A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation

IEEE/CAA Journal of Automatica Sinica
| Citation: | Y. Li, S. Teng, Z. Wu, J. Wang, M. Liu, Z. Xuanyuan, and L. Chen, “Datasets, metrics, benchmarks and future research in autonomous driving: A review,” IEEE/CAA J. Autom. Sinica, early access, 2026. doi: 10.1109/JAS.2025.125957

|

| [1] |
L. Chen, Y. Li, C. Huang, B. Li, Y. Xing, D. Tian, et al, “Milestones in autonomous driving and intelligent vehicles: Survey of surveys,” IEEE Trans. Intell. Veh., vol. 8, no. 2, pp. 1046–1056, Feb. 2023. doi: 10.1109/TIV.2022.3223131
|
| [2] |
L. Chen, Y. Li, C. Huang, Y. Xing, D. Tian, L. Li, et al, “Milestones in autonomous driving and intelligent vehicles-part I: Control, computing system design, communication, HD map, testing, and human behaviors,” IEEE Trans. Syst., Man, Cybern.: Syst., vol. 53, no. 9, pp. 5831–5847, Sep. 2023. doi: 10.1109/TSMC.2023.3276218
|
| [3] |
L. Chen, S. Teng, B. Li, X. Na, Y. Li, Z. Li, J. Wang, D. Cao, N. Zheng, and F.-Y. Wang, “Milestones in autonomous driving and intelligent vehicles-part II: Perception and planning,” IEEE Trans. Syst., Man, Cybern.: Syst., vol. 53, no. 10, pp. 6401–6415, Oct. 2023. doi: 10.1109/TSMC.2023.3283021
|
| [4] |
P. Dollar, C. Wojek, B. Schiele, and P. Perona, “Pedestrian detection: A benchmark,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Miami, USA, 2009, pp. 304−311.
|
| [5] |
A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? The KITTI vision benchmark suite,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Providence, USA, 2012, pp. 3354−3361.
|
| [6] |
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V. Patnaik, P. Tsui, et al, “Scalability in perception for autonomous driving: Waymo open dataset,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2020, pp. 2443−2451.
|
| [7] |
H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuScenes: A multimodal dataset for autonomous driving,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2020, pp. 11618−11628.
|
| [8] |
W. Maddern, G. Pascoe, C. Linegar, and P. Newman, “1 year, 1000 km: The oxford RobotCar dataset,” Int. J. Rob. Res., vol. 36, no. 1, pp. 3–15, Jan. 2017. doi: 10.1177/0278364916679498
|
| [9] |
Q.-H. Pham, P. Sevestre, R. S. Pahwa, H. Zhan, C. H. Pang, Y. Chen, A. Mustafa, V. Chandrasekhar, and J. Lin, “A*3D dataset: Towards autonomous driving in challenging environments,” in Proc. IEEE Int. Conf. Robotics and Autom., Paris, France, 2020, pp. 2267−2273.
|
| [10] |
J. Geyer, Y. Kassahun, M. Mahmudi, X. Ricou, R. Durgesh, A. S. Chung, et al, “A2D2: Audi autonomous driving dataset,” arXiv preprint arXiv: 2004.06320, 2020.
|
| [11] |
M.-F. Chang, J. Lambert, P. Sangkloy, J. Singh, S. Bak, A. Hartnett, et al, “Argoverse: 3D tracking and forecasting with rich maps,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 8740−8749.
|
| [12] |
F. Yu, H. Chen, X. Wang, W. Xian, Y. Chen, F. Liu, V. Madhavan, and T. Darrell, “BDD100K: A diverse driving dataset for heterogeneous multitask learning,” in Proc. Conf. IEEE/CVF Computer Vision and Pattern Recognition, Seattle, USA, 2020, pp. 2633−2642.
|
| [13] |
Z. Che, G. Li, T. Li, B. Jiang, X. Shi, X. Zhang, Y. Lu, G. Wu, Y. Liu, and J. Ye, “D.2-city: A large-scale dashcam video dataset of diverse traffic scenarios,” arXiv preprint arXiv: 1904.01975, 2019.
|
| [14] |
A. Patil, S. Malla, H. Gang, and Y.-T. Chen, “The H3D dataset for full-surround 3D multi-object detection and tracking in crowded urban scenes,” in Proc. IEEE Int. Conf. Robotics and Autom., Montreal, Canada, 2019, pp. 9552−9557.
|
| [15] |
J. Mao, M. Niu, C. Jiang, H. Liang, J. Chen, X. Liang, et al, “One million scenes for autonomous driving: Once dataset,” in Proc. 35th Conf. Neural Information Processing Systems Track on Datasets and Benchmarks, Montreal, Canada, 2021, pp. 1−13.
|
| [16] |
P. Xiao, Z. Shao, S. Hao, Z. Zhang, X. Chai, J. Jiao, et al, “PandaSet: Advanced sensor suite dataset for autonomous driving,” in Proc. IEEE Int. Intelligent Transportation Systems Conf., Indianapolis, USA, 2021, pp. 3095−3101.
|
| [17] |
M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene understanding,” in Proc. Conf. IEEE/CVF Computer Vision and Pattern Recognition, Las Vegas, USA, 2016, pp. 3213−3223.
|
| [18] |
J. Houston, G. Zuidhof, L. Bergamini, Y. Ye, L. Chen, A. Jain, S. Omari, V. Iglovikov, and P. Ondruska, “One thousand and one hours: Self-driving motion prediction dataset,” in Proc. Conf. Robot Learning, Cambridge, MA, USA, 2021, pp. 409−418.
|
| [19] |
J. Xue, J. Fang, T. Li, B. Zhang, P. Zhang, Z. Ye, and J. Dou, “BLVD: Building a large-scale 5D semantics benchmark for autonomous driving,” in Proc. IEEE Int. Conf. Robotics and Autom., Montreal, Canada, 2019, pp. 6685−6691.
|
| [20] |
J. Han, X. Liang, H. Xu, K. Chen, L. Hong, J. Mao, et al, “SODA10M: A large-scale 2D self/semi-supervised object detection dataset for autonomous driving,” in Proc. 35th Conf. Neural Information Processing Systems Track on Datasets and Benchmarks, 2021, pp. 1−13.
|
| [21] |
J. Jeong, Y. Cho, Y.-S. Shin, H. Roh, and A. Kim, “Complex urban LiDAR data set,” in Proc. IEEE Int. Conf. Robotics and Autom., Brisbane, Australia, 2018, pp. 6344−6351.
|
| [22] |
J.-L. Blanco-Claraco, F.-Á. Moreno-Duenas, and J. González-Jiménez, “The Málaga urban dataset: High-rate stereo and lidar in a realistic urban scenario,” Int. J. Rob. Res., vol. 33, no. 2, pp. 207–214, Feb. 2014. doi: 10.1177/0278364913507326
|
| [23] |
H. Schafer, E. Santana, A. Haden, and R. Biasini, “A commute in data: The comma2k19 dataset,” arXiv preprint arXiv: 1812.05752, 2018.
|
| [24] |
S. Agarwal, A. Vora, G. Pandey, W. Williams, H. Kourous, and J. McBride, “Ford multi-AV seasonal dataset,” Int. J. Rob. Res., vol. 39, no. 12, pp. 1367–1376, Oct. 2020. doi: 10.1177/0278364920961451
|
| [25] |
Z. Yan, L. Sun, T. Krajník, and Y. Ruichek, “Eu long-term dataset with multiple sensors for autonomous driving,” in Proc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems, Las Vegas, USA, 2020, pp. 10697−10704.
|
| [26] |
M. Warren, D. McKinnon, H. He, and B. Upcroft, “Unaided stereo vision based pose estimation,” in Proc. Australasian Conf. Robotics and Autom., Brisbane, Australia, 2010, pp. 60−67.
|
| [27] |
N. Carlevaris-Bianco, A. K. Ushani, and R. M. Eustice, “University of michigan north campus long-term vision and LiDAR dataset,” Int. J. Rob. Res., vol. 35, no. 9, pp. 1023–1035, Aug. 2016. doi: 10.1177/0278364915614638
|
| [28] |
S. Workman, R. Souvenir, and N. Jacobs, “Wide-area image geolocalization with aerial reference imagery,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Santiago, Chile, 2015, pp. 3961−3969.
|
| [29] |
T. Sattler, W. Maddern, C. Toft, A. Torii, L. Hammarstrand, E. Stenborg, et al, “Benchmarking 6DOF outdoor visual localization in changing conditions,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018, pp. 8601−8610.
|
| [30] |
T.-Y. Lin, S. Belongie, and J. Hays, “Cross-view image geolocalization,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Portland, USA, 2013, pp. 891−898.
|
| [31] |
S. Workman and N. Jacobs, “On the location dependence of convolutional neural network features,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition Workshops, Boston, USA, 2015, pp. 70−78.
|
| [32] |
L. Liu and H. Li, “Lending orientation to neural networks for cross-view geo-localization,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 5617−5626.
|
| [33] |
N. Sünderhauf, P. Neubert, and P. Protzel, “Are we there yet? Challenging SeqSLAM on a 3000 km journey across all four seasons,” in Proc. IEEE Int. Conf. Robotics and Autom. Workshops, Karlsruhe, Germany, 2013, pp. 1−3.
|
| [34] |
A. Torii, R. Arandjelović, J. Sivic, M. Okutomi, and T. Pajdla, “24/7 place recognition by view synthesis,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Boston, USA, 2015, pp. 1808−1817.
|
| [35] |
A. Torii, J. Sivic, T. Pajdla, and M. Okutomi, “Visual place recognition with repetitive structures,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2013, pp. 883−890.
|
| [36] |
T. Sattler, T. Weyand, B. Leibe, and L. Kobbelt, “Image retrieval for image-based localization revisited,” in Proc. British Machine Vision Conf., Surrey, UK, 2012, pp. 76.1−76.12.
|
| [37] |
P. Wenzel, N. Yang, R. Wang, N. Zeller, and D. Cremers, “4Seasons: Benchmarking visual SLAM and long-term localization for autonomous driving in challenging conditions,” Int. J. Comput. Vis., vol. 133, no. 4, pp. 1564–1586, Apr. 2025. doi: 10.1007/s11263-024-02230-4
|
| [38] |
G. Zhang, X. Yan, and Y. Ye, “Loop closure detection via maximization of mutual information,” IEEE Access, vol. 7, pp. 124217−124232, 2019.
|
| [39] |
J. G. Rogers, J. M. Gregory, J. Fink, and E. Stump, “Test your SLAM! the SubT-tunnel dataset and metric for mapping,” in Proc. IEEE Int. Conf. Robotics and Autom., 2020, Paris, France, pp. 955−961.
|
| [40] |
A. Ess, B. Leibe, K. Schindler, and L. Van Gool, “A mobile vision system for robust multi-person tracking,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Anchorage, USA, 2008, pp. 1−8.
|
| [41] |
C. Wojek, S. Walk, and B. Schiele, “Multi-cue onboard pedestrian detection,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Miami, USA, 2009, pp. 794−801.
|
| [42] |
M. Enzweiler and D. M. Gavrila, “Monocular pedestrian detection: Survey and experiments,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 31, no. 12, pp. 2179–2195, Dec. 2009. doi: 10.1109/TPAMI.2008.260
|
| [43] |
X. Li, F. Flohr, Y. Yang, H. Xiong, M. Braun, S. Pan, K. Li, and D. M. Gavrila, “A new benchmark for vision-based cyclist detection,” in Proc. IEEE Intelligent Vehicles Symp., Gothenburg, Sweden, 2016, pp. 1028−1033.
|
| [44] |
S. Zhang, R. Benenson, and B. Schiele, “CityPersons: A diverse dataset for pedestrian detection,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Honolulu, USA, 2017, pp. 4457−4465.
|
| [45] |
L. Neumann, M. Karg, S. Zhang, C. Scharfenberger, E. Piegert, S. Mistr, et al, “NightOwls: A pedestrians at night dataset,” in Proc. 14th Asian Conf. Computer Vision, Perth, Australia, 2018, pp. 691−705.
|
| [46] |
M. Braun, S. Krebs, F. Flohr, and D. M. Gavrila, “EuroCity persons: A novel benchmark for person detection in traffic scenes,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 8, pp. 1844–1861, Aug. 2019. doi: 10.1109/TPAMI.2019.2897684
|
| [47] |
S. Hwang, J. Park, N. Kim, Y. Choi, and I. So Kweon, “Multispectral pedestrian detection: Benchmark dataset and baseline,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Boston, USA, 2015, pp. 1037−1045.
|
| [48] |
H. Xu, S. Wang, X. Cai, W. Zhang, X. Liang, and Z. Li, “CurveLane-NAS: Unifying lane-sensitive architecture search and adaptive point blending,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 689−704.
|
| [49] |
X. Pan, J. Shi, P. Luo, X. Wang, and X. Tang, “Spatial as deep: Spatial CNN for traffic scene understanding,” in Proc. 32nd AAAI Conf. Artificial Intelligence, New Orleans, USA, 2018, pp. 7276−7283.
|
| [50] |
S. Lee, J. Kim, J. S. Yoon, S. Shin, O. Bailo, N. Kim, T.-H. Lee, H. S. Hong, S.-H. Han, and I. So Kweon, “VPGNet: Vanishing point guided network for lane and road marking detection and recognition,” in Proc. IEEE Int. Conf. Computer Vision, Venice, Italy, 2017, pp. 1965−1973.
|
| [51] |
K. Behrendt and R. Soussan, “Unsupervised labeled lane markers using maps,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2019, pp. 832−839.
|
| [52] |
L. Chen, C. Sima, Y. Li, Z. Zheng, J. Xu, X. Geng, et al, “PersFormer: 3D lane detection via perspective transformer and the OpenLane benchmark,” in Proc. 17th European Conf. Computer Vision, Tel Aviv, Israel, 2022, pp. 550−567.
|
| [53] |
F. Yan, M. Nie, X. Cai, J. Han, H. Xu, Z. Yang, C. Ye, Y. Fu, M. B. Mi, and L. Zhang, “ONCE-3DLanes: Building monocular 3D lane detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 17122−17131.
|
| [54] |
B. Roberts, S. Kaltwang, S. Samangooei, M. Pender-Bare, K. Tertikas, and J. Redford, “A dataset for lane instance segmentation in urban environments,” in Proc. 15th European Conf. Computer Vision, Munich, Germany, 2018, pp. 543−559.
|
| [55] |
W. Cheng, H. Luo, W. Yang, L. Yu, S. Chen, and W. Li, “DET: A high-resolution DVS dataset for lane extraction,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition Workshops, Long Beach, USA, 2019, pp. 1666−1675.
|
| [56] |
T. Sato and Q. A. Chen, “Towards driving-oriented metric for lane detection models,” in Proc. Conf. IEEE/CVF Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 17132−17141.
|
| [57] |
D. Jin, W. Park, S.-G. Jeong, H. Kwon, and C.-S. Kim, “Eigenlanes: Data-driven lane descriptors for structurally diverse lanes,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 17142−17150.
|
| [58] |
T. Wu and A. Ranganathan, “A practical system for road marking detection and recognition,” in Proc. IEEE Intelligent Vehicles Symp., Madrid, Spain, 2012, pp. 25−30.
|
| [59] |
X. Liu, Z. Deng, H. Lu, and L. Cao, “Benchmark for road marking detection: Dataset specification and performance baseline,” in Proc. IEEE 20th. Int. Conf. Intelligent Transportation Systems, Yokohama, Japan, 2017, pp. 1−6.
|
| [60] |
O. Jayasinghe, S. Hemachandra, D. Anhettigama, S. Kariyawasam, R. Rodrigo, and P. Jayasekara, “CeyMo: See more on roads-a novel benchmark dataset for road marking detection,” in Proc. IEEE/CVF Winter Conf. Applications of Computer Vision, Waikoloa, USA, 2022, pp. 3381−3390.
|
| [61] |
K. Behrendt, L. Novak, and R. Botros, “A deep learning approach to traffic lights: Detection, tracking, and classification,” in Proc. IEEE Int. Conf. Robotics and Autom., Singapore, Singapore, 2017, pp. 1370−1377.
|
| [62] |
D. Tabernik and D. Skočaj, “Deep learning for large-scale traffic-sign detection and recognition,” IEEE Trans. Intell. Transp. Syst., vol. 21, no. 4, pp. 1427–1440, Apr. 2020. doi: 10.1109/TITS.2019.2913588
|
| [63] |
C. Ertler, J. Mislej, T. Ollmann, L. Porzi, G. Neuhold, and Y. Kuang, “The mapillary traffic sign dataset for detection and classification on a global scale,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 68−84.
|
| [64] |
S. Houben, J. Stallkamp, J. Salmen, M. Schlipsing, and C. Igel, “Detection of traffic signs in real-world images: The German traffic sign detection benchmark,” in Proc. Int. Joint Conf. Neural Networks, Dallas, USA, 2013, pp. 1−8.
|
| [65] |
J. Zhang, Z. Xie, J. Sun, X. Zou, and J. Wang, “A cascaded R-CNN with multiscale attention and imbalanced samples for traffic sign detection,” IEEE Access, vol. 8, pp. 29742−29754, 2020.
|
| [66] |
F. Larsson and M. Felsberg, “Using Fourier descriptors and spatial models for traffic sign recognition,” in Proc. 17th Scandinavian Conf. Image Analysis, Ystad, Sweden, 2011, pp. 238−249.
|
| [67] |
Z. Zhu, D. Liang, S. Zhang, X. Huang, B. Li, and S. Hu, “Traffic-sign detection and classification in the wild,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Las Vegas, USA, 2016, pp. 2110−2118.
|
| [68] |
M. Mathias, R. Timofte, R. Benenson, and L. Van Gool, “Traffic sign recognition-how far are we from the solution?” in Proc. Int. Joint Conf. Neural Networks, Dallas, USA, 2013, pp. 1−8.
|
| [69] |
J. Stallkamp, M. Schlipsing, J. Salmen, and C. Igel, “Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition,” Neural Netw., vol. 32, pp. 323–332, Aug. 2012. doi: 10.1016/j.neunet.2012.02.016
|
| [70] |
Y.-W. Seo, J. Lee, W. Zhang, and D. Wettergreen, “Recognition of highway workzones for reliable autonomous driving,” IEEE Trans. Intell. Transp. Syst., vol. 16, no. 2, pp. 708–718, Apr. 2015. doi: 10.1109/tits.2014.2335535
|
| [71] |
R. de Charette and F. Nashashibi, “Real time visual traffic lights recognition based on spot light detection and adaptive traffic lights templates,” in Proc. IEEE Intelligent Vehicles Symp., Xi’an, China, 2009, pp. 358−363.
|
| [72] |
A. Fregin, J. Muller, U. Krebel, and K. Dietmayer, “The DriveU traffic light dataset: Introduction and comparison with existing datasets,” in Proc. IEEE Int. Conf. Robotics and Autom., Brisbane, Australia, 2018, pp. 3376−3383.
|
| [73] |
L. Yang, P. Luo, C. C. Loy, and X. Tang, “A large-scale car dataset for fine-grained categorization and verification,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Boston, USA, 2015, pp. 3973−3981.
|
| [74] |
G. J. Brostow, J. Shotton, J. Fauqueur, and R. Cipolla, “Segmentation and recognition using structure from motion point clouds,” in Proc. 10th European Conf. Computer Vision, Marseille, France, 2008, pp. 44−57.
|
| [75] |
L. Ding, J. Terwilliger, R. Sherony, B. Reimer, and L. Fridman, “MIT DriveSeg (manual) dataset,” 2020. [Online]. Available: https://dx.doi.org/10.21227/mmke-dv03
|
| [76] |
G. Neuhold, T. Ollmann, S. R. Bulò, and P. Kontschieder, “The mapillary vistas dataset for semantic understanding of street scenes,” in Proc. IEEE Int. Conf. Computer Vision, Venice, Italy, 2017, pp. 5000−5009.
|
| [77] |
B. Kim, J. Yim, and J. Kim, “Highway driving dataset for semantic video segmentation,” in Proc. British Machine Vision Conf., Newcastle, UK, 2020, pp. 1−12.
|
| [78] |
F. Tung, J. Chen, L. Meng, and J. J. Little, “The Raincouver scene parsing benchmark for self-driving in adverse weather and at night,” IEEE Robot. Autom. Lett., vol. 2, no. 4, pp. 2188–2193, Oct. 2017. doi: 10.1109/LRA.2017.2723926
|
| [79] |
X. Fu, Q. Qi, Z.-J. Zha, Y. Zhu, and X. Ding, “Rain streak removal via dual graph convolutional network,” in Proc. 35th AAAI Conf. Artificial Intelligence, 2021, pp. 1352−1360.
|
| [80] |
X. Zhong, S. Tu, X. Ma, K. Jiang, W. Huang, and Z. Wang, “Rainy WCity: A real rainfall dataset with diverse conditions for semantic driving scene understanding,” in Proc. 31st Int. Joint Conf. Artificial Intelligence, Vienna, Austria, 2022, pp. 1743−1749.
|
| [81] |
G. Varma, A. Subramanian, A. Namboodiri, M. Chandraker, and C. V. Jawahar, “IDD: A dataset for exploring problems of autonomous navigation in unconstrained environments,” in Proc. IEEE Winter Conf. Applications of Computer Vision, Waikoloa, USA, 2019, pp. 1743−1751.
|
| [82] |
O. Zendel, K. Honauer, M. Murschitz, D. Steininger, and G. F. Domínguez, “WildDash —— creating hazard-aware benchmarks,” in Proc. 15th European Conf. Computer Vision, Munich, Germany, 2018, pp. 407−421.
|
| [83] |
X. Huang, X. Cheng, Q. Geng, B. Cao, D. Zhou, P. Wang, Y. Lin, and R. Yang, “The ApolloScape dataset for autonomous driving,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition Workshops, Salt Lake City, USA, 2018, pp. 1067−10676.
|
| [84] |
J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall, “SemanticKITTI: A dataset for semantic scene understanding of LiDAR sequences,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea (South), 2019, pp. 9296−9306.
|
| [85] |
A. Rasouli, I. Kotseruba, and J. K. Tsotsos, “Are they going to cross? A benchmark dataset and baseline for pedestrian crosswalk behavior,” in Proc. IEEE Int. Conf. Computer Vision Workshops, Venice, Italy, 2017, pp. 206−213.
|
| [86] |
C. Caraffi, T. $\overset{\vee}{\mathop{\text{V}}}\, $ojíř, J. Trefný, J. Šochman, and J. Matas, “A system for real-time detection and tracking of vehicles from a single car-mounted camera,” in Proc. 15th Int. Conf. Intelligent Transportation Systems, Anchorage, USA, 2012, pp. 975−982.
|
| [87] |
A. Dominguez-Sanchez, S. Orts-Escolano, J. Garcia-Rodriguez, and M. Cazorla, “A new dataset and performance evaluation of a region-based CNN for urban object detection,” in Proc. Int. Joint Conf. Neural Networks, Rio de Janeiro, Brazil, 2018, pp. 1−8.
|
| [88] |
K. Behrendt, “Boxy vehicle detection in large images,” in Proc. IEEE/CVF Int. Conf. Computer Vision Workshop, Seoul, Korea (South), 2019, pp. 840−846.
|
| [89] |
K. Takumi, K. Watanabe, Q. Ha, A. Tejero-De-Pablos, Y. Ushiku, and T. Harada, “Multispectral object detection for autonomous vehicles,” in Proc. Thematic Workshops of ACM Multimedia, Mountain View, USA, 2017, pp. 35−43.
|
| [90] |
X. Tian, T. Jiang, L. Yun, Y. Wang, Y. Wang, and H. Zhao, “Occ3D: A large-scale 3D occupancy prediction benchmark for autonomous driving,” in Proc. 37th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2023, p. 2809.
|
| [91] |
X. Wang, Z. Zhu, W. Xu, Y. Zhang, Y. Wei, X. Chi, Y. Ye, D. Du, J. Lu, and X. Wang, “OpenOccupancy: A large scale benchmark for surrounding semantic occupancy perception,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Paris, France, 2023, pp. 17804−17813.
|
| [92] |
G. Yang, X. Song, C. Huang, Z. Deng, J. Shi, and B. Zhou, “DrivingStereo: A large-scale dataset for stereo matching in autonomous driving scenarios,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 899−908.
|
| [93] |
A. Z. Zhu, D. Thakur, T. Özaslan, B. Pfrommer, V. Kumar, and K. Daniilidis, “The multivehicle stereo event camera dataset: An event camera dataset for 3D perception,” IEEE Robot. Autom. Lett., vol. 3, no. 3, pp. 2032–2039, Jul. 2018. doi: 10.1109/LRA.2018.2800793
|
| [94] |
F. B. Campo, F. L. Ruiz, and A. D. Sappa, “Multimodal stereo vision system: 3D data extraction and algorithm evaluation,” IEEE J. Sel. Top. Signal Process., vol. 6, no. 5, pp. 437–446, Sep. 2012. doi: 10.1109/JSTSP.2012.2204036
|
| [95] |
R. Guzmán, J.-B. Hayet, and R. Klette, “Towards ubiquitous autonomous driving: The CCSAD dataset,” in Proc. 16th Int. Conf. Computer Analysis of Images and Patterns, Valletta, Malta, 2015, pp. 582−593.
|
| [96] |
M. Menze and A. Geiger, “Object scene flow for autonomous vehicles,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Boston, USA, 2015, pp. 3061−3070.
|
| [97] |
D. Kondermann, R. Nair, K. Honauer, K. Krispin, J. Andrulis, A. Brock, et al, “The HCI benchmark suite: Stereo and flow ground truth with uncertainties for urban autonomous driving,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition Workshops, Las Vegas, USA, 2016, pp. 19−28.
|
| [98] |
J. Uhrig, N. Schneider, L. Schneider, U. Franke, T. Brox, and A. Geiger, “Sparsity invariant CNNs,” in Proc. Int. Conf. 3D Vision, Qingdao, China, 2017, pp. 11−20.
|
| [99] |
H. Hirschmuller, “Stereo processing by semiglobal matching and mutual information,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 30, no. 2, pp. 328–341, Feb. 2008. doi: 10.1109/TPAMI.2007.1166
|
| [100] |
R. Chandra, X. Wang, M. Mahajan, R. Kala, R. Palugulla, C. Naidu, A. Jain, and D. VV, “METEOR: A dense, heterogeneous, and unstructured traffic dataset with rare behaviors,” in Proc. IEEE Int. Conf. Robotics and Autom., London, UK, 2023, pp. 9169−9175.
|
| [101] |
P. Voigtlaender, M. Krause, A. Osep, J. Luiten, B. B. G. Sekar, A. Geiger, and B. Leibe, “MOTS: Multi-object tracking and segmentation,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 7934−7943.
|
| [102] |
Y. Cui, Z. Cao, Y. Xie, X. Jiang, F. Tao, Y. V. Chen, L. Li, and D. Liu, “DG-labeler and DGL-MOTS dataset: Boost the autonomous driving perception,” in Proc. IEEE/CVF Winter Conf. Applications of Computer Vision, Waikoloa, USA, 2022, pp. 3411−3420.
|
| [103] |
R. Chandra, U. Bhattacharya, A. Bera, and D. Manocha, “TraPHic: Trajectory prediction in dense and heterogeneous traffic using weighted interactions,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 8475−8484.
|
| [104] |
H. Caesar, J. Kabzan, K. S. Tan, W. K. Fong, E. Wolff, A. Lang, L. Fletcher, O. Beijbom, and S. Omari, “NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles,” arXiv preprint arXiv: 2106.11810, 2022.
|
| [105] |
X. He and C. Lv, “Towards energy-efficient autonomous driving: A multi-objective reinforcement learning approach,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 5, pp. 1329–1331, May 2023. doi: 10.1109/JAS.2023.123378
|
| [106] |
A. Jain, H. S. Koppula, S. Soh, B. Raghavan, A. Singh, and A. Saxena, “Brain4Cars: Car that knows before you do via sensory-fusion deep learning architecture,” arXiv preprint arXiv: 1601.00740, 2016.
|
| [107] |
N. Pugeault and R. Bowden, “How much of driving is preattentive?” IEEE Trans. Veh. Technol., vol. 64, no. 12, pp. 5424–5438, Dec. 2015. doi: 10.1109/TVT.2015.2487826
|
| [108] |
Y. Chen, J. Wang, J. Li, C. Lu, Z. Luo, H. Xue, and C. Wang, “LiDAR-video driving dataset: Learning driving policies effectively,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018, pp. 5870−5878.
|
| [109] |
J. Binas, D. Neil, S.-C. Liu, and T. Delbruck, “DDD17: End-to-end DAVIS driving dataset,” arXiv preprint arXiv: 1711.01458, 2017.
|
| [110] |
E. Romera, L. M. Bergasa, and R. Arroyo, “Need data for driver behaviour analysis? presenting the public UAH-DriveSet,” in Proc. IEEE 19th Int. Conf. Intelligent Transportation Systems, Rio de Janeiro, Brazil, 2016, pp. 387−392.
|
| [111] |
V. Ramanishka, Y.-T. Chen, T. Misu, and K. Saenko, “Toward driving scene understanding: A dataset for learning driver behavior and causal reasoning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018, pp. 7699−7707.
|
| [112] |
P. Mirowski, A. Banki-Horvath, K. Anderson, D. Teplyashin, K. M. Hermann, M. Malinowski, et al, “The StreetLearn environment and dataset,” arXiv preprint arXiv: 1903.01292, 2019.
|
| [113] |
X. Ye, M. Shu, H. Li, Y. Shi, Y. Li, G. Wang, X. Tan, and E. Ding, “Rope3D: The roadside perception dataset for autonomous driving and monocular 3D object detection task,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, 21309−21318.
|
| [114] |
H. Yu, W. Yang, H. Ruan, Z. Yang, Y. Tang, X. Gao, et al, “V2X-seq: A large-scale sequential dataset for vehicle-infrastructure cooperative perception and forecasting,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Vancouver, Canada, 2023, pp. 5486−5495.
|
| [115] |
K. Matzen and N. Snavely, “NYC3DCars: A dataset of 3D vehicles in geographic context,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Sydney, Australia, 2013, pp. 761−768.
|
| [116] |
X. Liu, W. Liu, T. Mei, and H. Ma, “PROVID: Progressive and multimodal vehicle reidentification for large-scale urban surveillance,” IEEE Trans. Multimedia, vol. 20, no. 3, pp. 645–658, Mar. 2018. doi: 10.1109/TMM.2017.2751966
|
| [117] |
Y. Lou, Y. Bai, J. Liu, S. Wang, and L. Duan, “VERI-Wild: A large dataset and a new method for vehicle re-identification in the wild,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 3230−3238.
|
| [118] |
Z. Tang, M. Naphade, M.-Y. Liu, X. Yang, S. Birchfield, S. Wang, R. Kumar, D. Anastasiu, and J.-N. Hwang, “CityFlow: A city-scale benchmark for multi-target multi-camera vehicle tracking and re-identification,” in Proc. IEEE/CVF Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 8789−8798.
|
| [119] |
H. Liu, Y. Tian, Y. Wang, L. Pang, and T. Huang, “Deep relative distance learning: Tell the difference between similar vehicles,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Las Vegas, USA, 2016, pp. 2167−2175.
|
| [120] |
J. Sochor, J. Špaňhel, and A. Herout, “BoxCars: Improving fine-grained recognition of vehicles using 3-D bounding boxes in traffic surveillance,” IEEE Trans. Intell. Transp. Syst., vol. 20, no. 1, pp. 97–108, Jan. 2019. doi: 10.1109/TITS.2018.2799228
|
| [121] |
L. Wen, D. Du, Z. Cai, Z. Lei, M.-C. Chang, H. Qi, J. Lim, M.-H. Yang, and S. Lyu, “UA-DETRAC: A new benchmark and protocol for multi-object detection and tracking,” Comput. Vis. Image Underst., vol. 193, p. 102907, Apr. 2020. doi: 10.1016/j.cviu.2020.102907
|
| [122] |
R. Krajewski, J. Bock, L. Kloeker, and L. Eckstein, “The highD dataset: A drone dataset of naturalistic vehicle trajectories on German highways for validation of highly automated driving systems,” in Proc. 21st Int. Conf. Intelligent Transportation Systems, Maui, USA, 2018, pp. 2118−2125.
|
| [123] |
V. Alexiadis, J. Colyar, J. Halkias, R. Hranac, and G. McHale, “The next generation simulation program,” ITE J., vol. 74, no. 8, pp. 22–26, Aug. 2004.
|
| [124] |
W. Zhan, L. Sun, D. Wang, H. Shi, A. Clausse, M. Naumann, et al, “INTERACTION dataset: An INTERnational, adversarial and cooperative moTION dataset in interactive driving scenarios with semantic maps,” arXiv preprint arXiv: 1910.03088, 2019.
|
| [125] |
L. Chen, X. Hu, W. Tian, H. Wang, D. Cao, and F.-Y. Wang, “Parallel planning: A new motion planning framework for autonomous driving,” IEEE/CAA J. Autom. Sinica, vol. 6, no. 1, pp. 236–246, Jan. 2019. doi: 10.1109/JAS.2018.7511186
|
| [126] |
D. Wu, W. Han, T. Wang, X. Dong, X. Zhang, and J. Shen, “Referring multi-object tracking,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Vancouver, Canada, 2023, pp. 14633−14642.
|
| [127] |
A. B. Vasudevan, D. Dai, and L. Van Gool, “Object referring in videos with language and human gaze,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018, pp. 4129−4138.
|
| [128] |
T. Qian, J. Chen, L. Zhuo, Y. Jiao, and Y.-G. Jiang, “NuScenes-QA: A multi-modal visual question answering benchmark for autonomous driving scenario,” in Proc. 38th AAAI Conf. Artificial Intelligence, Vancouver, Canada, 2024, pp. 4542−4550.
|
| [129] |
T. Deruyttere, S. Vandenhende, D. Grujicic, L. Van Gool, and M.-F. Moens, “Talk2Car: Taking control of your self-driving car,” in Proc. Conf. Empirical Methods in Natural Language Processing and 9th Int. Joint Conf. Natural Language Processing, Hong Kong, China, 2019, pp. 2088−2098.
|
| [130] |
D. Wu, W. Han, Y. Liu, T. Wang, C.-Z. Xu, X. Zhang, and J. Shen, “Language prompt for autonomous driving,” in Proc. 39th AAAI Conf. Artificial Intelligence, Philadelphia, Pennsylvania, USA, 2025, pp. 8359−8367.
|
| [131] |
J. Kim, A. Rohrbach, T. Darrell, J. Canny, and Z. Akata, “Textual explanations for self-driving vehicles,” in Proc. 15th European Conf. Computer Vision, Munich, Germany, 2018, pp. 577−593.
|
| [132] |
Y. Xu, X. Yang, L. Gong, H.-C. Lin, T.-Y. Wu, Y. Li, and N. Vasconcelos, “Explainable object-induced action decision for autonomous vehicles,” in Proc. Conf. IEEE/CVF Computer Vision and Pattern Recognition, Seattle, USA, 2020, pp. 9520−9529.
|
| [133] |
J. Kim, T. Misu, Y.-T. Chen, A. Tawari, and J. Canny, “Grounding human-to-vehicle advice for self-driving vehicles,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 10583−10591.
|
| [134] |
X. Ding, J. Han, H. Xu, X. Liang, W. Zhang, and X. Li, “Holistic autonomous driving understanding by bird’view injected multi-modal large models,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2024, pp. 13668−13677.
|
| [135] |
J. Yang, S. Gao, Y. Qiu, L. Chen, T. Li, B. Dai, et al, “Generalized predictive model for autonomous driving,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2024, pp. 14662−14672.
|
| [136] |
H. Maeda, Y. Sekimoto, T. Seto, T. Kashiyama, and H. Omata, “Road damage detection and classification using deep neural networks with smartphone images,” Comput. Aided Civ. Infrastruct. Eng., vol. 33, no. 12, pp. 1127–1141, Dec. 2018. doi: 10.1111/mice.12387
|
| [137] |
P. Pinggera, S. Ramos, S. Gehrig, U. Franke, C. Rother, and R. Mester, “Lost and found: Detecting small road hazards for self-driving vehicles,” in Proc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems, Daejeon, Korea (South), 2016, pp. 1099−1106.
|
| [138] |
J. Kim, K. An, and D. Lee, “RoSA dataset: Road construct zone segmentation for autonomous driving,” in Computer Vision —— ECCV 2024 Workshops, A. Del Bue, C. Canton, J. Pont-Tuset, and T. Tommasi, Eds. Cham, Germany: Springer, 2024, pp. 322−338.
|
| [139] |
Z.-D. Zhang, M.-L. Tan, Z.-C. Lan, H.-C. Liu, L. Pei, and W.-X. Yu, “CDNet: A real-time and robust crosswalk detection network on Jetson Nano based on YOLOv5,” Neural Comput. Appl., vol. 34, no. 13, pp. 10719–10730, Feb. 2022. doi: 10.1007/s00521-022-07007-9
|
| [140] |
Y. Gong, L. Deng, S. Tao, X. Lu, P. Wu, Z. Xie, Z. Ma, and M. Xie, “Unified Chinese license plate detection and recognition with high efficiency,” J. Vis. Commun. Image Represent., vol. 86, p. 103541, Jul. 2022. doi: 10.1016/j.jvcir.2022.103541
|
| [141] |
S. Alletto, A. Palazzi, F. Solera, S. Calderara, and R. Cucchiara, “DR(eye)VE: A dataset for attention-based tasks with applications to autonomous and assisted driving,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition Workshops, Las Vegas, USA, 2016, pp. 54−60.
|
| [142] |
Y. Xia, D. Zhang, J. Kim, K. Nakayama, K. Zipser, and D. Whitney, “Predicting driver attention in critical situations,” in Proc. 14th Asian Conf. Computer Vision, Perth, Australia, 2019, pp. 658−674.
|
| [143] |
J. Fang, D. Yan, J. Qiao, and J. Xue, “DADA: A large-scale benchmark and model for driver attention prediction in accidental scenarios,” arXiv preprint arXiv: 1912.12148v1, 2019.
|
| [144] |
C. Lu, T. Yue, and S. Ali, “DeepScenario: An open driving scenario dataset for autonomous driving system testing,” in Proc. IEEE/ACM 20th Int. Conf. Mining Software Repositories, Melbourne, Australia, 2023, pp. 52−56.
|
| [145] |
G. Singh, S. Akrigg, M. Di Maio, V. Fontana, R. J. Alitappeh, S. Khan, et al, “ROAD: The road event awareness dataset for autonomous driving,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 1, pp. 1036–1054, Jan. 2023. doi: 10.1109/TPAMI.2022.3150906
|
| [146] |
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “CARLA: An open urban driving simulator,” in Proc. Conf. Robot Learning, Mountain View, USA, 2017, pp. 1−16.
|
| [147] |
G. Lou, Y. Deng, X. Zheng, M. Zhang, and T. Zhang, “Testing of autonomous driving systems: Where are we and where should we go?” in Proc. 30th ACM Joint European Software Engineering Conf. and Symp. the Foundations of Software Engineering, Singapore, Singapore, 2022, pp. 31−43.
|
| [148] |
P. A. Lopez, M. Behrisch, L. Bieker-Walz, J. Erdmann, Y.-P. Flötteröd, R. Hilbrich, L. Lücken, J. Rummel, P. Wagner, and E. Wiessner, “Microscopic traffic simulation using sumo,” in Proc. 21st IEEE Int. Conf. Intelligent Transportation Systems, Maui, USA, 2018, pp. 2575−2582.
|
| [149] |
S. Shah, D. Dey, C. Lovett, and A. Kapoor, “AirSim: High-fidelity visual and physical simulation for autonomous vehicles,” in Field and Service Robotics, Cham, Germany: Springer, 2018, pp. 621−635.
|
| [150] |
Z. Yang, Y. Zhang, J. Yu, J. Cai, and J. Luo, “End-to-end multi-modal multi-task vehicle control for self-driving cars with visual perceptions,” in Proc. 24th Int. Conf. Pattern Recognition, Beijing, China, 2018, pp. 2289−2294.
|
| [151] |
G. Rong, B. H. Shin, H. Tabatabaee, Q. Lu, S. Lemke, M. Možeiko, et al, “LGSVL simulator: A high fidelity simulator for autonomous driving,” in Proc. IEEE 23rd Int. Conf. Intelligent Transportation Systems, Rhodes, Greece, 2020, pp. 1−6.
|
| [152] |
Q. Li, Z. Peng, L. Feng, Q. Zhang, Z. Xue, and B. Zhou, “MetaDrive: Composing diverse driving scenarios for generalizable reinforcement learning,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 3, pp. 3461–3475, Mar. 2023. doi: 10.1109/tpami.2022.3190471
|
| [153] |
D. Garg, M. Chli, and G. Vogiatzis, “Traffic3D: A rich 3D-traffic environment to train intelligent agents,” in Proc. 19th Int. Conf. Computational Science, Faro, Portugal, 2019, pp. 749−755.
|
| [154] |
G. Ros, L. Sellart, J. Materzynska, D. Vazquez, and A. M. Lopez, “The SYNTHIA dataset: A large collection of synthetic images for semantic segmentation of urban scenes,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Las Vegas, USA, 2016, pp. 3234−3243.
|
| [155] |
A. Gaidon, Q. Wang, Y. Cabon, and E. Vig, “VirtualWorlds as proxy for multi-object tracking analysis,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Las Vegas, USA, 2016, pp. 4340−4349.
|
| [156] |
S. R. Richter, Z. Hayder, and V. Koltun, “Playing for benchmarks,” in Proc. IEEE Conf. Int. Conf. Computer Vision, Venice, Italy, 2017, pp. 2232−2241.
|
| [157] |
X. Weng, Y. Man, J. Park, Y. Yuan, M. O’Toole, and K. M. Kitani, “All-in-one drive: A comprehensive perception dataset with high-density long-range point clouds,” in Proc. 35th Conf. Neural Information Processing Systems Track on Datasets and Benchmarks, 2021, pp. 1−13.
|
| [158] |
S. R. Richter, V. Vineet, S. Roth, and V. Koltun, “Playing for data: Ground truth from computer games,” in Proc. 14th European Conf. Computer Vision, Amsterdam, the Netherlands, 2016, pp. 102−118.
|
| [159] |
B. Hurl, K. Czarnecki, and S. Waslander, “Precise synthetic image and lidar (presil) dataset for autonomous vehicle perception,” in Proc. IEEE Intelligent Vehicles Symp., Paris, France, 2019, pp. 2522−2529.
|
| [160] |
Y. Li, D. Ma, Z. An, Z. Wang, Y. Zhong, S. Chen, and C. Feng, “V2X-sim: Multi-agent collaborative perception dataset and benchmark for autonomous driving,” IEEE Robot. Autom. Lett., vol. 7, no. 4, pp. 10914–10921, Oct. 2022. doi: 10.1109/LRA.2022.3192802
|
| [161] |
E. Alberti, A. Tavera, C. Masone, and B. Caputo, “IDDA: A large-scale multi-domain dataset for autonomous driving,” IEEE Robot. Autom. Lett., vol. 5, no. 4, pp. 5526–5533, Oct. 2020. doi: 10.1109/LRA.2020.3009075
|
| [162] |
B. Stuhr, J. Haselberger, and J. Gebele, “CARLANE: A lane detection benchmark for unsupervised domain adaptation from simulation to multiple real-world domains,” in Proc. 36th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2022, pp. 292.
|
| [163] |
Y. Guo, G. Chen, P. Zhao, W. Zhang, J. Miao, J. Wang, and T. E. Choe, “Gen-lanenet: A generalized and scalable approach for 3D lane detection,” in Proc. European Conf. Computer Vision, 2020, pp. 666−681.
|
| [164] |
N. Garnett, R. Cohen, T. Pe’er, R. Lahav, and D. Levi, “3D-LaneNet: End-to-end 3D multiple lane detection,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea (South), 2019, pp. 2921−2930.
|
| [165] |
D. Temel, G. Kwon, M. Prabhushankar, and G. AlRegib, “CURE-TSR: Challenging unreal and real environments for traffic sign recognition,” arXiv preprint arXiv: 1712.02463, 2018.
|
| [166] |
T. Sun, M. Segu, J. Postels, Y. Wang, L. Van Gool, B. Schiele, F. Tombari, and F. Yu, “SHIFT: A synthetic driving dataset for continuous multi-task domain adaptation,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 21339−21350.
|
| [167] |
R. Xu, H. Xiang, X. Xia, X. Han, J. Li, and J. Ma, “OPV2V: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication,” in Proc. Int. Conf. Robotics and Autom., Philadelphia, USA, 2022, pp. 2583−2589.
|
| [168] |
X. Li, X. Yang, Z. Ma, and J.-H. Xue, “Deep metric learning for few-shot image classification: A review of recent developments,” Pattern Recognit., vol. 138, p. 109381, Jun. 2023. doi: 10.1016/j.patcog.2023.109381
|
| [169] |
R. Kümmerle, B. Steder, C. Dornhege, M. Ruhnke, G. Grisetti, C. Stachniss, and A. Kleiner, “On measuring the accuracy of SLAM algorithms,” Auton. Robots, vol. 27, no. 4, pp. 387–407, Sep. 2009. doi: 10.1007/s10514-009-9155-6
|
| [170] |
M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman, “The PASCAL visual object classes (VOC) challenge,” Int. J. Comput. Vis., vol. 88, no. 2, pp. 303–338, Jun. 2010. doi: 10.1007/s11263-009-0275-4
|
| [171] |
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft COCO: Common objects in context,” in Proc. 13th European Conf. Computer Vision, Zurich, Switzerland, 2014, pp. 740−755.
|
| [172] |
D. Eigen, C. Puhrsch, and R. Fergus, “Depth map prediction from a single image using a multi-scale deep network,” in Proc. 28th Int. Conf. Neural Information Processing Systems, Montreal, Canada, 2014, pp. 2366−2374.
|
| [173] |
K. Bernardin and R. Stiefelhagen, “Evaluating multiple object tracking performance: The clear mot metrics,” EURASIP J. Image Video Process., vol. 2008, no. 1, p. 246309, May 2008. doi: 10.1155/2008/246309
|
| [174] |
A. Milan, L. Leal-Taixé, I. Reid, S. Roth, and K. Schindler, “MOT16: A benchmark for multi-object tracking,” arXiv preprint arXiv: 1603.00831, 2016.
|
| [175] |
J. Luiten, A. Ošep, P. Dendorfer, P. Torr, A. Geiger, L. Leal-Taixé, and B. Leibe, “HOTA: A higher order metric for evaluating multi-object tracking,” Int. J. Comput. Vis., vol. 129, no. 2, pp. 548–578, Feb. 2021. doi: 10.1007/s11263-020-01375-2
|
| [176] |
X. Weng, J. Wang, S. Levine, K. Kitani, and N. Rhinehart, “Inverting the pose forecasting pipeline with SPF2: Sequential pointcloud forecasting for sequential pose forecasting,” in Proc. Conf. Robot Learning, 2020, pp. 11−20.
|
| [177] |
A. Simonelli, S. R. Bulò, L. Porzi, M. Lopez-Antequera, and P. Kontschieder, “Disentangling monocular 3D object detection,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea (South), 2019, pp. 1991−1999.
|
| [178] |
J. Li, S. Luo, Z. Zhu, H. Dai, A. S. Krylov, Y. Ding, and L. Shao, “3D IoU-net: IoU guided 3D object detector for point clouds,” arXiv preprint arXiv: 2004.04962, 2020.
|
| [179] |
X. Weng and K. Kitani, “A baseline for 3D multi-object tracking,” arXiv preprint arXiv: 1907.03961, 2019.
|
| [180] |
M. Evtikhiev, E. Bogomolov, Y. Sokolov, and T. Bryksin, “Out of the BLEU: How should we assess quality of the code generation models?” J. Syst. Softw., vol. 203, p. 111741, Sep. 2023. doi: 10.1016/j.jss.2023.111741
|
| [181] |
T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger, and Y. Artzi, “BERTScore: Evaluating text generation with BERT,” in Proc. 8th Int. Conf. Learning Representations, Addis Ababa, Ethiopia, 2020, pp. 1−43.
|
| [182] |
J. Fu, S.-K. Ng, Z. Jiang, and P. Liu, “GPTScore: Evaluate as you desire,” in Proc. Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Mexico City, Mexico, 2023, pp. 6556−6576.
|
| [183] |
R. Vedantam, C. L. Zitnick, and D. Parikh, “CIDEr: Consensus-based image description evaluation,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Boston, USA, 2015, pp. 4566−4575.
|
| [184] |
P. Anderson, B. Fernando, M. Johnson, and S. Gould, “SPICE: Semantic propositional image caption evaluation,” in Proc. 14th European Conf. Computer Vision, Amsterdam, the Netherlands, 2016, pp. 382−398.
|
| [185] |
X. Tian, J. Gu, B. Li, Y. Liu, Y. Wang, Z. Zhao, K. Zhan, P. Jia, X. Lang, and H. Zhao, “DriveVLM: The convergence of autonomous driving and large vision-language models,” in Proc. 8th Conf. Robot Learning, Munich, Germany, 2024, pp. 4698−4726.
|
| [186] |
R. Arandjelović, P. Gronat, A. Torii, T. Pajdla, and J. Sivic, “NetVLAD: CNN architecture for weakly supervised place recognition,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Las Vegas, USA, 2016, pp. 5297−5307.
|
| [187] |
M. A. Uy and G. H. Lee, “PointNetVLAD: Deep point cloud based retrieval for large-scale place recognition,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018, pp. 4470−4479.
|
| [188] |
L. Luo, S. Zheng, Y. Li, Y. Fan, B. Yu, S.-Y. Cao, J. Li, and H.-L. Shen, “BEVPlace: Learning lidar-based place recognition using bird’s eye view images,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Paris, France, 2023, pp. 8666−8675.
|
| [189] |
T. Barros, L. Garrote, M. Aleksandrov, C. Premebida, and U. J. Nunes, “TReR: A lightweight transformer re-ranking approach for 3D LiDAR place recognition,” in Proc. IEEE 26th Int. Conf. Intelligent Transportation Systems, Bilbao, Spain, 2023, pp. 2843−2849.
|
| [190] |
L. Luo, S.-Y. Cao, B. Han, H.-L. Shen, and J. Li, “BVMatch: Lidar-based place recognition using bird’s-eye view images,” IEEE Robot. Autom. Lett., vol. 6, no. 3, pp. 6076–6083, Jul. 2021. doi: 10.1109/LRA.2021.3091386
|
| [191] |
K. Cai, C. X. Lu, and X. Huang, “STUN: Self-teaching uncertainty estimation for place recognition,” in Proc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems, Kyoto, Japan, 2022, pp. 6614−6621.
|
| [192] |
Z. Huang, R. Huang, L. Sun, C. Zhao, M. Huang, and S. Su, “VEFNet: An event-RGB cross modality fusion network for visual place recognition,” in Proc. IEEE Int. Conf. Image Processing, Bordeaux, France, 2022, pp. 2671−2675.
|
| [193] |
D. Rozenberszki and A. L. Majdik, “Lol: Lidar-only odometry and localization in 3D point cloud maps,” in Proc. IEEE Int. Conf. Robotics and Autom., Paris, France, 2020, pp. 4379−4385.
|
| [194] |
P. Agarwal, W. Burgard, and L. Spinello, “Metric localization using google street view,” in Proc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems, Hamburg, Germany, 2015, pp. 3111−3118.
|
| [195] |
X. Chen, T. Läbe, A. Milioto, T. Röhling, J. Behley, and C. Stachniss, “OverlapNet: A siamese network for computing LiDAR scan similarity with applications to loop closing and localization,” Auton. Robots, vol. 46, no. 1, pp. 61–81, Feb., Jan. 2022. doi: 10.1007/s10514-021-09999-0
|
| [196] |
N. Engel, V. Belagiannis, and K. Dietmayer, “Attention-based vehicle self-localization with HD feature maps,” in Proc. IEEE Int. Conf. Intelligent Transportation Systems, Indianapolis, USA, 2021, pp. 76−83.
|
| [197] |
T. Y. Tang, D. De Martini, S. Wu, and P. Newman, “Self-supervised localisation between range sensors and overhead imagery,” in Proc. Robotics: Science and Systems, Corvalis, USA, 2020, pp. 1−10.
|
| [198] |
Z. Zhang, Z. Yao, and M. Lu, “TWO: A simple method of directly closing the loop for LiDAR odometry,” in Proc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems, Detroit, USA, 2023, pp. 11003−11010.
|
| [199] |
X. Chen, P. Wu, G. Li, and T. H. Li, “LIO-PPF: Fast LiDAR-inertial odometry via incremental plane pre-fitting and skeleton tracking,” in Proc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems, Detroit, USA, 2023, pp. 1458−1465.
|
| [200] |
J. Wang, B. Tian, R. Zhang, and L. Chen, “ULSM: Underground localization and semantic mapping with salient region loop closure under perceptually-degraded environment,” in Proc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems, Kyoto, Japan, 2022, pp. 1320−1327.
|
| [201] |
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 213−229.
|
| [202] |
W. Wang, Z. Chen, X. Chen, J. Wu, X. Zhu, G. Zeng, Pet al, “VisionLLM: Large language model is also an open-ended decoder for vision-centric tasks,” in Proc. 37th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2023, pp. 2688.
|
| [203] |
S. Choi, S. Jung, H. Yun, J. T. Kim, S. Kim, and J. Choo, “RobustNet: Improving domain generalization in urban-scene segmentation via instance selective whitening,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 11575−11585.
|
| [204] |
P. Oza, V. A. Sindagi, V. S. Vibashan, and V. M. Patel, “Unsupervised domain adaptation of object detectors: A survey,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 6, pp. 4018−4040, Jun. 2024.
|
| [205] |
D. Wu, M.-W. Liao, W.-T. Zhang, X.-G. Wang, X. Bai, W.-Q. Cheng, and W.-Y. Liu, “YOLOP: You only look once for panoptic driving perception,” Mach. Intell. Res., vol. 19, no. 6, pp. 550–562, Nov. 2022. doi: 10.1007/s11633-022-1339-y
|
| [206] |
L.-C. Chen, G. Papandreou, F. Schroff, and H. Adam, “Rethinking atrous convolution for semantic image segmentation,” arXiv preprint arXiv: 1706.05587, 2017.
|
| [207] |
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable DETR: Deformable transformers for end-to-end object detection,” in Proc. 9th Int. Conf. Learning Representations, 2021, pp. 1−16.
|
| [208] |
B. Cheng, A. G. Schwing, and A. Kirillov, “Per-pixel classification is not all you need for semantic segmentation,” in Proc. 35th Int. Conf. Neural Information Processing Systems, 2021, pp. 1367.
|
| [209] |
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar, “Masked-attention mask transformer for universal image segmentation,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 1280−1289.
|
| [210] |
C. Hümmer, M. Schwonberg, L. Zhou, H. Cao, A. Knoll, and H. Gottschalk, “Strong but simple: A baseline for domain generalized dense perception by clip-based transfer learning,” in Proc. 17th Asian Conf. Computer Vision, Hanoi, Vietnam, 2024, pp. 463−484
|
| [211] |
W. Wang, J. Dai, Z. Chen, Z. Huang, Z. Li, X. Zhu, et al, “InternImage: Exploring large-scale vision foundation models with deformable convolutions,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Vancouver, Canada, 2023, pp. 14408−14419.
|
| [212] |
J. Ding, N. Xue, G.-S. Xia, B. Schiele, and D. Dai, “HGFormer: Hierarchical grouping transformer for domain generalized semantic segmentation,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Vancouver, Canada, 2023, pp. 15413−15423.
|
| [213] |
R. Azad, M. Heidary, K. Yilmaz, M. Hüttemann, S. Karimijafarbigloo, Y. Wu, A. Schmeink, and D. Merhof, “Loss functions in the era of semantic segmentation: A survey and outlook,” arXiv preprint arXiv: 2312.05391, 2023.
|
| [214] |
K. Yilmaz, J. Schult, A. Nekrasov, and B. Leibe, “Mask4Former: Mask transformer for 4D panoptic segmentation,” in Proc. IEEE Int. Conf. Robotics and Autom., Yokohama, Japan, 2024, pp. 9418−9425.
|
| [215] |
X. Wu, L. Jiang, P.-S. Wang, Z. Liu, X. Liu, Y. Qiao, W. Ouyang, T. He, and H. Zhao, “Point transformer V3: Simpler, faster, stronger,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2024, pp. 4840−4851.
|
| [216] |
C. Yang, Y. Chen, H. Tian, C. Tao, X. Zhu, Z. Zhang, G. Huang, H. Li, Y. Qiao, L. Lu et al., “BEVFormer v2: Adapting modern image backbones to bird’s-eye-view recognition via perspective supervision,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Vancouver, Canada, 2023, pp. 17830−17839.
|
| [217] |
Y. Wei, L. Zhao, W. Zheng, Z. Zhu, J. Zhou, and J. Lu, “SurroundOcc: Multi-camera 3D occupancy prediction for autonomous driving,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Paris, France, 2023, pp. 21672−21683.
|
| [218] |
J. Zeng, C. Yao, Y. Wu, and Y. Jia, “Temporally consistent stereo matching,” in Proc. 18th European Conf. Computer Vision, Milan, Italy, 2024, pp. 341−359.
|
| [219] |
H. Liu, T. Lu, Y. Xu, J. Liu, and L. Wang, “Learning optical flow and scene flow with bidirectional camera-LiDAR fusion,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 4, pp. 2378–2395, Apr. 2024. doi: 10.1109/TPAMI.2023.3330866
|
| [220] |
T.-X. Xu, Y.-C. Guo, Y.-K. Lai, and S.-H. Zhang, “MBPTrack: Improving 3D point cloud tracking with memory networks and box priors,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Paris, France, 2023, pp. 9877−9886.
|
| [221] |
Z. Zong, D. Jiang, G. Song, Z. Xue, J. Su, H. Li, and Y. Liu, “Temporal enhanced training of multi-view 3D object detector via historical object prediction,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Paris, France, 2023, pp. 3758−3767.
|
| [222] |
I. Bae, J. Oh, and H.-G. Jeon, “EigenTrajectory: Low-rank descriptors for multi-modal trajectory forecasting,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Paris, France, 2023, pp. 9983−9995.
|
| [223] |
X. Chen, S. Shi, C. Zhang, B. Zhu, Q. Wang, K. C. Cheung, S. See, and H. Li, “TrajectoryFormer: 3D object tracking transformer with predictive trajectory hypotheses,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Paris, France, 2023, pp. 18481−18490.
|
| [224] |
E. W. Dijkstra, “A note on two problems in connexion with graphs,” Numer. Math., vol. 1, no. 1, pp. 269–271, Dec. 1959. doi: 10.1007/BF01386390
|
| [225] |
N. J. Nilsson, “A mobius automation: An application of artificial intelligence techniques,” in Proc. 1st Int. Joint Conf. Artificial Intelligence, Washington, USA, 1969, pp. 509−520.
|
| [226] |
H. Bai, S. Cai, N. Ye, D. Hsu, and W. S. Lee, “Intention-aware online POMDP planning for autonomous driving in a crowd,” in Proc. IEEE Int. Conf. Robotics and Autom., Seattle, USA, 2015, pp. 454−460.
|
| [227] |
J. Wei, J. M. Snider, T. Gu, J. M. Dolan, and B. Litkouhi, “A behavioral planning framework for autonomous driving,” in Proc. IEEE Intelligent Vehicles Symp., Dearborn, USA, 2014, pp. 458−464.
|
| [228] |
S. Karaman, M. R. Walter, A. Perez, E. Frazzoli, and S. Teller, “Anytime motion planning using the RRT,” in Proc. IEEE Int. Conf. Robotics and Autom., Shanghai, China, 2011, pp. 1478−1483.
|
| [229] |
Y. Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, et al, “Planning-oriented autonomous driving,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Vancouver, Canada, 2023, pp. 17853−17862.
|
| [230] |
Z. Huang, H. Liu, and C. Lv, “GameFormer: Game-theoretic modeling and learning of transformer-based interactive prediction and planning for autonomous driving,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Paris, France, 2023, pp. 3880−3890.
|
| [231] |
S. Teng, X. Hu, P. Deng, B. Li, Y. Li, Y. Ai, D. Yang, L. Li, Z. Xuanyuan, F. Zhu, and L. Chen, “Motion planning for autonomous driving: The state of the art and future perspectives,” IEEE Trans. Intell. Veh., vol. 8, no. 6, pp. 3692–3711, Jun. 2023. doi: 10.1109/TIV.2023.3274536
|
| [232] |
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, “End-to-end autonomous driving: Challenges and frontiers,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 12, pp. 10164–10183, Dec. 2024. doi: 10.1109/TPAMI.2024.3435937
|
| [233] |
X. Zhou, M. Liu, E. Yurtsever, B. L. Zagar, W. Zimmer, H. Cao, and A. C. Knoll, “Vision language models in autonomous driving: A survey and outlook,” IEEE Trans. Intell. Veh., arXiv preprint arXiv: 2310.14414, 2024.
|
| [234] |
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, and H. Li, “DriveLM: Driving with graph visual question answering,” in Proc. 18th European Conf. Computer Vision, Milan, Italy, 2024, pp. 256−274.
|
| [235] |
E. Cui, W. Wang, Z. Li, J. Xie, H. Zou, HL Deng, GL Luo, LL Lu, X. Zhu, and J. Dai, “DriveMLM: Aligning multi-modal large language models with behavioral planning states for autonomous driving,” Vis. Intell., vol. 3, no. 1, pp. 22, Oct. 2025.
|
| [236] |
H. Shao, Y. Hu, L. Wang, G. Song, S. L. Waslander, Y. Liu, and H. Li, “LMDrive: Closed-loop end-to-end driving with large language models,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2024, pp. 15120−15130.
|
| [237] |
Z. Huang, C. Feng, F. Yan, B. Xiao, Z. Jie, Y. Zhong, X. Liang, and L. Ma, “DriveMM: All-in-one large multimodal model for autonomous driving,” arXiv preprint arXiv: 2412.07689, 2024.
|
| [238] |
A.-M. Marcu, L. Chen, J. Hünermann, A. Karnsund, B. Hanotte, P. Chidananda, et al, “LingoQA: Visual question answering for autonomous driving,” in Proc. 18th European Conf. Computer Vision, Milan, Italy, 2024, pp. 252−269.
|
| [239] |
M. Nie, R. Peng, C. Wang, X. Cai, J. Han, H. Xu, and L. Zhang, “Reason2Drive: Towards interpretable and chain-based reasoning for autonomous driving,” in Proc. 18th European Conf. Computer Vision, Milan, Italy, 2024, pp. 292−308.
|
| [240] |
Y. Ma, C. Cui, X. Cao, W. Ye, P. Liu, J. Lu, et al, “LaMPilot: An open benchmark dataset for autonomous driving with language model programs,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2024, pp. 15141−15151.
|
| [241] |
S. Sreeram, T.-H. Wang, A. Maalouf, G. Rosman, S. Karaman, and D. Rus, “Probing multimodal LLMs as world models for driving,” IEEE Robot. Autom. Lett., vol. 10, no. 11, pp. 11403–11410, Nov. 2025. doi: 10.1109/LRA.2025.3608656
|
| [242] |
S. Wang, Z. Yu, X. Jiang, S. Lan, M. Shi, N. Chang, J. Kautz, Y. Li, and J. M. Alvarez, “OmniDrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2025, pp. 22442−22452.
|
| [243] |
M. Liang, J.-C. Su, S. Schulter, S. Garg, S. Zhao, Y. Wu, and M. Chandraker, “AIDE: An automatic data engine for object detection in autonomous driving,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2024, pp. 14695−14706.
|
| [244] |
Z. Yang, X. Jia, H. Li, and J. Yan, “LLM4Drive: A survey of large language models for autonomous driving,” arXiv preprint arXiv: 2311.01043, 2024.
|
| [245] |
K. Li, K. Chen, H. Wang, L. Hong, C. Ye, J. Han, et al, “CODA: A real-world road corner case dataset for object detection in autonomous driving,” in Proc. 17th European Conf. Computer Vision, Tel Aviv, Israel, 2022, pp. 406−423.
|
| [246] |
L. Li, W. Shao, W. Dong, Y. Tian, K. Yang, and W. Zhang, “Data-centric evolution in autonomous driving: A comprehensive survey of big data system, data mining, and closed-loop technologies,” arXiv preprint arXiv: 2401.12888, 2024.
|
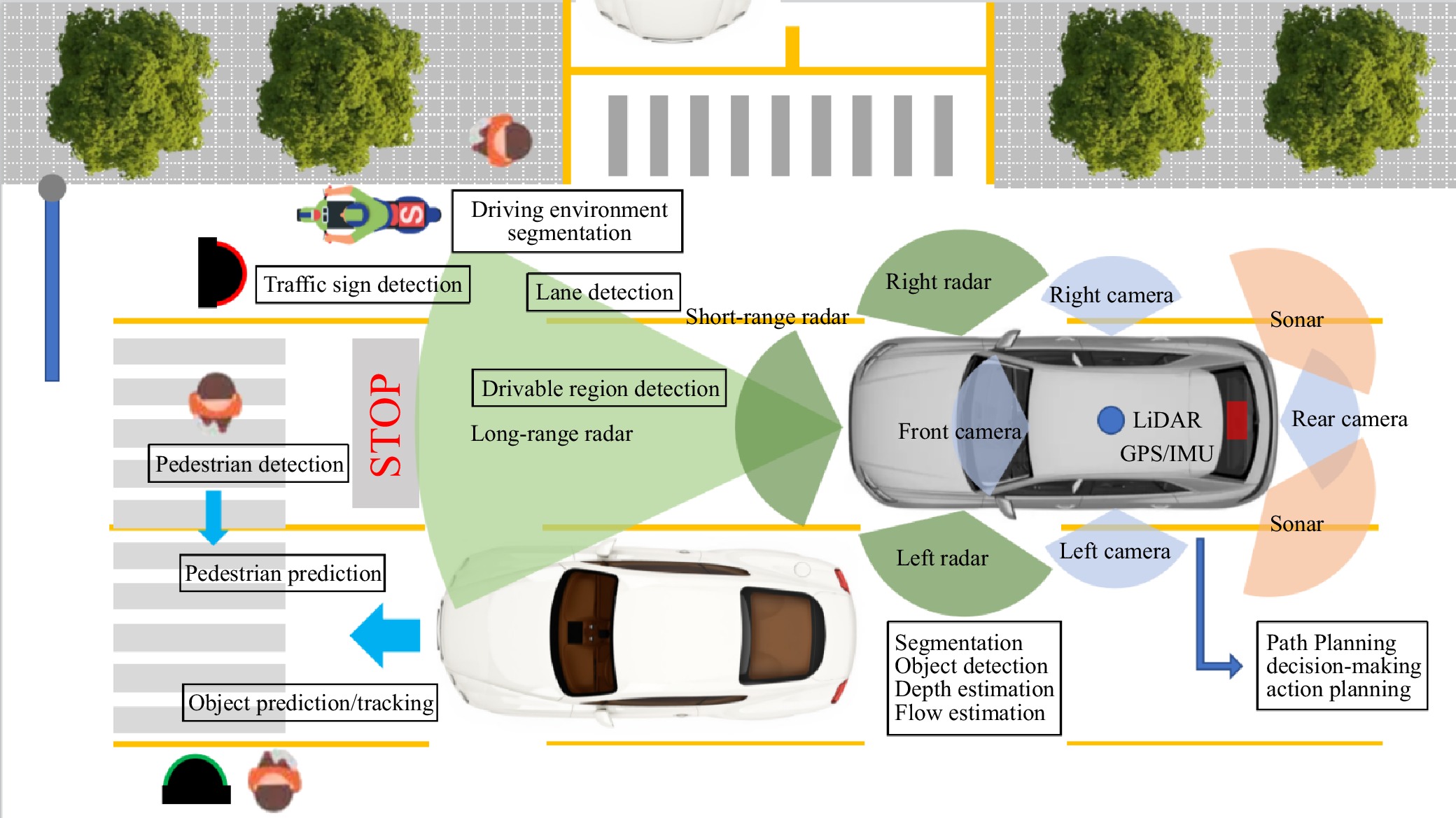
Figures(5) / Tables(10)






 DownLoad:
DownLoad: