A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 9
Issue 6
Volume 9
Issue 6
IEEE/CAA Journal of Automatica Sinica
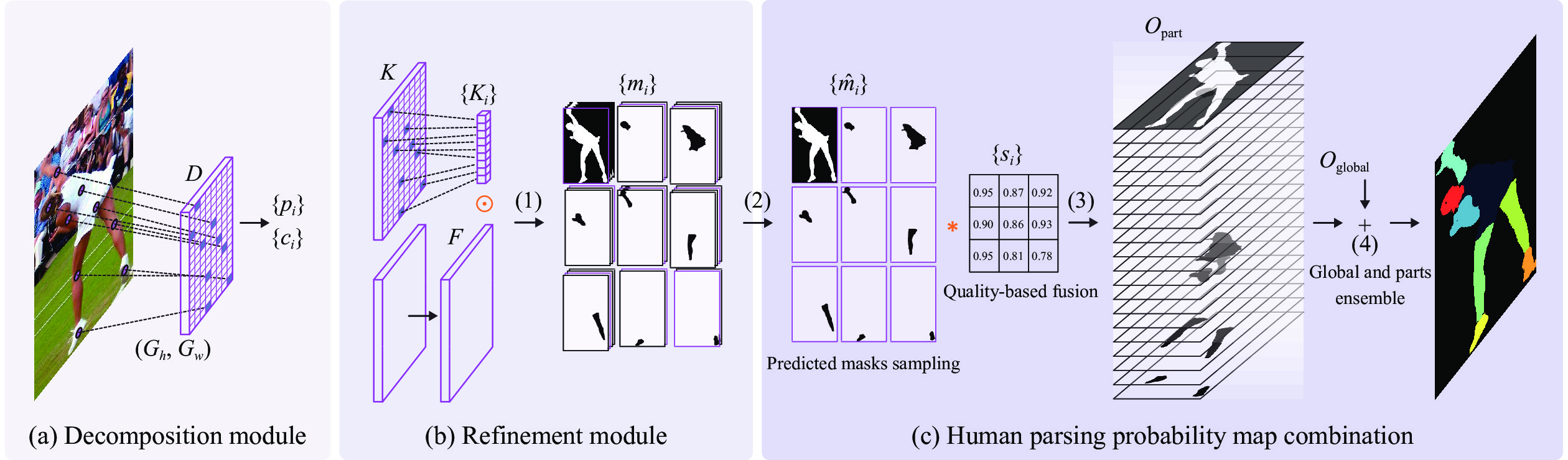
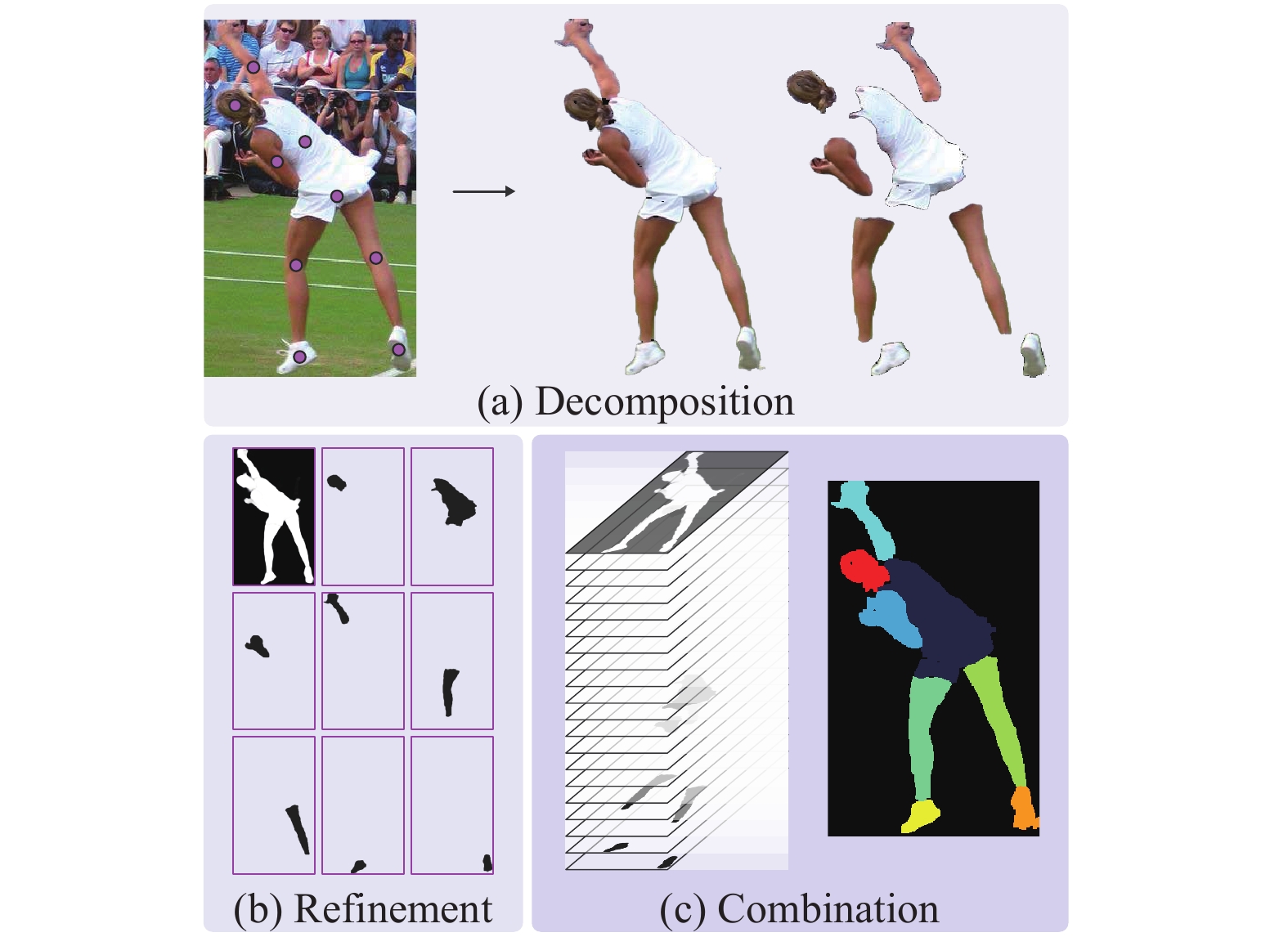
| Citation: | L. Yang, Z. W. Liu, T. F. Zhou, and Q. Song, “Part decom- position and refinement network for human parsing,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 6, pp. 1111–1114, Jun. 2022. doi: 10.1109/JAS.2022.105647

|

| [1] |
S. Qi, W. Wang, B. Jia, J. Shen, and S.-C. Zhu, “Learning human-object interactions by graph parsing neural networks,” in Proc. ECCV, 2018.
|
| [2] |
T. Zhou, S. Qi, W. Wang, J. Shen, and S.-C. Zhu, “Cascaded parsing of human-object interaction recognition,” in Proc. TPAMI, 2021.
|
| [3] |
K. Gong, X. Liang, Y. Li, Y. Chen, and L. Lin, “Instance-level human parsing via part grouping network,” in Proc. ECCV, 2018.
|
| [4] |
T. Zhou, W. Wang, S. Liu, Y. Yang, and L. V. Gool, “Differentiable multi-granularity human representation learning for instance-aware human semantic parsing,” in Proc. ICCV, 2021.
|
| [5] |
T. Ruan, T. Liu, Z. Huang, Y. Wei, S. Wei, Y. Zhao, and T. Huang, “Devil in the details: Towards accurate single and multiple human parsing,” in Proc. AAAI, 2019.
|
| [6] |
L. Yang, Q. Song, Z. Wang, and M. Jiang, “Parsing r-CNN for instance-level human analysis,” in Proc. CVPR, 2019.
|
| [7] |
W. Wang, Z. Zhang, S. Qi, J. Shen, Y. Pang, and L. Shao, “Learning compositional neural information fusion for human parsing,” in Proc. ICCV, 2019.
|
| [8] |
W. Wang, H. Zhu, J. Dai, Y. Pang, J. Shen, and L. Shao, “Hierarchical human parsing with typed part-relation reasoning,” in Proc. CVPR, 2020.
|
| [9] |
L. Yang, Q. Song, Z. Wang, M. Hu, C. Liu, X. Xin, W. Jia, and S. Xu, “Renovating parsing r-CNN for accurate multiple human parsing,” in Proc. ECCV, 2020.
|
| [10] |
X. Zhang, Y. Chen, B. Zhu, J. Wang, and M. Tang, “Part-aware context network for human parsing,” in Proc. CVPR, 2020.
|
| [11] |
L. Yang, Q. Song, Z. Wang, Z. Liu, S. Xu, and Z. Li, “Quality-aware network for human parsing,” arXiv: 2103.05997, 2021.
|
| [12] |
K. He, G. Gkioxari, P. Dollár, and R. Girshick, “Mask r-CNN,” in Proc. ICCV, 2017.
|
| [13] |
X. Wang, T. Kong, C. Shen, Y. Jiang, and L. Li, “SOLO: Segmenting objects by locations,” in Proc. ECCV, 2020.
|
| [14] |
W. Xinlong, Z. Rufeng, K. Tao, L. Lei, and S. Chunhua, “Solov2: Dynamic, faster and stronger,” in Proc. NIPS, 2020.
|
| [15] |
F. Xia, P. Wang, X. Chen, and A. L. Yuille, “Joint multi-person pose estimation and semantic part segmentation,” in Proc. CVPR, 2017.
|
| [16] |
X. Liang, K. Gong, X. Shen, and L. Lin, “Look into person: Joint human parsing and pose estimation network and a new benchmark,” in Proc. TPAMI, 2018.
|
| [17] |
L. Yang, Q. Song, Y. Wu, and M. Hu, “Attention inspiring receptive-fields network for learning invariant representations,” in Proc. TNNLS, 2018.
|
| [18] |
Z. Zhang, C. Su, L. Zheng, and X. Xie, “Correlating edge, pose with parsing,” in Proc. CVPR, 2020.
|
| [19] |
Y. Liu, L. Zhao, S. Zhang, and J. Yang, “Hybrid resolution network using edge guided region mutual information loss for human parsing,” in Proc. ACM MM, 2020.
|
| [20] |
R. Ji, D. Du, L. Zhang, L. Wen, Y. Wu, C. Zhao, F. Huang, and S. Lyu, “Learning semantic neural tree for human parsing,” in Proc. ECCV, 2020.
|
| [21] |
N. Wang and H. Ai, “Who blocks who: Simultaneous clothing segmentation for grouping images,” in Proc. ICCV, 2011.
|
| [22] |
L. Zhu, Y. Chen, Y. Lu, C. Lin, and A. Yuille, “Max margin and/or graph learning for parsing the human body,” in Proc. CVPR, 2008.
|
| [23] |
K. Gong, Y. Gao, X. Liang, X. Shen, and L. Lin, “Graphonomy: Universal human parsing via graph transfer learning,” in Proc. CVPR, 2019.
|
| [24] |
S. Wang, Y. Gong, J. Xing, L. Huang, C. Huang, and W. Hu, “RDSNet: A new deep architecture for reciprocal object detection and instance segmentation,” in Proc. AAAI, 2020.
|
| [25] |
T. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” in Proc. ICCV, 2017.
|
| [26] |
N. Bodla, B. Singh, R. Chellappa, and L. S. Davis, “Improving object detection with one line of code,” in Proc. ICCV, 2017.
|
| [27] |
H. Qin, W. Hong, W.-C. Hung, Y.-H. Tsai, and M.-H. Yang, “A top-down unified framework for instance-level human parsing,” in Proc. BMVC, 2019.
|
| [28] |
X. Liu, M. Zhang, W. Liu, J. Song, and T. Mei, “BraidNet: Braiding semantics and details for accurate human parsing,” in Proc. ACM MM, 2019.
|
| [29] |
L. Chen, Y. Yang, J. Wang, W. Xu, and A. Yuille, “Attention to scale: Scale-aware semantic image segmentation,” in Proc. CVPR, 2016.
|
| [30] |
Y. Luo, Z. Zheng, L. Zheng, T. Guan, J. Yu, and Y. Yang, “Macro-micro adversarial network for human parsing,” in Proc. ECCV, 2018.
|
| [31] |
Y. Yuan, X. Chen, and J. Wang, “Object-contextual representations for semantic segmentation,” in Proc. ECCV, 2020.
|
| [32] |
P. Li, Y. Xu, Y. Wei, and Y. Yang, “Self-correction for human parsing,” arXiv:1910.09777, 2019.
|
Figures(2) / Tables(6)






 DownLoad:
DownLoad: