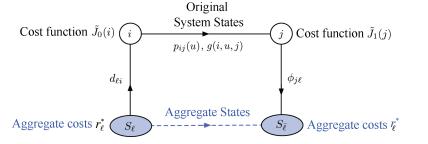
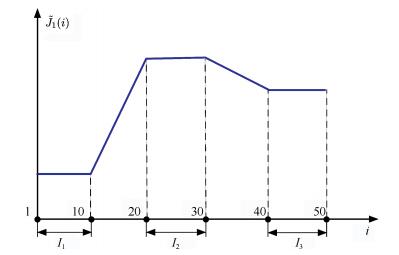
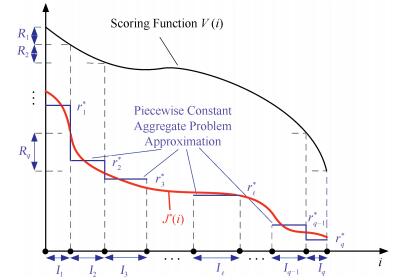
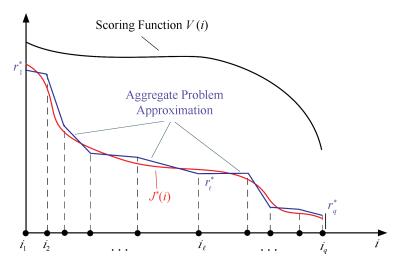
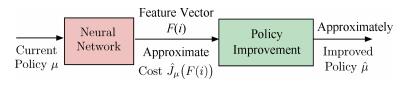
A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 6
Issue 1
Volume 6
Issue 1
IEEE/CAA Journal of Automatica Sinica
| Citation: | Dimitri P. Bertsekas, "Feature-Based Aggregation and Deep Reinforcement Learning: A Survey and Some New Implementations," IEEE/CAA J. Autom. Sinica, vol. 6, no. 1, pp. 1-31, Jan. 2019. doi: 10.1109/JAS.2018.7511249

|

| [1] |
D. P. Bertsekas, "Approximate policy iteration: a survey and some new methods, " J. Control Theory Appl., vol. 9, no. 3, pp. 310-335, Aug. 2011. http://www.cnki.com.cn/Article/CJFDTotal-KZLL201103003.htm
|
| [2] |
C. E. Shannon, "Programming a digital computer for playing chess, " Phil. Mag., vol. 41, no. 7, pp. 356-375, 1950. doi: 10.1080/14786445008521796
|
| [3] |
A. L. Samuel, "Some studies in machine learning using the game of checkers, " IBM J. Res. Develop., vol. 3, pp. 210-229, 1959. doi: 10.1147/rd.33.0210
|
| [4] |
A. L. Samuel, "Some studies in machine learning using the game of checkers. Ⅱ-Recent progress, " IBM J. Res. Develop., vol. pp. 601-617, 1967. http://www.sciencedirect.com/science/article/pii/0066413869900044
|
| [5] |
P. J. Werbös, "Advanced forecasting methods for global crisis warning and models of intelligence, " Gener. Syst. Yearbook, vol. 22, no. 6, pp. 25-38, Jan. 1977.
|
| [6] |
A. G. Barto, R. S. Sutton, and C. W. Anderson, "Neuronlike adaptive elements that can solve difficult learning control problems, " IEEE Trans. Syst. Man Cybern., vol. 13, no. 5, pp. 835-846, Sep-Oct. 1983. http://dl.acm.org/citation.cfm?id=104432
|
| [7] |
J. Christensen and R. E. Korf, "A unified theory of heuristic evaluation functions and its application to learning, " in Proc. of the 5th AAAI National Conf. on Artificial Intelligence, Philadelphia, Pennsylvania, 1986, pp. 148-152.
|
| [8] |
J. H. Holland, "Escaping brittleness: the possibilities of general purpose learning algorithms applied to parallel rule-based systems, " Machine Learning: An Artificial Intelligence Approach, R. S. Michalski, J. G. Carbonell, and T. M. Mitchell, eds. San Mateo, CA: Morgan Kaufmann, 1986, pp. 593-623.
|
| [9] |
R. S. Sutton, "Learning to predict by the methods of temporal differences, " Mach. Learn., vol. 3, no. 1, pp. 9-44, Aug. 1988.
|
| [10] |
G. Tesauro, "Practical issues in temporal difference learning, " Mach. Learn., vol. 8, no. 3-4, pp. 257-277, 1992. doi: 10.1007/BF00992697
|
| [11] |
G. Tesauro, "TD-gammon, a self-teaching backgammon program, achieves master-level play, " Neural Comput., vol. 6, no. 2, pp. 215-219, Mar. 1994. doi: 10.1007/978-1-4757-2379-3_11.pdf
|
| [12] |
G. Tesauro, "Temporal difference learning and TD-gammon, " Commun. ACM, vol. 38, no. 3, pp. 58-68, Mar. 1995.
|
| [13] |
G. Tesauro, "Programming backgammon using self-teaching neural nets, " Artif. Intell., vol. 134, no. 1-2, pp. 181-199, Jan. 2002.
|
| [14] |
G. Tesauro, "Neurogammon wins computer olympiad, " Neural Comput., vol. 1, no. 3, pp. 321-323, 1989. doi: 10.1162/neco.1989.1.3.321
|
| [15] |
G. Tesauro, "Connectionist learning of expert preferences by comparison training, " in Advances in Neural Information Processing Systems, Cambridge, MA, 1989, pp. 99-106. http://dl.acm.org/citation.cfm?id=89863
|
| [16] |
G. Tesauro and G. R. Galperin, "On-line policy improvement using monte-carlo search, " Presented at the 1996 Neural Information Processing Systems Conference, Denver; also in Advances in Neural Information Processing Systems 9, M. Mozer et al. eds. Denver, Colorado, 1997.
|
| [17] |
D. P. Bertsekas, Dynamic Programming and Optimal Control, Vol. I, 4th ed. Belmont, MA: Athena Scientific, 2017.
|
| [18] |
A. G. Barto, S. J. Bradtke, and S. P. Singh, " Real-time learning and control using asynchronous dynamic programming, " Artif. Intell., vol. 72, no. 1-2, pp. 81-138, Jun. 1995.
|
| [19] |
D. P. Bertsekas and J. N. Tsitsiklis, Neuro-Dynamic Programming. Belmont, MA: Athena Scientific, 1996.
|
| [20] |
R. S. Sutton and A. G. Barto, Reinforcement Learning. Cambridge, MA: MIT Press, 1998(A draft 2nd edition is available on-line).
|
| [21] |
X. R. Cao, Stochastic Learning and Optimization: A Sensitivity-Based Approach. Springer, 2007.
|
| [22] |
L. Busoniu, R. Babuska, B. De Schutter, and D. Ernst, Reinforcement Learning and Dynamic Programming Using Function Approximators. Boca Raton, FL, USA: CRC Press, 2010.
|
| [23] |
C. Szepesvari, Algorithms for Reinforcement Learning, San Franscisco, CA: Morgan and Claypool Publishers, 2010.
|
| [24] |
W. B. Powell, Approximate Dynamic Programming: Solving the Curses of Dimensionality, 2nd Ed. Hoboken, NJ: John Wiley and Sons, 2011.
|
| [25] |
H. S. Chang, J. Q. Hu, M. C. Fu, and S. I. Marcus, Simulation-Based Algorithms for Markov Decision Processes, 2nd Ed. Springer, 2013.
|
| [26] |
V. Vrabie, K. G. Vamvoudakis, and F. L. Lewis, Optimal Adaptive Control and Differential Games by Reinforcement Learning Principles. London: The Institution of Engineering and Technology, London, 2012.
|
| [27] |
A. Gosavi, Simulation-Based Optimization: Parametric Optimization Techniques and Reinforcement Learning, 2nd Ed. Springer, 2015.
|
| [28] |
J. Si, A. G. Barto, W. B. Powell, and D. Wunsch, Handbook of Learning and Approximate Dynamic Programming. IEEE Press, 2004.
|
| [29] |
F. L. Lewis, D. Liu, and G. G. Lendaris, "Special issue on adaptive dynamic programming and reinforcement learning in feedback control, " IEEE Trans. Syst. Man Cybern. Part B:Cybern., vol. 38, no. 4, 2008. http://openurl.ebscohost.com/linksvc/linking.aspx?stitle=IEEE%20Transactions%20on%20Systems%20Man%20and%20Cybernetics%20Part%20B&volume=37&issue=3&spage=751
|
| [30] |
F. L. Lewis and D. Liu, Reinforcement Learning and Approximate Dynamic Programming for Feedback Control. IEEE Press, Computational Intelligence Series, 2012.
|
| [31] |
B. Abramson, "Expected-outcome: a general model of static evaluation, " IEEE Trans. Pattern Anal. Mach. Intell., vol. 12, no. 2, pp. 182-193, Feb. 1990. http://openurl.ebscohost.com/linksvc/linking.aspx?stitle=IEEE%20Transactions%20on%20Pattern%20Analysis%20and%20Machine%20Intelligence&volume=12&issue=2&spage=182
|
| [32] |
D. P. Bertsekas, J. N. Tsitsiklis, and C. Wu, "Rollout algorithms for combinatorial optimization, " Heurist., vol. 3, no. 3, pp. 245-262, Dec. 1997.
|
| [33] |
D. P. Bertsekas and D. A. Castanon, "Rollout algorithms for stochastic scheduling problems, " Heurist., vol. 5, no.1, pp. 89-108, Apr. 1999.
|
| [34] |
D. P. Bertsekas, "Rollout algorithms for discrete optimization: a survey, " in Handbook of Combinatorial Optimization, P. Pardalos, D. Z. Du, and R. Graham, eds. New York, NY: Springer, 2013.
|
| [35] |
H. S. Chang, M. C. Fu, J. Hu, and S. I. Marcus, "An adaptive sampling algorithm for solving Markov decision processes, " Operat. Res., vol. 53, no. 1, pp. 126-139, Feb. 2005. http://www.jstor.org/stable/25146851
|
| [36] |
R. Coulom, "Efficient selectivity and backup operators in Monte-Carlo tree search, " in Proc. of the 5th Int. Conf. on Computers and Games, Turin, Italy, 2006, pp. 72-83.
|
| [37] |
C. B. Browne, E. Powley, D. Whitehouse, S. M. Lucas, P. I. Cowling, P. Rohlfshagen, S. Tavener, D. Perez, S. Samothrakis, and S. Colton, "A survey of Monte Carlo tree search methods, " IEEE Trans. Comput. Intell. AI Games, vol. 4, no. 1, pp. 1-43, Mar. 2012.
|
| [38] |
I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning. Cambridge, MA:MIT Press, 2016.
|
| [39] |
J. Schmidhuber, "Deep learning in neural networks: an overview, " Neural Netw., vol. 61, pp. 85-117, Jan. 2015.
|
| [40] |
K. Arulkumaran, M. P. Deisenroth, M. Brundage, and A. A. Bharath, "A brief survey of deep reinforcement learning, " arXiv preprint arXiv: 1708.05866, 2017.
|
| [41] |
W. B. Liu, Z. D. Wang, X. H. Liu, N. Y. Zeng, Y. R. Liu, and F. E. Alsaadi, "A survey of deep neural network architectures and their applications, " Neurocomputing, vol. 234, pp. 11-26, Apr. 2017.
|
| [42] |
Y. X. Li, "Deep reinforcement learning: an overview, " arXiv preprint ArXiv: 1701.07274v5, 2017.
|
| [43] |
D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepel, T. Lillicrap, K. Simonyan, and D. Hassabis, "Mastering chess and Shogi by self-play with a general reinforcement learning algorithm, " arXiv preprint arXiv: 1712.01815, 2017.
|
| [44] |
A. G. Ivakhnenko, "The group method of data handling:a rival of the method of stochastic approximation, " Soviet Autom. Control, vol. 13, pp. 43-55, 1968.
|
| [45] |
A. G. Ivakhnenko, "Polynomial theory of complex systems, " IEEE Trans. Syst. Man Cybern., vol. 4, pp. 364-378, Oct. 1971. http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=4308320
|
| [46] |
J. C. Bean, J. R. Birge, and R. L. Smith, "Aggregation in dynamic programming, " Operat. Res., vol. 35, no.2, pp. 215-220, Apr. 1987.
|
| [47] |
F. Chatelin and W. L. Miranker, "Acceleration by aggregation of successive approximation methods, " Linear Algebra Appl., vol. 43, pp. 17-47, Mar. 1982.
|
| [48] |
C. C. Douglas and J. Douglas, "A unified convergence theory for abstract multigrid or multilevel algorithms, serial and parallel, " SIAM J. Numer. Anal., vol. 30, no. 1, pp. 136-158, 1993. doi: 10.1137/0730007
|
| [49] |
D. F. Rogers, R. D. Plante, R. T. Wong, and J. R. Evans, "Aggregation and disaggregation techniques and methodology in optimization, " Operat. Res., vol. 39, no. 4, pp. 553-582, Aug. 1991.
|
| [50] |
S. P. Singh, T. Jaakkola, and M. I. Jordan, "Reinforcement learning with soft state aggregation, " in Advances in Neural Information Processing Systems 7, MIT Press, 1995.
|
| [51] |
G. J. Gordon, "Stable function approximation in dynamic programming, " in Proc. of the 12th Int. Conf. on Machine Learning, California, 1995.
|
| [52] |
J. N. Tsitsiklis and B. Van Roy, "Feature-based methods for large scale dynamic programming, " Mach. Learn., vol. 22, no. 1-3, pp. 59-94, Mar. 1996.
|
| [53] |
K. Ciosek and D. Silver, "Value iteration with options and state aggregation, " Report, Center for Computational Statistics and Machine Learning, University College London, 2015.
|
| [54] |
I. V. Serban, C. Sankar, M. Pieper, J. Pineau, and J. Bengio, "The bottleneck simulator: a model-based deep reinforcement learning approach, " arXiv preprint arXiv: 1807.04723.v1, 2018.
|
| [55] |
D. P. Bertsekas, Dynamic Programming and Optimal Control, Vol. Ⅱ: Approximate Dynamic Programming, 4th ed. Belmont, MA: Athena Scientific, 2012.
|
| [56] |
O. E. David, N. S. Netanyahu, and L. Wolf, "Deepchess: end-to-end deep neural network for automatic learning in chess, " in Proc. of the 25th Int. Conf. Artificial Neural Networks, Barcelona, Spain, 2016, pp. 88-96. http://www.springerlink.com/openurl.asp?id=doi:10.1007/978-3-319-44781-0_11
|
| [57] |
D. P. Bertsekas, Abstract Dynamic Programming, 2nd Ed. Belmont, MA: Athena Scientific, 2018.
|
| [58] |
M. A. Krasnoselskii, G. M. Vainikko, R. P. Zabreyko, Y. B. Ruticki, and V. V. Stetśenko, Approximate Solution of Operator Equations. Groningen: Wolters-Noordhoff Pub., 1972.
|
| [59] |
C. A. J. Fletcher, Computational Galerkin Methods. franelatod by D. Louvish, Springer, 1984.
|
| [60] |
Y. Saad, Iterative Methods for Sparse Linear Systems, 2nd ed. Philadelphia, PA: SIAM, 2003.
|
| [61] |
A. Kirsch, An Introduction to the Mathematical Theory of Inverse Problems, 2nd Ed. Springer, 2011.
|
| [62] |
D. P. Bertsekas, "Temporal difference methods for general projected equations, " IEEE Trans. Autom. Control, vol. 56, no. 9, pp. 2128-2139, Sep. 2011.
|
| [63] |
H. Z. Yu and D. P. Bertsekas, "Error bounds for approximations from projected linear equations, " Math. Operat. Res., vol. 35, no. 2, pp. 306-329, Apr. 2010.
|
| [64] |
D. P. Bertsekas, "Proximal algorithms and temporal differences for large linear systems: extrapolation, approximation, and simulation, " Report LIDS-P-3205, MIT; arXiv preprint arXiv: 1610.05427, 2016.
|
| [65] |
D. P. Bertsekas, "Proximal algorithms and temporal difference methods for solving fixed point problems, " Comput. Optimiz. Appl., vol. 70, no. 3, pp. 709-736, Jul. 2018.
|
| [66] |
H. Z. Yu and D. P. Bertsekas, "Weighted Bellman Equations and their Applications in Approximate Dynamic Programming, " Lab. for Information and Decision Systems Report LIDS-P-2876, MIT, 2012.
|
| [67] |
D. P. Bertsekas, "λ-policy iteration: a review and a new implementation, " Lab. for Information and Decision Systems Report LIDSP-2874, MIT; in Reinforcement Learning and Approximate Dynamic Programming for Feedback Control, F. L. Lewis and D. R. Liu, eds. IEEE Press, Computational Intelligence Series, 2012.
|
| [68] |
A. Fern, S. Yoon, and R. Givan, "Approximate policy iteration with a policy language bias: solving relational Markov decision processes, " J. Artif. Intell. Res., vol. 25, pp. 75-118, Jan. 2006. http://dl.acm.org/citation.cfm?id=1622546
|
| [69] |
B. Scherrer, "Performance bounds for λ policy iteration and application to the game of Tetris, " J. Mach. Learn. Res., vol. 14, no. 1, pp. 1181-1227, Jan. 2013. http://www.oalib.com/paper/4086129
|
| [70] |
B. Scherrer, M. Ghavamzadeh, V. Gabillon, B. Lesner, and M. Geist, "Approximate modified policy iteration and its application to the game of Tetris, " J. Mach. Learn. Res., vol. 16, no. 1, pp. 1629-1676, Jan. 2015.
|
| [71] |
V. Gabillon, M. Ghavamzadeh, and B. Scherrer, "Approximate dynamic programming finally performs well in the game of Tetris, " in Advances in Neural Information Processing Systems, South Lake Tahoe, United States, 2013, pp. 1754-1762.
|
| [72] |
D. P. Bertsekas, Convex Optimization Algorithms. Belmont, MA: Athena Scientific, 2015.
|
| [73] |
D. P. Bertsekas, Nonlinear Programming, 3rd ed. Belmont, MA: Athena Scientific, 2016.
|
| [74] |
D. P. Bertsekas and J. N. Tsitsiklis, "Gradient convergence in gradient methods with errors, " SIAM J. Optimiz., vol. 10, no. 3, pp. 627-642, 2000. http://www.ams.org/mathscinet-getitem?mr=1741189
|
| [75] |
G. Cybenko, "Approximation by superpositions of a sigmoidal function, " Math. Control Sign. Syst., vol. 2, no. 4, pp. 303-314, Dec. 1989.
|
| [76] |
K. Funahashi, "On the approximate realization of continuous mappings by neural networks, " Neural Netw., vol. 2, no. 3, pp. 183-192, 1989.
|
| [77] |
K. Hornick, M. Stinchcombe, and H. White, "Multilayer feedforward networks are universal approximators, " Neural Netw., vol. 2, no. 5, pp. 359-366, 1989.
|
| [78] |
M. Leshno, V. Y. Lin, A. Pinkus, and S. Schocken, "Multilayer feedforward networks with a nonpolynomial activation function can approximate any function, " Neural Netw., vol. 6, no. 6, pp. 861-867, 1993.
|
| [79] |
C. M. Bishop, Neural Networks for Pattern Recognition. Oxford: Oxford University Press, 1995.
|
| [80] |
L. K. Jones, "Constructive approximations for neural networks by sigmoidal functions, " Proc. IEEE, vol. 78, no. 10, pp. 1586-1589, Oct. 1990.
|
| [81] |
G. E. Hinton, S. Osindero, and Y. W. Teh, "A fast learning algorithm for deep belief nets, " Neural Comput., vol. 18, no. 7, pp. 1527-1554, Jul. 2006.
|
| [82] |
S. Haykin, Neural Networks and Learning Machines, 3rd Ed. Englewood-Cliffs, NJ: Prentice-Hall, 2008.
|
| [83] |
B. Van Roy, "Performance loss bounds for approximate value iteration with state aggregation, " Math. Operat. Res., vol. 31, no. 2, pp. 234-244, May 2006. http://connection.ebscohost.com/c/articles/21761580/performance-loss-bounds-approximate-value-iteration-state-aggregation
|
| [84] |
J. N. Tsitsiklis, "Asynchronous stochastic approximation and Qlearning, " Mach. Learn., vol. 16, no. 3, pp. 185-202, Sep. 1994.
|
| [85] |
G. Tesauro, "Comparison training of chess evaluation functions, " in Machines that Learn to Play Games, Commack, Nova Science Publishers, 2001, pp. 117-130.
|
| [86] |
D. P. Bertsekas and D. A. Castanon, "Adaptive aggregation methods for infinite horizon dynamic programming, " IEEE Trans. Autom. Control, vol. 34, no. 6, pp. 589-598, Jun. 1989.
|
| [87] |
T. P. Runarsson, M. Schoenauer, and M. Sebag, Pilot, "Rollout and Monte Carlo Tree Search Methods for Job Shop Scheduling, " in Learning and Intelligent Optimization (pp. 160-174), Springer, Berlin, Heidelberg, 2012.
|
| [88] |
D. P. Bertsekas, "A counterexample to temporal differences learning, " Neural Comput., vol. 7, no. 2, pp. 270-279, Mar. 1995. http://dl.acm.org/citation.cfm?id=206098
|
| [89] |
D. P. Bertsekas and J. N. Tsitsiklis, "An analysis of stochastic shortest path problems, " Math. Operat. Res., vol. 16, no. 3, pp. 580-595, Aug. 1991. http://dl.acm.org/citation.cfm?id=119204
|
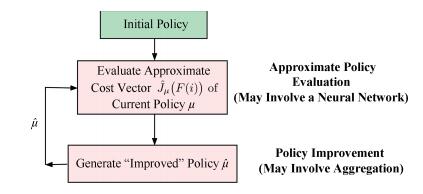
Figures(20)






 DownLoad:
DownLoad: