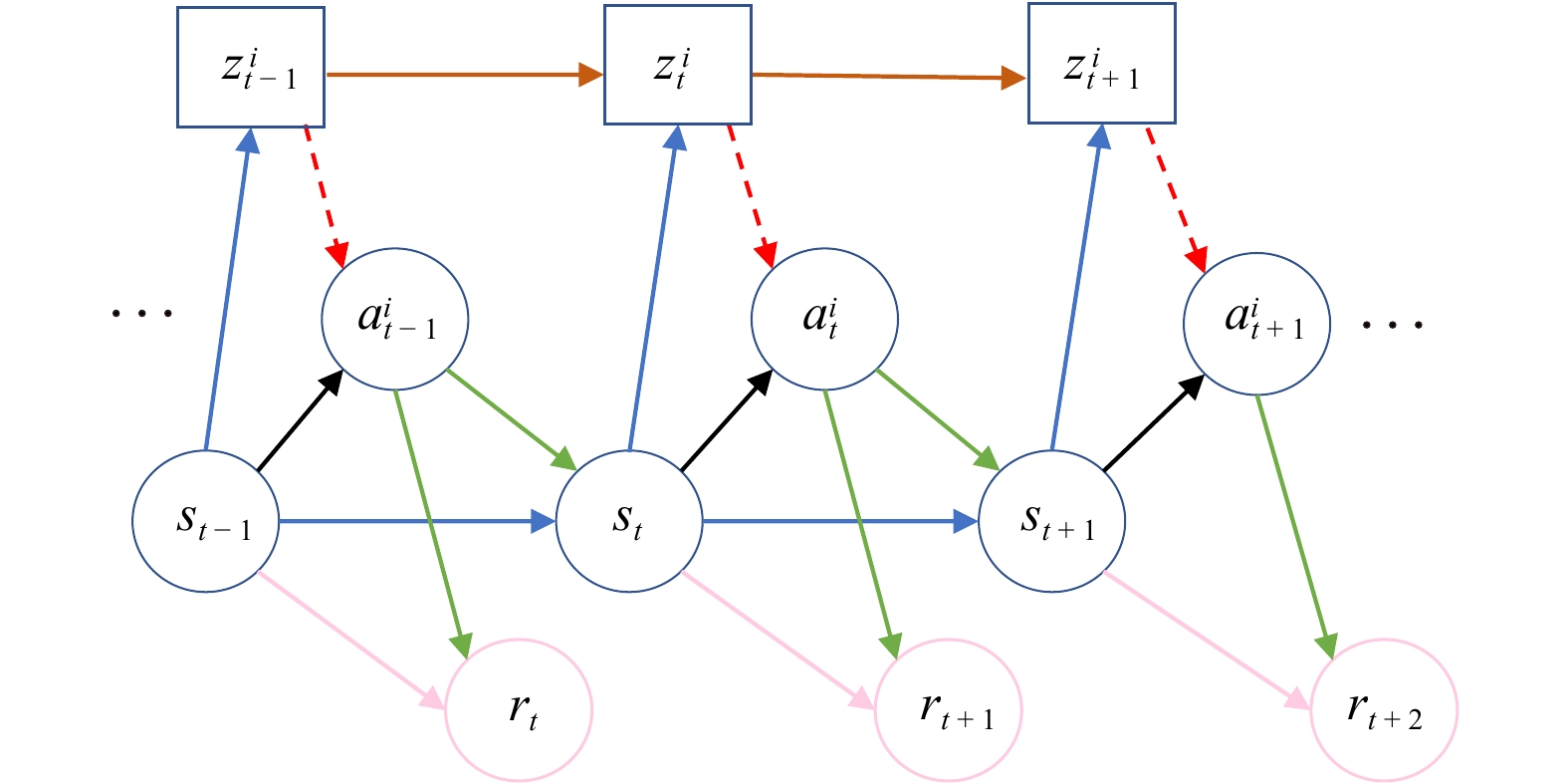
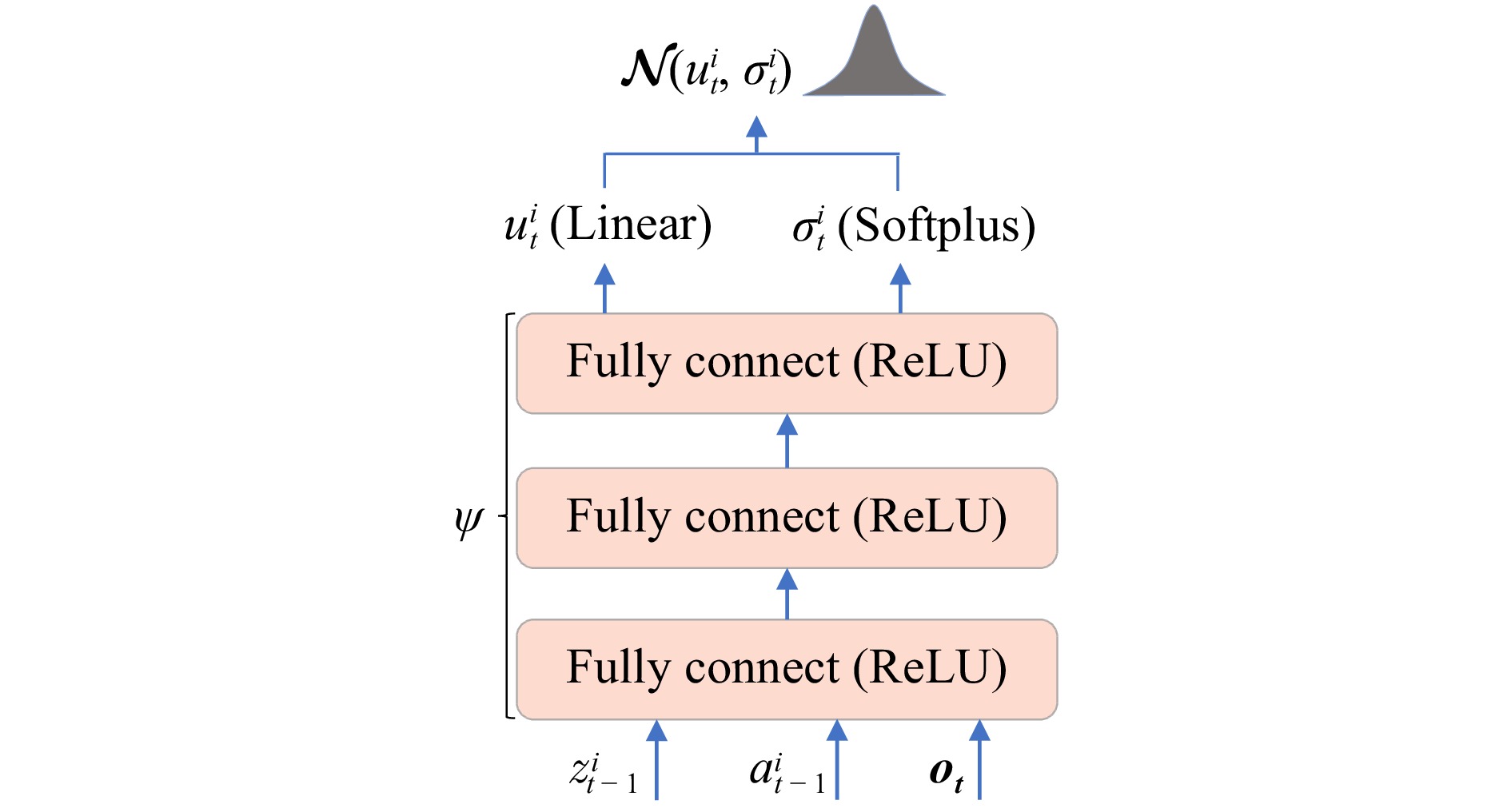
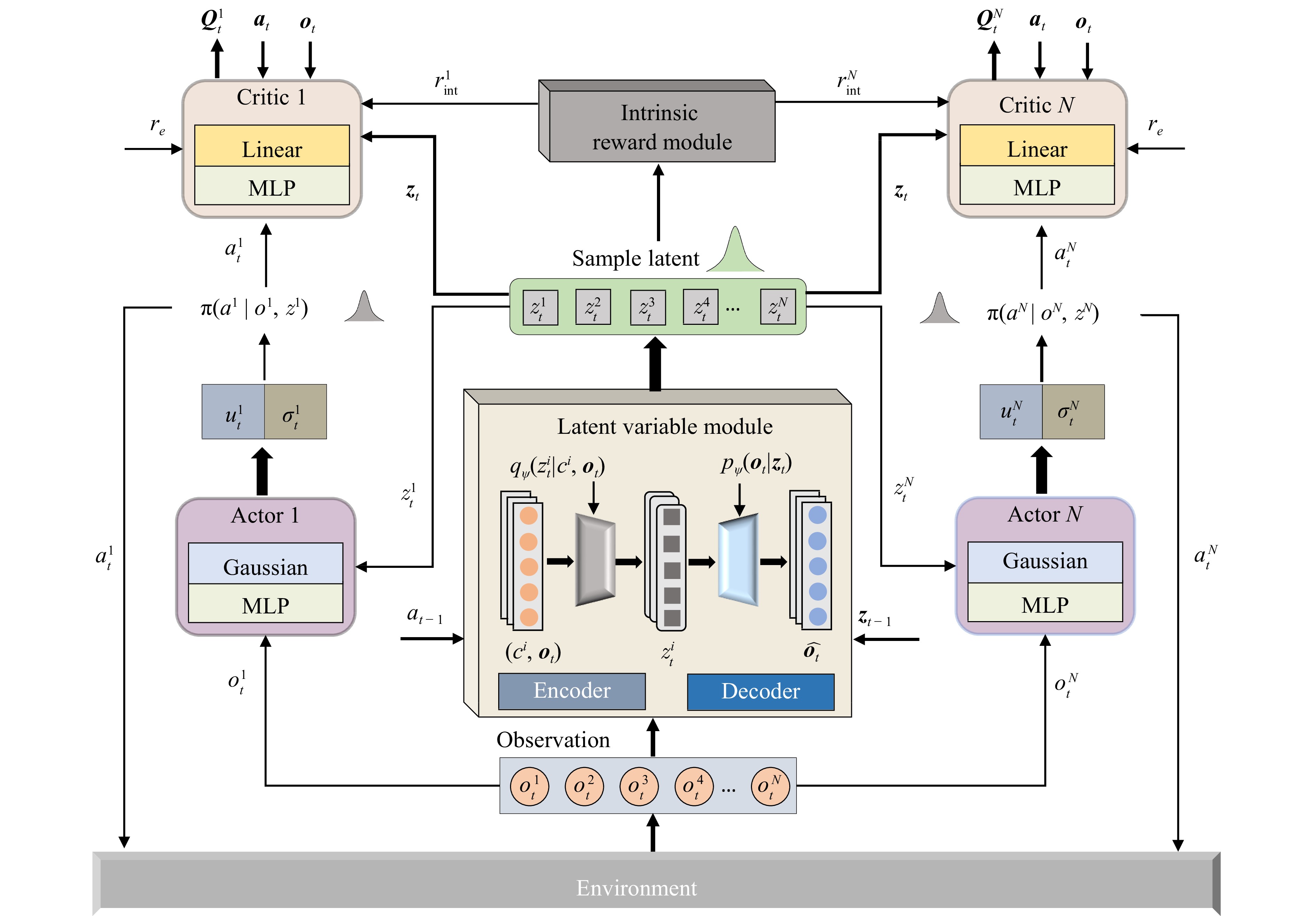
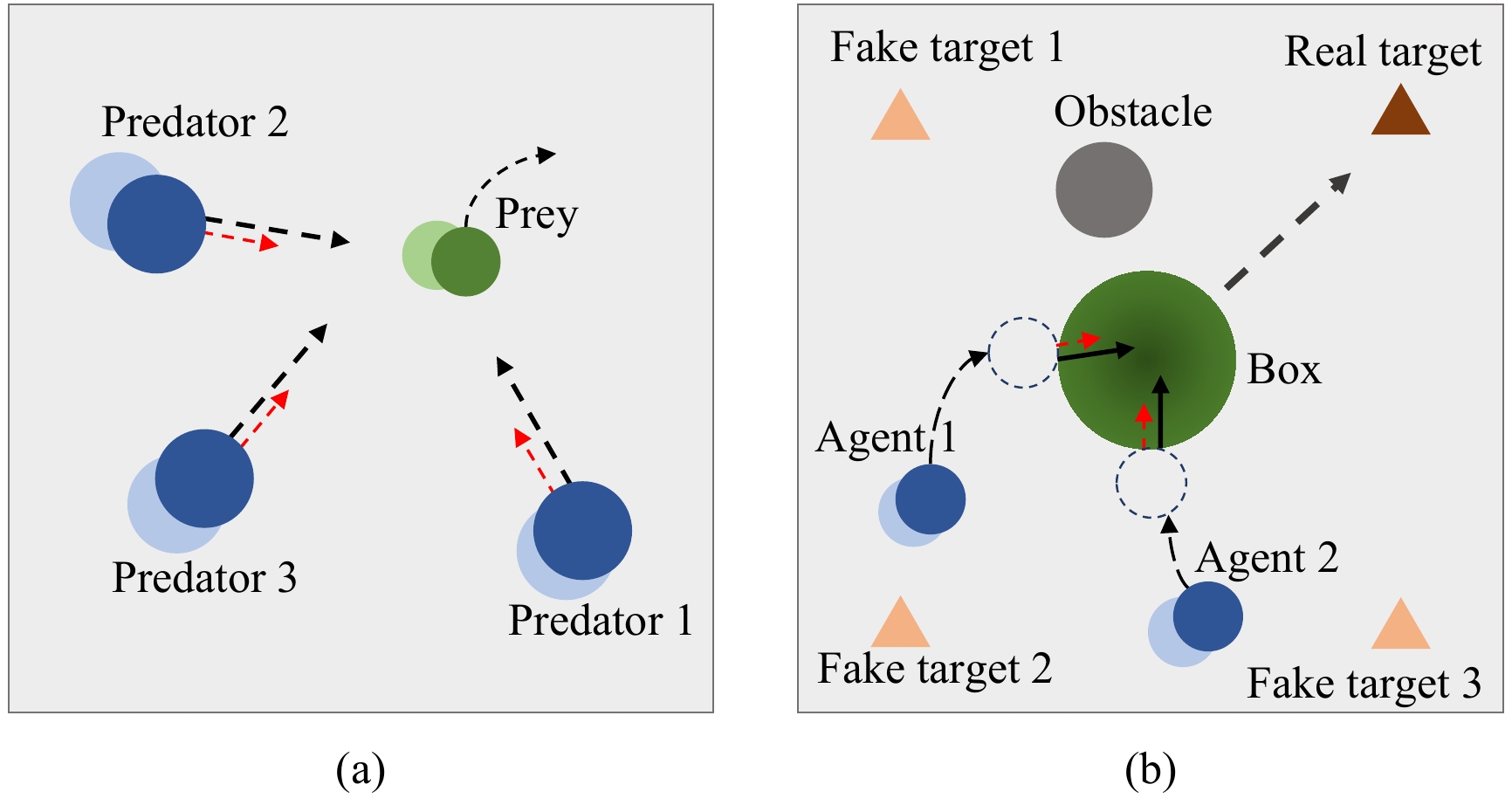
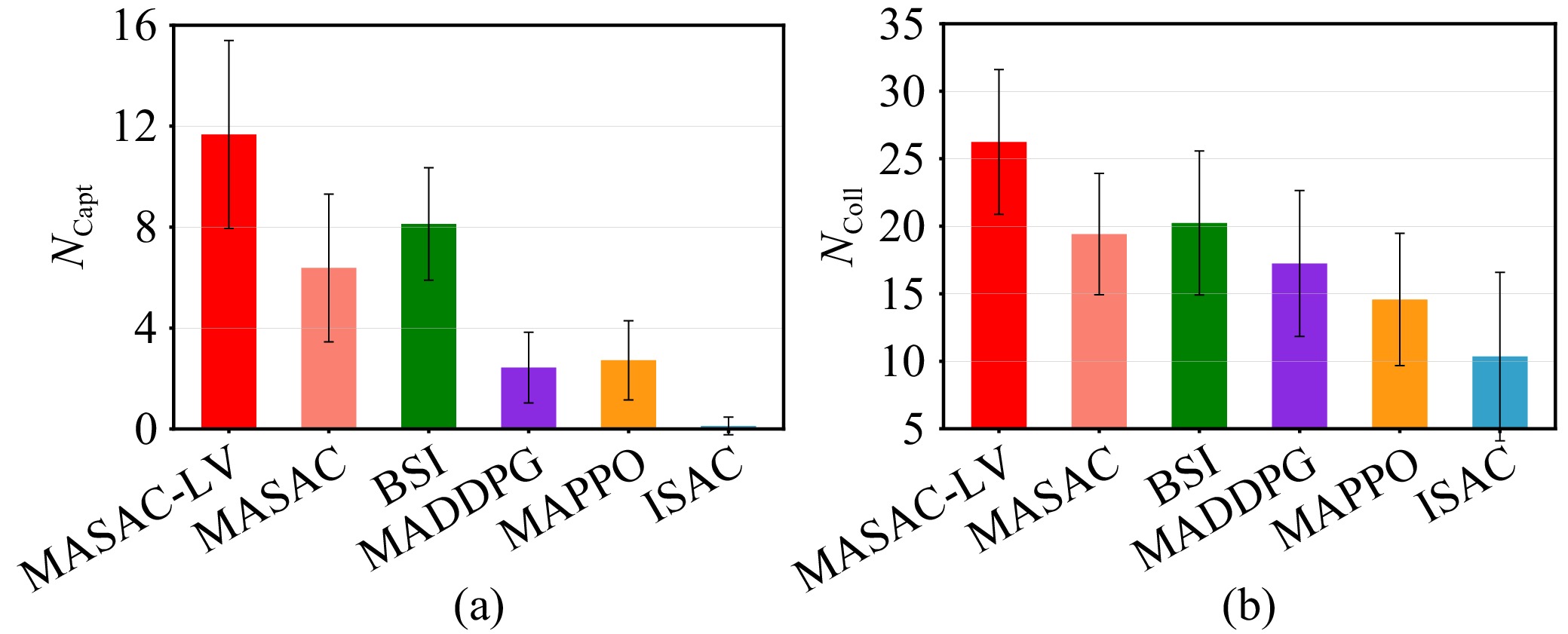
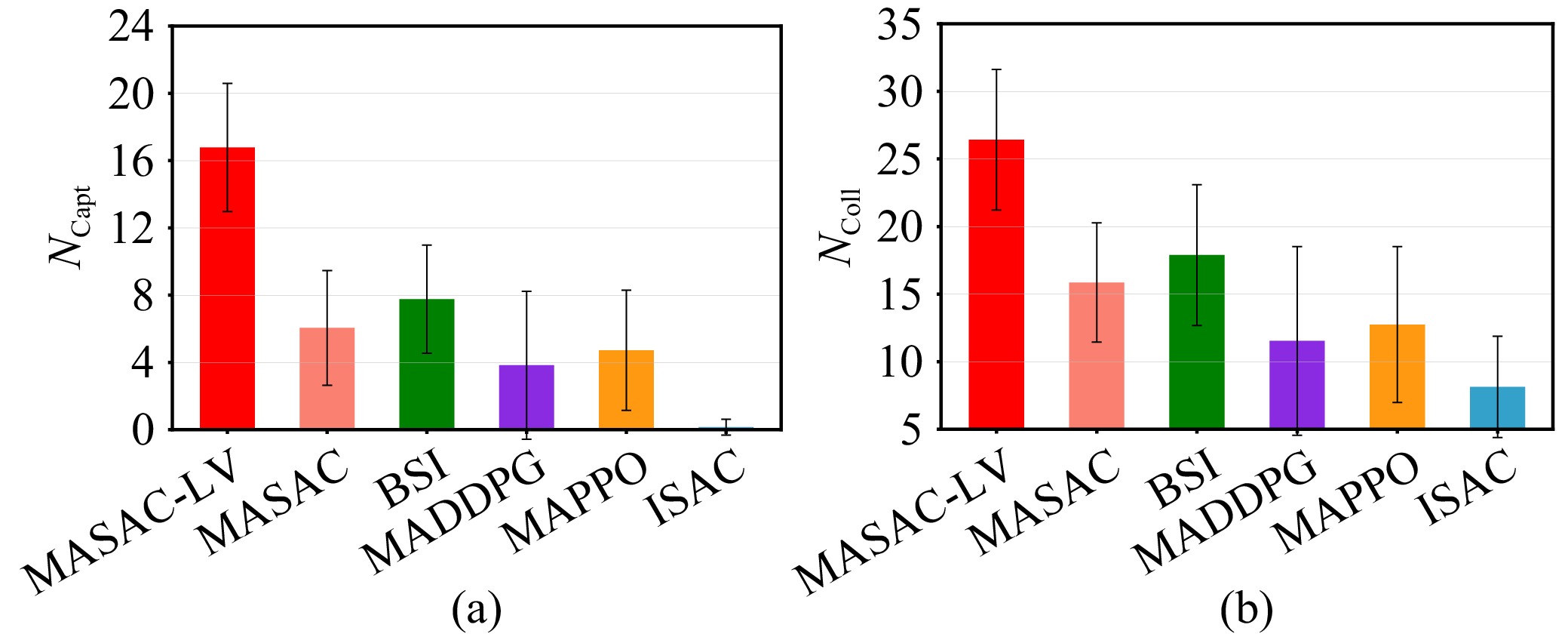
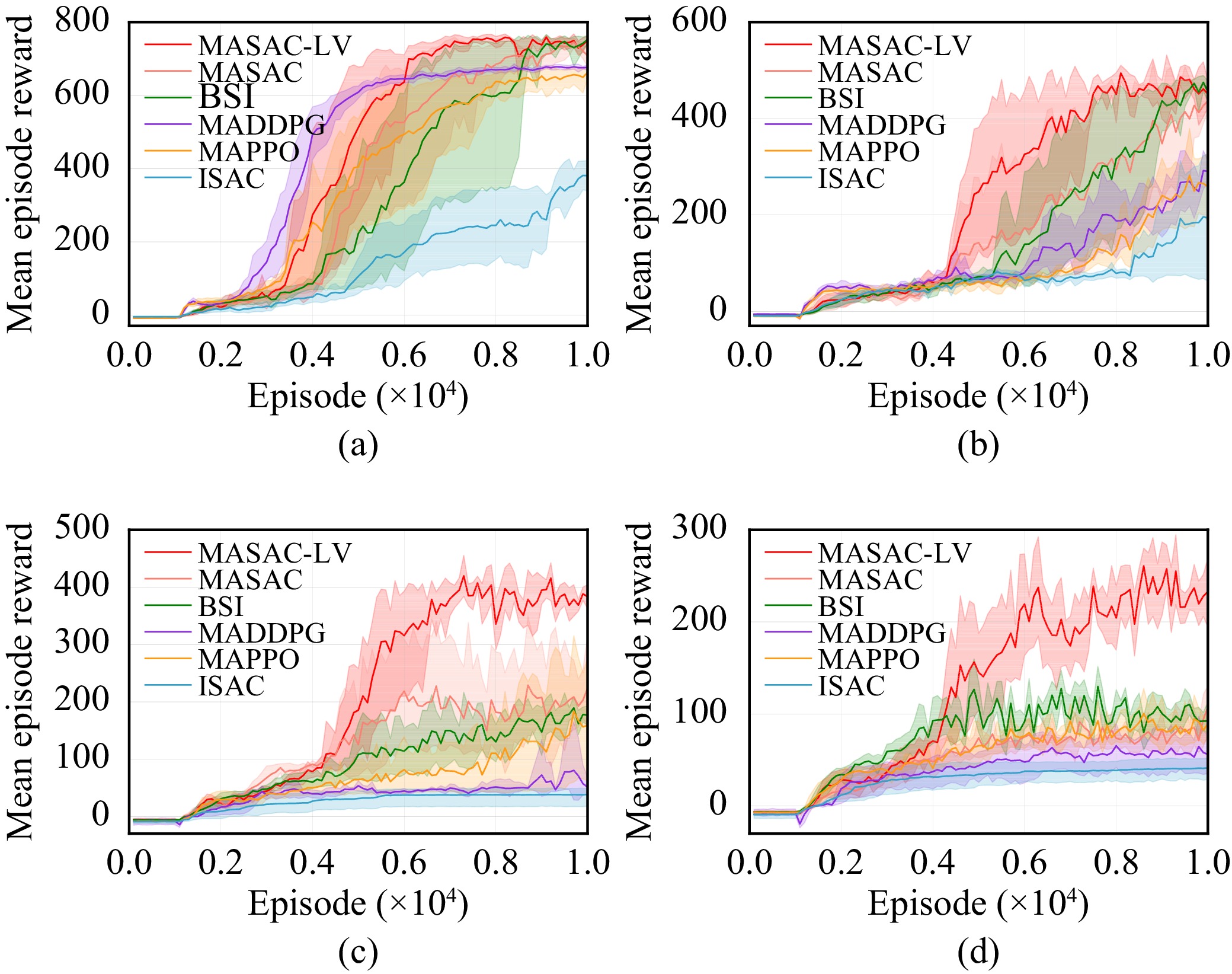
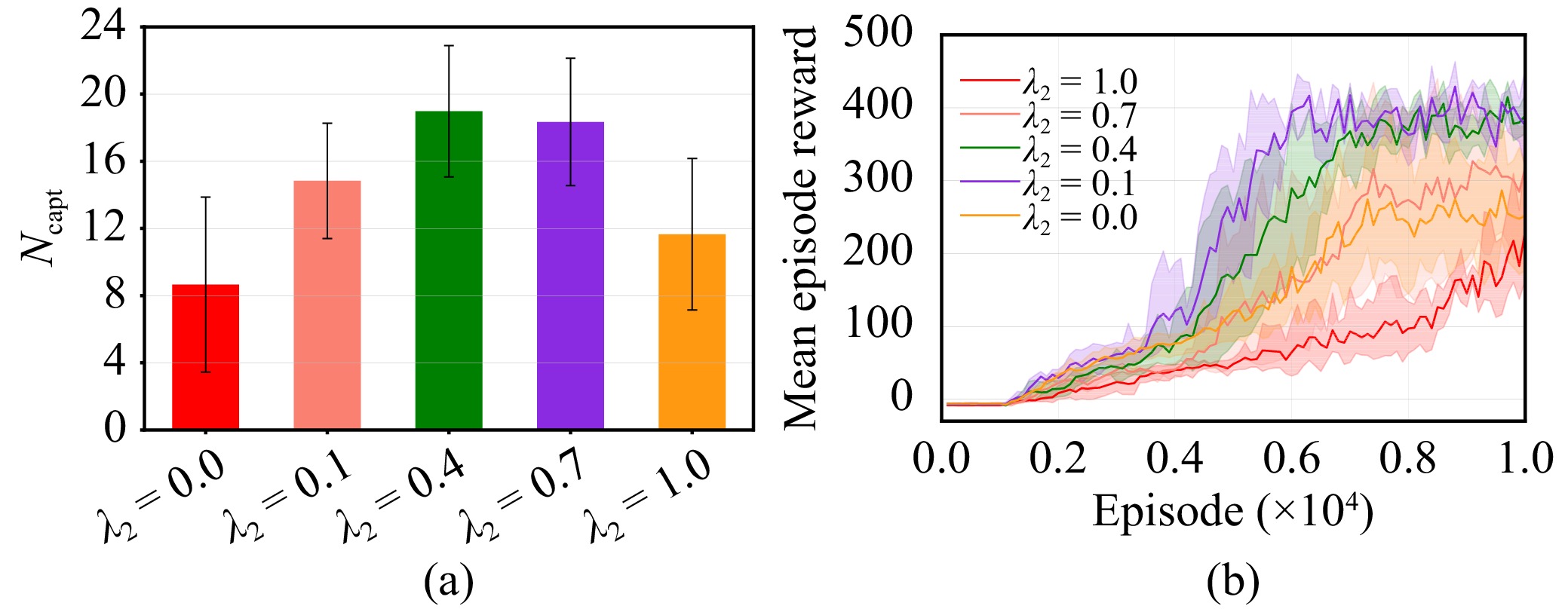
Efficient exploration in complex coordination tasks has been considered a challenging problem in multi-agent reinforcement learning (MARL). It is significantly more difficult for those tasks with latent variables that agents cannot directly observe. However, most of the existing latent variable discovery methods lack a clear representation of latent variables and an effective evaluation of the influence of latent variables on the agent. In this paper, we propose a new MARL algorithm based on the soft actor-critic method for complex continuous control tasks with confounders. It is called the multi-agent soft actor-critic with latent variable (MASAC-LV) algorithm, which uses variational inference theory to infer the compact latent variables representation space from a large amount of offline experience. Besides, we derive the counterfactual policy whose input has no latent variables and quantify the difference between the actual policy and the counterfactual policy via a distance function. This quantified difference is considered an intrinsic motivation that gives additional rewards based on how much the latent variable affects each agent. The proposed algorithm is evaluated on two collaboration tasks with confounders, and the experimental results demonstrate the effectiveness of MASAC-LV compared to other baseline algorithms.

| [1] |
K. Wang and C. Mu, “Learning-based control with decentralized dynamic event-triggering for vehicle systems,” IEEE Trans. Industrial Informatics, vol. 19, no. 3, pp. 2629–2639, 2023. doi: 10.1109/TII.2022.3168034
|
| [2] |
C. Mu, K. Wang, and T. Qiu, “Dynamic event-triggering neural learning control for partially unknown nonlinear systems,” IEEE Trans. Cyber., vol. 52, no. 4, pp. 2200–2213, 2022. doi: 10.1109/TCYB.2020.3004493
|
| [3] |
J. Ibarz, J. Tan, C. Finn, M. Kalakrishnan, P. Pastor, and S. Levine, “How to train your robot with deep reinforcement learning: Lessons we have learned,” Int. J. Robotics Research, vol. 40, no. 4–5, pp. 698–721, 2021. doi: 10.1177/0278364920987859
|
| [4] |
P. Liu, D. Tateo, H. B. Ammar, and J. Peters, “Robot reinforcement learning on the constraint manifold,” in Proc. 5th Conf. Robot Learning, 2022, vol. 164, pp. 1357–1366.
|
| [5] |
L. Tai, G. Paolo, and M. Liu, “Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation,” in Proc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems, 2017, pp. 31–36.
|
| [6] |
M. G. Bellemare, S. Candido, P. S. Castro, J. Gong, M. C. Machado, S. Moitra, S. S. Ponda, and Z. Wang, “Autonomous navigation of stratospheric balloons using reinforcement learning,” Nature, vol. 588, no. 7836, pp. 77–82, 2020. doi: 10.1038/s41586-020-2939-8
|
| [7] |
O. Vinyals, I. Babuschkin, W. M. Czarnecki, et al., “Grandmaster level in starcraft II using multi-agent reinforcement learning,” Nature, vol. 575, no. 7782, pp. 350–354, 2019. doi: 10.1038/s41586-019-1724-z
|
| [8] |
C. Sun, W. Liu, and L. Dong, “Reinforcement learning with task decomposition for cooperative multiagent systems,” IEEE Trans. Neural Networks Learn. Syst., vol. 32, no. 5, pp. 2054–2065, 2021. doi: 10.1109/TNNLS.2020.2996209
|
| [9] |
H. J. Bae and P. Koumoutsakos, “Scientific multi-agent reinforcement learning for wall-models of turbulent flows,” Nature Communications, vol. 13, no. 1, pp. 1–9, 2022. doi: 10.1038/s41467-021-27699-2
|
| [10] |
W. Liu, W. Cai, K. Jiang, G. Cheng, Y. Wang, J. Wang, J. Cao, L. Xu, C. Mu, and C. Sun, “XUANCE: A comprehensive and unified deep reinforcement learning library,” arXiv preprint arXiv: 2312.16248, 2023.
|
| [11] |
G. Papoudakis, F. Christianos, A. Rahman, and S. V. Albrecht, “Dealing with non-stationarity in multi-agent deep reinforcement learning,” [Online], Available: https://arxiv.org/abs/1906.04737, 2019.
|
| [12] |
L. Canese, G. C. Cardarilli, L. Di Nunzio, R. Fazzolari, D. Giardino, M. Re, and S. Spanò, “Multi-agent reinforcement learning: A review of challenges and applications,” Applied Sciences, vol. 11, p. 11, 2021.
|
| [13] |
M. Zhou, Z. Liu, P. Sui, Y. Li, and Y. Chung, “Learning implicit credit assignment for cooperative multi-agent reinforcement learning,” Advances in Neural Information Processing Systems, vol. 33, pp. 11853–11864, 2020.
|
| [14] |
W. Liu, L. Dong, J. Liu, and C. Sun, “Knowledge transfer in multi-agent reinforcement learning with incremental number of agents,” J. Systems Engineering and Electronics, vol. 33, no. 2, pp. 447–460, 2022. doi: 10.23919/JSEE.2022.000045
|
| [15] |
W. Liu, L. Dong, D. Niu, and C. Sun, “Efficient exploration for multiagent reinforcement learning via transferable successor features,” IEEE CAA J. Autom. Sinica, vol. 9, no. 9, pp. 1673–1686, 2022. doi: 10.1109/JAS.2022.105809
|
| [16] |
S. Omidshafiei, J. Pazis, C. Amato, J. P. How, and J. Vian, “Deep decentralized multi-task multi-agent reinforcement learning under partial observability,” in Proc. Int. Conf. Machine Learning, 2017, pp. 2681–2690.
|
| [17] |
C. S. de Witt, B. Peng, P. Kamienny, P. H. S. Torr, W. Böhmer, and S. Whiteson, “Deep multi-agent reinforcement learning for decentralized continuous cooperative control,” [Online], Available: https://arxiv.org/abs/2003.06709, 2020.
|
| [18] |
J. Su, S. C. Adams, and P. A. Beling, “Value-decomposition multi-agent actor-critics,” in Proc. 35th AAAI Conf. Artificial Intelligence, 2021, pp. 11352–11360.
|
| [19] |
J. Li, K. Kuang, B. Wang, F. Liu, L. Chen, C. Fan, F. Wu, and J. Xiao, “Deconfounded value decomposition for multi-agent reinforcement learning,” in Proc. Int. Conf. Machine Learning, 2022, vol. 162, pp. 12843–12856.
|
| [20] |
R. Zohar, S. Mannor, and G. Tennenholtz, “Locality matters: A scalable value decomposition approach for cooperative multi-agent reinforcement learning,” in Proc. AAAI Conf. Artificial Intelligence, 2022, vol. 36, no. 8, pp. 9278–9285.
|
| [21] |
T. Zhang, Y. Li, C. Wang, G. Xie, and Z. Lu, “FOP: Factorizing optimal joint policy of maximum-entropy multi-agent reinforcement learning,” in Proc. 38th Int. Conf. Machine Learning, 2021, vol. 139, pp. 12491–12500.
|
| [22] |
Y. Chen, K. Wang, G. Song, and X. Jiang, “Entropy enhanced multiagent coordination based on hierarchical graph learning for continuous action space,” [Online], Available: https://arxiv.org/abs/2208.10676, 2022.
|
| [23] |
A. X. Lee, A. Nagabandi, P. Abbeel, and S. Levine, “Stochastic latent actor-critic: Deep reinforcement learning with a latent variable model,” Advances in Neural Information Processing Systems, vol. 33, pp. 741–752, 2020.
|
| [24] |
S. A. Sontakke, A. Mehrjou, L. Itti, and B. Schölkopf, “Causal curiosity: RL agents discovering self-supervised experiments for causal representation learning,” in Proc. 38th Int. Conf. Machine Learning, 2021, vol. 139, pp. 9848–9858.
|
| [25] |
N. Jaques, A. Lazaridou, E. Hughes, Ç. Gülçehre, P. A. Ortega, D. Strouse, J. Z. Leibo, and N. de Freitas, “Social influence as intrinsic motivation for multi-agent deep reinforcement learning,” in Proc. 36th Int. Conf. Machine Learning, 2019, vol. 97, pp. 3040–3049.
|
| [26] |
L. Zheng, J. Chen, J. Wang, J. He, Y. Hu, Y. Chen, C. Fan, Y. Gao, and C. Zhang, “Episodic multi-agent reinforcement learning with curiositydriven exploration,” in Proc. Advances in Neural Information Processing Systems, 2021, pp. 3757–3769.
|
| [27] |
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv: 1312.6114, 2014.
|
| [28] |
T. Haarnoja, H. Tang, P. Abbeel, and S. Levine, “Reinforcement learning with deep energy-based policies,” in Proc. 34th Int. Conf. Machine Learning, 2017, vol. 70, pp. 1352–1361.
|
| [29] |
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Offpolicy maximum entropy deep reinforcement learning with a stochastic actor,” in Proc. 35th Int. Conf. Machine Learning, 2018, vol. 80, pp. 1856–1865.
|
| [30] |
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” arXiv preprint arXiv: 1509.02971, 2016.
|
| [31] |
M. Tan, “Multi-agent reinforcement learning: Independent vs. cooperative agents,” in Proc. 10th Int. Conf. Machine Learning, 1993, pp. 330–337.
|
| [32] |
F. A. Oliehoek, M. T. Spaan, and N. Vlassis, “Optimal and approximate q-value functions for decentralized pomdps,” J. Artificial Intelligence Research, vol. 32, pp. 289–353, 2008. doi: 10.1613/jair.2447
|
| [33] |
R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, and I. Mordatch, “Multiagent actor-critic for mixed cooperative-competitive environments,” in Proc. Advances in Neural Information Processing Systems, 2017, pp. 6379–6390.
|
| [34] |
M. Hua, C. Zhang, F. Zhang, Z. Li, X. Yu, H. Xu, and Q. Zhou, “Energy management of multi-mode plug-in hybrid electric vehicle using multiagent deep reinforcement learning,” Applied Energy, vol. 348, p. 121526, 2023. doi: 10.1016/j.apenergy.2023.121526
|
| [35] |
T. Rashid, M. Samvelyan, C. Schroeder, G. Farquhar, J. Foerster, and S. Whiteson, “QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning,” in Proc. 35th Int. Conf. Machine Learning, Jul. 2018, vol. 80, pp. 4295–4304.
|
| [36] |
J. N. Foerster, G. Farquhar, T. Afouras, N. Nardelli, and S. Whiteson, “Counterfactual multi-agent policy gradients,” in Proc. 32th AAAI Conf. Artificial Intelligence, 2018, pp. 2974–2982.
|
| [37] |
K. Jiang, W. Liu, Y. Wang, L. Dong, and C. Sun, “Credit assignment in heterogeneous multi-agent reinforcement learning for fully cooperative tasks,” Applied Intelligence, vol. 53, no. 23, pp. 29205–29222, 2023.
|
| [38] |
H. Ryu, H. Shin, and J. Park, “Multi-agent actor-critic with hierarchical graph attention network,” in Proc. 34th AAAI Conf. Artificial Intelligence, 2020, pp. 7236–7243.
|
| [39] |
T. Haarnoja, K. Hartikainen, P. Abbeel, and S. Levine, “Latent space policies for hierarchical reinforcement learning,” in Proc. 35th Int. Conf. Machine Learning, 2018, vol. 80, pp. 1846–1855.
|
| [40] |
M. Watter, J. T. Springenberg, J. Boedecker, and M. A. Riedmiller, “Embed to control: A locally linear latent dynamics model for control from raw images,” in Proc. Advance In Neural Information Processing Systems, 2015, pp. 2746–2754.
|
| [41] |
O. Rybkin, C. Zhu, A. Nagabandi, K. Daniilidis, I. Mordatch, and S. Levine, “Model-based reinforcement learning via latent-space collocation,” in Proc. 38th Int. Conf. Machine Learning, 2021, vol. 139, pp. 9190–9201.
|
| [42] |
D. Hafner, T. P. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson, “Learning latent dynamics for planning from pixels,” in Proc. 36th Int. Conf. Machine Learning, 2019, vol. 97, pp. 2555–2565.
|
| [43] |
M. Zhang, S. Vikram, L. Smith, P. Abbeel, M. Johnson, and S. Levine, “Solar: Deep structured representations for model-based reinforcement learning,” in Proc. Int. Conf. Machine Learning, 2019, pp. 7444–7453.
|
| [44] |
M. Gasse, D. Grasset, G. Gaudron, and P.-Y. Oudeyer, “Causal reinforcement learning using observational and interventional data,” arXiv preprint arXiv:2106.14421, 2021.
|
| [45] |
S. Lee and E. Bareinboim, “Structural causal bandits: Where to intervene?” in Proc. Advance in Neural Information Processing Systems, 2018, vol. 31, pp. 2573–2583.
|
| [46] |
L. Wang, Z. Yang, and Z. Wang, “Provably efficient causal reinforcement learning with confounded observational data,” in Proc. Advances in Neural Information Processing Systems, 2021, pp. 21164–21175.
|
| [47] |
M. Seitzer, B. Schölkopf, and G. Martius, “Causal influence detection for improving efficiency in reinforcement learning,” in Proc. Advances in Neural Information Processing Systems, 2021, pp. 22905–22918.
|
| [48] |
P. Madumal, T. Miller, L. Sonenberg, and F. Vetere, “Explainable reinforcement learning through a causal lens,” in Proc. 34th AAAI Conf. Artificial Intelligence, 2020, pp. 2493–2500.
|
| [49] |
N. Jaques, A. Lazaridou, E. Hughes, Ç. Gülçehre, P. A. Ortega, D. Strouse, J. Z. Leibo, and N. de Freitas, “Intrinsic social motivation via causal influence in multi-agent RL,” [Online], Available: https://arxiv.org/abs/1810.08647, 2018.
|
| [50] |
S. J. Grimbly, J. P. Shock, and A. Pretorius, “Causal multi-agent reinforcement learning: Review and open problems,” [Online], Available: https://corr.org/abs/2111.06721, 2021.
|
| [51] |
N. Gruver, J. Song, M. J. Kochenderfer, and S. Ermon, “Multi-agent adversarial inverse reinforcement learning with latent variables,” in Proc. 19th Int. Conf. Autonomous Agents and Multiagent Systems, 2020, pp. 1855–1857.
|
| [52] |
R. L. Burden, J. D. Faires, and A. M. Burden, Numerical Analysis. Boston, USA: Cengage Learning, 2015.
|
Figures(9) / Tables(5)






 DownLoad:
DownLoad: