A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 11
Issue 3
Volume 11
Issue 3
IEEE/CAA Journal of Automatica Sinica
| Citation: | Y. Zhang, L. Zhang, and Y. Cai, “Value iteration-based cooperative adaptive optimal control for multi-player differential games with incomplete information,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 3, pp. 690–697, Mar. 2024. doi: 10.1109/JAS.2023.124125

|
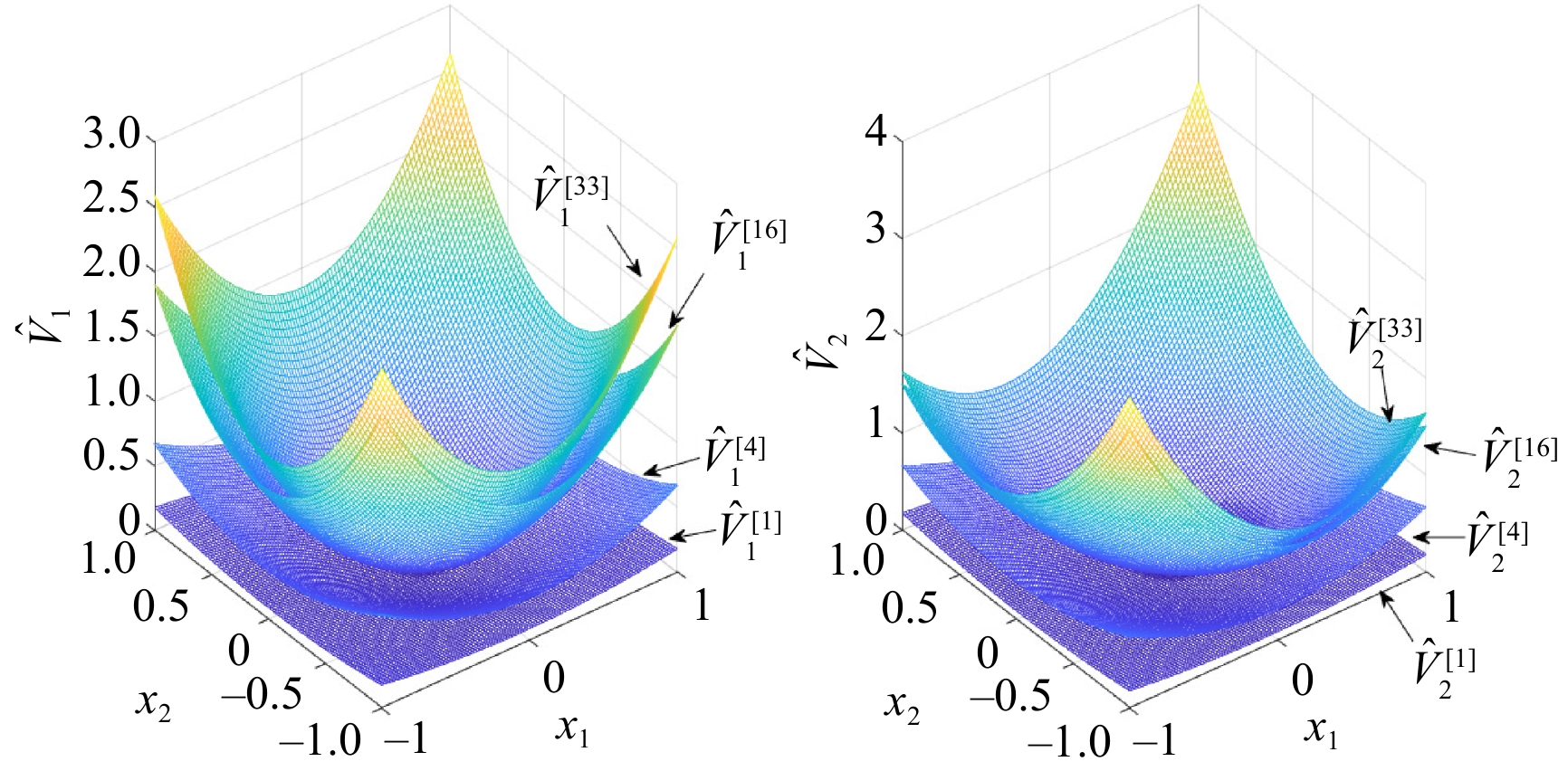
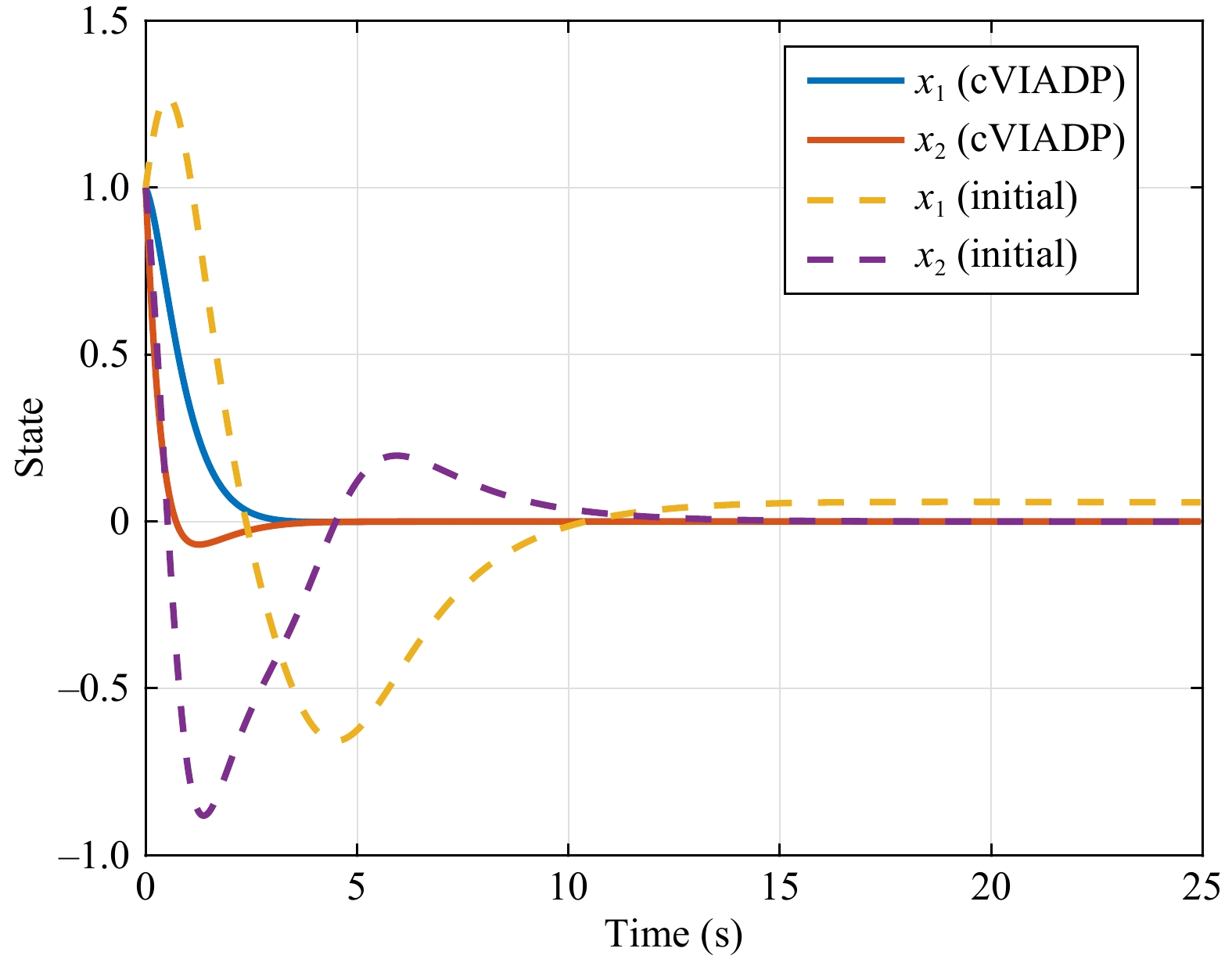
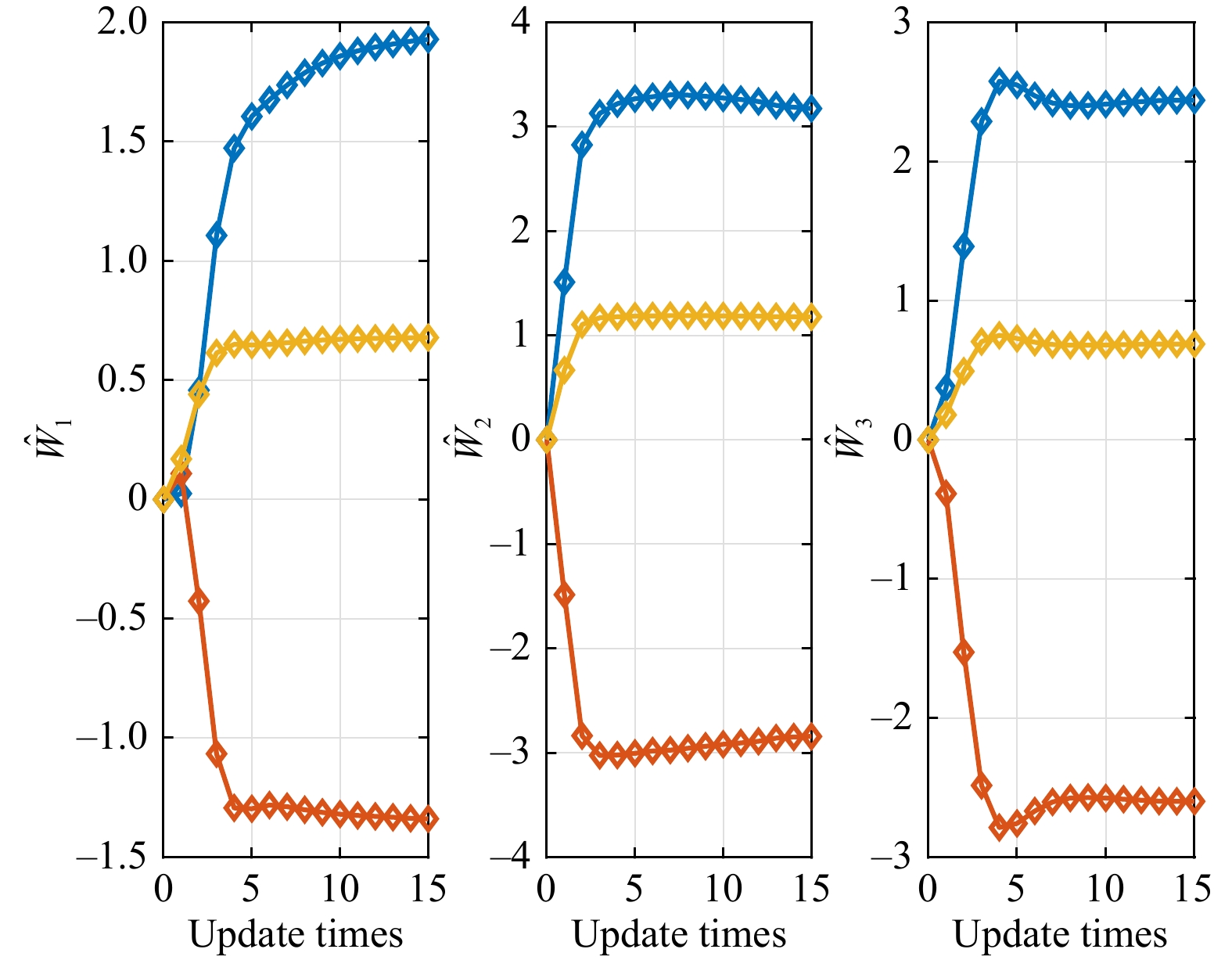
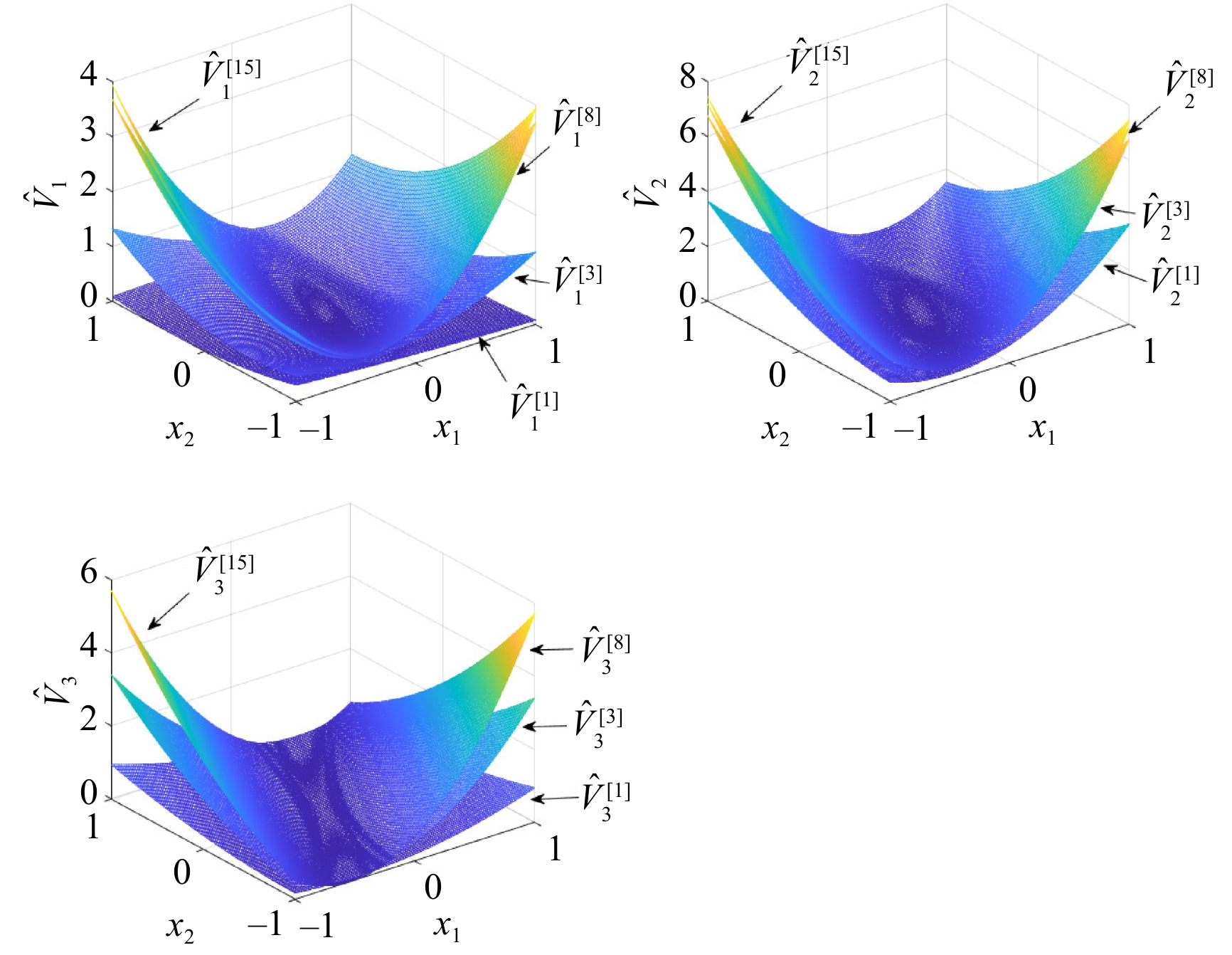
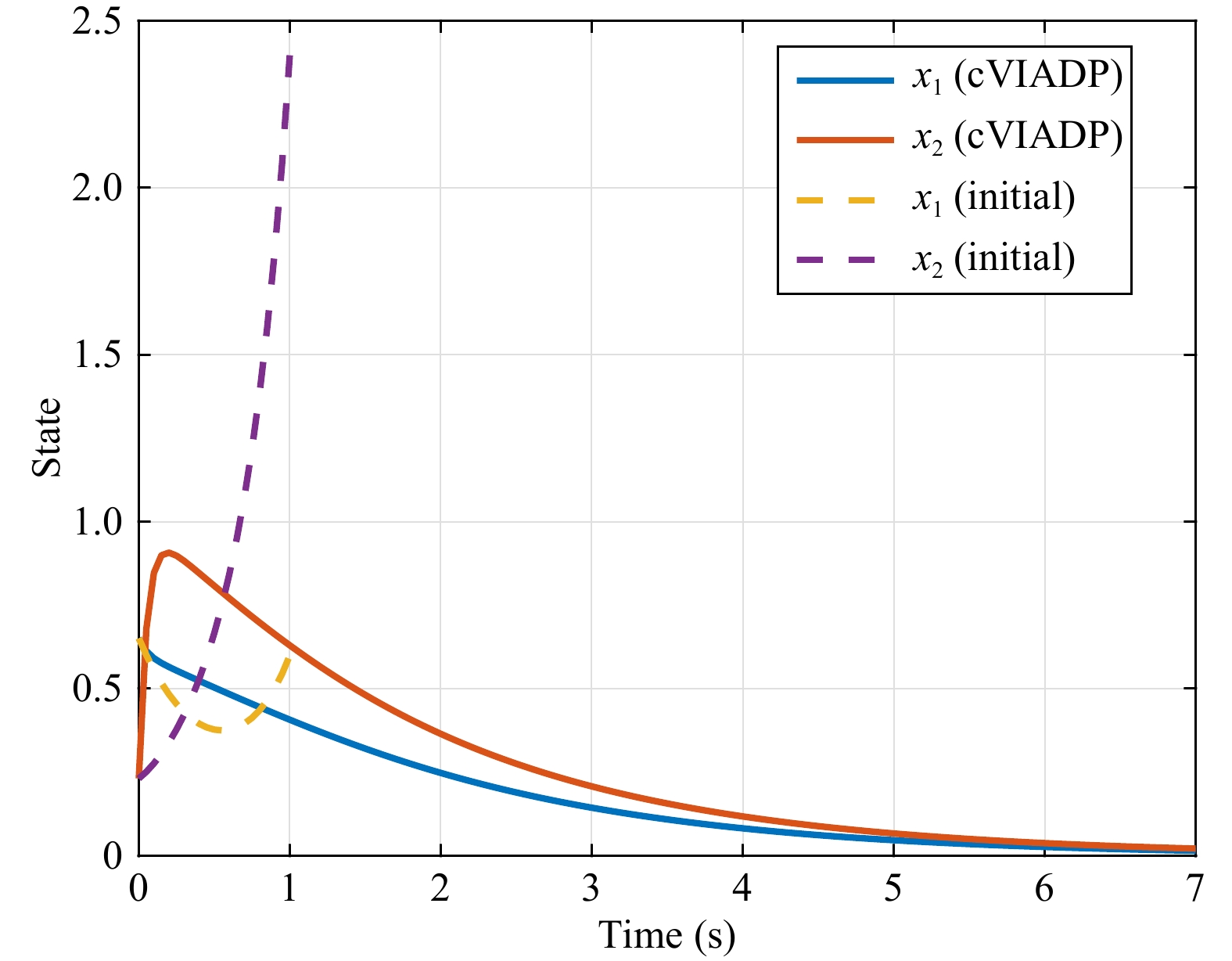
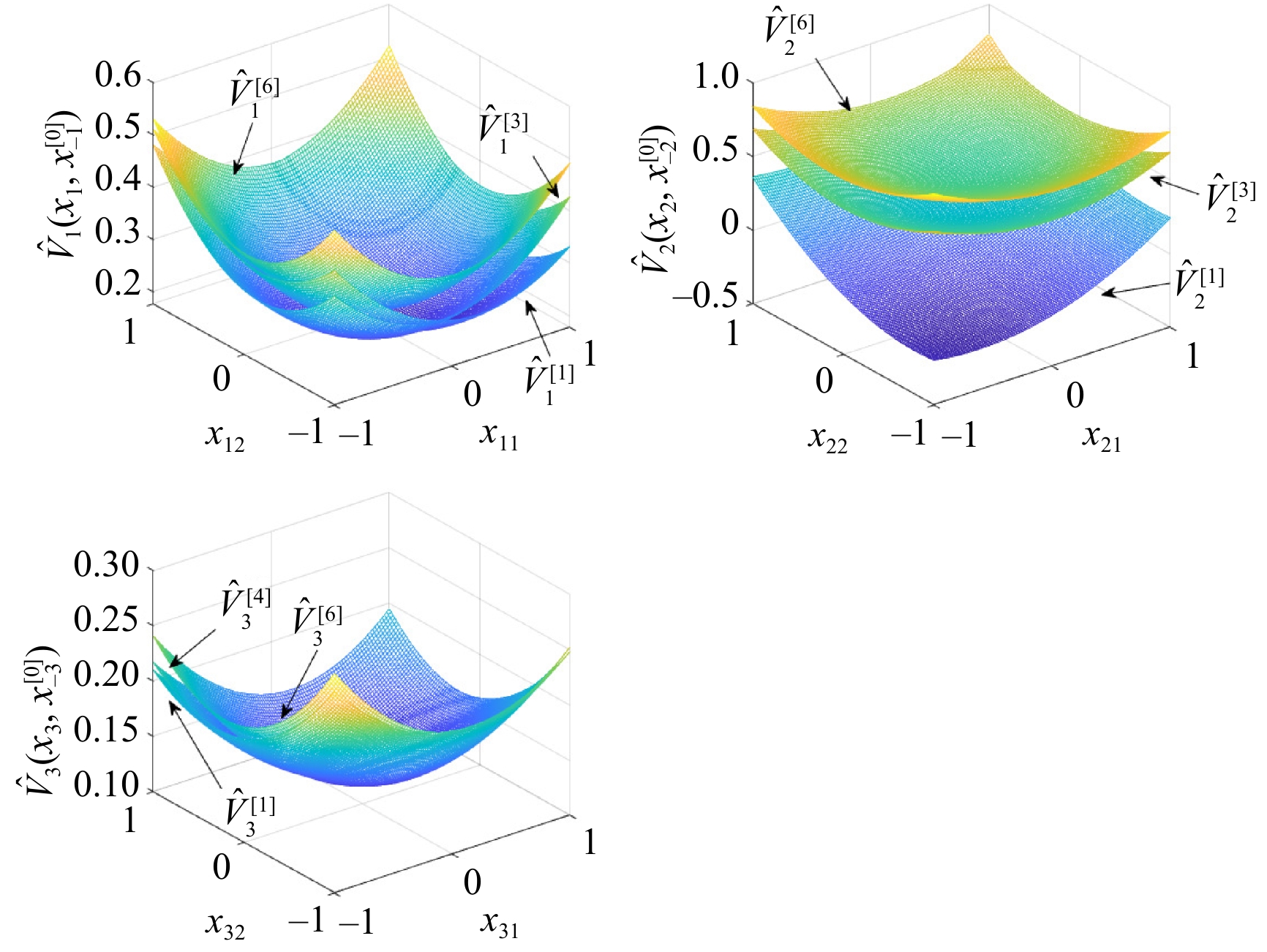
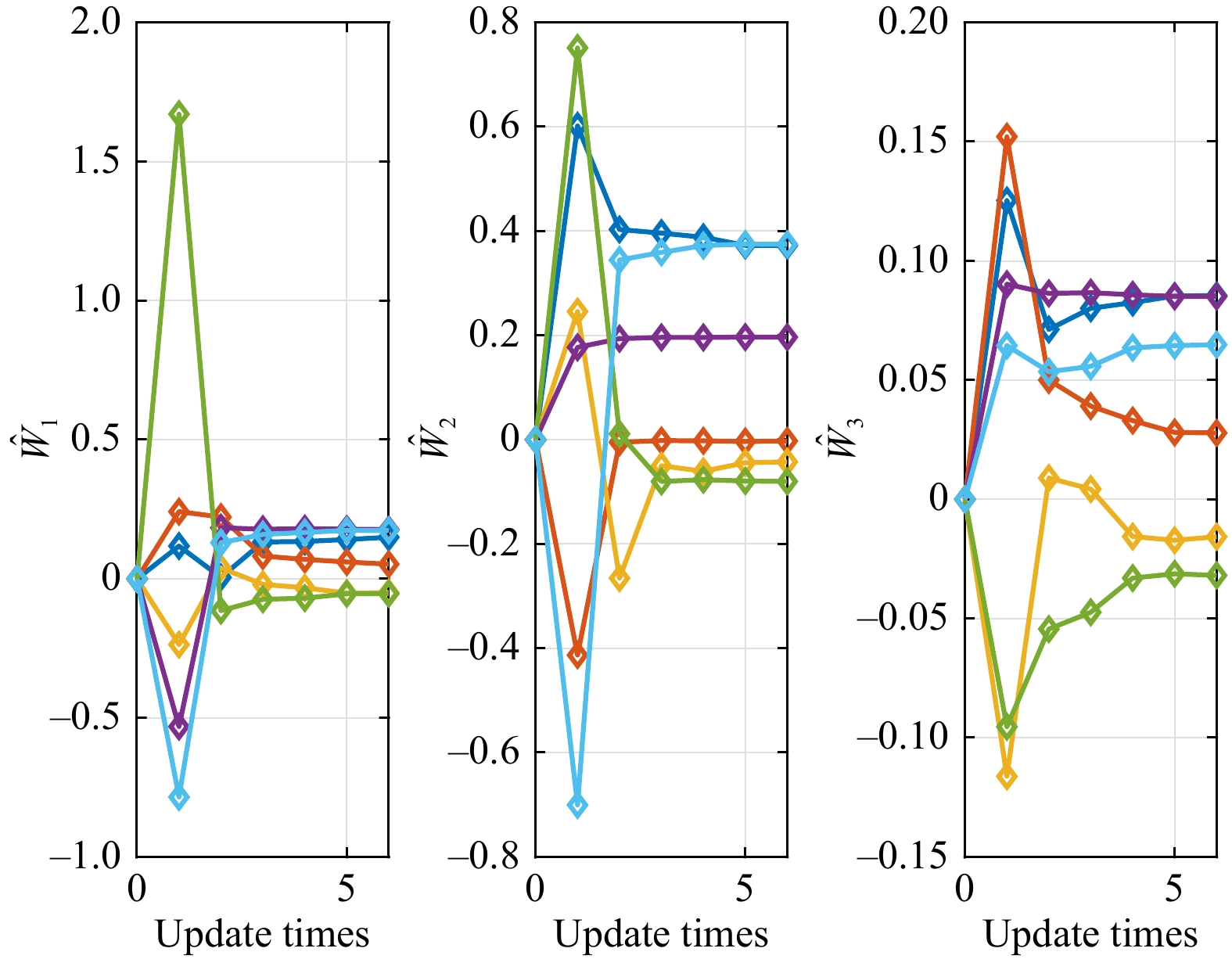
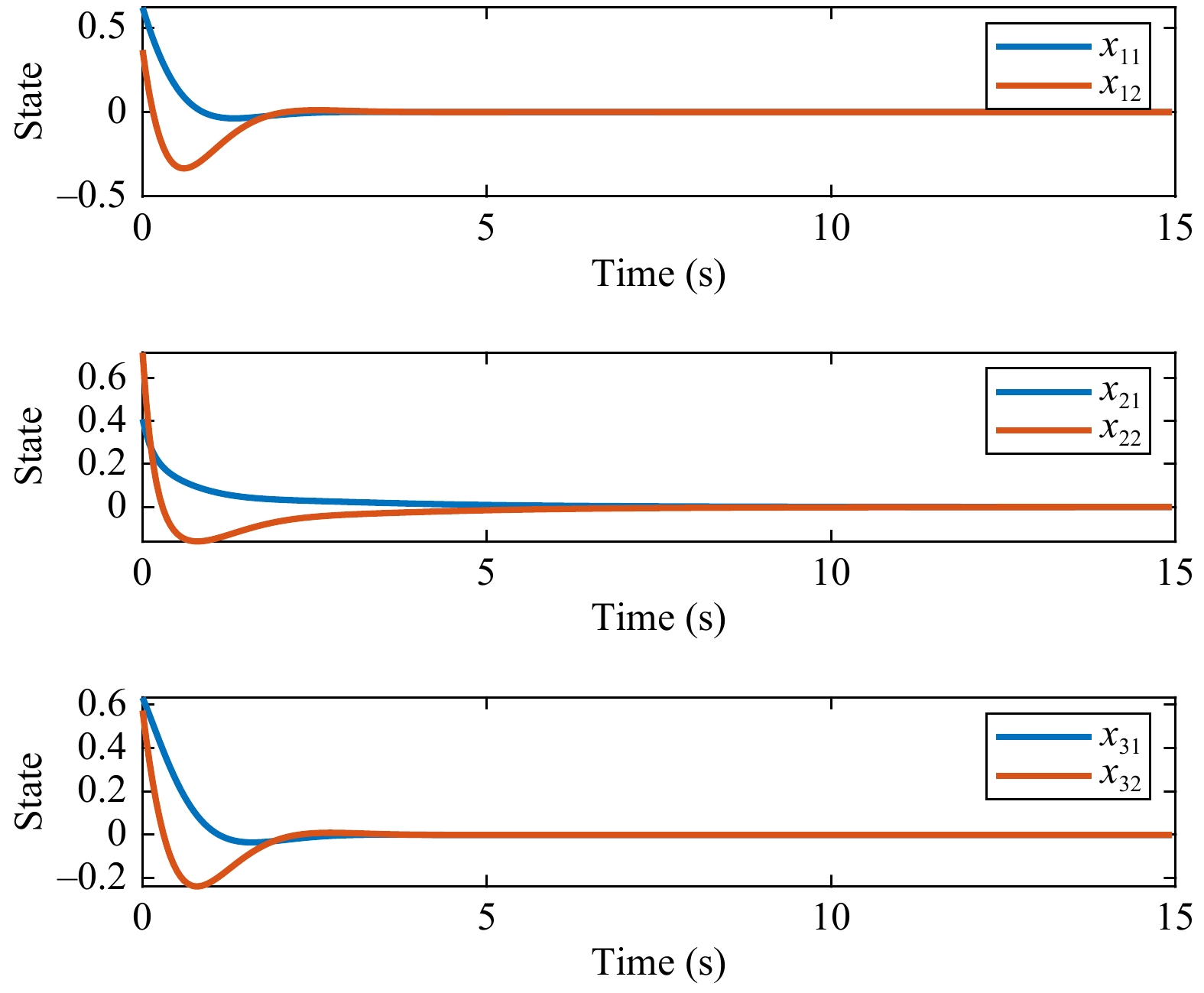
This paper presents a novel cooperative value iteration (VI)-based adaptive dynamic programming method for multi-player differential game models with a convergence proof. The players are divided into two groups in the learning process and adapt their policies sequentially. Our method removes the dependence of admissible initial policies, which is one of the main drawbacks of the PI-based frameworks. Furthermore, this algorithm enables the players to adapt their control policies without full knowledge of others’ system parameters or control laws. The efficacy of our method is illustrated by three examples.

| [1] |
P. J. Werbos, “Approximate dynamic programming for real-time control and neural modeling,” Handbook of Intelligent Control, 1992.
|
| [2] |
G. Zhu, X. Li, R. Sun, Y. Yang, and P. Zhang, “Policy iteration for optimal control of discrete-time time-varying nonlinear systems,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 3, pp. 781–791, 2023. doi: 10.1109/JAS.2023.123096
|
| [3] |
M. Ha, D. Wang, and D. Liu, “Discounted iterative adaptive critic designs with novel stability analysis for tracking control,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 7, pp. 1262–1272, 2022. doi: 10.1109/JAS.2022.105692
|
| [4] |
F. Ali, I. Raffaele, T. Massimo, and N. Joshua, “Approximate dynamic programming for stochastic resource allocation problems,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 4, pp. 975–990, 2020. doi: 10.1109/JAS.2020.1003231
|
| [5] |
K. G. Vamvoudakis, “Non-zero sum Nash Q-learning for unknown deterministic continuous-time linear systems,” Automatica, vol. 61, pp. 274–281, Nov. 2015. doi: 10.1016/j.automatica.2015.08.017
|
| [6] |
Y. Fu and T. Chai, “Online solution of two-player zero-sum games for continuous-time nonlinear systems with completely unknown dynamics,” IEEE Trans. Neural Networks and Learning Systems, vol. 27, no. 12, pp. 2577–2587, 2016. doi: 10.1109/TNNLS.2015.2496299
|
| [7] |
Q. Wei, R. Song, and P. Yan, “Data-driven zero-sum neuro-optimal control for a class of continuous-time unknown nonlinear systems with disturbance using ADP,” IEEE Trans. Neural Networks and Learning Systems, vol. 27, no. 2, pp. 444–458, 2016. doi: 10.1109/TNNLS.2015.2464080
|
| [8] |
R. Song, F. L. Lewis, and Q. Wei, “Off-policy integral reinforcement learning method to solve nonlinear continuous-time multiplayer nonzero-sum games,” IEEE Trans. Neural Networks and Learning Systems, vol. 28, no. 3, pp. 704–713, 2017. doi: 10.1109/TNNLS.2016.2582849
|
| [9] |
Q. Wei, D. Liu, Q. Lin, and R. Song, “Adaptive dynamic programming for discrete-time zero-sum games,” IEEE Trans. Neural Networks and Learning Systems, vol. 29, no. 4, pp. 957–969, 2018. doi: 10.1109/TNNLS.2016.2638863
|
| [10] |
K. G. Vamvoudakis and F. L. Lewis, “Online solution of nonlinear two-player zero-sum games using synchronous policy iteration,” Int. Journal of Robust and Nonlinear Control, vol. 22, pp. 1460–1483, sep. 2012. doi: 10.1002/rnc.1760
|
| [11] |
H. Zhang, H. Jiang, C. Luo, and G. Xiao, “Discrete-time nonzero-sum games for multiplayer using policy-iteration-based adaptive dynamic programming algorithms,” IEEE Trans. Cybernetics, vol. 47, pp. 3331–3340, Oct. 2017. doi: 10.1109/TCYB.2016.2611613
|
| [12] |
T. Bian and Z.-P. Jiang, “Reinforcement learning and adaptive optimal control for continuous-time nonlinear systems: A value iteration approach,” IEEE Trans. Neural Networks and Learning Systems, vol. 33, no. 7, pp. 2781–2790, 2022. doi: 10.1109/TNNLS.2020.3045087
|
| [13] |
G. Xiao, H. Zhang, K. Zhang, and Y. Wen, “Value iteration based integral reinforcement learning approach for H1 controller design of continuous-time nonlinear systems,” Neurocomputing, vol. 285, pp. 51–59, 2018. doi: 10.1016/j.neucom.2018.01.029
|
| [14] |
G. Xiao, R. Zhang, T. Zou, S. Li, B. Zhou, and C. Shen, “Value iteration algorithm for nonlinear continuous-time nonzero-sum games,” in Proc. Int. Conf. Security, Pattern Analysis, and Cybernetics, pp. 105–108, 2021.
|
| [15] |
D. Liu, H. Li, and D. Wang, “Online synchronous approximate optimal learning algorithm for multi-player non-zero-sum games with unknown dynamics,” IEEE Trans. Systems,Man,and Cybernetics: Systems, vol. 44, pp. 1015–1027, 2014. doi: 10.1109/TSMC.2013.2295351
|
| [16] |
D. Zhao, Q. Zhang, D. Wang, and Y. Zhu, “Experience replay for optimal control of nonzero-sum game systems with unknown dynamics,” IEEE Trans. Cybernetics, vol. 46, pp. 854–865, 2016. doi: 10.1109/TCYB.2015.2488680
|
| [17] |
J. Zhao, “Adaptive dynamic programming and optimal control of unknown multiplayer systems based on game theory,” IEEE Access, vol. 10, pp. 77695–77706, 2022.
|
| [18] |
J. Zhao, “Data-driven adaptive dynamic programming for optimal control of continuous-time multicontroller systems with unknown dynamics,” IEEE Access, vol. 10, pp. 41503–41511, 2022. doi: 10.1109/ACCESS.2022.3168032
|
| [19] |
D. Cappello and T. Mylvaganam, “Distributed control of multi-agent systems via linear quadratic differential games with partial information,” in 2018 IEEE Conf. on Decision and Control (CDC), pp. 4565–4570, 2018.
|
| [20] |
K. A. Cavalieri, N. Satak, and J. E. Hurtado, Incomplete Information Pursuit-Evasion Games With Uncertain Relative Dynamics. AIAA SciTech Forum, American Institute of Aeronautics and Astronautics, 2014. doi: 10.2514/6.2014-0971.
|
| [21] |
F. Köpf, S. Ebbert, M. Flad, and S. Hohmann, “Adaptive dynamic programming for cooperative control with incomplete information,” in Proc. IEEE Int. Conf. Systems, Man, and Cybernetics, pp. 2632–2638, 2018.
|
| [22] |
K. G. Vamvoudakis, F. L. Lewis, and G. R. Hudas, “Multi-agent differential graphical games: Online adaptive learning solution for synchronization with optimality,” Automatica, vol. 48, no. 8, pp. 1598–1611, 2012. doi: 10.1016/j.automatica.2012.05.074
|
| [23] |
R. Song, Q. Wei, and Q. Li, Adaptive Dynamic Programming: Single and Multiple Controllers. Springer Singapore, 2019.
|
Figures(9)






 DownLoad:
DownLoad: