A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation

IEEE/CAA Journal of Automatica Sinica
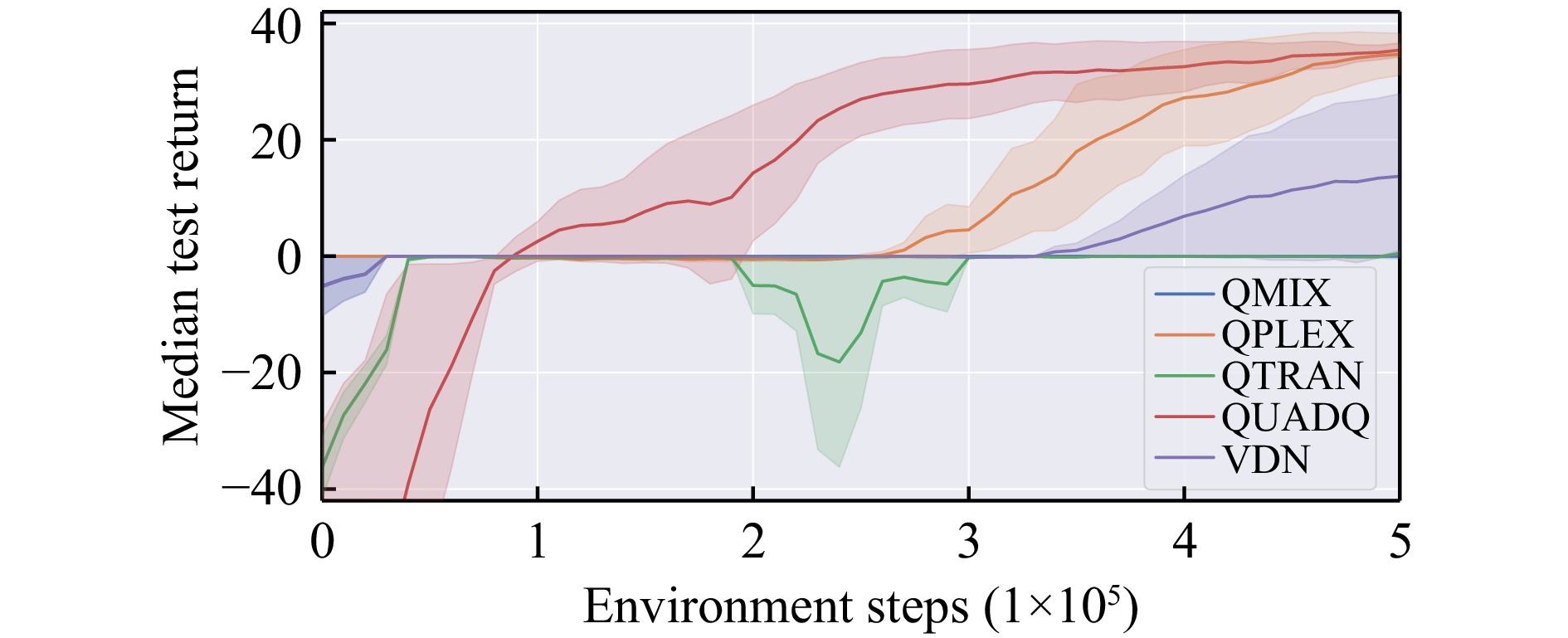
| Citation: | S. Wang, R. Zhang, Y. Zhou, J. Shao, and Y. Cheng, “QuadQ: Quadratic-based value decomposition for cooperative policy optimization in multi-agent reinforcement learning,” IEEE/CAA J. Autom. Sinica, early access, 2026. doi: 10.1109/JAS.2025.125666

|

| [1] |
W. Zhou, D. Chen, J. Yan, Z. Li, H. Yin, and W. Ge, “Multi-agent reinforcement learning for cooperative lane changing of connected and autonomous vehicles in mixed traffic,” Autonomous Intelligent Systems, vol. 2, no. 1, p. 5, 2022.
|
| [2] |
W. Cao, J. Yan, X. Yang, X. Luo, and X. Guan, “Communication-aware formation control of auvs with model uncertainty and fading channel via integral reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 1, pp. 159–176, 2023.
|
| [3] |
L. Xia, Q. Li, R. Song, and H. Modares, “Optimal synchronization control of heterogeneous asymmetric input-constrained unknown nonlinear mass via reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 3, pp. 520–532, 2021.
|
| [4] |
H. Zhang, Y. Li, Z. Wang, Y. Ding, and H. Yan, “Policy gradient adaptive dynamic programming for model-free multi-objective optimal control,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 4, pp. 1060–1062, 2023.
|
| [5] |
P. Sunehag, G. Lever, A. Gruslys, W. M. Czarnecki, V. Zambaldi, M. Jaderberg, M. Lanctot, N. Sonnerat, J. Z. Leibo, K. Tuyls, and T. Graepel, “Value-decomposition networks for cooperative multi-agent learning based on team reward,” in Proc. AAMAS, 2018, pp. 2085–2087.
|
| [6] |
T. Rashid, M. Samvelyan, C. S. De Witt, G. Farquhar, J. Foerster, and S. Whiteson, “Monotonic value function factorisation for deep multi-agent reinforcement learning,” J. Machine Learning Research, vol. 21, no. 178, pp. 1–51, 2020.
|
| [7] |
K. Son, D. Kim, W. J. Kang, D. E. Hostallero, and Y. Yi, “QTRAN: Learning to factorize with transformation for cooperative multi-agent reinforcement learning,” in proc. Int. Conf. Machine Learning, 2019, pp. 5887–5896.
|
| [8] |
J. Wang, Z. Ren, T. Liu, Y. Yu, and C. Zhang, “QPLEX: Duplex dueling multi-agent Q-learning,” in proc. Int. Conf. Learning Representations, 2021, pp. 1–27.
|
| [9] |
T. Rashid, G. Farquhar, B. Peng, and S. Whiteson, “Weighted QMIX: Expanding monotonic value function factorisation for deep multi-agent reinforcement learning,” Advances in Neural Information Processing Systems, vol. 33, pp. 10199–10210, 2020.
|
| [10] |
H. Li, H. Zhou, Y. Zou, D. Yu, and T. Lan, “ConCAVEQ: Non-monotonic value function factorization via concave representations in deep multi-agent reinforcement learning,” in Proc. AAAI Conf. Artificial Intelligence, 2024, vol. 38, no. 16, pp. 17461–17468.
|
| [11] |
S. Whiteson, M. Samvelyan, T. Rashid, C. De Witt, G. Farquhar, N. Nardelli, T. Rudner, C. Hung, P. Torr, and J. Foerster, “The starcraft multi-agent challenge,” in Proc. Int. Joint Conf. Autonomous Agents and Multiagent Systems, 2019, pp. 2186–2188.
|
Figures(1) / Tables(1)






 DownLoad:
DownLoad: