A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 9
Issue 9
Volume 9
Issue 9
IEEE/CAA Journal of Automatica Sinica
| Citation: | Z. Y. Zhang, Z. B. Mo, Y. T. Chen, and J. Huang, “Reinforcement learning behavioral control for nonlinear autonomous system,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 9, pp. 1561–1573, Sept. 2022. doi: 10.1109/JAS.2022.105797

|

| [1] |
H. Wang, H. Zhao, J. Zhang, D. Ma, J. Li, and J. Wei, “Survey on unmanned aerial vehicle networks: A cyber physical system perspective,” IEEE Communications Surveys &Tutorials, vol. 22, no. 2, pp. 1027–1070, 2019.
|
| [2] |
Y. Cao, W. Yu, W. Ren, and G. Chen, “An overview of recent progress in the study of distributed multi-agent coordination,” IEEE Trans. Industrial informatics, vol. 9, no. 1, pp. 427–438, 2012.
|
| [3] |
K. K. Oh, M. C. Park, and H. S. Ahn, “A survey of multi-agent formation control,” Automatica, vol. 53, pp. 424–440, 2015. doi: 10.1016/j.automatica.2014.10.022
|
| [4] |
H. Yang and J. Liu, “An adaptive rbf neural network control method for a class of nonlinear systems,” IEEE/CAA J. Autom. Sinica, vol. 5, no. 2, pp. 457–462, 2018. doi: 10.1109/JAS.2017.7510820
|
| [5] |
J. Lu, Q. Wei, and F. Wang, “Parallel control for optimal tracking via adaptive dynamic programming,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 6, pp. 1662–1674, 2020. doi: 10.1109/JAS.2020.1003426
|
| [6] |
M. Tipaldi and L. Glielmo, “A survey on model-based mission planning and execution for autonomous spacecraft,” IEEE Systems Journal, vol. 12, no. 4, pp. 3893–3905, 2017.
|
| [7] |
L. Garattoni and M. Birattari, “Autonomous task sequencing in a robot swarm,” Science Robotics, vol. 3, no. 20, 2018.
|
| [8] |
H. Ueno and Y. Saito, “Model-based vision and intelligent task scheduling for autonomous human-type robot arm,” Robotics and Autonomous Systems, vol. 18, no. 1-2, pp. 195–206, 1996. doi: 10.1016/0921-8890(95)00077-1
|
| [9] |
C. Ott, A. Dietrich, and A. Albu-Schäffer, “Prioritized multi-task compliance control of redundant manipulators,” Automatica, vol. 53, pp. 416–423, 2015. doi: 10.1016/j.automatica.2015.01.015
|
| [10] |
R. Brooks, “A robust layered control system for a mobile robot,” IEEE Journal on Robotics and Automation, vol. 2, no. 1, pp. 14–23, 1986. doi: 10.1109/JRA.1986.1087032
|
| [11] |
R. C. Arkin, “Motor schema based mobile robot navigation,” The Int. Journal of Robotics Research, vol. 8, no. 4, pp. 92–112, 1989. doi: 10.1177/027836498900800406
|
| [12] |
T. Balch and R. C. Arkin, “Behavior-based formation control for multirobot teams,” IEEE Trans. Robotics and Automation, vol. 14, no. 6, pp. 926–939, 1998. doi: 10.1109/70.736776
|
| [13] |
G. Antonelli and S. Chiaverini, “Kinematic control of platoons of autonomous vehicles,” IEEE Trans. Robotics, vol. 22, no. 6, pp. 1285–1292, 2006. doi: 10.1109/TRO.2006.886272
|
| [14] |
G. Antonelli, F. Arrichiello, and S. Chiaverini, “The null-space-based behavioral control for autonomous robotic systems,” Intelligent Service Robotics, vol. 1, no. 1, pp. 27–39, 2008. doi: 10.1007/s11370-007-0002-3
|
| [15] |
A. Marino, L. E. Parker, G. Antonelli, and F. Caccavale, “A decentralized architecture for multi-robot systems based on the null-space-behavioral control with application to multi-robot border patrolling,” Journal of Intelligent &Robotic Systems, vol. 71, no. 3, pp. 423–444, 2013.
|
| [16] |
L. Moreno, E. Moraleda, M. Salichs, J. Pimentel, and A. de la Escalera, “Fuzzy supervisor for behavioral control of autonomous systems,” in Proc. IECON’93-19th Annu. Conf. IEEE Industrial Electronics, pp. 258–261, 1993.
|
| [17] |
A. Marino, F. Caccavale, L. E. Parker, and G. Antonelli, “Fuzzy behavioral control for multi-robot border patrol,” in Proc. IEEE 17th Mediterranean Conf. Control and Automation, pp. 246–251, 2009.
|
| [18] |
Y. Chen, Z. Zhang, and J. Huang, “Dynamic task priority planning for null-space behavioral control of multi-agent systems,” IEEE Access, vol. 8, pp. 149643–149651, 2020. doi: 10.1109/ACCESS.2020.3016347
|
| [19] |
J. Chen, M. Gan, J. Huang, L. Dou, and H. Fang, “Formation control of multiple Euler-Lagrange systems via null-space-based behavioral control,” Science China Information Sciences, vol. 59, no. 1, pp. 1–11, 2016.
|
| [20] |
M. C. P. Santos, C. D. Rosales, M. Sarcinelli-Filho, and R. Carelli, “A novel null-space-based UAV trajectory tracking controller with collision avoidance,” IEEE/ASME Trans. Mechatronics, vol. 22, no. 6, pp. 2543–2553, 2017. doi: 10.1109/TMECH.2017.2752302
|
| [21] |
J. Huang, N. Zhou, and M. Cao, “Adaptive fuzzy behavioral control of second-order autonomous agents with prioritized missions: Theory and experiments,” IEEE Trans. Industrial Electronics, vol. 66, no. 12, pp. 9612–9622, 2019. doi: 10.1109/TIE.2019.2892669
|
| [22] |
N. Zhou, X. Cheng, Z. Sun, and Y. Xia, “Fixed-time cooperative behavioral control for networked autonomous agents with second-order nonlinear dynamics,” IEEE Trans. Cybernetics, 2021. DOI: 10.1109/TCYB.2021.3057219.
|
| [23] |
F. L. Lewis, D. Vrabie, and V. L. Syrmos, Optimal Control. John Wiley & Sons, 2012.
|
| [24] |
B. Kiumarsi, K. G. Vamvoudakis, H. Modares, and F. L. Lewis, “Optimal and autonomous control using reinforcement learning: A survey,” IEEE Trans. Neural Networks and Learning Systems, vol. 29, no. 6, pp. 2042–2062, 2017.
|
| [25] |
D. Liu, S. Xue, B. Zhao, B. Luo, and Q. Wei, “Adaptive dynamic programming for control: A survey and recent advances,” IEEE Trans. Systems, Man, and Cybernetics: Systems, 2020.
|
| [26] |
V. G. Lopez and F. L. Lewis, “Dynamic multiobjective control for continuous-time systems using reinforcement learning,” IEEE Trans. Automatic Control, vol. 64, no. 7, pp. 2869–2874, 2018.
|
| [27] |
M. Mazouchi, Y. Yang, and H. Modares, “Data-driven dynamic multiobjective optimal control: An aspiration-satisfying reinforcement learning approach,” IEEE Trans. Neural Networks and Learning Systems, 2021. DOI: 10.1109/TNNLS.2021.3072571.
|
| [28] |
K. Baizid, G. Giglio, F. Pierri, M. A. Trujillo, G. Antonelli, F. Caccavale, A. Viguria, S. Chiaverini, and A. Ollero, “Behavioral control of unmanned aerial vehicle manipulator systems,” Autonomous Robots, vol. 41, no. 5, pp. 1203–1220, 2017. doi: 10.1007/s10514-016-9590-0
|
| [29] |
A. Mustafa, N. K. Dhar, and N. K. Verma, “Event-triggered sliding mode control for trajectory tracking of nonlinear systems,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 1, pp. 307–314, 2019.
|
| [30] |
C. Silvestre, R. Cunha, N. Paulino, and A. Pascoal, “A bottom-following preview controller for autonomous underwater vehicles,” IEEE Trans. Control Systems Technology, vol. 17, no. 2, pp. 257–266, 2008.
|
| [31] |
J. Funke, M. Brown, S. M. Erlien, and J. C. Gerdes, “Collision avoidance and stabilization for autonomous vehicles in emergency scenarios,” IEEE Trans. Control Systems Technology, vol. 25, no. 4, pp. 1204–1216, 2016.
|
| [32] |
B. Wang and Y. Zhang, “An adaptive fault-tolerant sliding mode control allocation scheme for multirotor helicopter subject to simultaneous actuator faults,” IEEE Trans. Industrial Electronics, vol. 65, no. 5, pp. 4227–4236, 2017.
|
| [33] |
J. N. Franklin, Matrix Theory. Courier Corporation, 2012.
|
| [34] |
G. Wen, C. P. Chen, and B. Li, “Optimized formation control using simplified reinforcement learning for a class of multiagent systems with unknown dynamics,” IEEE Trans. Industrial Electronics, vol. 67, no. 9, pp. 7879–7888, 2019.
|
| [35] |
G. Wen, C. P. Chen, J. Feng, and N. Zhou, “Optimized multi-agent formation control based on an identifier-actor-critic reinforcement learning algorithm,” IEEE Trans. Fuzzy Systems, vol. 26, no. 5, pp. 2719–2731, 2017.
|
| [36] |
S. S. Ge and C. Wang, “Adaptive neural control of uncertain mimo nonlinear systems,” IEEE Trans. Neural Networks, vol. 15, no. 3, pp. 674–692, 2004. doi: 10.1109/TNN.2004.826130
|
| [37] |
V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, 2015. doi: 10.1038/nature14236
|
| [38] |
T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized experience replay,” arXiv preprint arXiv: 1511.05952, 2015.
|
| [39] |
Z. Wang, T. Schaul, M. Hessel, H. Hasselt, M. Lanctot, and N. Freitas, “Dueling network architectures for deep reinforcement learning,” in Proc. Int. Conf. Machine Learning, pp. 1995–2003, PMLR, 2016.
|
| [40] |
R. W. Beard, G. N. Saridis, and J. T. Wen, “Galerkin approximations of the generalized Hamilton-Jacobi-Bellman equation,” Automatica, vol. 33, no. 12, pp. 2159–2177, 1997. doi: 10.1016/S0005-1098(97)00128-3
|
| [41] |
B. Kosko, “Fuzzy systems as universal approximators,” IEEE Trans. Computers, vol. 43, no. 11, pp. 1329–1333, 1994. doi: 10.1109/12.324566
|
| [42] |
W. He, S. S. Ge, Y. Li, E. Chew, and Y. S. Ng, “Impedance control of a rehabilitation robot for interactive training,” in Proc. Int. Conf. Social Robotics, pp. 526–535, Springer, 2012.
|
| [43] |
H. Lin, B. Zhao, D. Liu, and C. Alippi, “Data-based fault tolerant control for affine nonlinear systems through particle swarm optimized neural networks,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 4, pp. 954–964, 2020. doi: 10.1109/JAS.2020.1003225
|
| [44] |
M. A. Johnson and M. H. Moradi, PID Control. Springer, 2005.
|
| [45] |
G. Wen, C. P. Chen, S. S. Ge, H. Yang, and X. Liu, “Optimized adaptive nonlinear tracking control using actor-critic reinforcement learning strategy,” IEEE Trans. Industrial Informatics, vol. 15, no. 9, pp. 4969–4977, 2019. doi: 10.1109/TII.2019.2894282
|
| [46] |
Y. Liu, X. Liu, Y. Jing, and Z. Zhang, “A novel finite-time adaptive fuzzy tracking control scheme for nonstrict feedback systems,” IEEE Trans. Fuzzy Systems, vol. 27, no. 4, pp. 646–658, 2018.
|
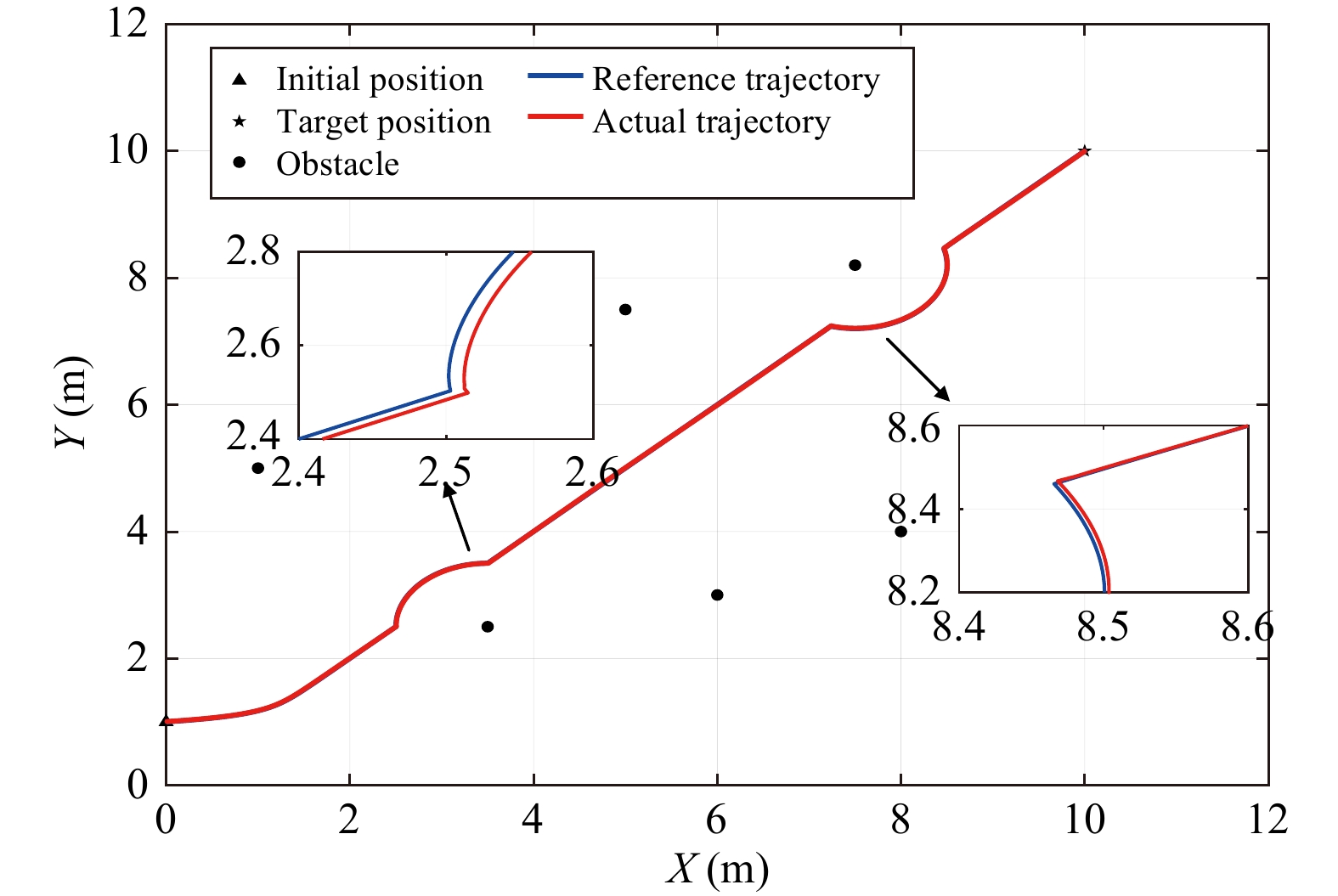
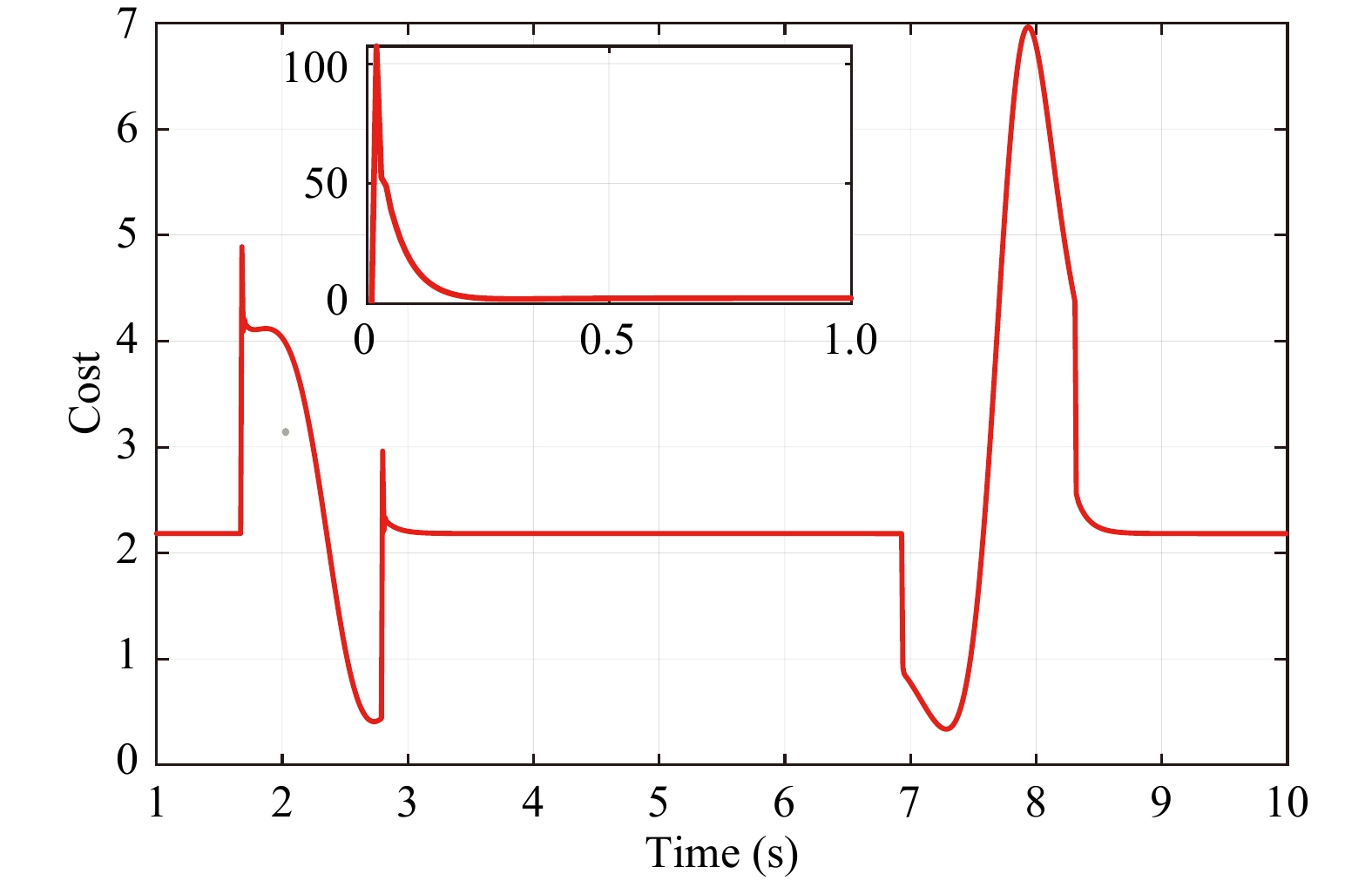
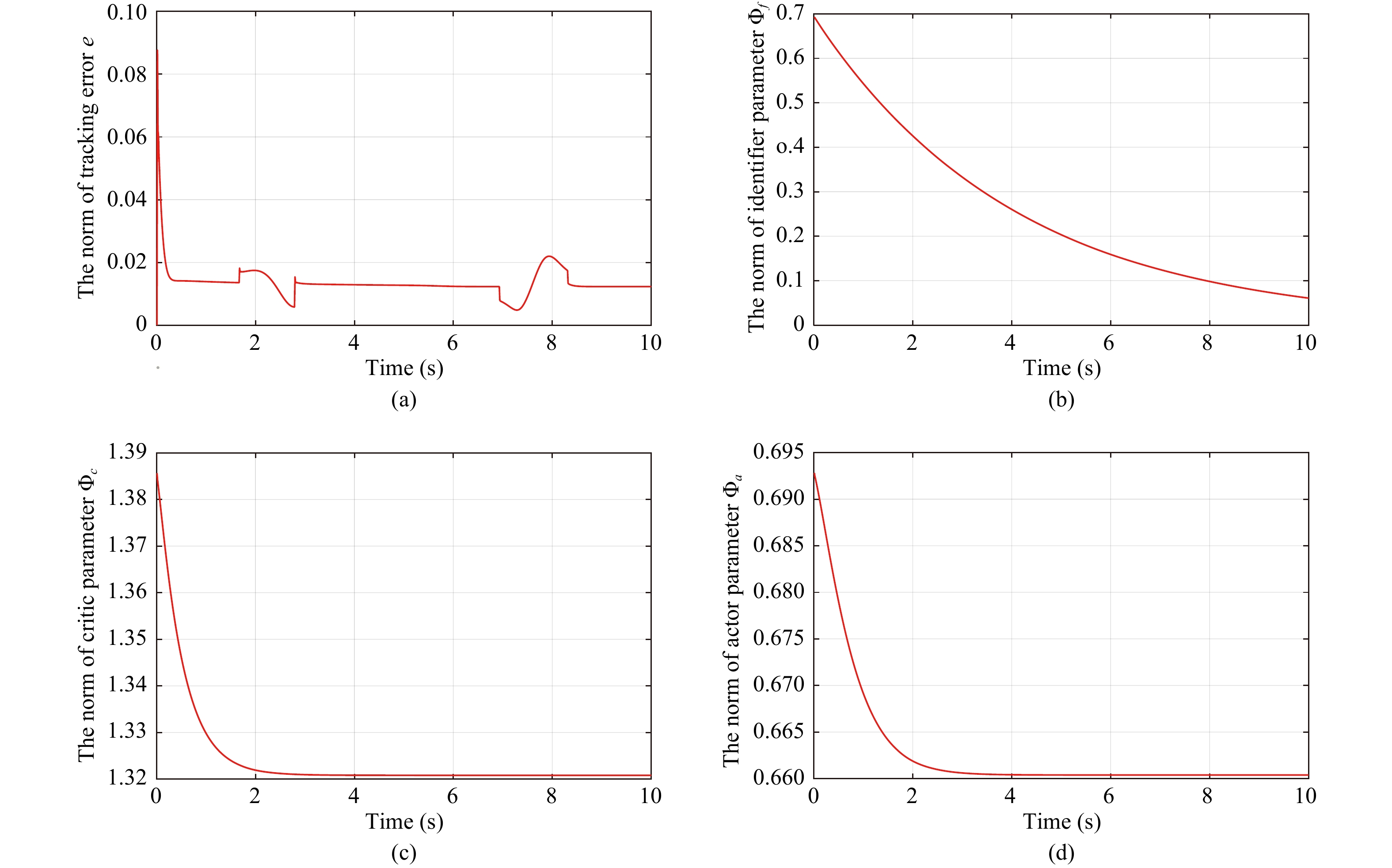
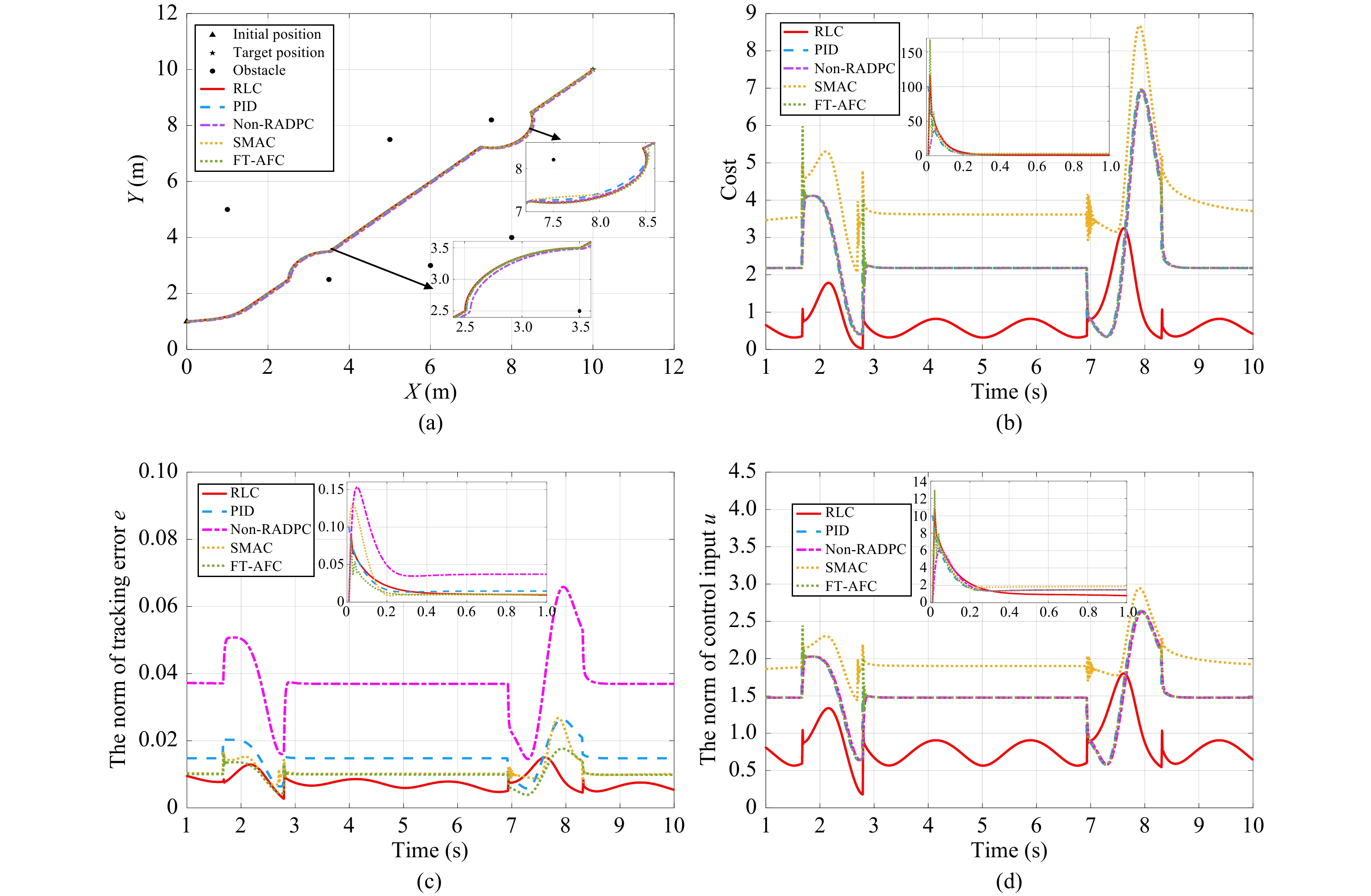
Figures(10) / Tables(6)






 DownLoad:
DownLoad: