2024, 11(11): 2298-2315.
doi: 10.1109/JAS.2024.124677
Abstract:
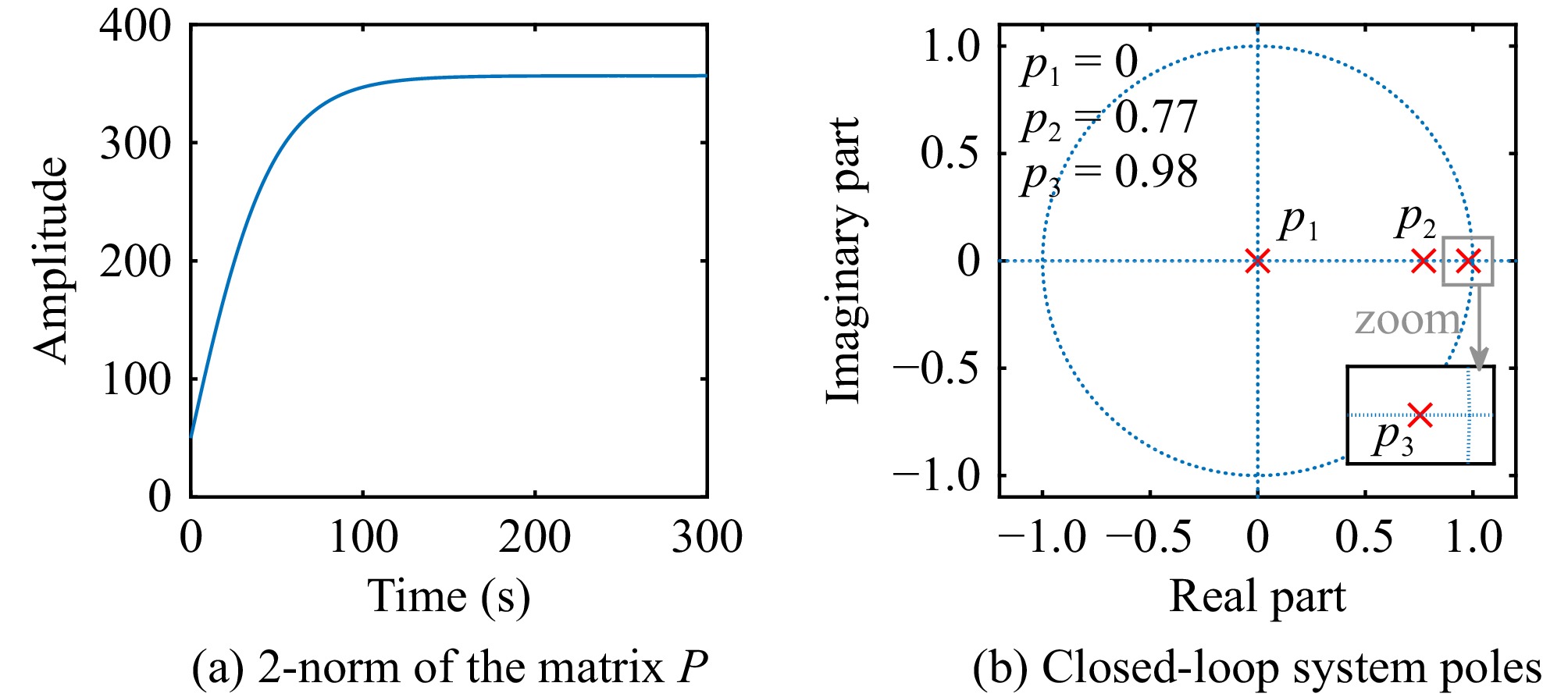
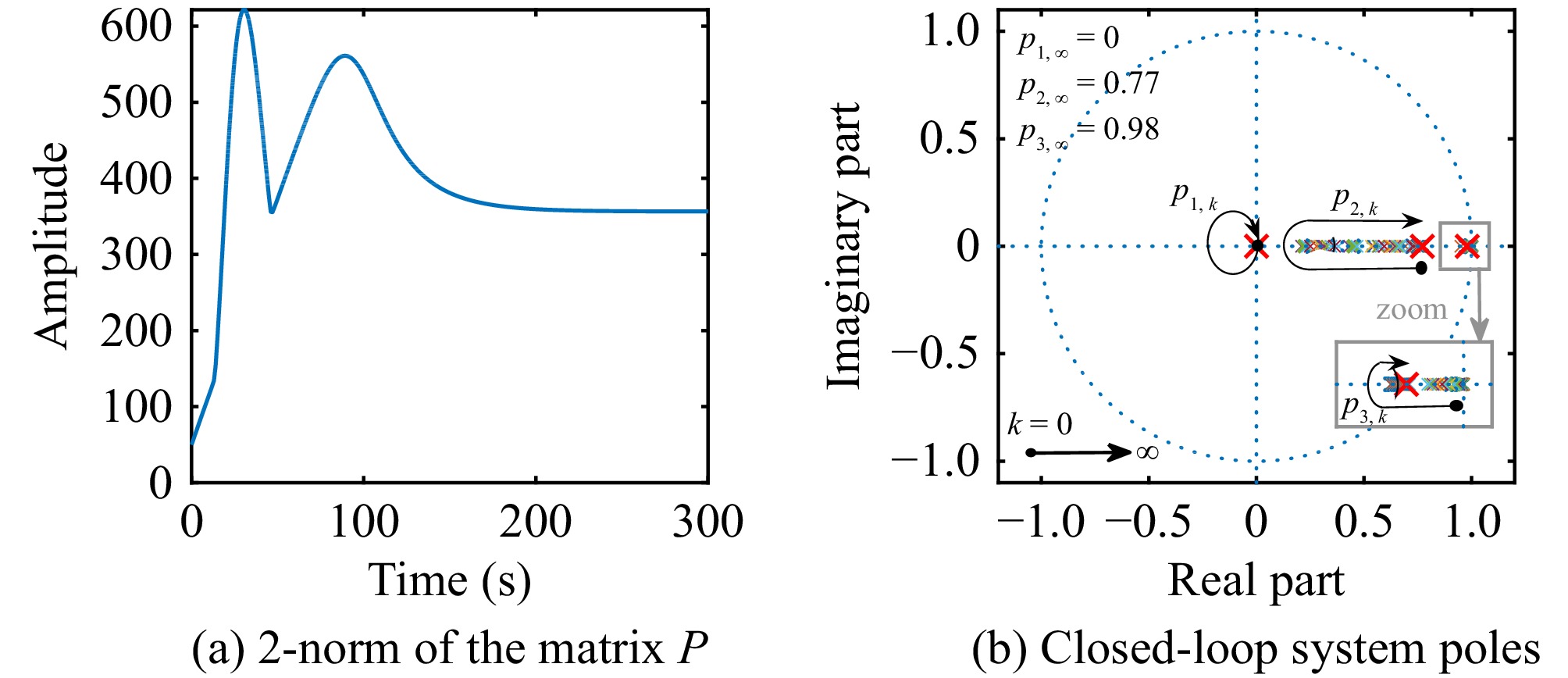
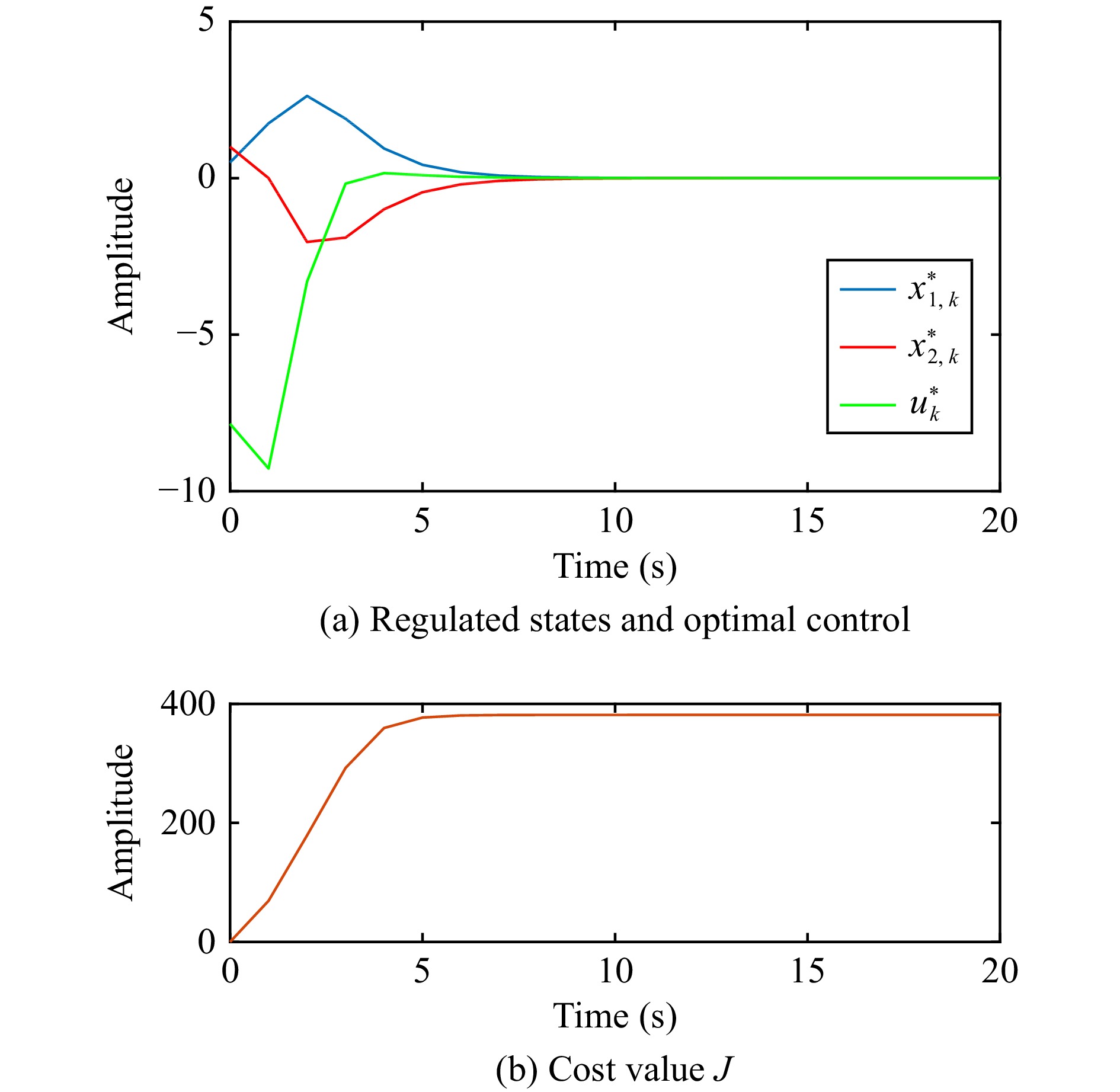
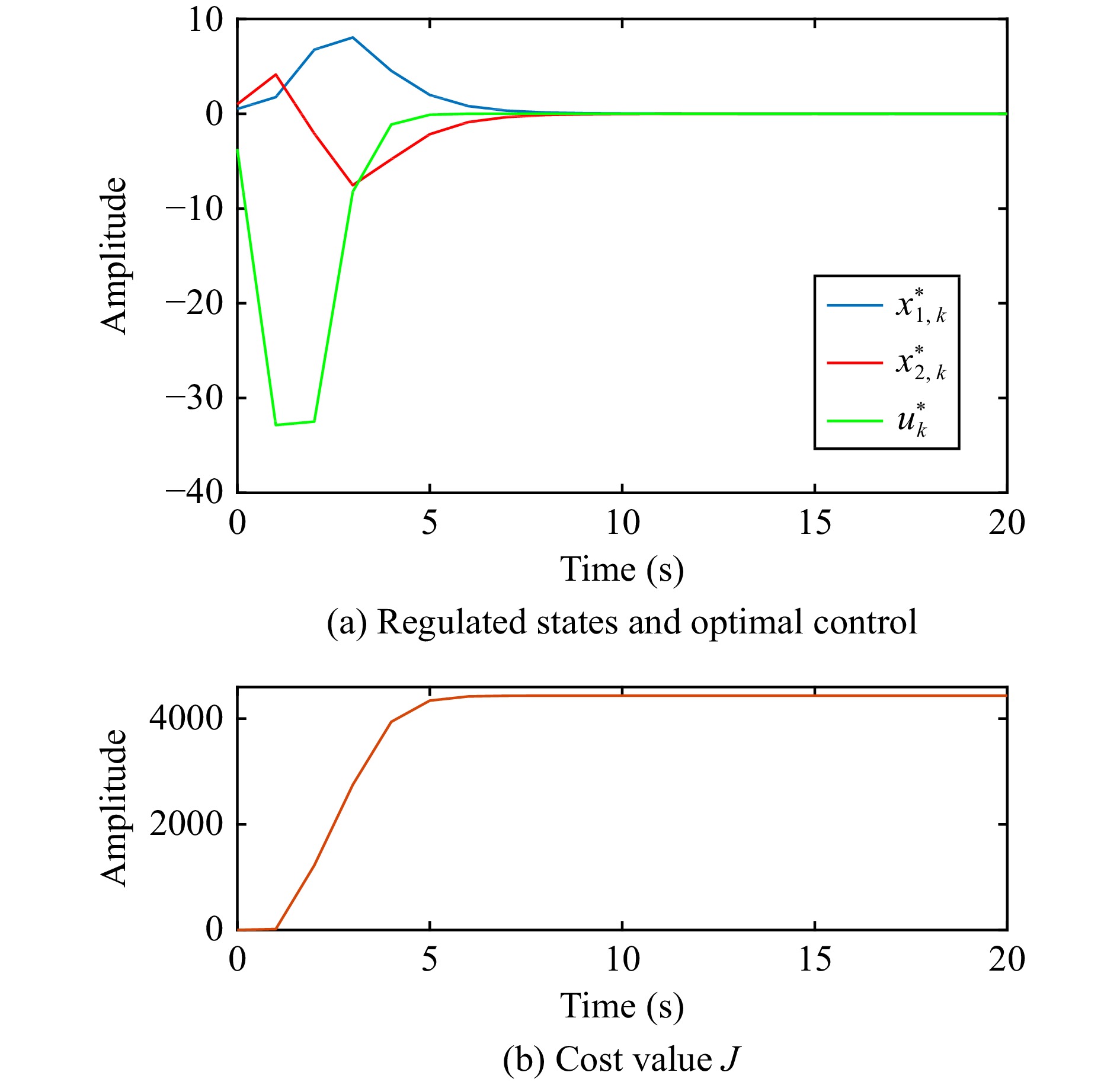
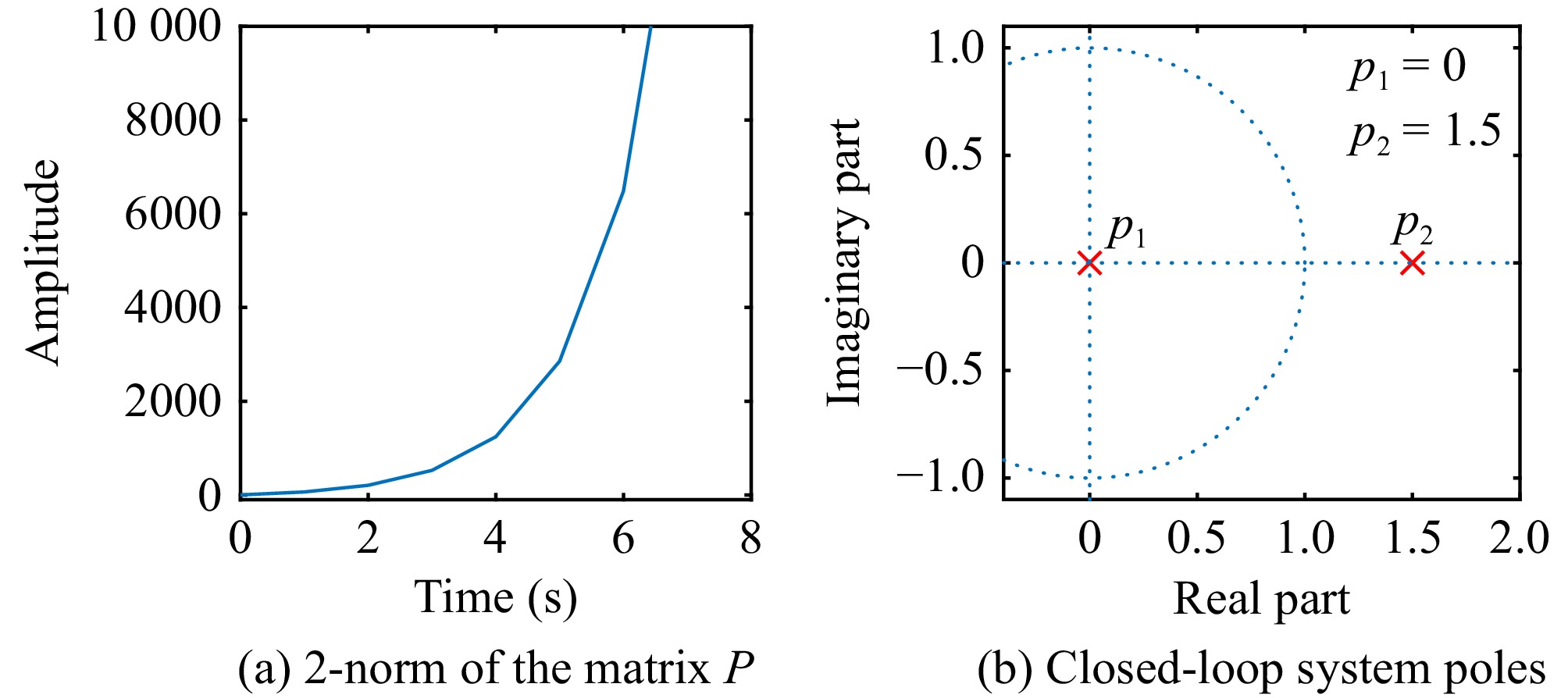
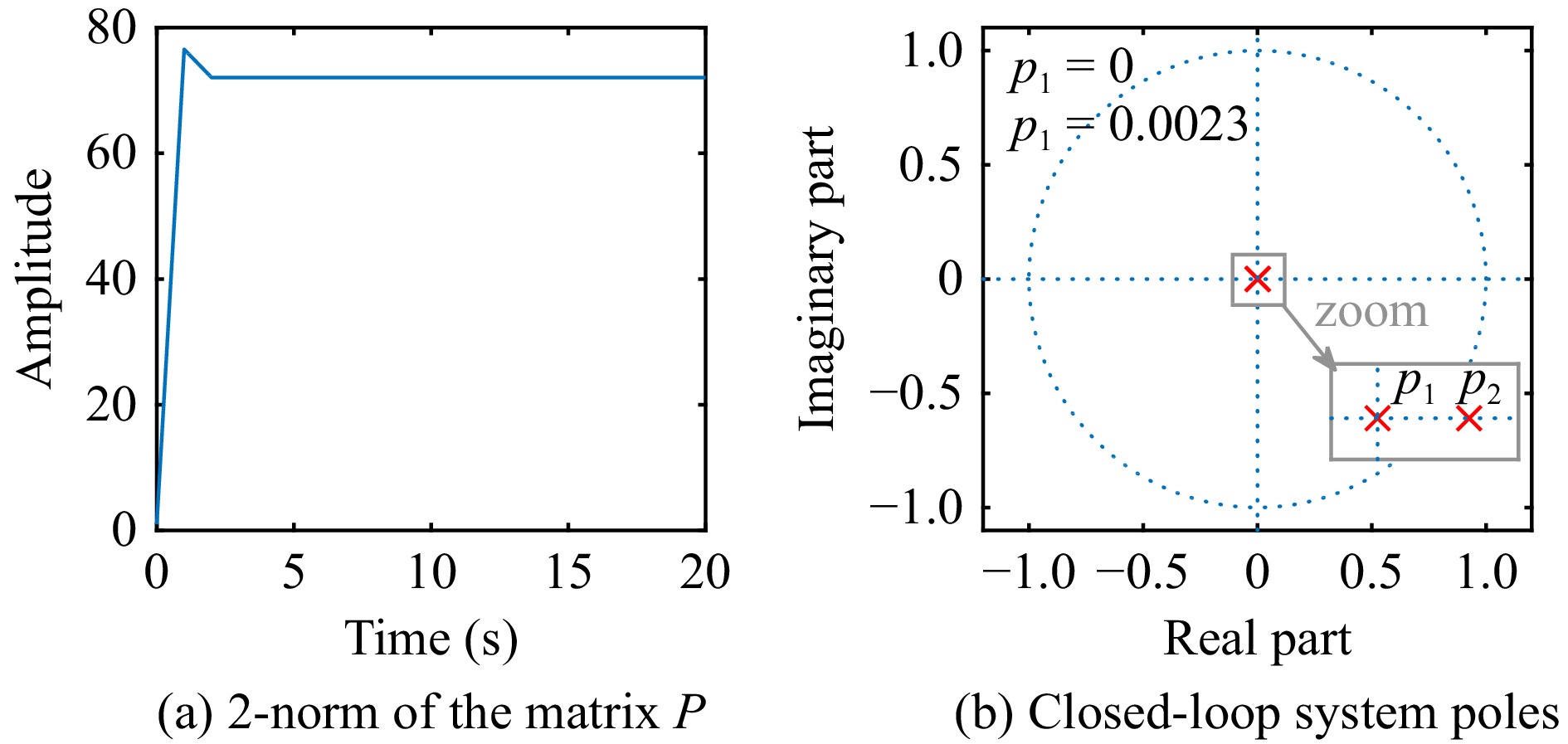
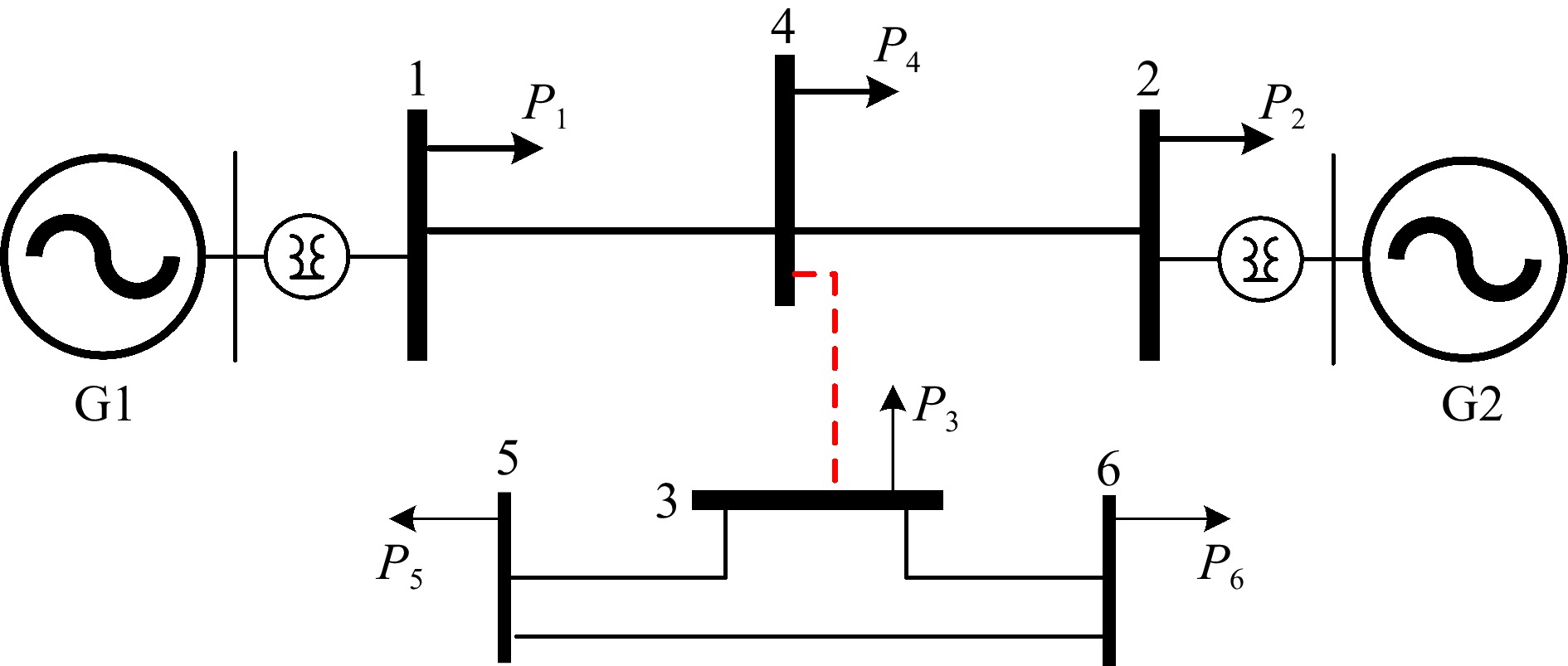
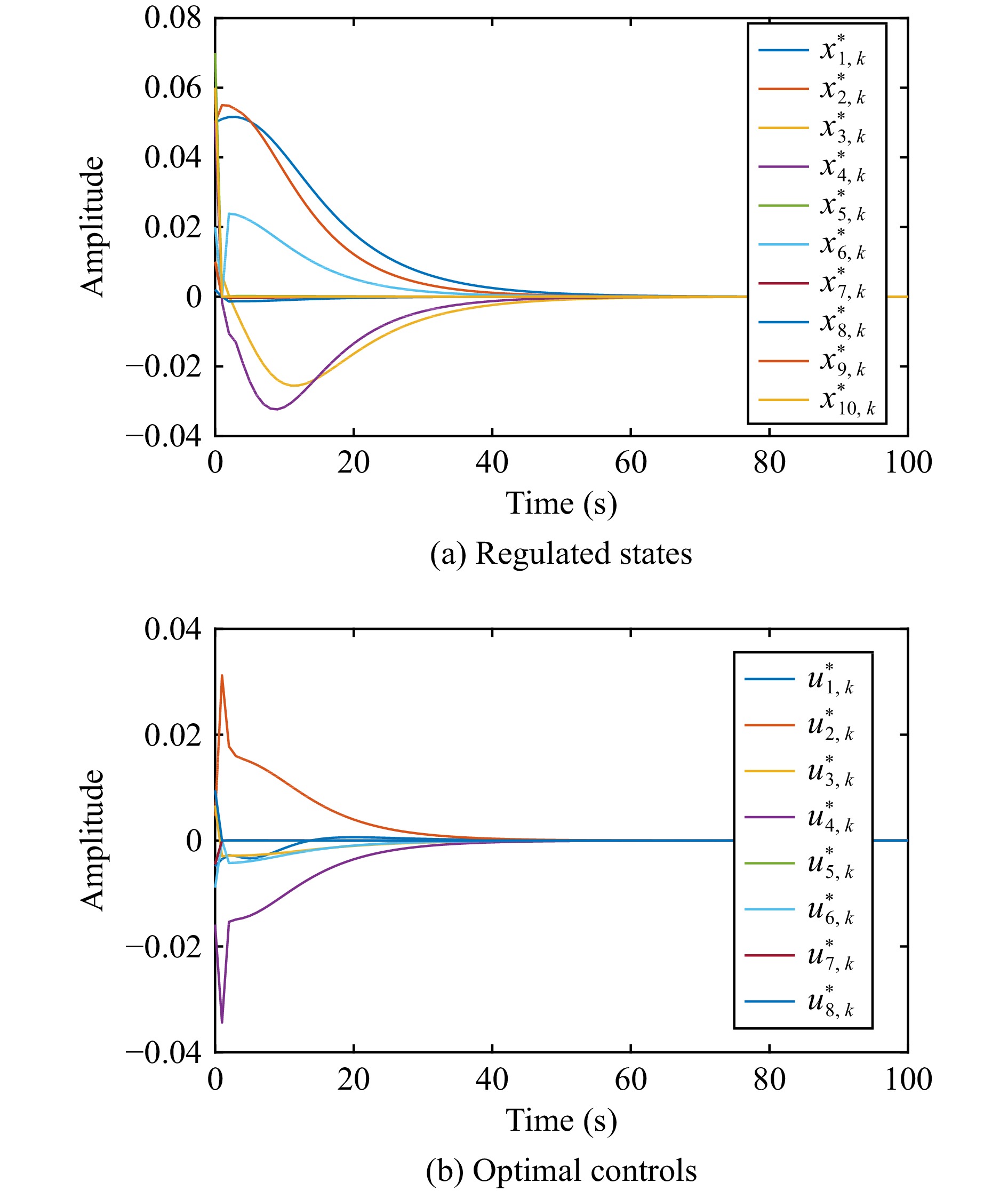
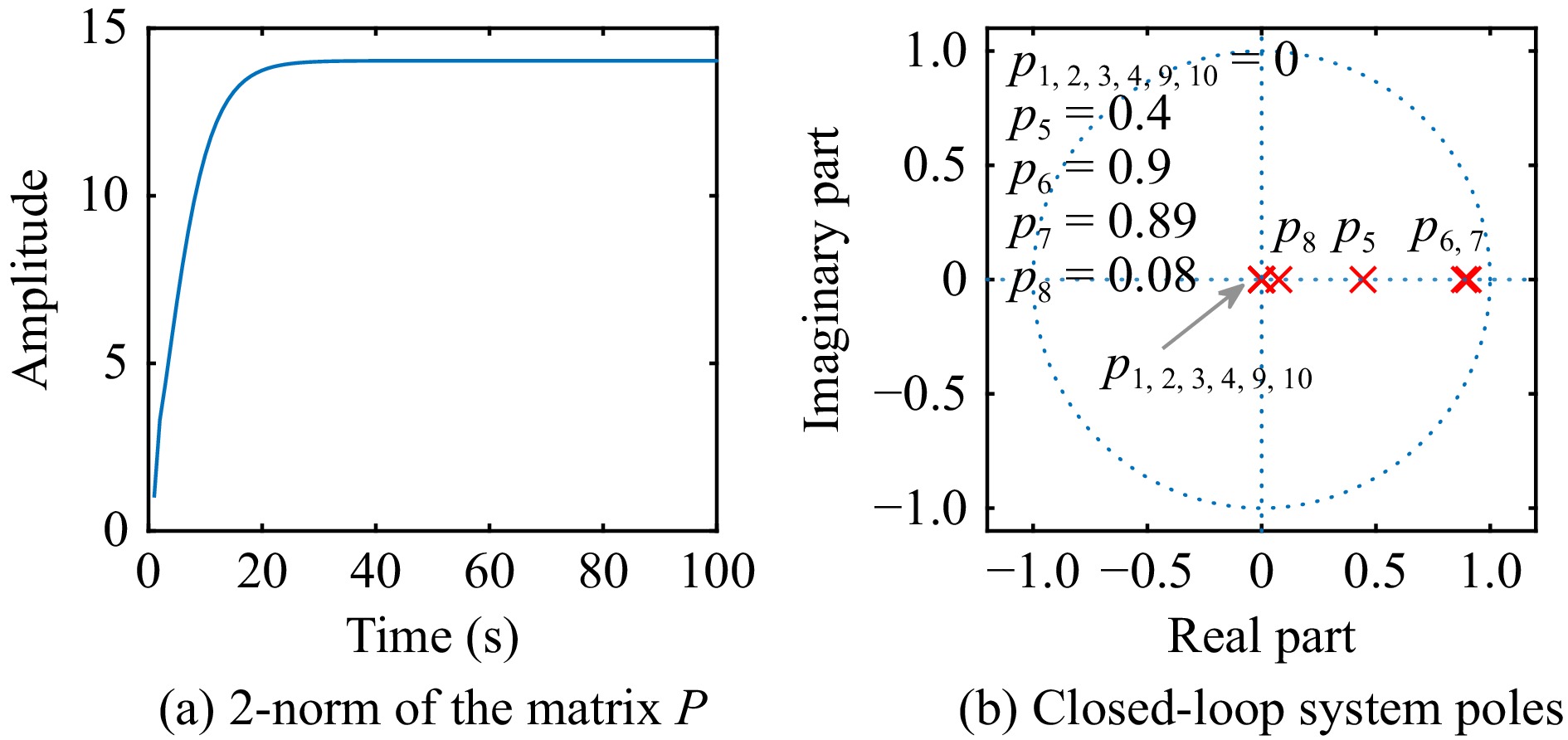
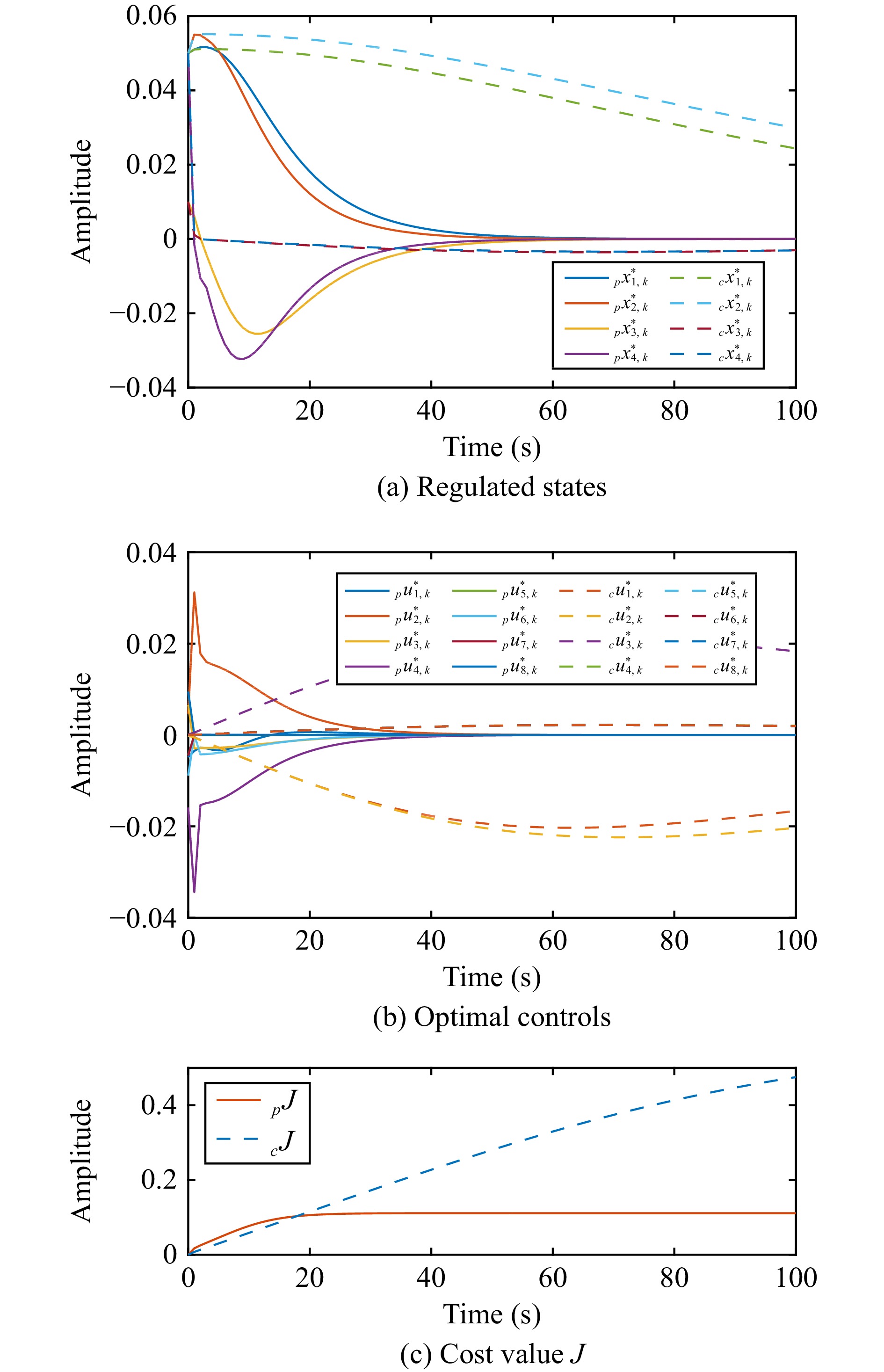
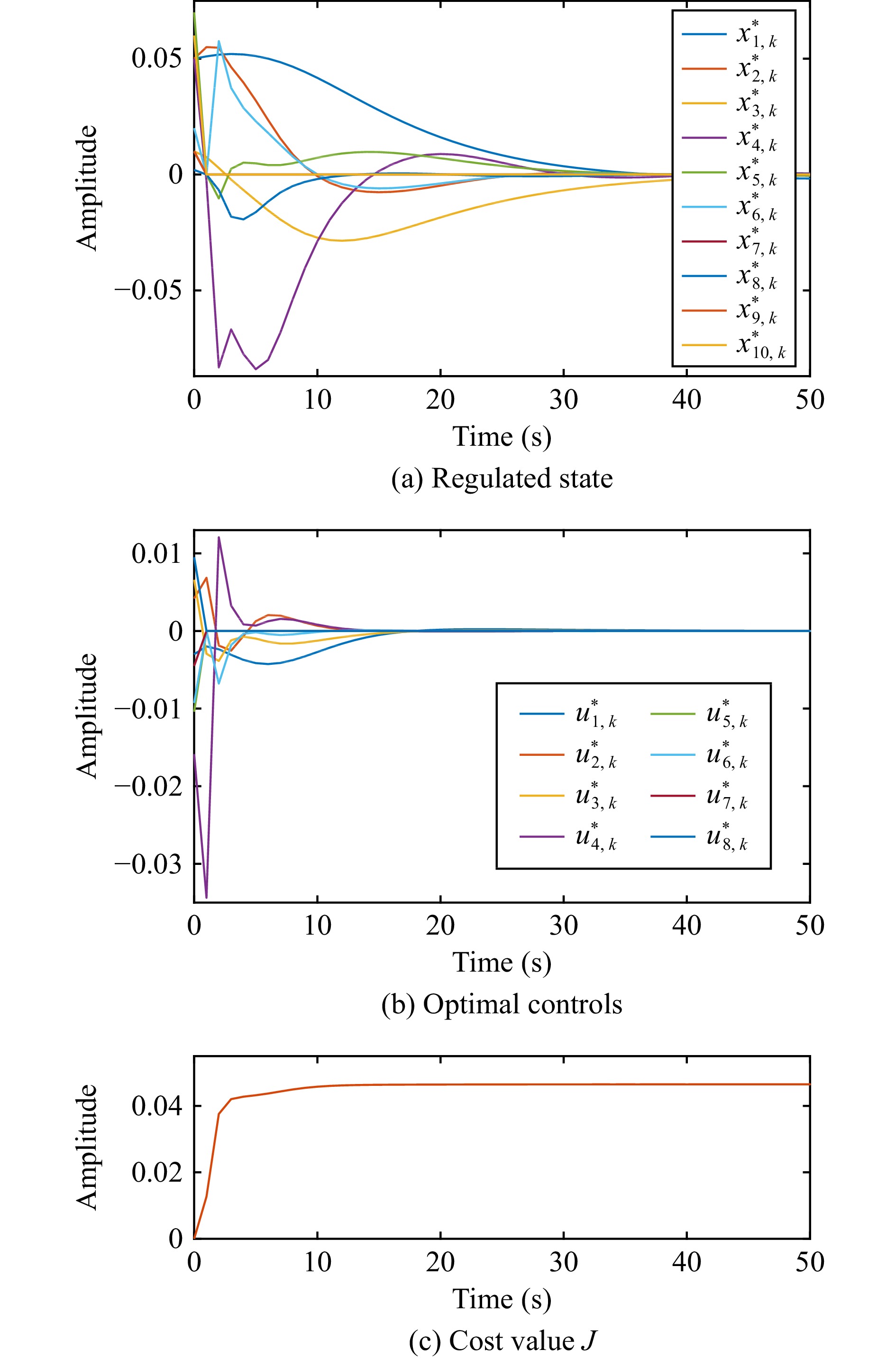
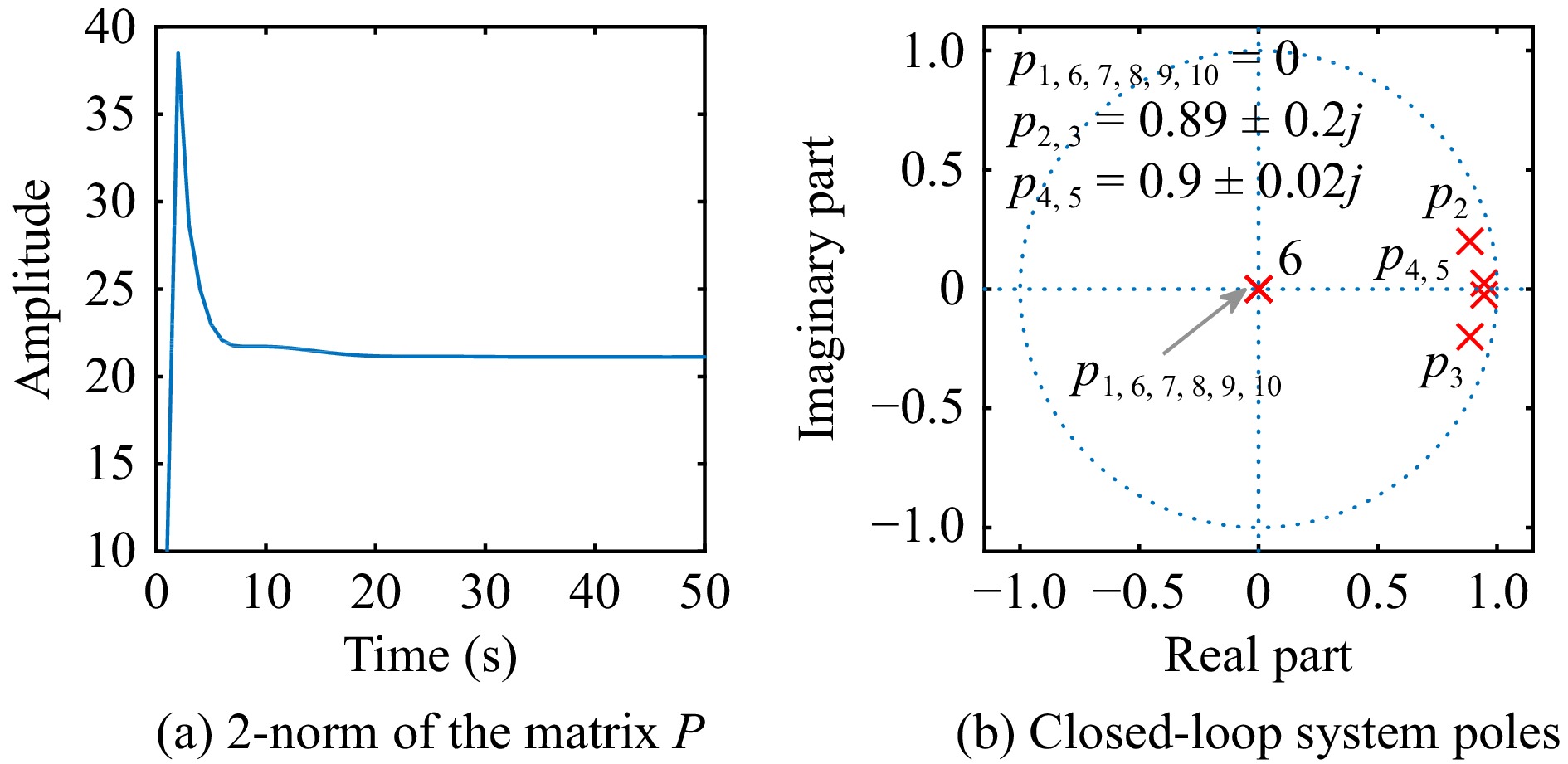
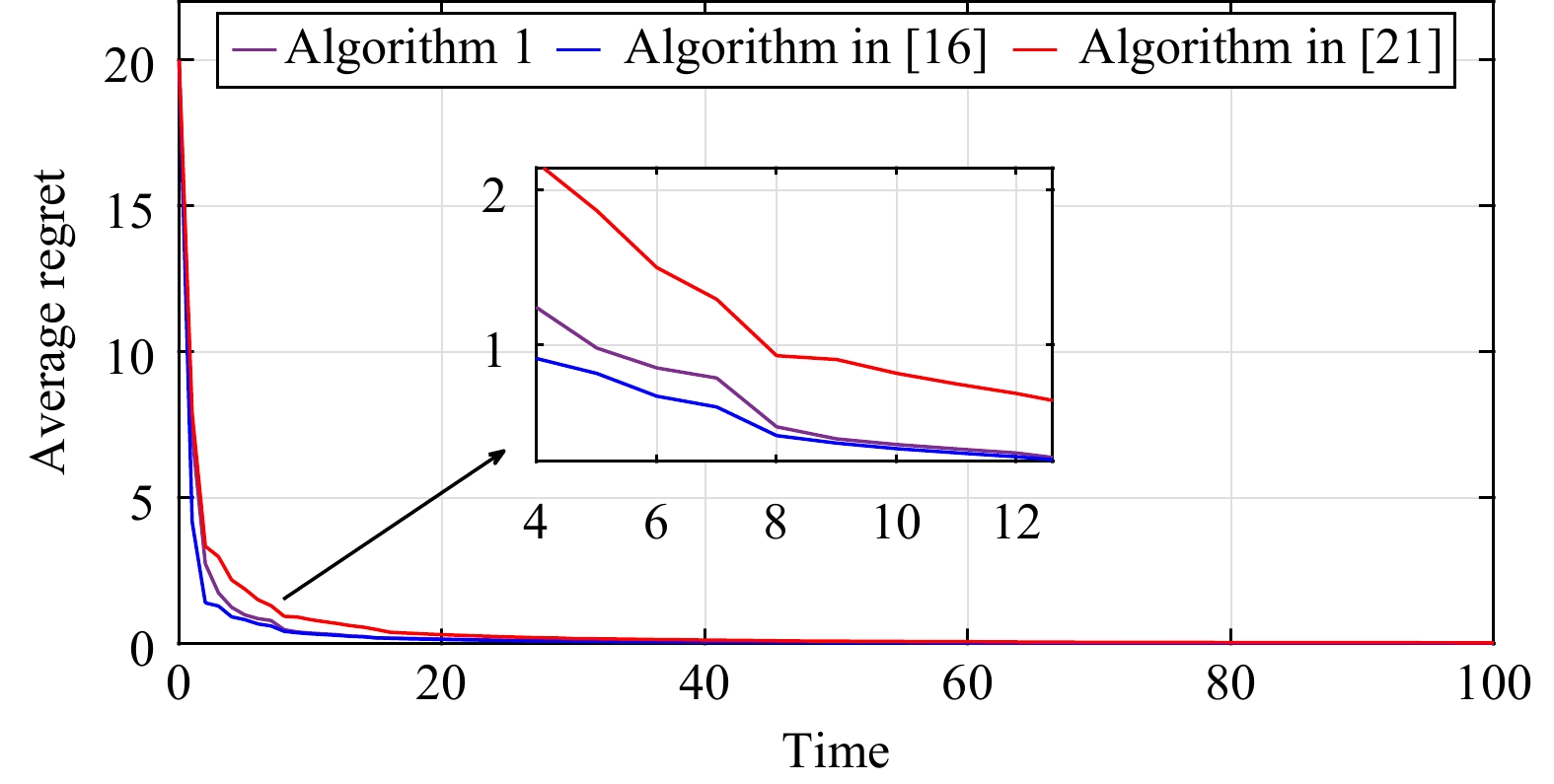
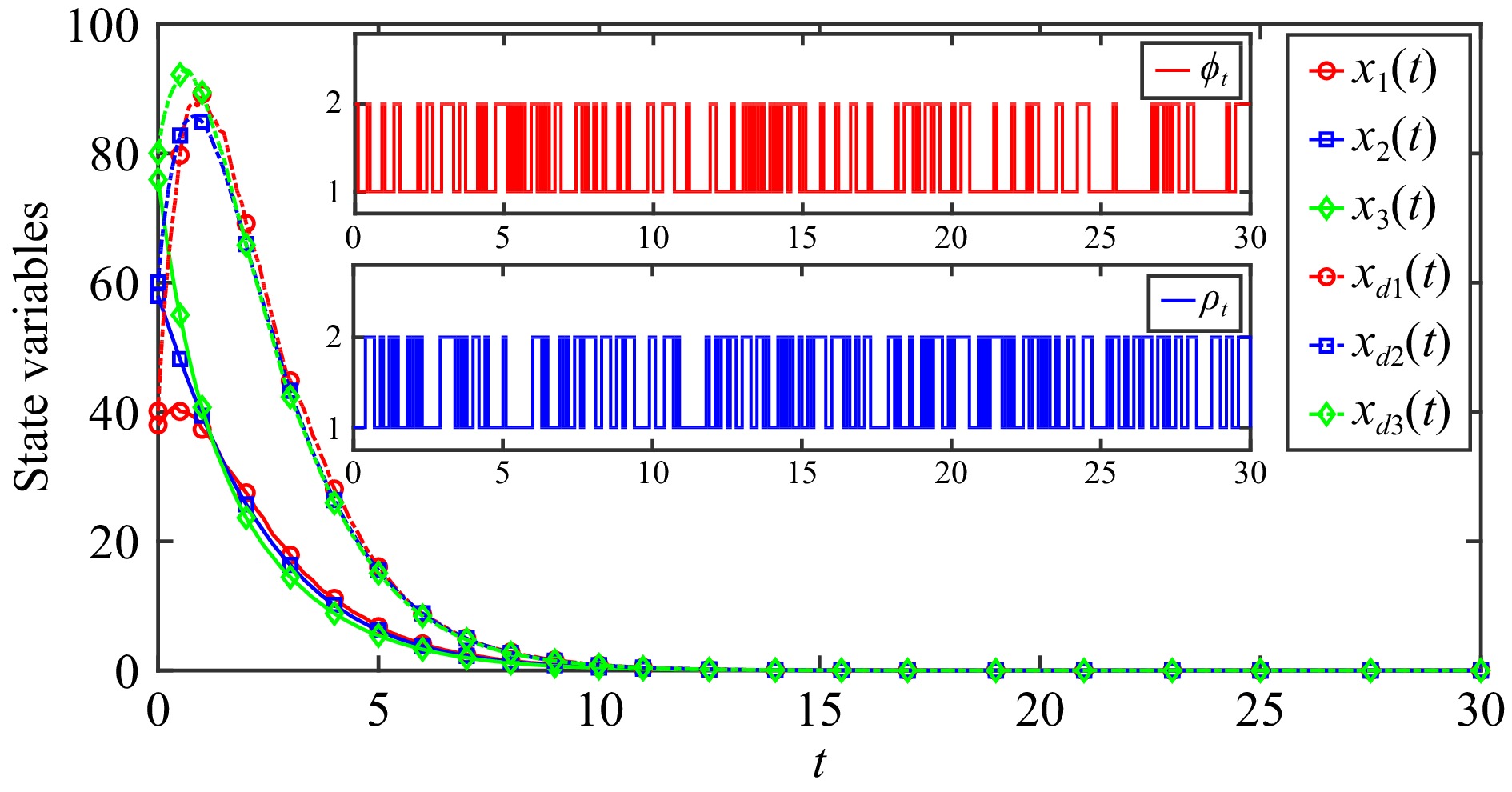
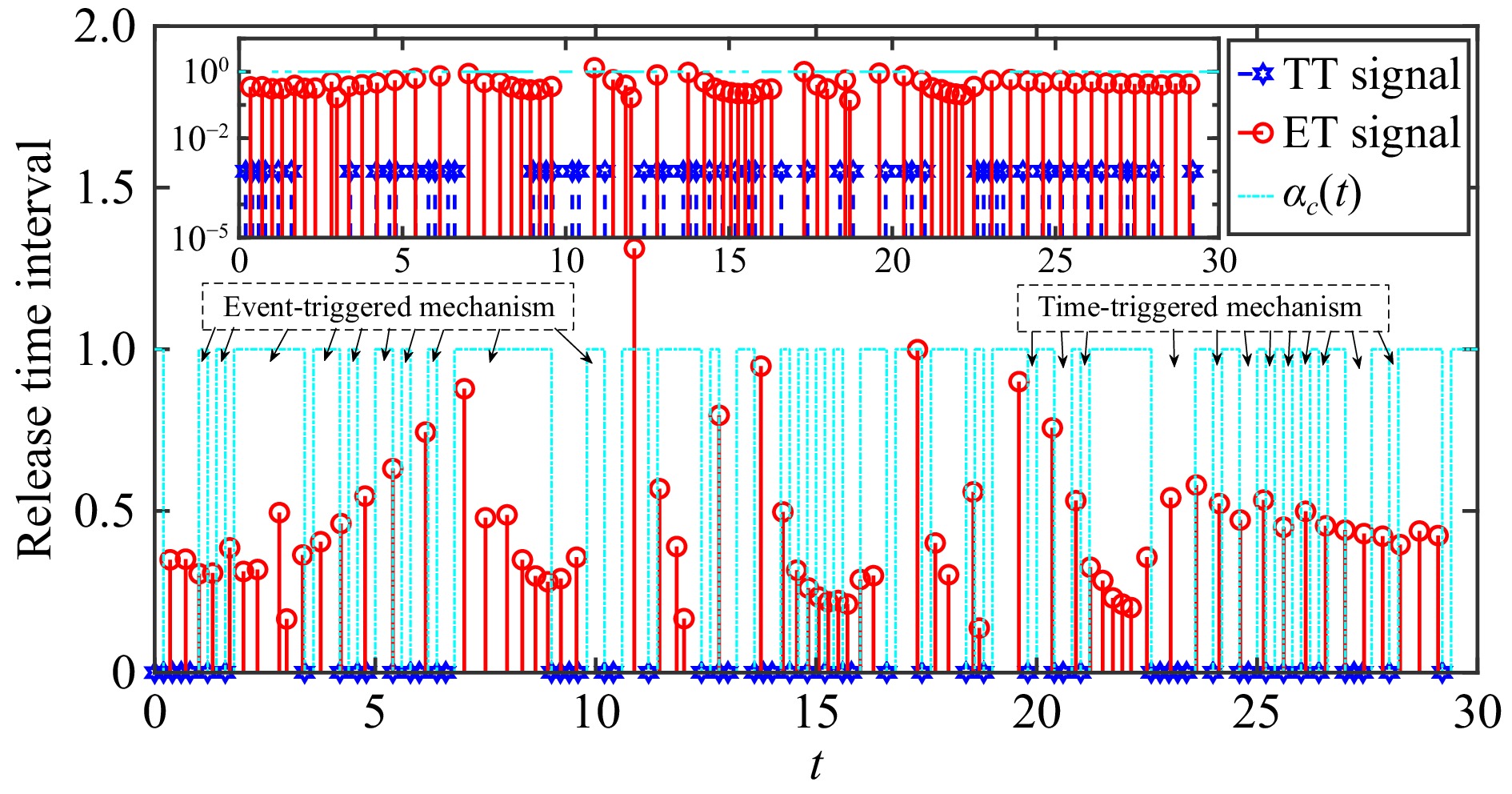
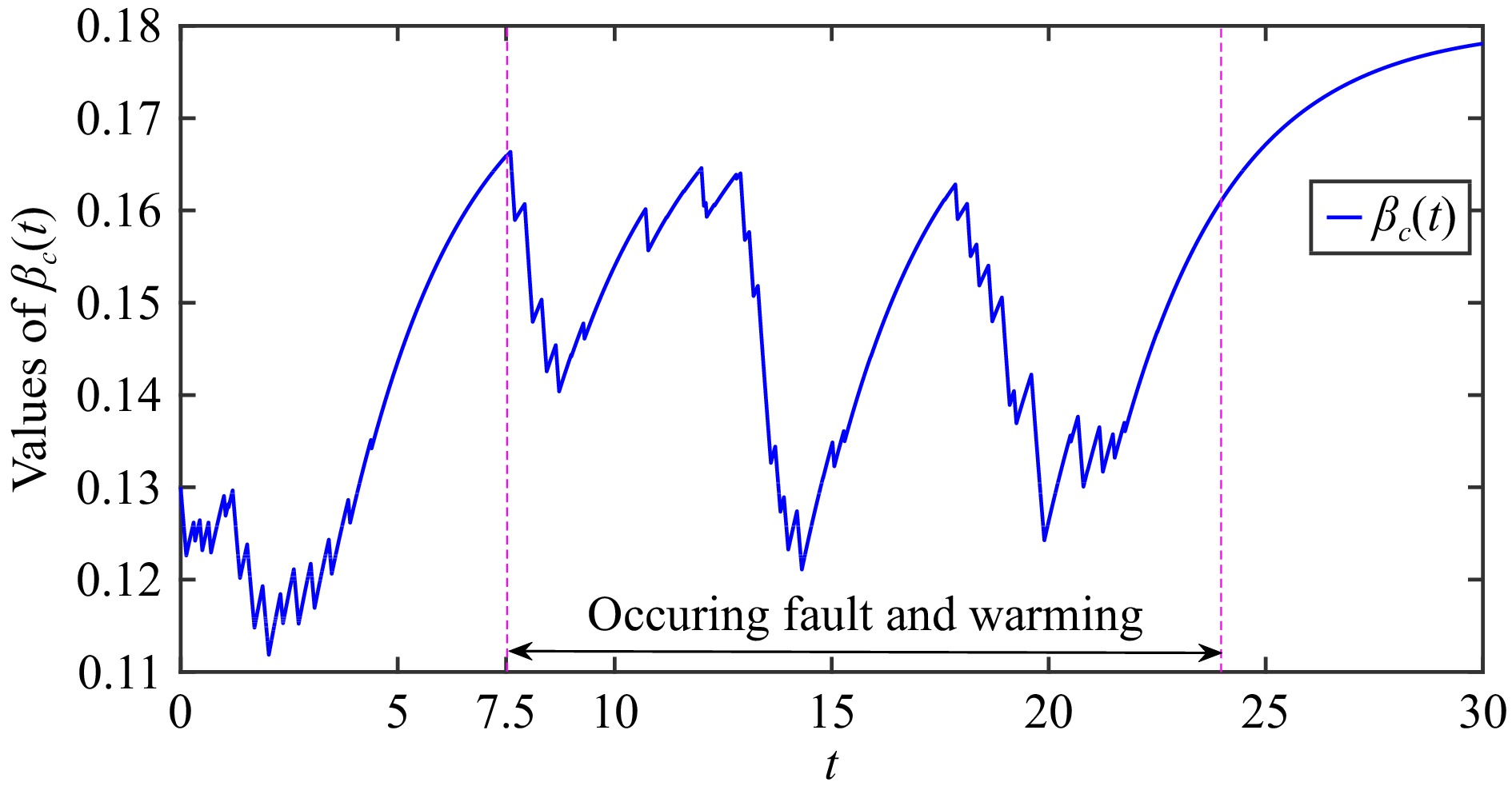
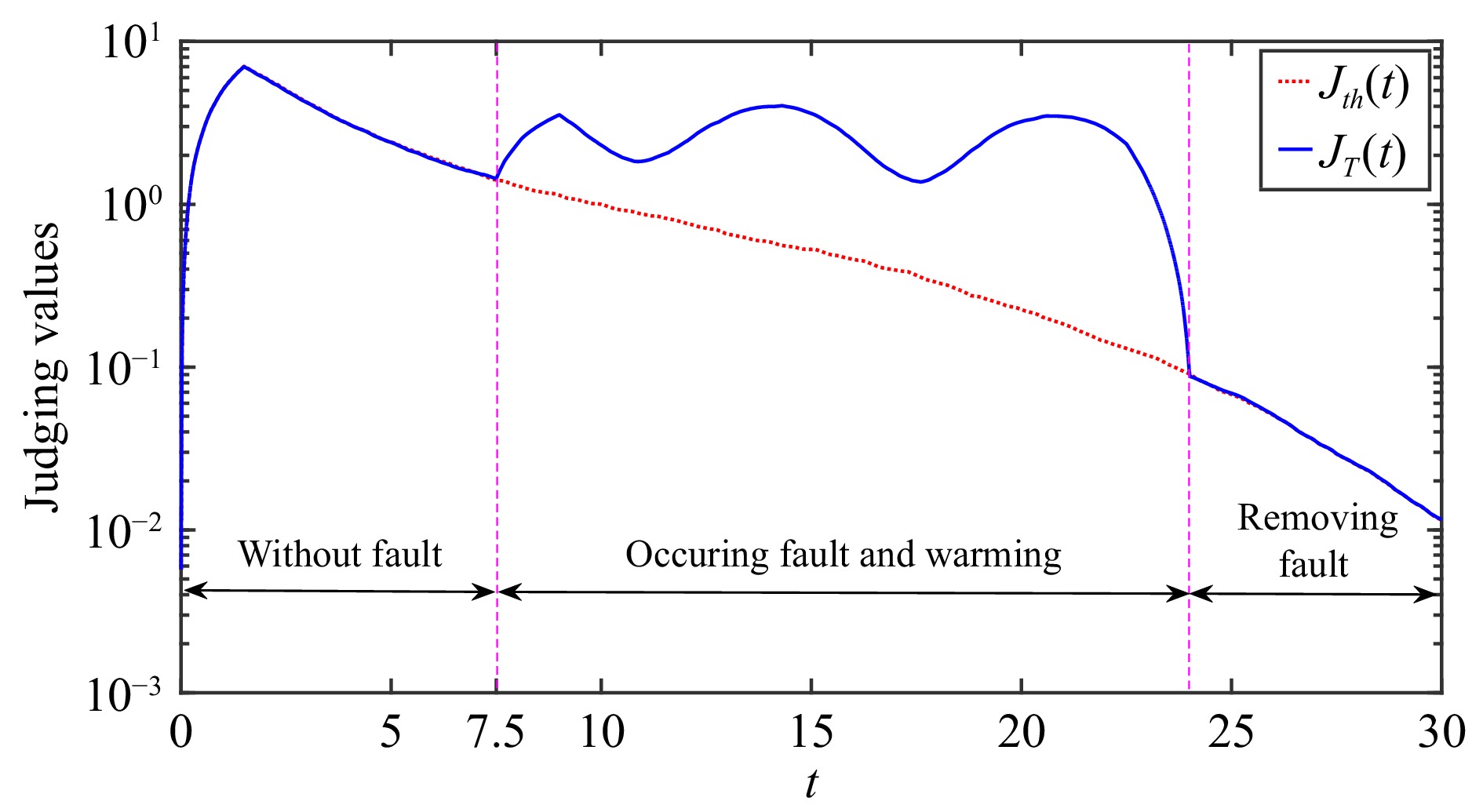
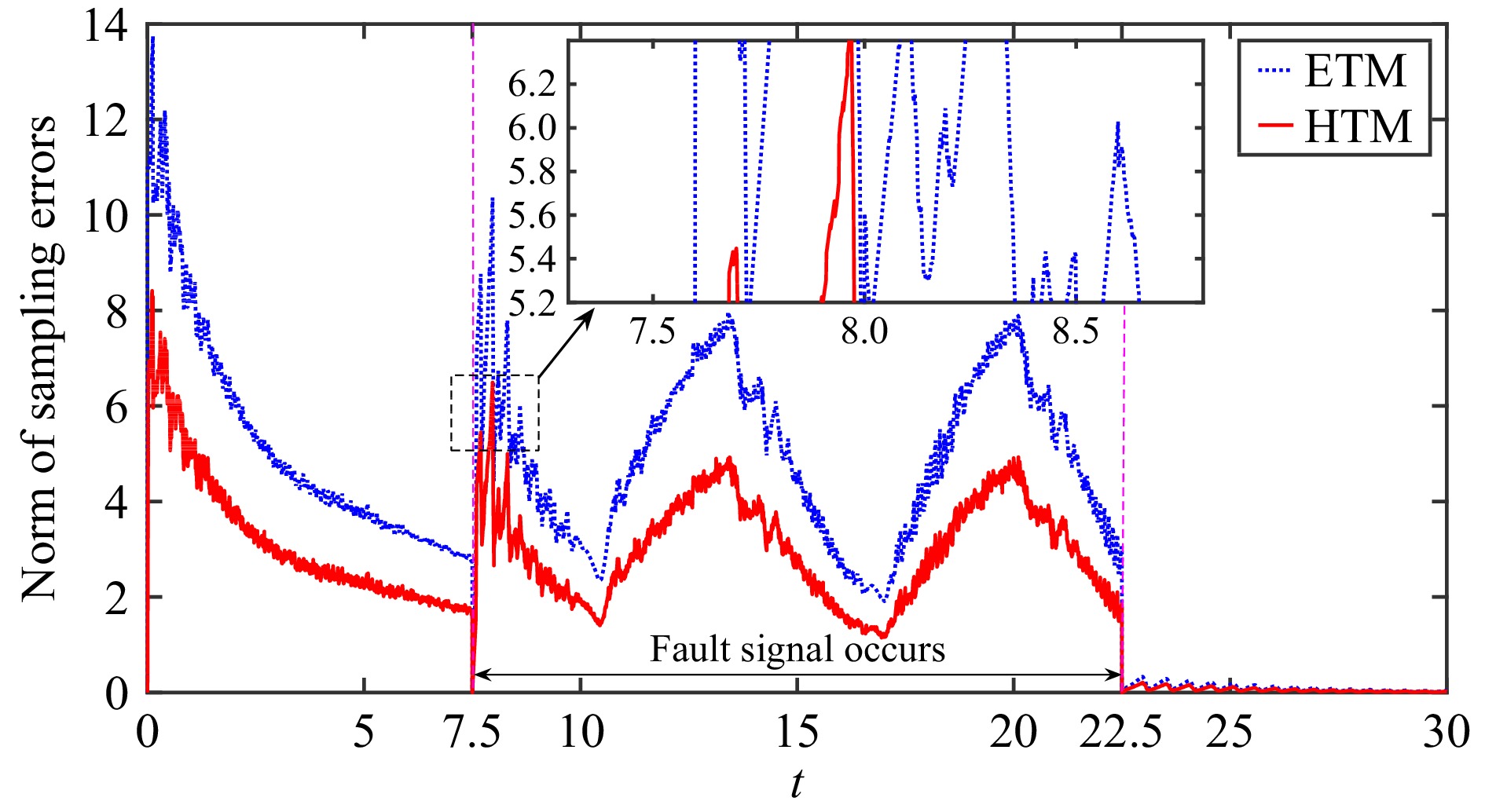
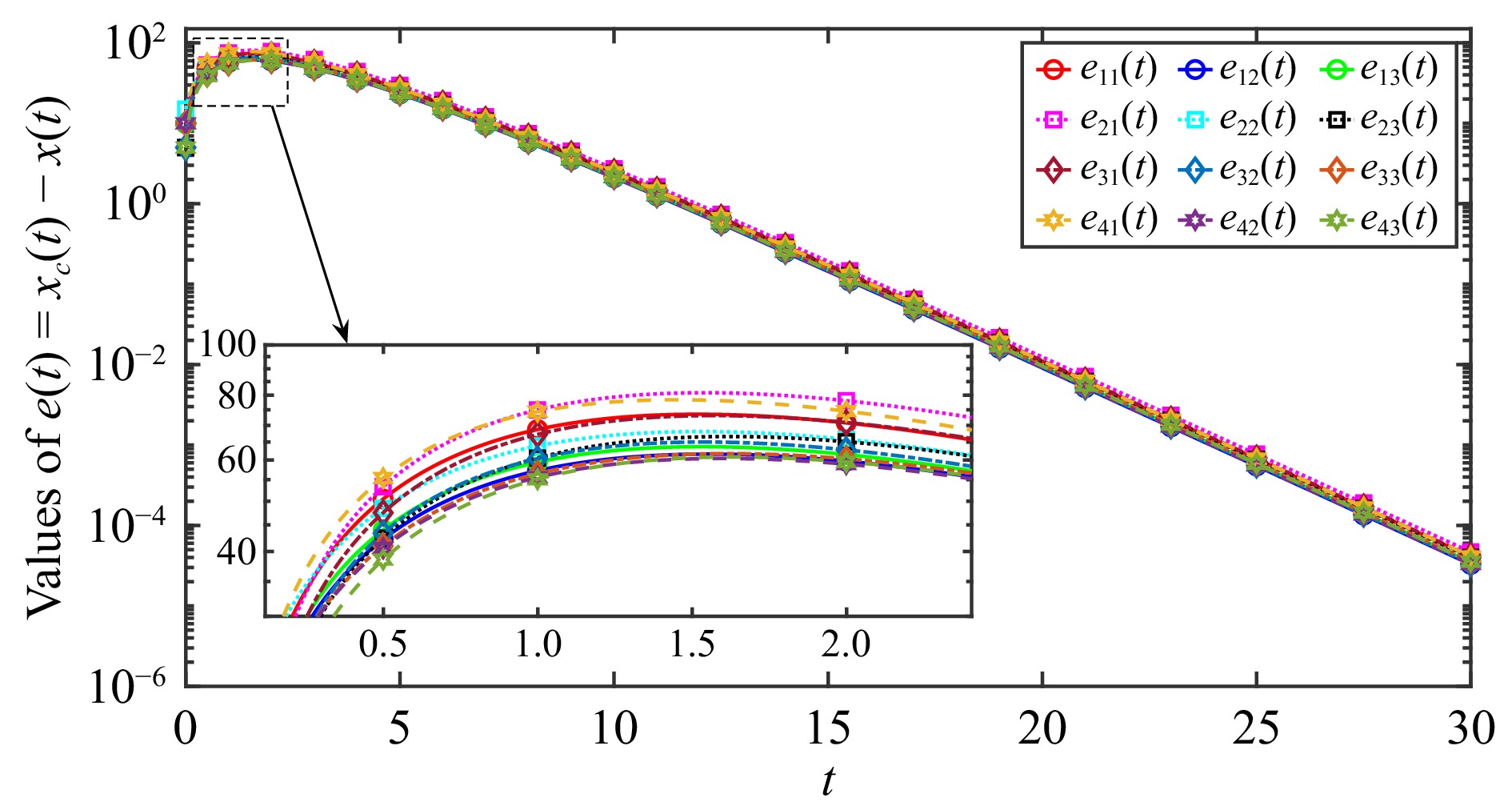
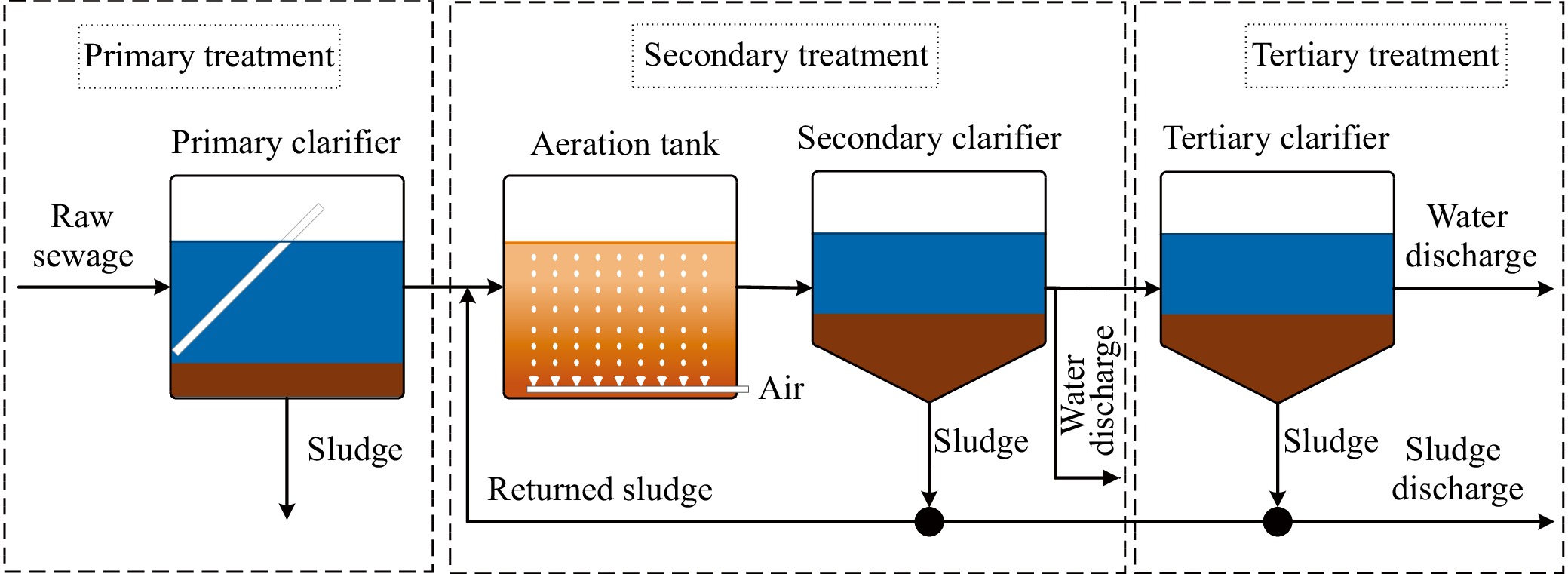
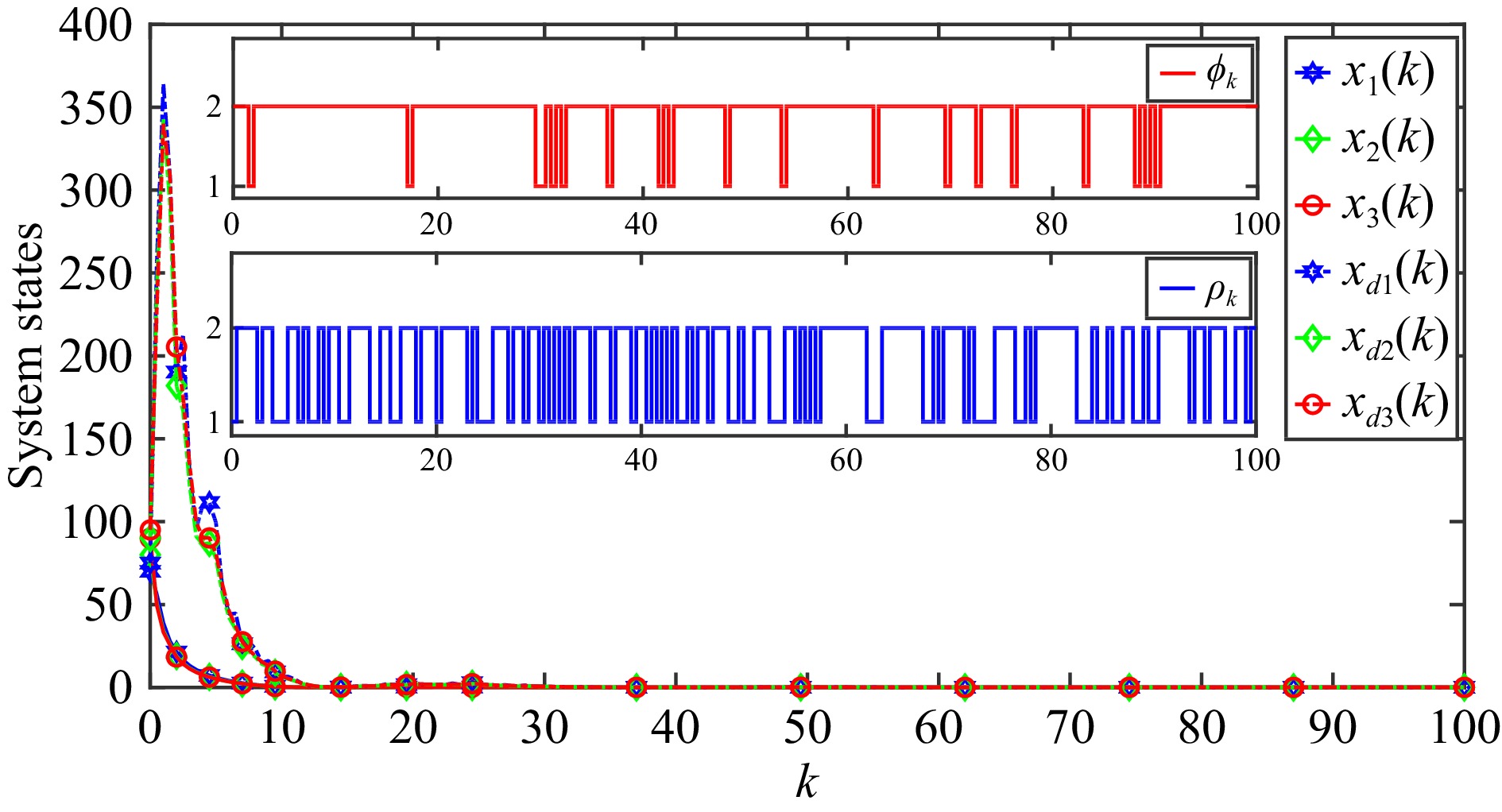
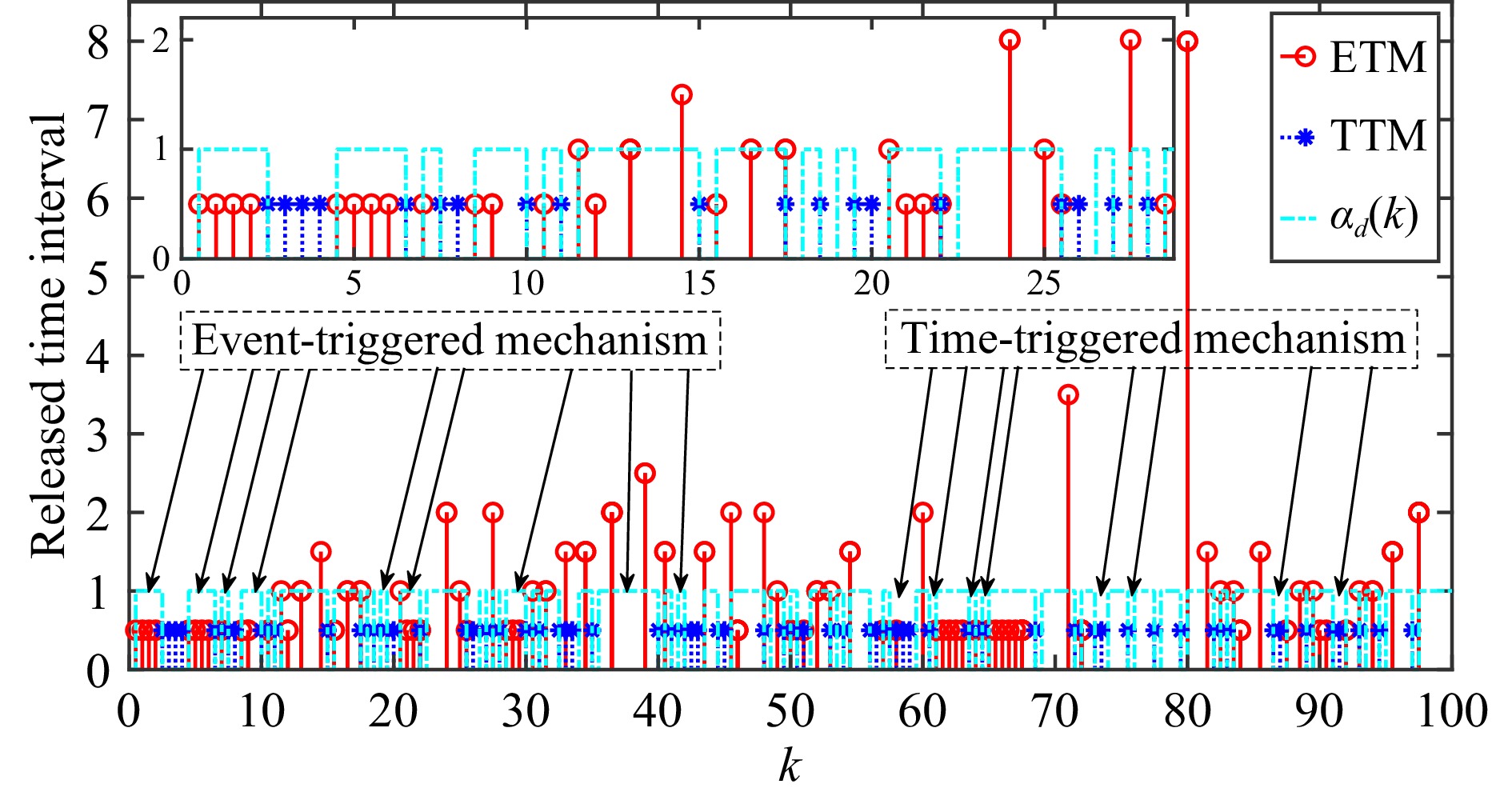
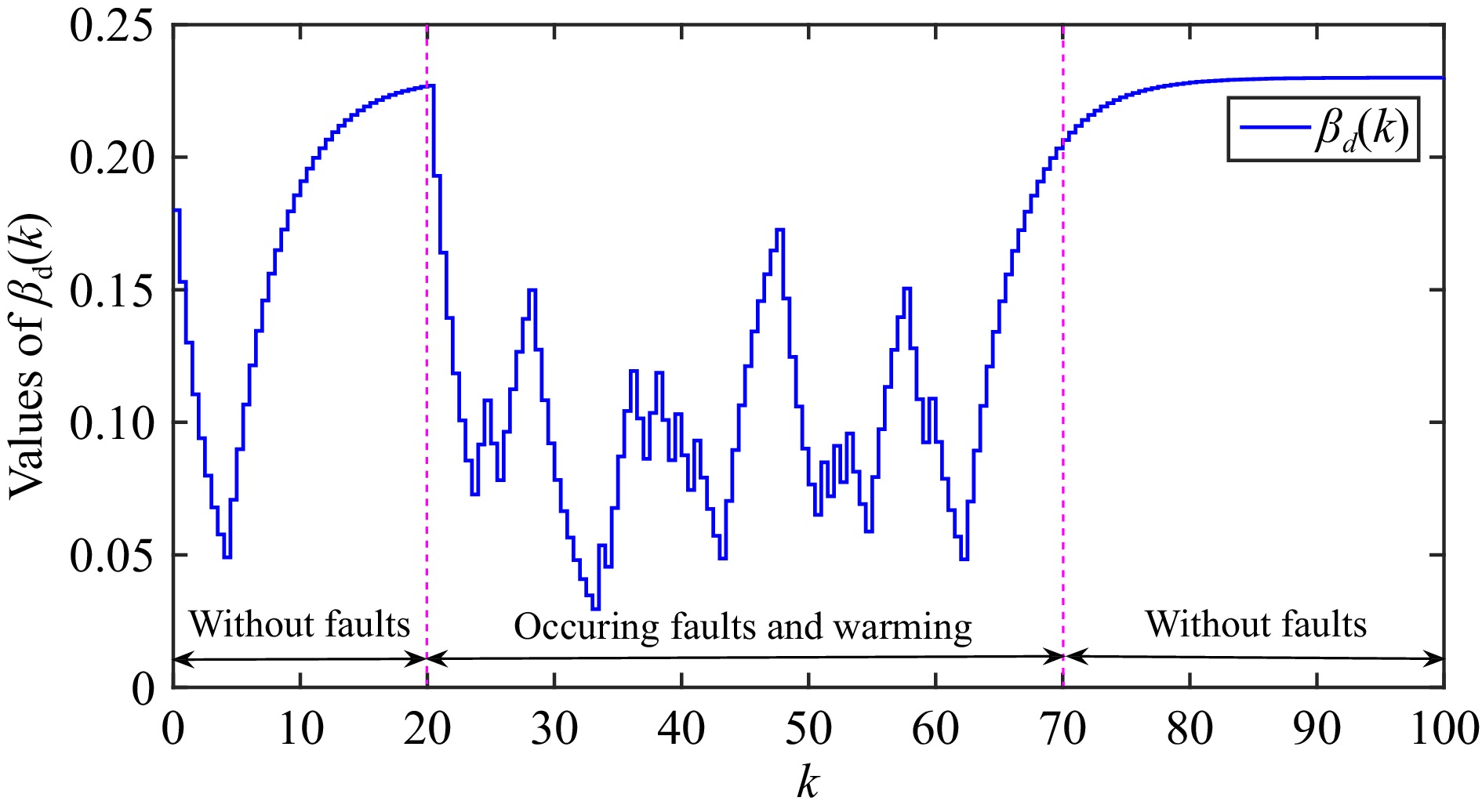
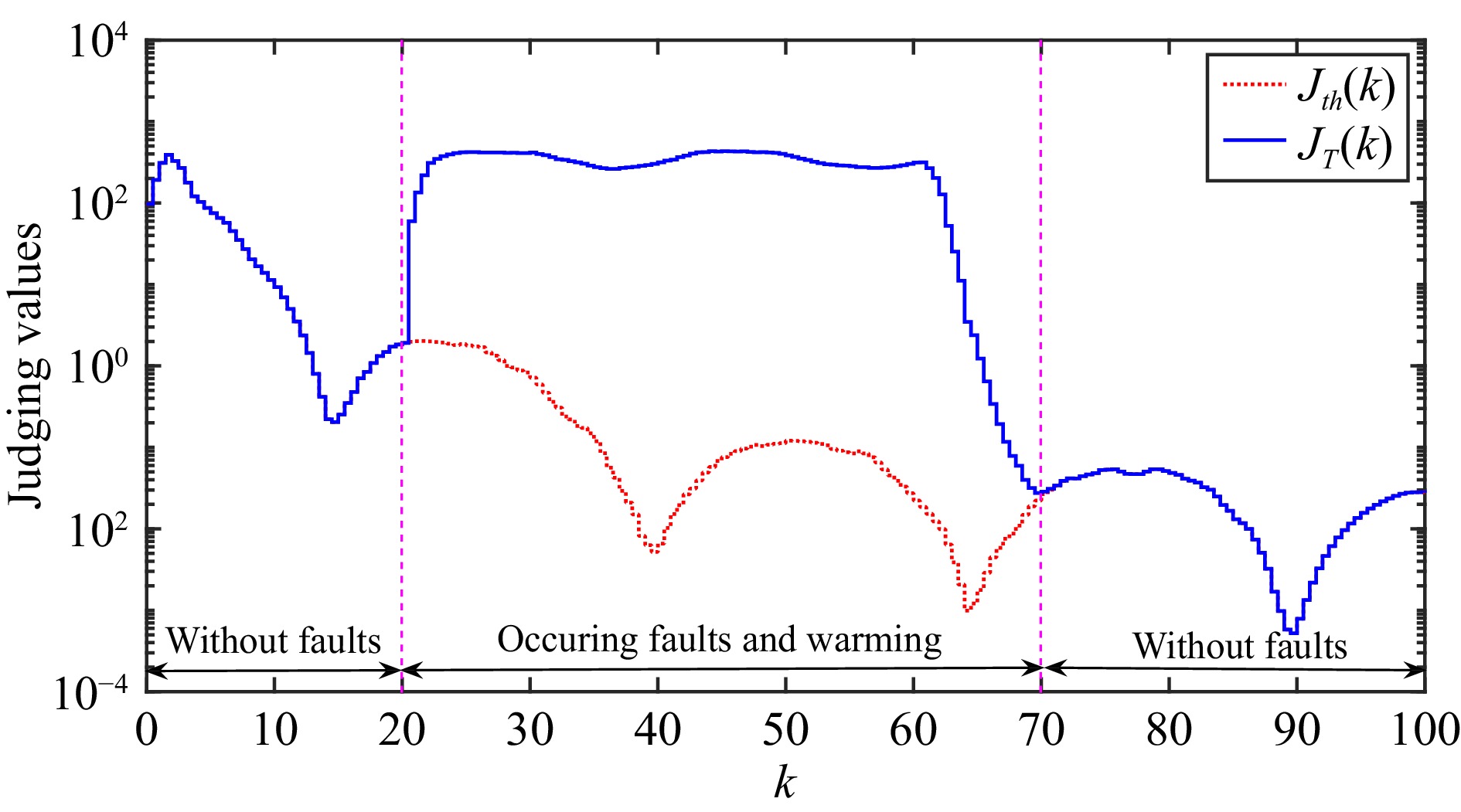
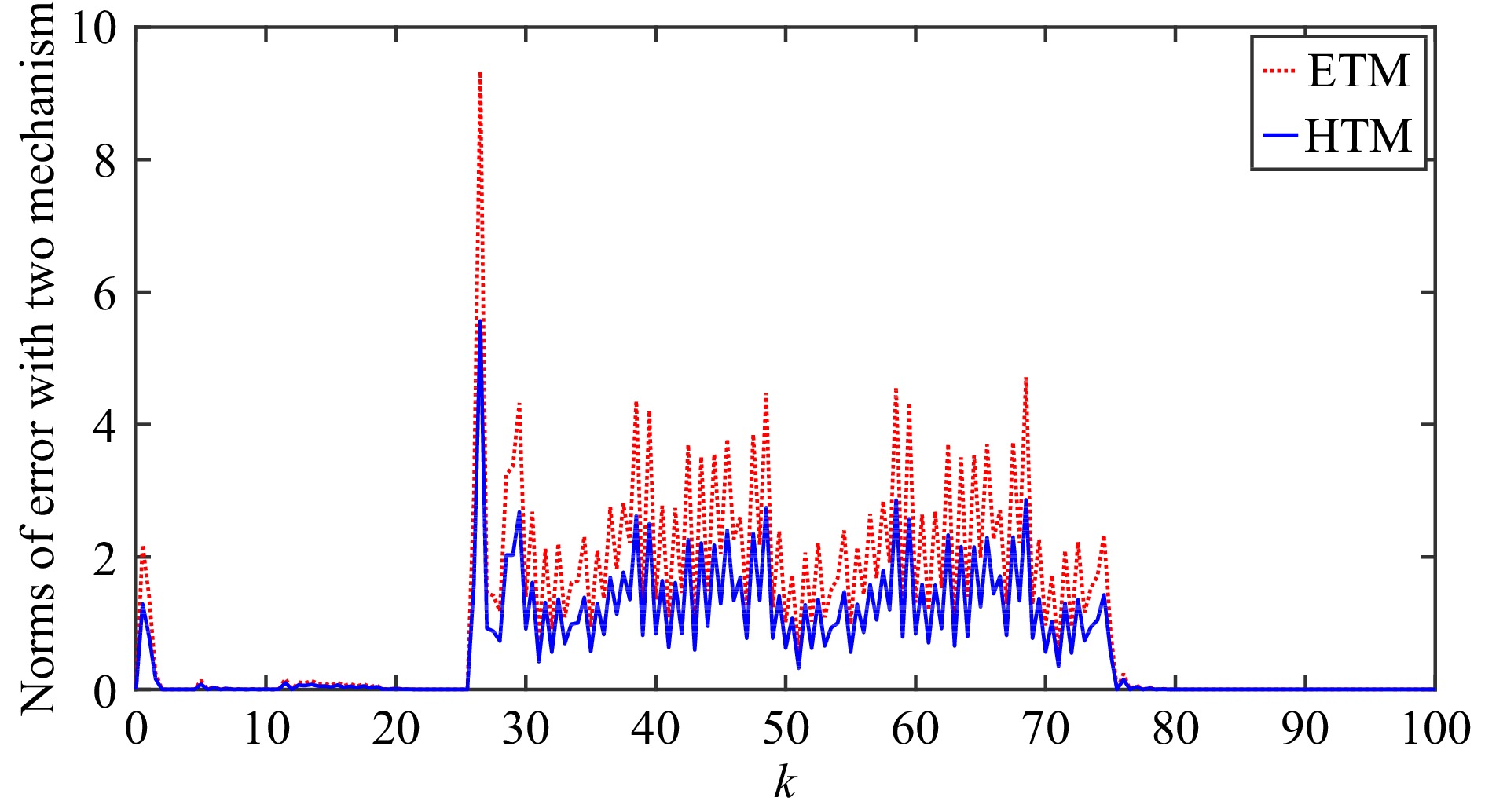
This paper is concerned with the double sensitive fault detection filter for positive Markovian jump systems. A new hybrid adaptive event-triggered mechanism is proposed by introducing a non-monotonic adaptive law. A linear adaptive event-triggered threshold is established by virtue of 1-norm inequality. Under such a triggering strategy, the original system can be transformed into an interval uncertain system. By using a stochastic copositive Lyapunov function, an asynchronous fault detection filter is designed for positive Markovian jump systems (PMJSs) in terms of linear programming. The presented filter satisfies both $ L_{-} $-gain ($ \ell_{-} $-gain) fault sensitivity and $ L_{1} $ ($ \ell_{1} $) internal differential privacy sensitivity. The proposed approach is also extended to the discrete-time case. Finally, two examples are provided to illustrate the effectiveness of the proposed design.
J. Zhang, B. Du, S. Zhang, and S. Ding, “A double sensitive fault detection filter for positive Markovian jump systems with a hybrid event-triggered mechanism,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 11, pp. 2298–2315, Nov. 2024. doi: 10.1109/JAS.2024.124677.












 E-mail Alert
E-mail Alert


