A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 10
Issue 11
Volume 10
Issue 11
IEEE/CAA Journal of Automatica Sinica
| Citation: | Z. Chen and N. Li, “An optimal control-based distributed reinforcement learning framework for a class of non-convex objective functionals of the multi-agent network,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 11, pp. 2081–2093, Nov. 2023. doi: 10.1109/JAS.2022.105992

|
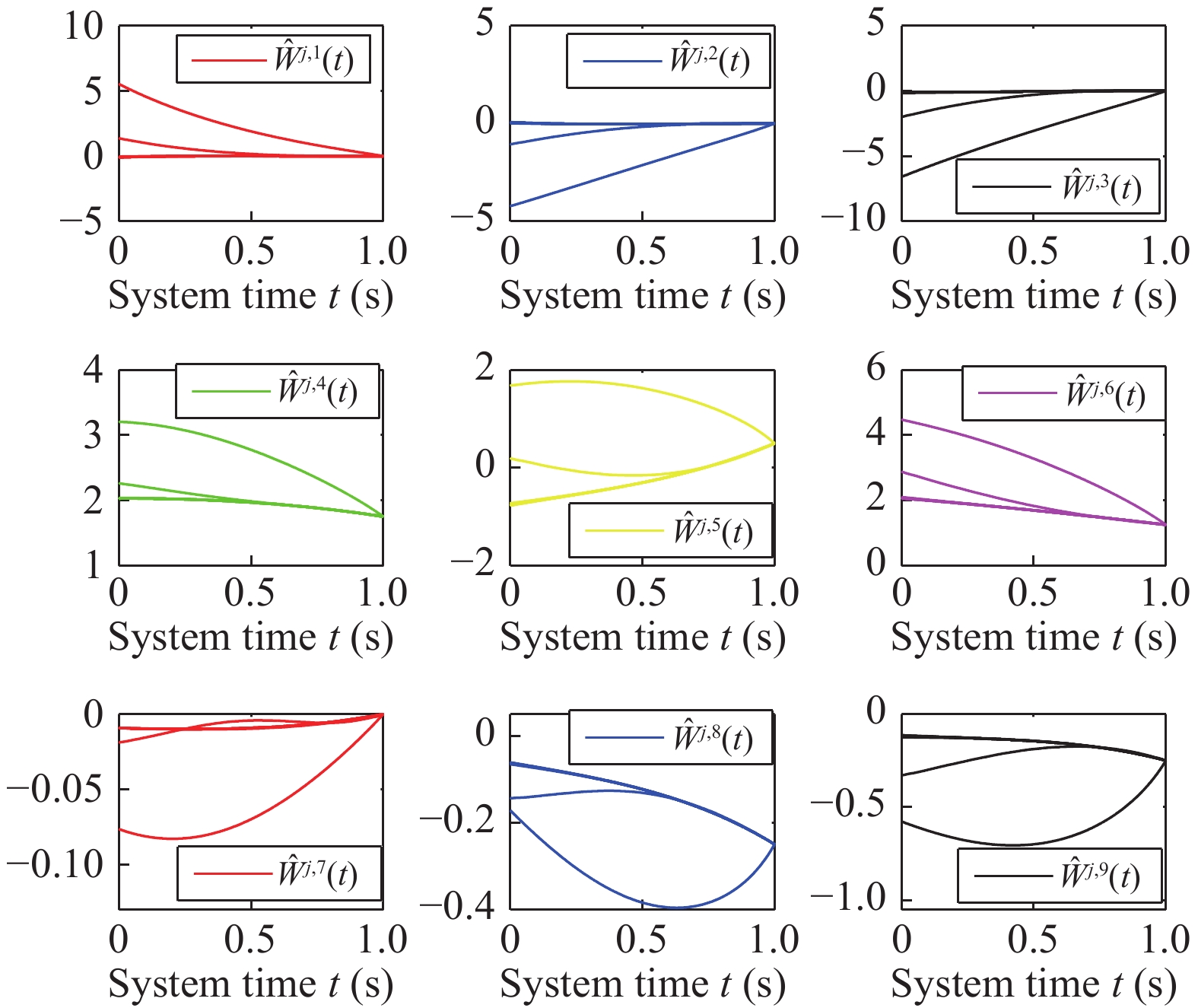
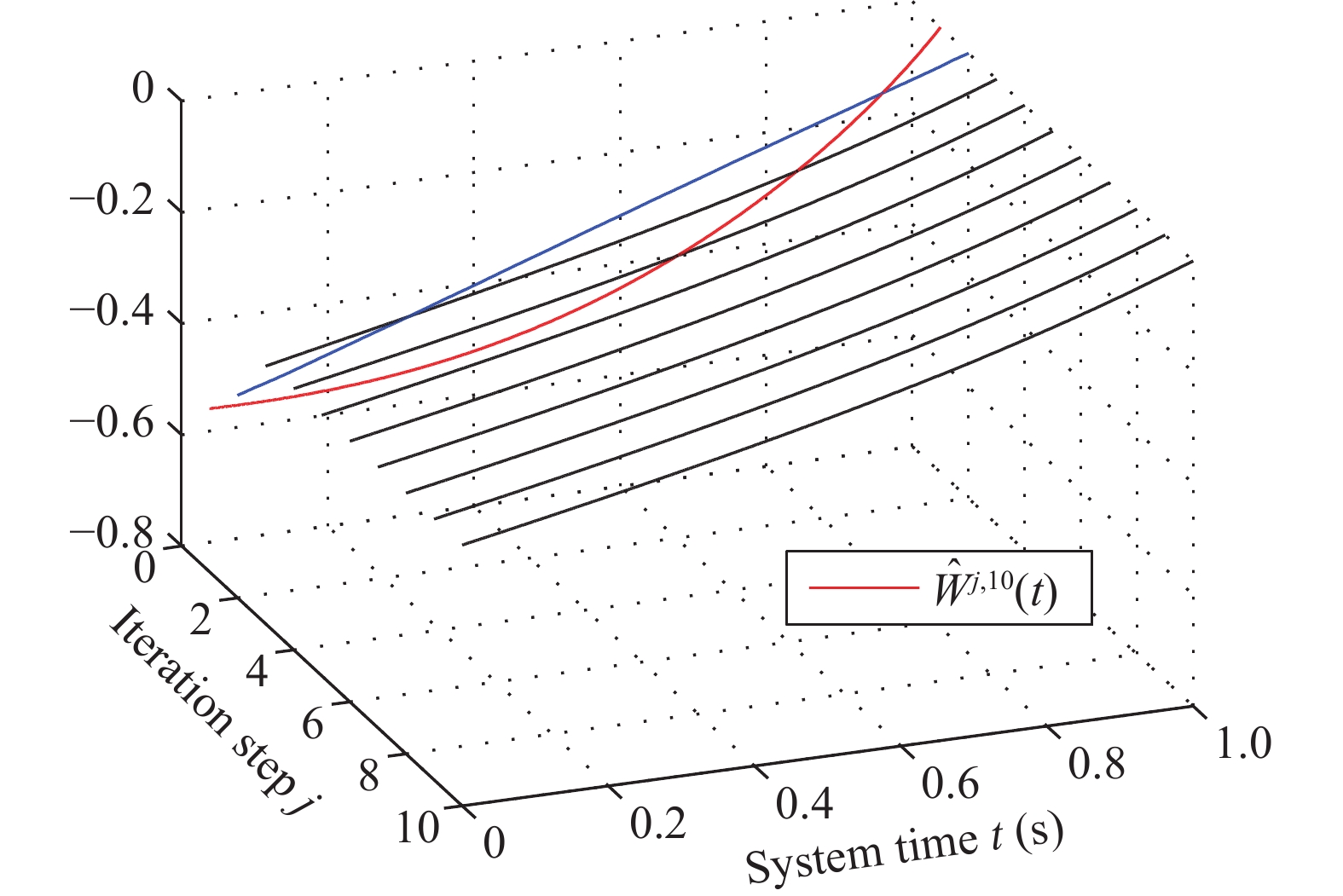
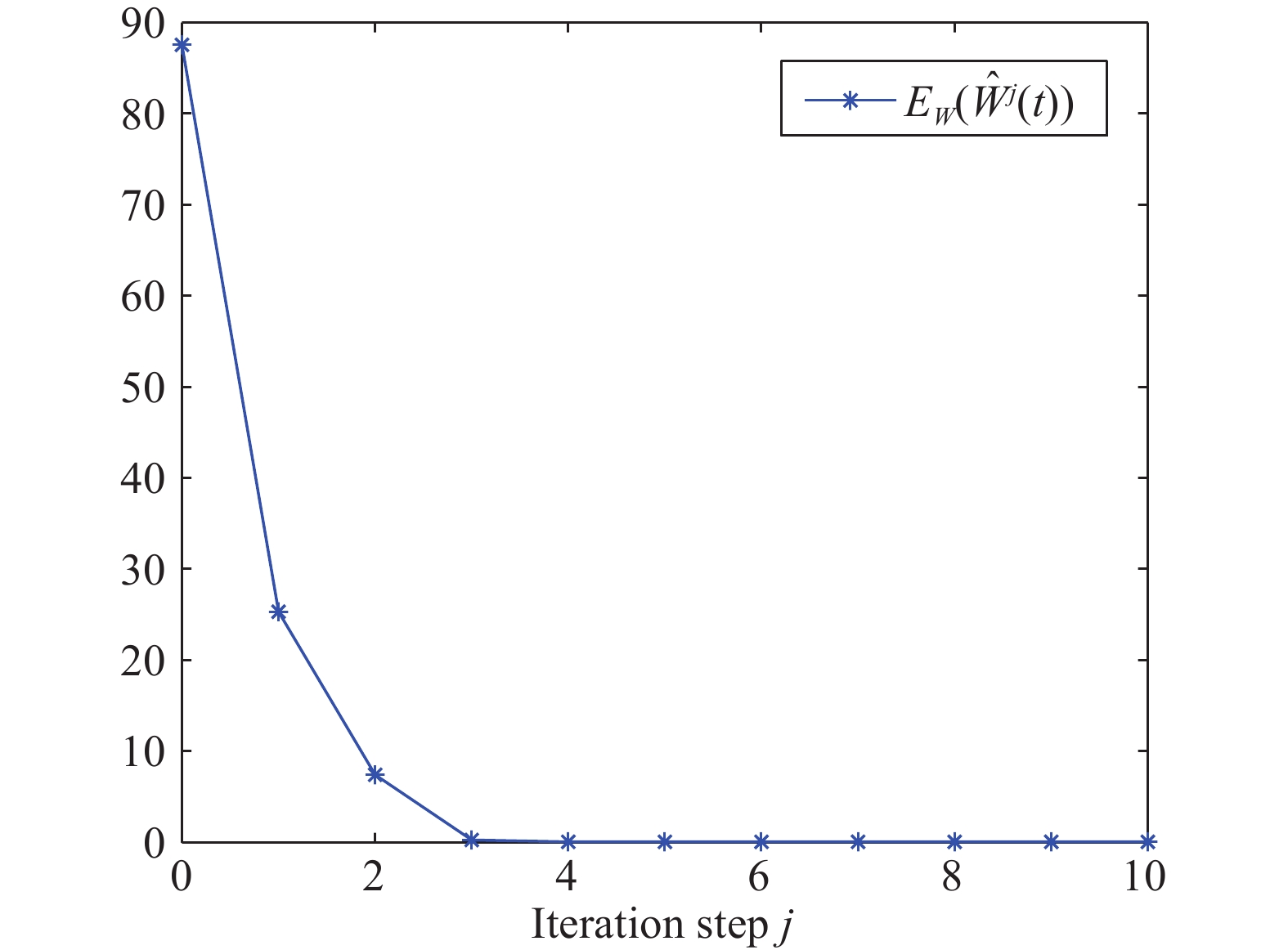
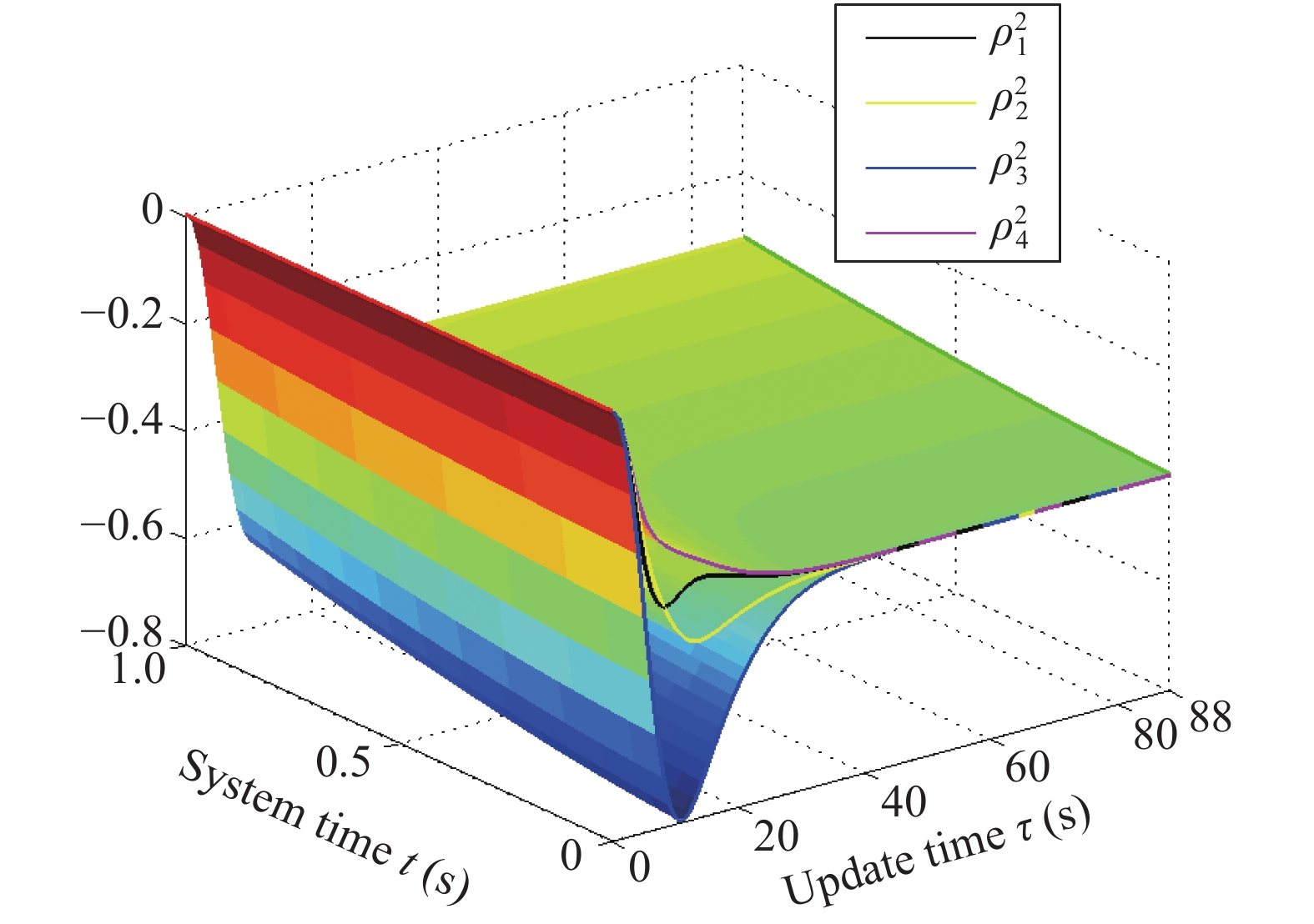
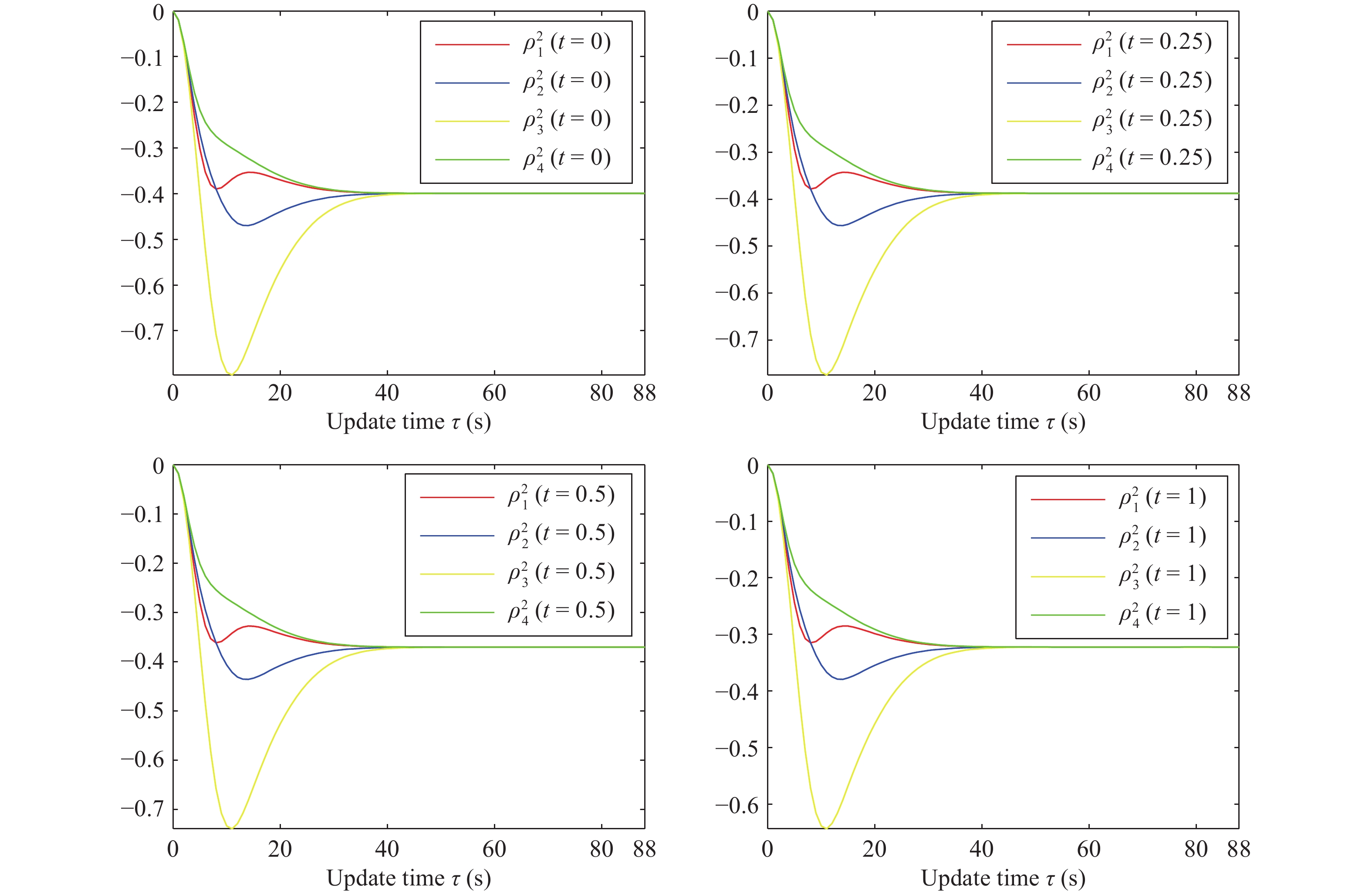
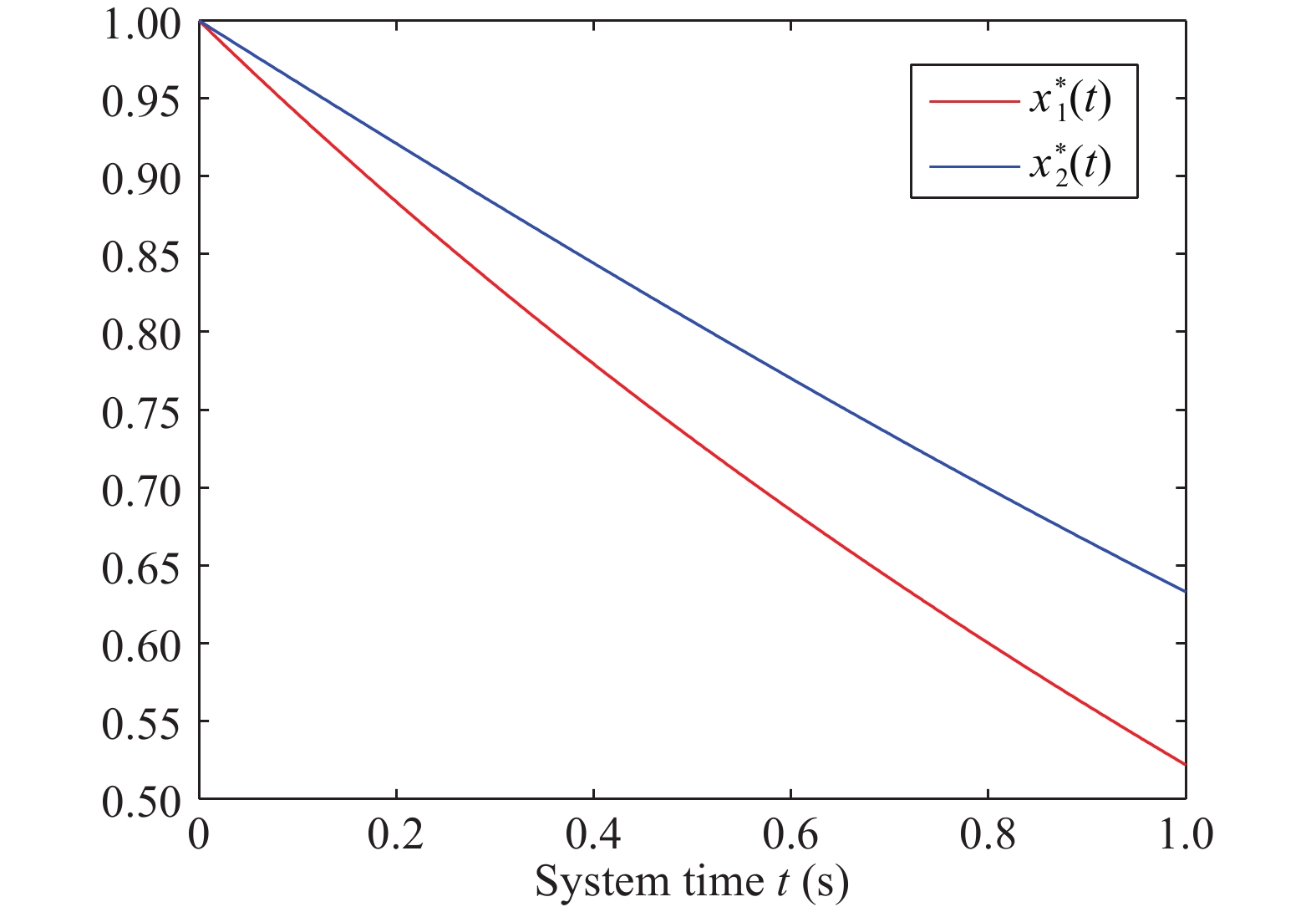
This paper studies a novel distributed optimization problem that aims to minimize the sum of the non-convex objective functionals of the multi-agent network under privacy protection, which means that the local objective of each agent is unknown to others. The above problem involves complexity simultaneously in the time and space aspects. Yet existing works about distributed optimization mainly consider privacy protection in the space aspect where the decision variable is a vector with finite dimensions. In contrast, when the time aspect is considered in this paper, the decision variable is a continuous function concerning time. Hence, the minimization of the overall functional belongs to the calculus of variations. Traditional works usually aim to seek the optimal decision function. Due to privacy protection and non-convexity, the Euler-Lagrange equation of the proposed problem is a complicated partial differential equation. Hence, we seek the optimal decision derivative function rather than the decision function. This manner can be regarded as seeking the control input for an optimal control problem, for which we propose a centralized reinforcement learning (RL) framework. In the space aspect, we further present a distributed reinforcement learning framework to deal with the impact of privacy protection. Finally, rigorous theoretical analysis and simulation validate the effectiveness of our framework.

| [1] |
A. Nedic and A. Ozdaglar, “Distributed subgradient methods for multiagent optimization,” IEEE Trans. Automatic Control, vol. 54, no. 1, pp. 48–61, 2009. doi: 10.1109/TAC.2008.2009515
|
| [2] |
A. Nedic, A. Ozdaglar, and A. Parrilo, “Constrained consensus and optimization in multi-agent networks,” IEEE Trans. Automatic Control, vol. 55, no. 4, pp. 922–938, 2010. doi: 10.1109/TAC.2010.2041686
|
| [3] |
S. S. Kia, J. Cortés, and S. Martínez, “Distributed convex optimization via continuous-time coordination algorithms with discrete-time communication,” Automatica, vol. 55, pp. 254–264, 2015. doi: 10.1016/j.automatica.2015.03.001
|
| [4] |
W. Shi, Q. Ling, G. Wu, and W. Yin, “Extra: An exact first-order algorithm for decentralized consensus optimization,” SIAM J. Optimization, vol. 25, no. 2, pp. 944–966, 2015. doi: 10.1137/14096668X
|
| [5] |
T. Yang, D. Wu, H. Fang, W. Ren, H. Wang, Y. Hong, and K. H. Johansson, “Distributed energy resource coordination over time-varying directed communication networks,” IEEE Trans. Control of Network Systems, vol. 6, no. 3, pp. 1124–1134, 2019. doi: 10.1109/TCNS.2019.2921284
|
| [6] |
D ai, W. Yu, and D. Chen, “Distributed Q-learning algorithm for dynamic resource allocation with unknown objective functions and application to microgrid,” IEEE Trans. Cybernetics, vol. 52, no. 11, pp. 12340–12350, 2022.
|
| [7] |
D. Liu, S. Baldi, W. Yu, and G. Chen, “On distributed implementation of switch-based adaptive dynamic programming,” IEEE Trans. Cybernetics, vol. 52, no. 7, pp. 7218–7224, 2022.
|
| [8] |
R. Mohebifard and A. Hajbabaie, “Distributed optimization and coordination algorithms for dynamic traffic metering in URBAN street networks,” IEEE Trans. Intelligent Transportation Systems, vol. 20, no. 5, pp. 1930–1941, 2018.
|
| [9] |
S. Dougherty and M. Guay, “An extremum-seeking controller for distributed optimization over sensor networks,” IEEE Trans. Automatic Control, vol. 62, no. 2, pp. 928–933, 2016.
|
| [10] |
S. Zhu, C. Chen, X. Ma, B. Yang, and X. Guan, “Consensus based estimation over relay assisted sensor networks for situation monitoring,” IEEE J. Selected Topics in Signal Processing, vol. 9, no. 2, pp. 278–291, 2014.
|
| [11] |
A. Nedic, A. Olshevsky, and W. Shi, “Achieving geometric convergence for distributed optimization over time-varying graphs,” SIAM J. Optimization, vol. 27, no. 4, pp. 2597–2633, 2017. doi: 10.1137/16M1084316
|
| [12] |
T. Yang, Y. Wan, H. Wang, and Z. Lin, “Global optimal consensus for discrete-time multi-agent systems with bounded controls,” Automatica, vol. 97, pp. 182–185, 2018. doi: 10.1016/j.automatica.2018.08.017
|
| [13] |
X. Ren, D. Li, Y. Xi, and H. Shao, “Distributed subgradient algorithm for multi-agent optimization with dynamic stepsize,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 8, pp. 1451–1464, 2021. doi: 10.1109/JAS.2021.1003904
|
| [14] |
P. Yi , Y. Hong, and F. Liu, “Distributed gradient algorithm for constrained optimization with application to load sharing in power systems,” Systems &Control Letters, vol. 83, pp. 45–52, 2015.
|
| [15] |
Y. Zhang, Y. Lou, and Y. Hong, “An approximate gradient algorithm for constrained distributed convex optimization,” IEEE/CAA J. Autom. Sinica, vol. 1, no. 1, pp. 61–67, 2014. doi: 10.1109/JAS.2014.7004621
|
| [16] |
X. Li, X. Yi, and L. Xie, “Distributed online optimization for multiagent networks with coupled inequality constraints,” IEEE Trans. Automatic Control, vol. 66, no. 8, pp. 3575–3591, 2021.
|
| [17] |
Q. Lü, X. Liao, T. Xiang, H. Li, and T. Huang, “Privacy masking stochastic subgradient-push algorithm for distributed online optimization,” IEEE Trans. Cybernetics, vol. 51, no. 6, pp. 3224–3237, 2020.
|
| [18] |
L. Ding, P. Hu, Z.-W. Liu, and G. Wen, “Transmission lines overload alleviation: Distributed online optimization approach,” IEEE Trans. Industrial Informatics, vol. 17, no. 5, pp. 3197–3208, 2020.
|
| [19] |
S. Lee, A. Nedić, and M. Raginsky, “Stochastic dual averaging for de-centralized online optimization on time-varying communication graphs,” IEEE Trans. Automatic Control, vol. 62, no. 12, pp. 6407–6414, 2017. doi: 10.1109/TAC.2017.2650563
|
| [20] |
S. Shahrampour and A. Jadbabaie, “Distributed online optimization in dynamic environments using mirror descent,” IEEE Trans. Automatic Control, vol. 63, no. 3, pp. 714–725, 2017.
|
| [21] |
S. Hosseini, A. Chapman, and M. Mesbahi, “Online distributed convex optimization on dynamic networks,” IEEE Trans. Automatic Control, vol. 61, no. 11, pp. 3545–3550, 2016. doi: 10.1109/TAC.2016.2525928
|
| [22] |
D. Li, L. Yu, N. Li, and F. L. Lewis, “Virtual-action-based coordinated reinforcement learning for distributed economic dispatch,” IEEE Trans. Power Systems, vol. 36, no. 6, pp. 5143–5152, 2021.
|
| [23] |
Y. Duan, X. He, and Y. Zhao, “Distributed algorithm based on consensus control strategy for dynamic economic dispatch problem,” Int. J. Electrical Power &Energy Systems, vol. 129, p. 106833, 2021.
|
| [24] |
K. Wang, Z. Fu, Q. Xu, D. Chen, L. Wang, and W. Yu, “Distributed fixed step-size algorithm for dynamic economic dispatch with power flow limits,” Science China Information Sciences, vol. 64, no. 1, pp. 1–13, 2021.
|
| [25] |
X. He, Y. Zhao, and T. Huang, “Optimizing the dynamic economic dispatch problem by the distributed consensus-based admm approach,” IEEE Trans. Industrial Informatics, vol. 16, no. 5, pp. 3210–3221, 2019.
|
| [26] |
Y. Eidelman, V. D. Milman, and A. Tsolomitis, Functional Analysis: An Introduction. Providence, USA: American Mathematical Society, 2004, vol. 66.
|
| [27] |
F. L. Lewis, D. Vrabie, and V. L. Syrmos, Optimal Control. New York, USA: John Wiley & Sons, 2012.
|
| [28] |
Z. Lin, J. Duan, S. E. Li, J. Li, H. Ma, Q. Sun, J. Chen, and B. Cheng, “Solving finite-horizon HJB for optimal control of continuoustime systems,” in Proc. IEEE Int. Conf. Computer, Control and Robotics, 2021, pp. 116–122.
|
| [29] |
D. Bertsekas, “Value and policy iterations in optimal control and adaptive dynamic programming,” IEEE Trans. Neural Networks And Learning Systems, vol. 28, no. 3, pp. 500–509, 2015.
|
| [30] |
B. Kiumarsi, K. G. Vamvoudakis, H. Modares, and F. L. Lewis, “Optimal and autonomous control using reinforcement learning: A survey,” IEEE Trans. Neural Networks and Learning Systems, vol. 29, no. 6, pp. 2042–2062, 2017.
|
| [31] |
B. Lian, W. Xue, F. L. Lewis, and T. Chai, “Robust inverse Q-learning for continuous-time linear systems in adversarial environments,” IEEE Trans. Cybernetics, vol. 52, no. 12, pp. 13083–13095, 2022. doi: 10.1109/TCYB.2021.3100749
|
| [32] |
K. G. Vamvoudakis, D. Vrabie, and F. L. Lewis, “Online adaptive algorithm for optimal control with integral reinforcement learning,” Int. J. Robust Nonlinear Control, vol. 24, no. 17, pp. 2686–2710, 2014. doi: 10.1002/rnc.3018
|
| [33] |
B. Lian, W. Xue, F. L. Lewis, and T. Chai, “Online inverse reinforcement learning for nonlinear systems with adversarial attacks,” Int. J. Robust and Nonlinear Control, vol. 31, no. 14, pp. 6646–6667, 2021. doi: 10.1002/rnc.5626
|
| [34] |
Q. Zhao, H. Xu, and S. Jagannathan, “Near optimal output feedback control of nonlinear discrete-time systems based on reinforcement neural network learning,” IEEE/CAA J. Automa. Sinica, vol. 1, no. 4, pp. 372–384, 2014. doi: 10.1109/JAS.2014.7004665
|
| [35] |
Z. Shi and Z. Wang, “Adaptive output-feedback optimal control for continuous-time linear systems based on adaptive dynamic programming approach,” Neurocomputing, vol. 438, pp. 334–344, 2021. doi: 10.1016/j.neucom.2021.01.070
|
| [36] |
Z.-P. Jiang, T. Bian, and W. N. Gao, “Learning-based control: A tutorial and some recent results,” Foundations and Trends ® in Systems and Control, vol. 8, p. 3, 2020.
|
| [37] |
K. G. Vamvoudakis and N.-M. T. Kokolakis, “Synchronous reinforcement learning-based control for cognitive autonomy,” Foundations and Trends ® in Systems and Control, vol. 8, pp. 1–2, 2020.
|
| [38] |
Z. Chen, W. Q. Xue, N. Li, and F. L. Lewis, “Twoloop reinforcement learning algorithm for finite-horizon optimal control of continuous-time affine nonlinear systems,” Int. J. Robust and Nonlinear Control, vol. 32, no. 1, pp. 393–420, 2022. doi: 10.1002/rnc.5826
|
| [39] |
A. Menon and J. S. Baras, “Collaborative extremum seeking for welfare optimization,” in Proc. IEEE Conf. Decision and Control, 2014, pp. 346–351.
|

Figures(12)






 DownLoad:
DownLoad: