A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 10
Issue 7
Volume 10
Issue 7
IEEE/CAA Journal of Automatica Sinica
| Citation: | C. C. Wang, Y. L. Wang, Q.-L. Han, and Y. K. Wu, “MUTS-based cooperative target stalking for a multi-USV system,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 7, pp. 1582–1592, Jul. 2023. doi: 10.1109/JAS.2022.106007

|
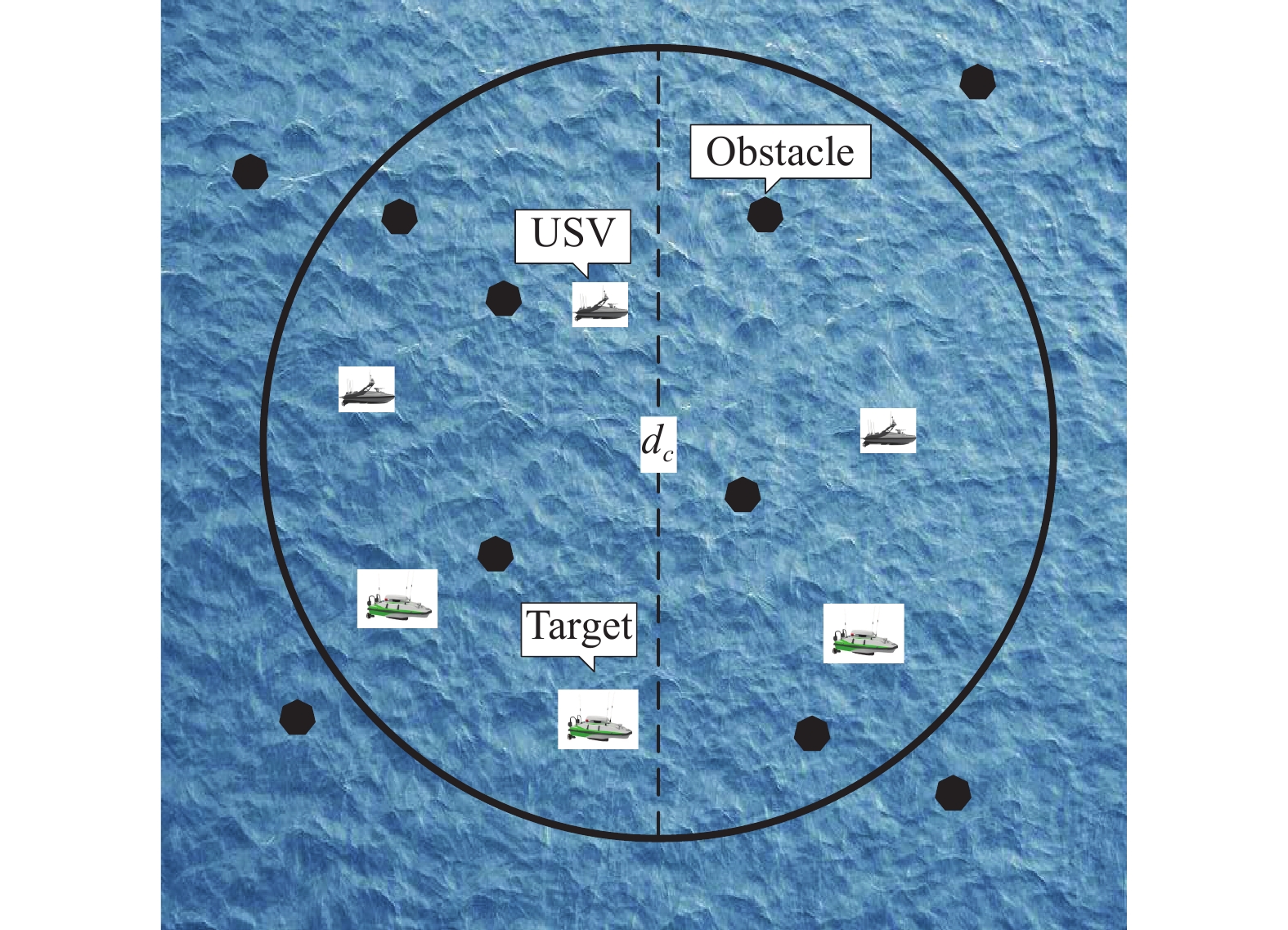
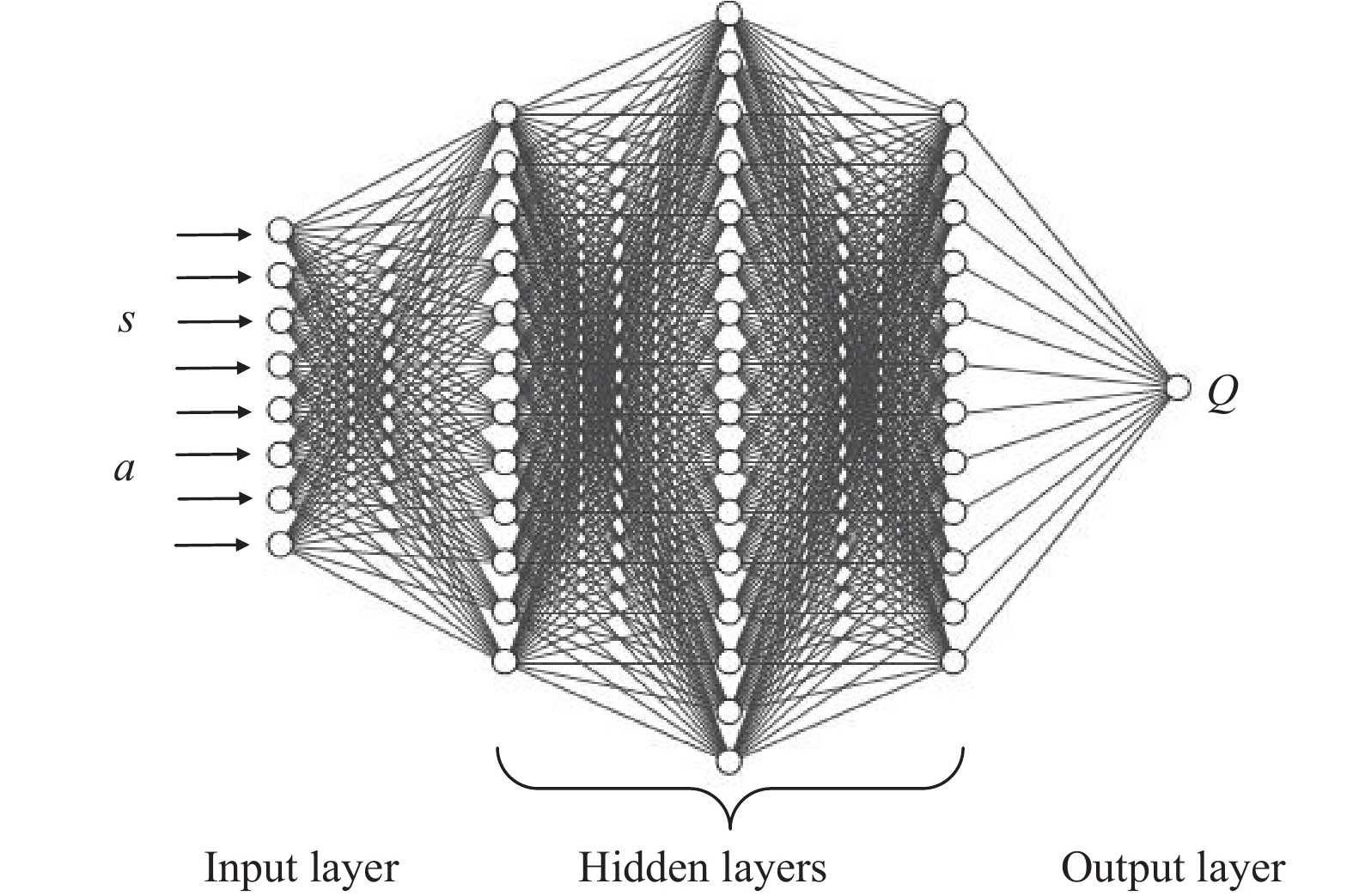
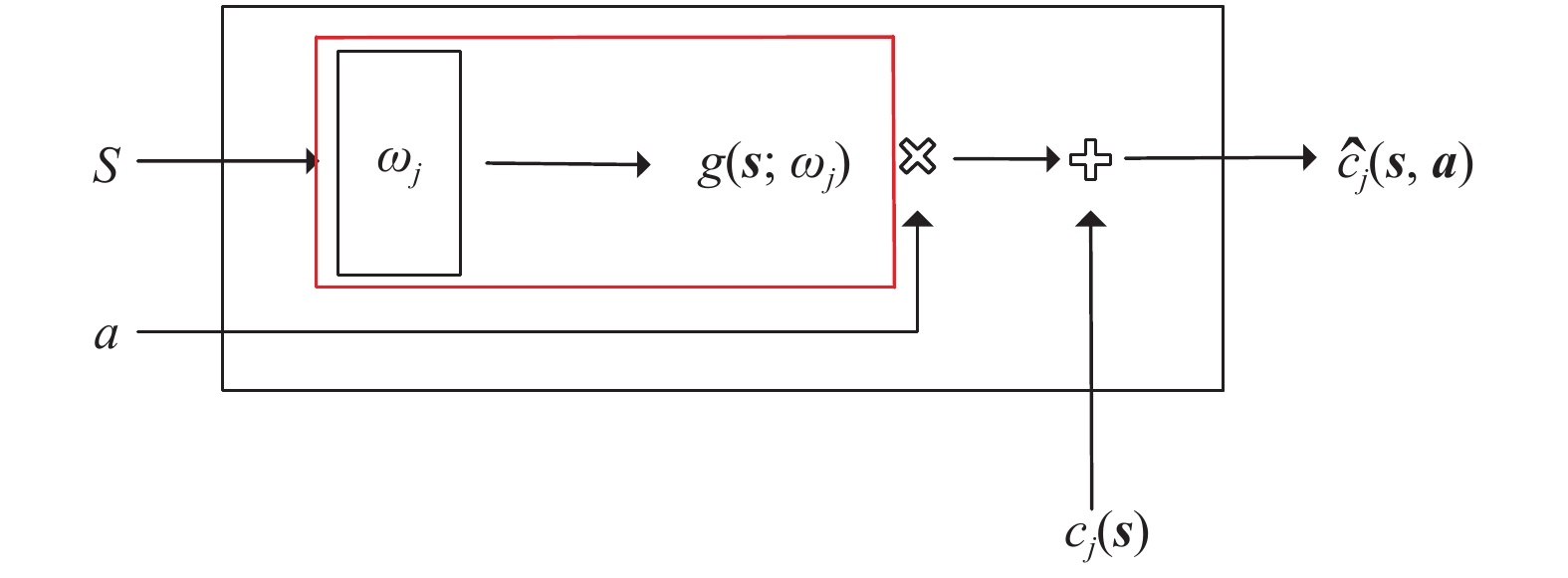
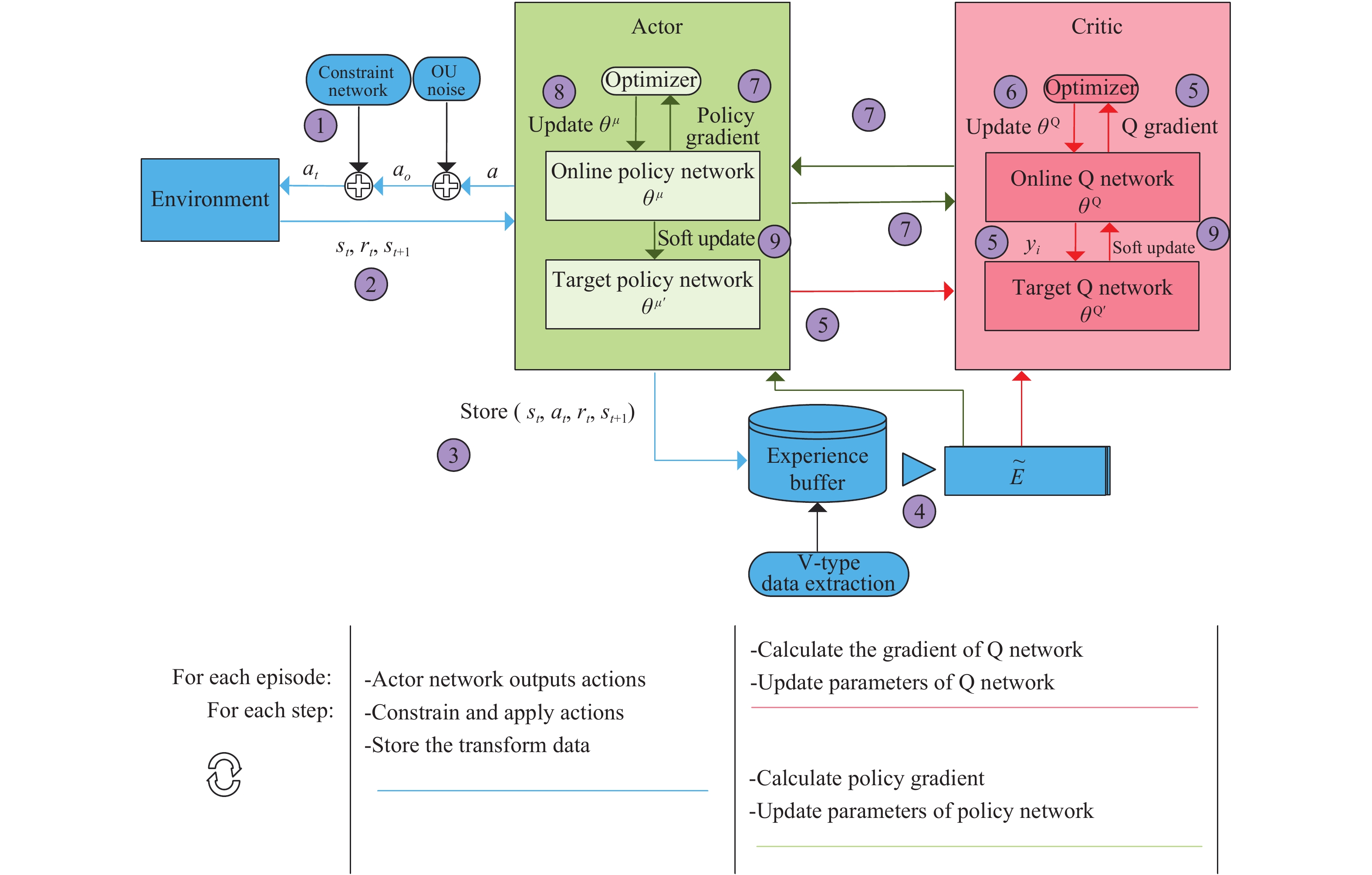
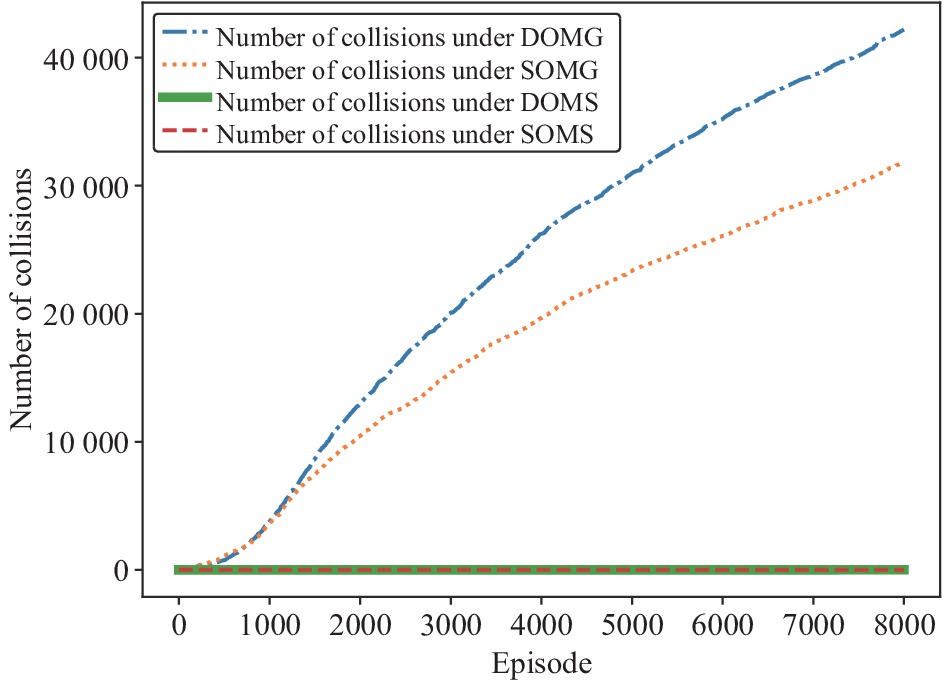
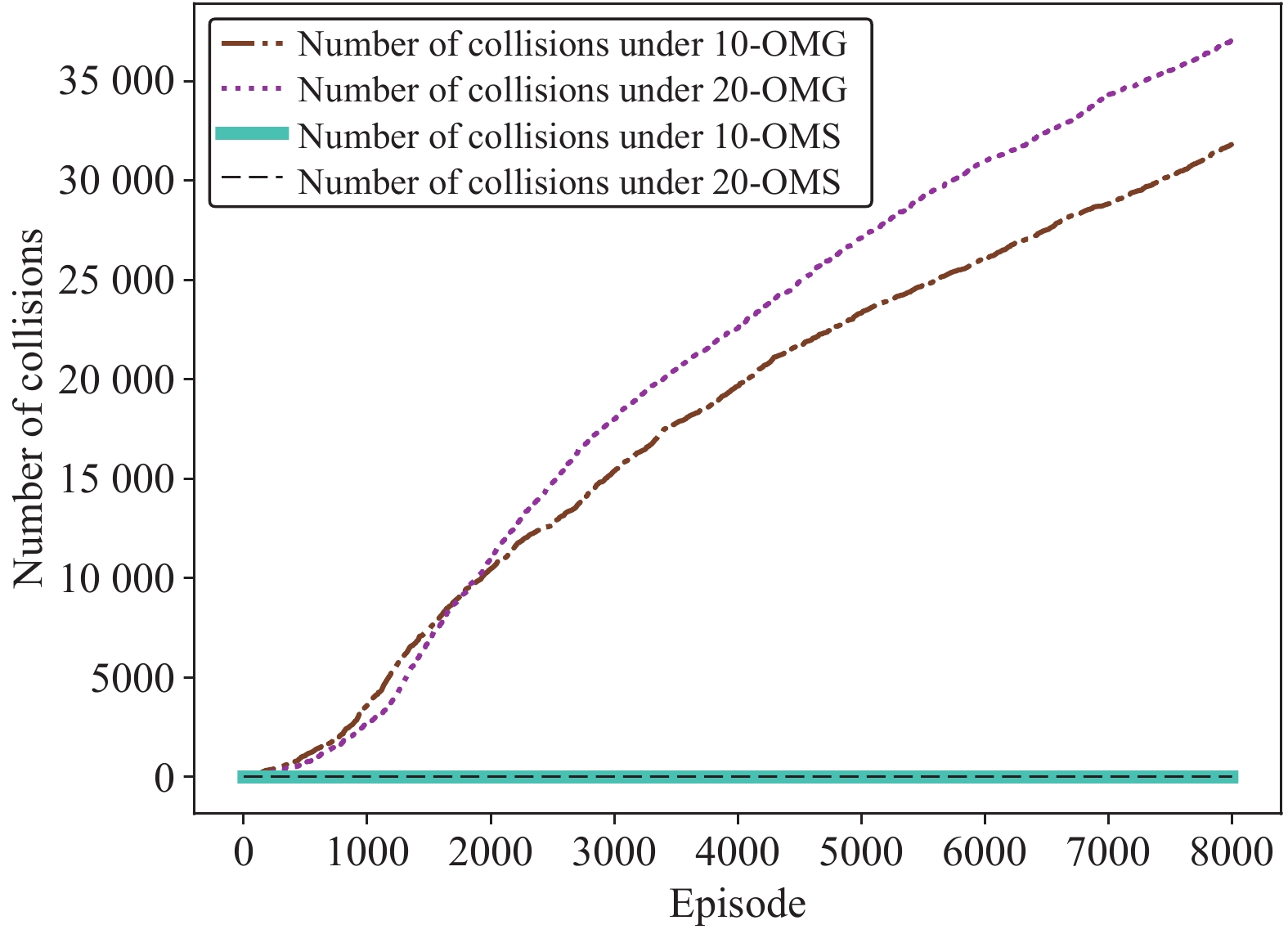
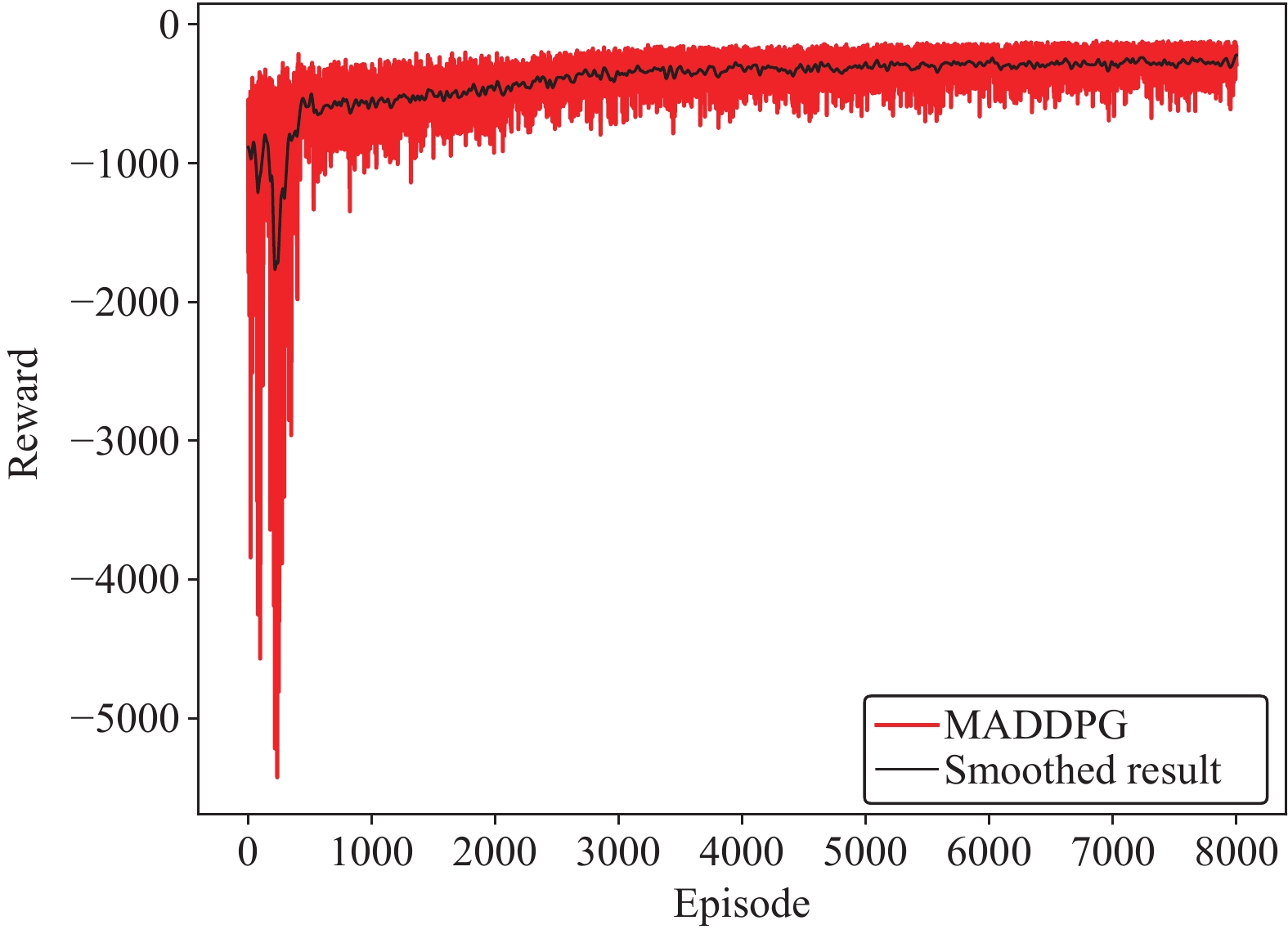
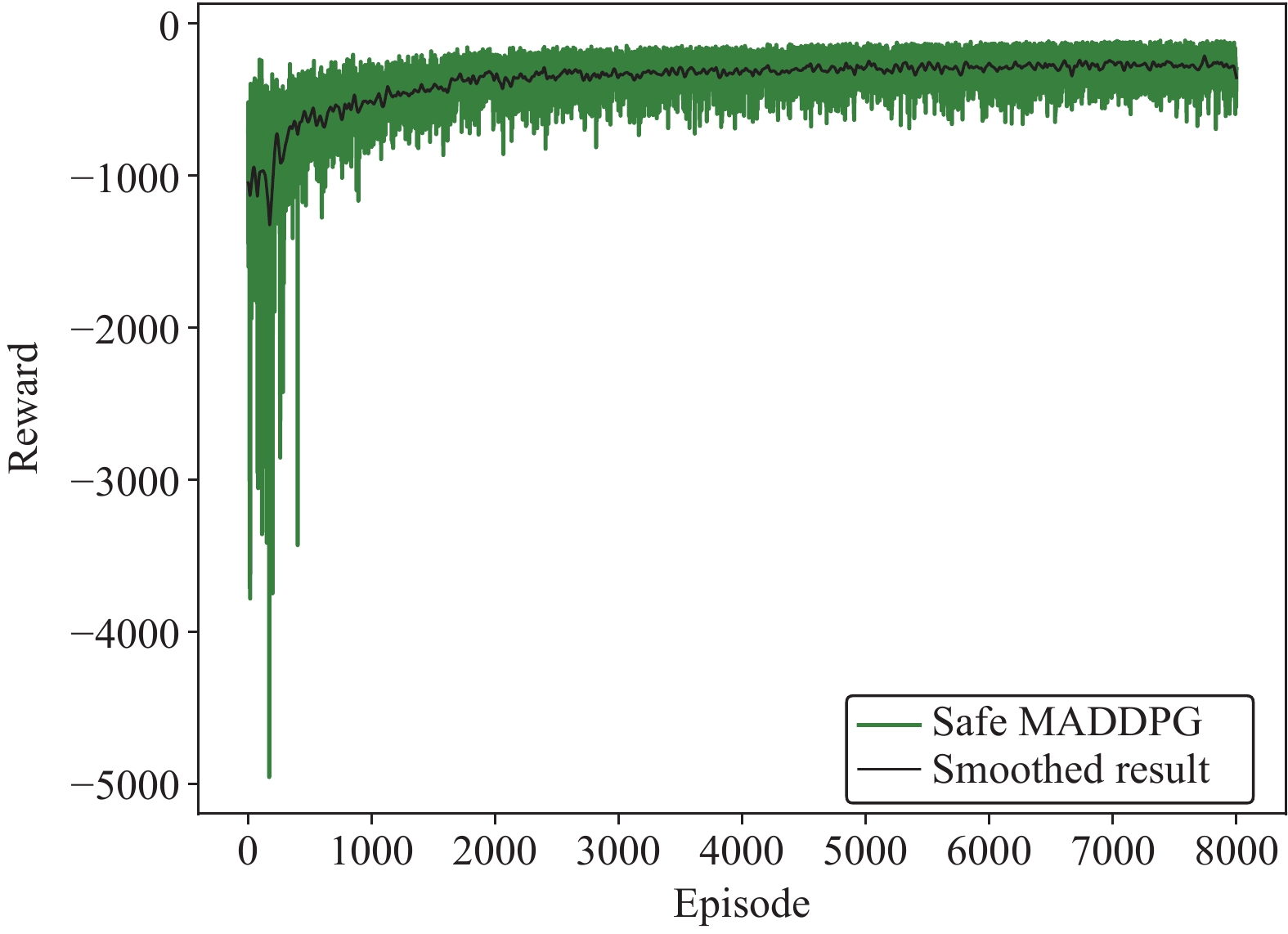
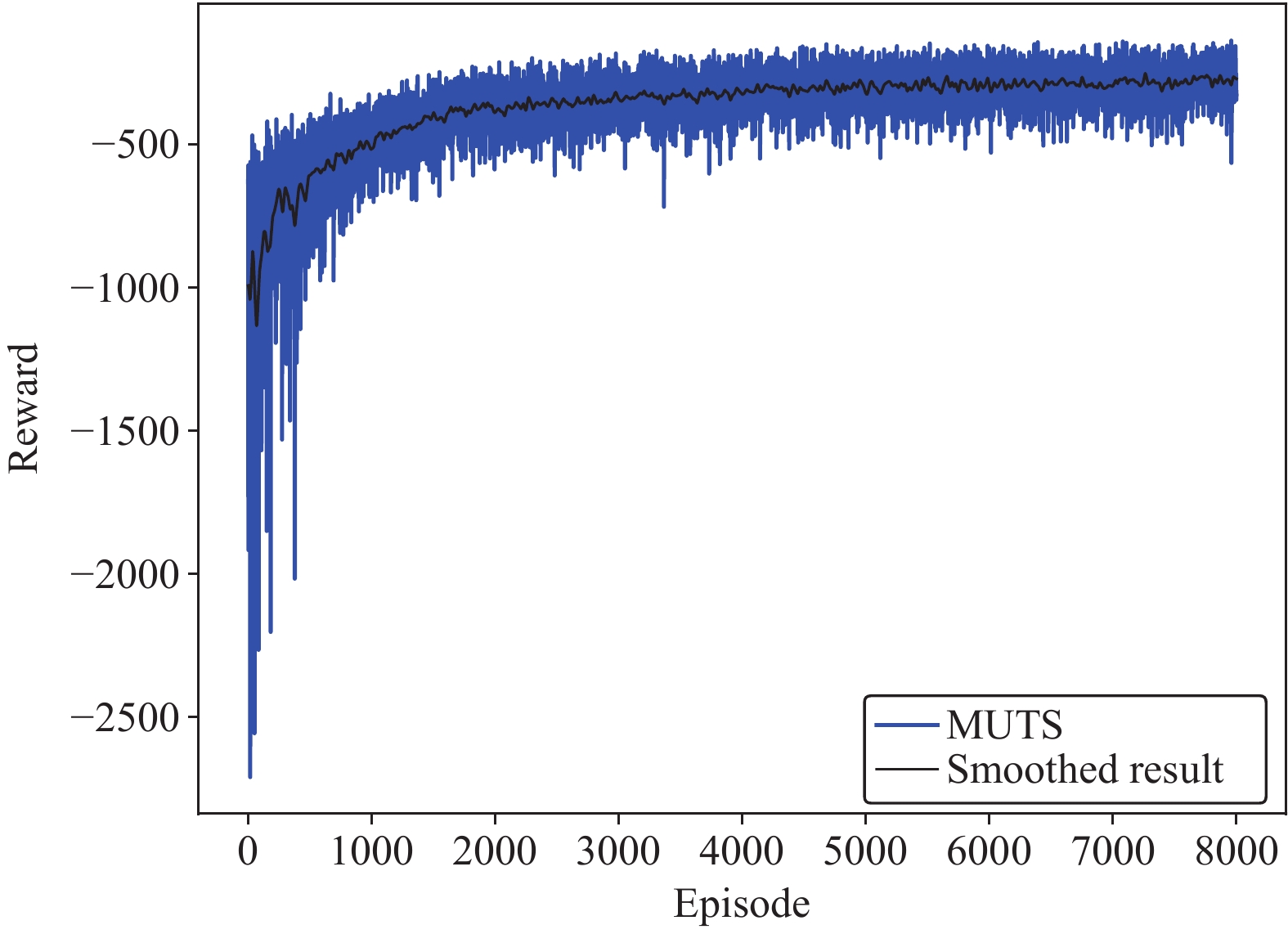
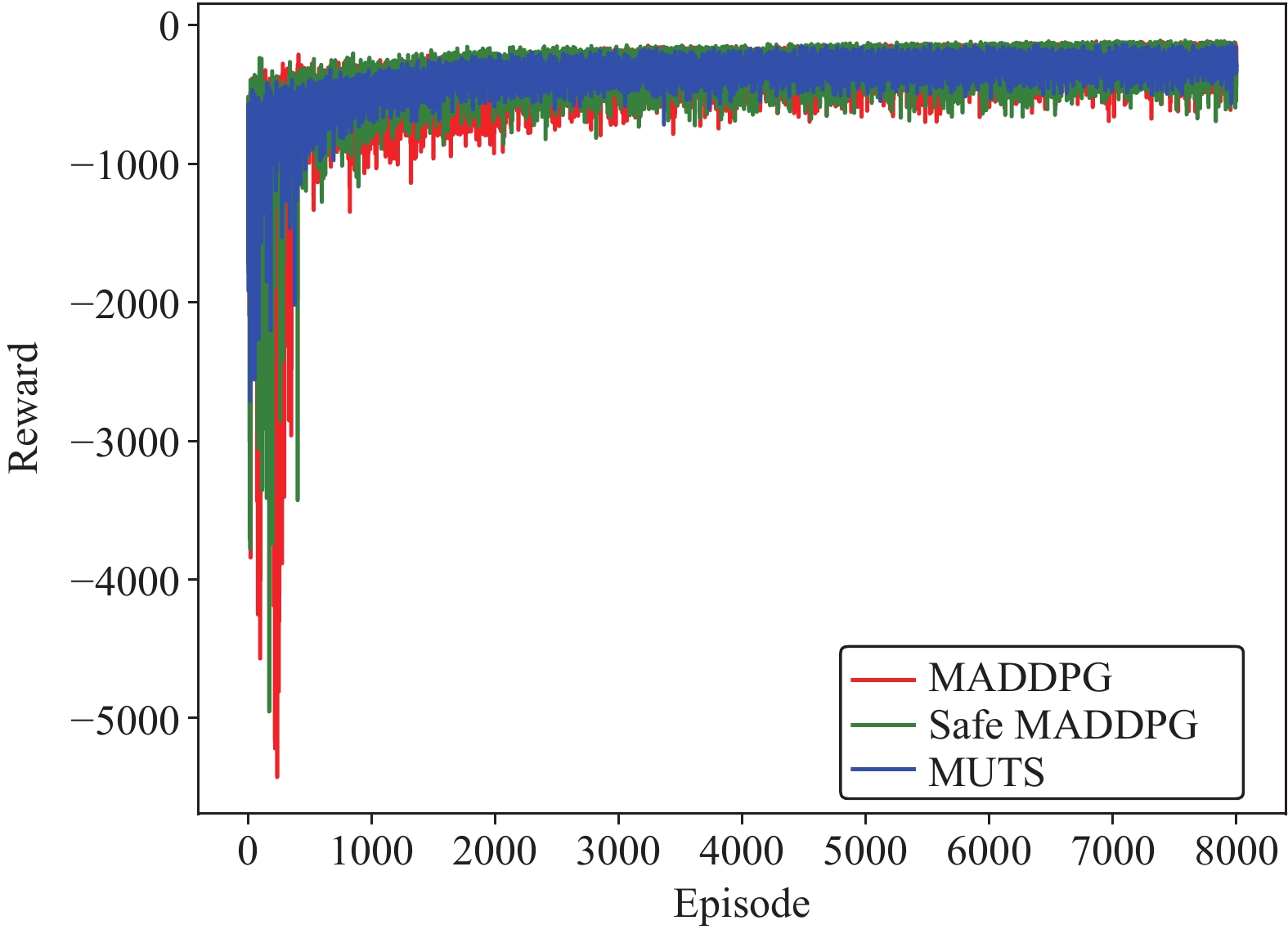
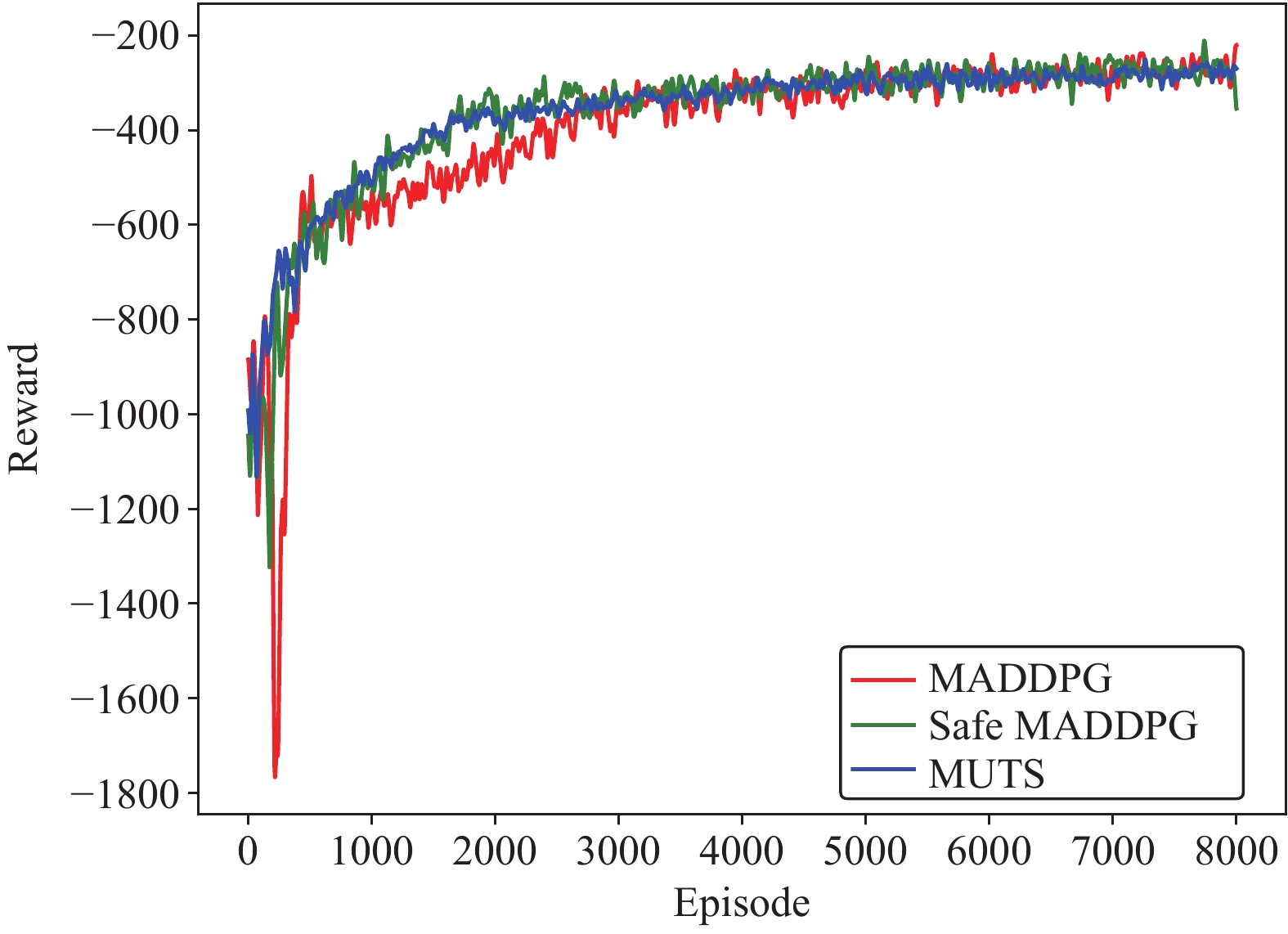
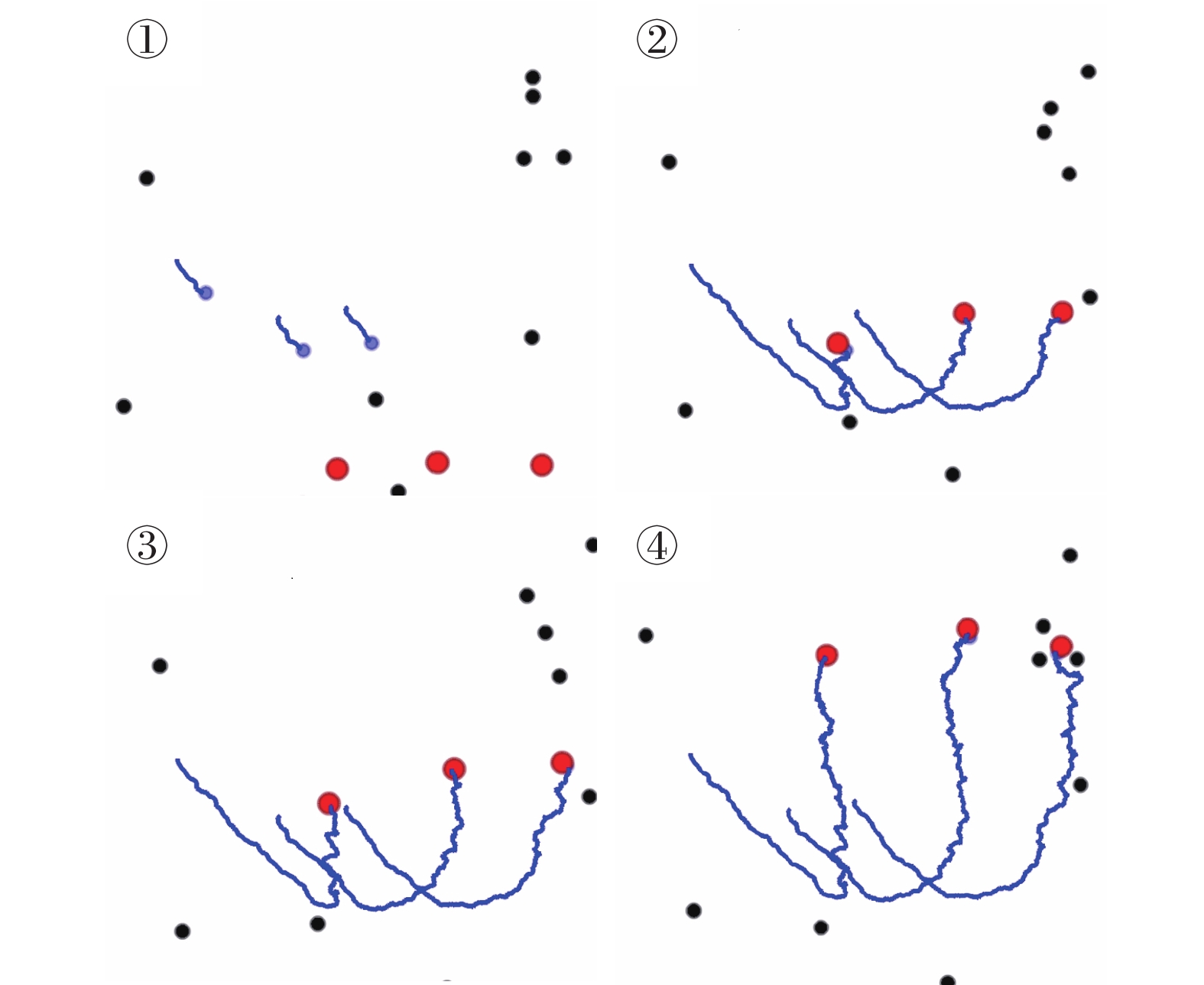
This paper is concerned with the cooperative target stalking for a multi-unmanned surface vehicle (multi-USV) system. Based on the multi-agent deep deterministic policy gradient (MADDPG) algorithm, a multi-USV target stalking (MUTS) algorithm is proposed. Firstly, a V-type probabilistic data extraction method is proposed for the first time to overcome shortcomings of the MADDPG algorithm. The advantages of the proposed method are twofold: 1) it can reduce the amount of data and shorten training time; 2) it can filter out more important data in the experience buffer for training. Secondly, in order to avoid the collisions of USVs during the stalking process, an action constraint method called Safe DDPG is introduced. Finally, the MUTS algorithm and some existing algorithms are compared in cooperative target stalking scenarios. In order to demonstrate the effectiveness of the proposed MUTS algorithm in stalking tasks, mission operating scenarios and reward functions are well designed in this paper. The proposed MUTS algorithm can help the multi-USV system avoid internal collisions during the mission execution. Moreover, compared with some existing algorithms, the newly proposed one can provide a higher convergence speed and a narrower convergence domain.

| [1] |
Z. Y. Zhou, J. C. Liu, and J. Z. Yu, “A survey of underwater multi-robot systems,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 1, pp. 1–18, Jan. 2022. doi: 10.1109/JAS.2021.1004269
|
| [2] |
A. Gonzalez-Garcia, D. Barragan-Alcantar, I. Collado-Gonzalez, and L. Garrido, “Adaptive dynamic programming and deep reinforcement learning for the control of an unmanned surface vehicle: Experimental results,” Control Eng. Pract., vol. 111, p. 104807, Jun. 2021. doi: 10.1016/j.conengprac.2021.104807
|
| [3] |
Y.-L. Wang and Q.-L. Han, “Network-based modelling and dynamic output feedback control for unmanned marine vehicles in network environments,” Automatica, vol. 91, pp. 43–53, May 2018. doi: 10.1016/j.automatica.2018.01.026
|
| [4] |
J. Woo, C. Yu, and N. Kim, “Deep reinforcement learning-based controller for path following of an unmanned surface vehicle,” Ocean Eng., vol. 183, pp. 155–166, Jul. 2019. doi: 10.1016/j.oceaneng.2019.04.099
|
| [5] |
Y. D. Cui, S. Osaki, and T. Matsubara, “Reinforcement learning boat autopilot: A sample-efficient and model predictive control based approach,” in Proc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems, Macau, China, 2019, pp. 2868–2875.
|
| [6] |
X. C. Wang, X. C. Liu, T. L. Shen, and W. D. Zhang, “A greedy navigation and subtle obstacle avoidance algorithm for USV using reinforcement learning,” in Proc. Chinese Automation Congr., Hangzhou, China, 2019, pp. 770–775.
|
| [7] |
Y. J. Zhao, Y. Ma, and S. L. Hu, “USV formation and path-following control via deep reinforcement learning with random braking,” IEEE Trans. Neural Netw. Learn. Syst., vol. 32, no. 12, pp. 5468–5478, Dec. 2021. doi: 10.1109/TNNLS.2021.3068762
|
| [8] |
L. Ma, Y.-L. Wang, and Q.-L. Han, “Cooperative target tracking of multiple autonomous surface vehicles under switching interaction topologies,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 3, pp. 673–684, Mar. 2023.
|
| [9] |
X. C. Huang, “Improved ‘infotaxis’ algorithm-based cooperative multi-USV pollution source search approach in lake water environment,” Symmetry, vol. 12, no. 4, p. 549, Apr. 2020. doi: 10.3390/sym12040549
|
| [10] |
H. Q. Sang, Y. S. You, X. J. Sun, Y. Zhou, and F. Liu, “The hybrid path planning algorithm based on improved A* and artificial potential field for unmanned surface vehicle formations,” Ocean Eng., vol. 223, p. 108709, Mar. 2021. doi: 10.1016/j.oceaneng.2021.108709
|
| [11] |
L. Y. Li, D. F. Wu, Y. Q. Huang, and Z.-M. Yuan, “A path planning strategy unified with a COLREGS collision avoidance function based on deep reinforcement learning and artificial potential field,” Appl. Ocean Res., vol. 113, p. 102759, Aug. 2021. doi: 10.1016/j.apor.2021.102759
|
| [12] |
V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis, “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, Feb. 2015. doi: 10.1038/nature14236
|
| [13] |
Y. X. Yang, Z. H. Ni, M. Y. Gao, J. Zhang, and D. C. Tao, “Collaborative pushing and grasping of tightly stacked objects via deep reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 1, pp. 135–145, Jan. 2022. doi: 10.1109/JAS.2021.1004255
|
| [14] |
S. J. Cao, D. L. Li, Y. T. Chen, and F. M. Zeng, “A realtime Q-learning method for unmanned surface vehicle target tracking,” in Proc. IEEE CSAA Guidance, Navigation and Control Conf., Xiamen, China, 2018, pp. 1–5.
|
| [15] |
B. Yoo and J. Kim, “Path optimization for marine vehicles in ocean currents using reinforcement learning,” J. Mar. Sci. Technol., vol. 21, no. 2, pp. 334–343, Jun. 2016. doi: 10.1007/s00773-015-0355-9
|
| [16] |
Y. J. Zhao, X. Qi, Y. Ma, Z. X. Li, R. Malekian, and M. A. Sotelo, “Path following optimization for an underactuated USV using smoothly-convergent deep reinforcement learning,” IEEE Trans. Intell. Transp. Syst., vol. 22, no. 10, pp. 6208–6220, Oct. 2021. doi: 10.1109/TITS.2020.2989352
|
| [17] |
A. B. Martinsen, A. M. Lekkas, S. Gros, J. A. Glomsrud, and T. A. Pedersen, “Reinforcement learning-based tracking control of USVs in varying operational conditions,” Front. Robot. AI, vol. 7, p. 32, Mar. 2020. doi: 10.3389/frobt.2020.00032
|
| [18] |
D. Luviano and W. Yu, “Continuous-time path planning for multi-agents with fuzzy reinforcement learning,” J. Intell. Fuzzy Syst., vol. 33, no. 1, pp. 491–501, Jun. 2017. doi: 10.3233/JIFS-161822
|
| [19] |
R. F. Wu, Z. K. Yao, J. Si, and H. H. Huang, “Robotic knee tracking control to mimic the intact human knee profile based on actor-critic reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 1, pp. 19–30, Jan. 2022. doi: 10.1109/JAS.2021.1004272
|
| [20] |
A. B. Martinsen and A. M. Lekkas, “Straight-path following for underactuated marine vessels using deep reinforcement learning,” IFAC-PapersOnLine, vol. 51, no. 29, pp. 329–334, Sept. 2018. doi: 10.1016/j.ifacol.2018.09.502
|
| [21] |
X. Wu, H. L. Chen, C. G. Chen, M. Y. Zhong, S. R. Xie, Y. K. Guo, and H. Fujita, “The autonomous navigation and obstacle avoidance for USVs with ANOA deep reinforcement learning method,” Knowl.-Based Syst., vol. 196, p. 105201, May 2020. doi: 10.1016/j.knosys.2019.105201
|
| [22] |
S. N. Gao, Z. H. Peng, H. L. Wang, L. Liu, and D. Wang, “Safety-critical model-free control for multi-target tracking of USVs with collision avoidance,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 7, pp. 1323–1326, Jul. 2022. doi: 10.1109/JAS.2022.105707
|
| [23] |
Y. Cheng and W. D. Zhang, “Concise deep reinforcement learning obstacle avoidance for underactuated unmanned marine vessels,” Neurocomputing, vol. 272, pp. 63–73, Jan. 2018. doi: 10.1016/j.neucom.2017.06.066
|
| [24] |
J. Woo and N. Kim, “Collision avoidance for an unmanned surface vehicle using deep reinforcement learning,” Ocean Eng., vol. 199, p. 107001, Mar. 2020. doi: 10.1016/j.oceaneng.2020.107001
|
| [25] |
H. Q. Shen, H. Hashimoto, A. Matsuda, Y. Taniguchi, D. Terada, and C. Guo, “Automatic collision avoidance of multiple ships based on deep Q-learning,” Appl. Ocean Res., vol. 86, pp. 268–288, May 2019. doi: 10.1016/j.apor.2019.02.020
|
| [26] |
Y. Ma, Y. J. Zhao, Y. L. Wang, L. X. Gan, and Y. Z. Zheng, “Collision-avoidance under COLREGS for unmanned surface vehicles via deep reinforcement learning,” Marit. Policy Manag., vol. 47, no. 5, pp. 665–686, May 2020. doi: 10.1080/03088839.2020.1756494
|
| [27] |
J. R. Wang, Y. T. Hong, J. L. Wang, J. P. Xu, Y. Tang, Q.-L. Han, and J. Kurths, “Cooperative and competitive multi-agent systems: From optimization to games,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 5, pp. 763–783, May 2022. doi: 10.1109/JAS.2022.105506
|
| [28] |
L. W. Huang, M. S. Fu, H. Qu, S. Y. Wang, and S. Q. Hu, “A deep reinforcement learning-based method applied for solving multi-agent defense and attack problems,” Expert Syst. Appl., vol. 176, p. 114896, Aug. 2021. doi: 10.1016/j.eswa.2021.114896
|
| [29] |
J. Xu, F. Huang, D. Wu, Y. F. Cui, Z. P. Yan, and K. Zhang, “Deep reinforcement learning based multi-AUVs cooperative decision-making for attack-defense confrontation missions,” Ocean Eng., vol. 239, p. 109794, Nov. 2021. doi: 10.1016/j.oceaneng.2021.109794
|
| [30] |
L. Chen, B. Hu, Z.-H. Guan, L. Zhao, and X. Shen, “Multiagent meta-reinforcement learning for adaptive multipath routing optimization,” IEEE Trans. Neural Netw. Learn. Syst., vol. 33, no. 10, pp. 5374–5386, Oct. 2022.
|
| [31] |
S. Jo, C. Jong, C. Pak, and H. Ri, “Multi-agent deep reinforcement learning-based energy efficient power allocation in downlink MIMO-NOMA systems,” IET Commun., vol. 15, no. 12, pp. 1642–1654, Jul. 2021. doi: 10.1049/cmu2.12177
|
| [32] |
T. I. Fossen, Handbook of Marine Craft Hydrodynamics and Motion Control. Chichester, UK: John Wiley & Sons, 2011.
|
| [33] |
A. Singh and S. S. Jha, “Learning safe cooperative policies in autonomous multi-UAV navigation,” in Proc. 18th IEEE India Council Int. Conf., Guwahati, India, 2021, pp. 1–6.
|
Figures(13) / Tables(3)






 DownLoad:
DownLoad: