A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 11
Issue 1
Volume 11
Issue 1
IEEE/CAA Journal of Automatica Sinica
| Citation: | Z. Wang, Y. Wang, and Z. Kowalczuk, “Adaptive optimal discrete-time output-feedback using an internal model principle and adaptive dynamic programming,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 1, pp. 131–140, Jan. 2024. doi: 10.1109/JAS.2023.123759

|

| [1] |
B. A. Francis, “The linear multivariable regulator problem,” SIAM J. Control Optimiz., vol. 15, no. 3, pp. 486–505, Jul. 1977. doi: 10.1137/0315033
|
| [2] |
Y. Jiang, W. Gao, J. Na, D. Zhang, T. T. Hämäläinen, V. Stojanovice, and F. L. Lewis, “Value iteration and adaptive optimal output regulation with assured convergence rate,” Control. Eng. Pract., vol. 121, p. 105042, Apr. 2022. doi: 10.1016/j.conengprac.2021.105042
|
| [3] |
Z. Hou and X. Bu, “Model free adaptive control with data dropouts,” Expert Syst. Appl., vol. 38, no. 8, pp. 10709–10717, Aug. 2011. doi: 10.1016/j.eswa.2011.01.158
|
| [4] |
J. Fan, Q. Wu, Y. Jiang, T. Chai, and F. L. Lewis, “Model-free optimal output regulation for linear discrete-time lossy networked control systems,” IEEE Trans. Syst.,Man,Cybern. B,Cybern., vol. 50, no. 11, pp. 4033–4042, Nov. 2020. doi: 10.1109/TSMC.2019.2946382
|
| [5] |
J Kluska and T. Żabiński, “PID-like adaptive fuzzy controller design based on absolute stability criterion,” IEEE Trans. Fuzzy Syst., vol. 28, no. 3, pp. 523–533, Mar. 2020. doi: 10.1109/TFUZZ.2019.2908772
|
| [6] |
Y. Mi, Y. Song, Y. Fu, and C. Wang, “The adaptive sliding mode reactive power control strategy for wind-diesel power system based on sliding mode observer,” IEEE Trans. Sustain. Energy, vol. 11, no. 4, pp. 2241–2251, Oct. 2020. doi: 10.1109/TSTE.2019.2952142
|
| [7] |
X. Yu, Z. Hou, M. M. Polycarpou, and L. Duan, “Data-driven iterative learning control for nonlinear discrete-time MIMO systems,” IEEE Trans. Neural Netw. Learn. Syst., vol. 32, no. 2, pp. 1136–1148, Mar. 2021.
|
| [8] |
S. Xu, J. Liu, C. Yang, X. Wu, and T Xu, “A learning-based stable servo control strategy using broad learning system applied for microrobotic control,” IEEE Trans. Cybern., vol. 52, no. 12, pp. 13727–13737, Dec. 2022. doi: 10.1109/TCYB.2021.3121080
|
| [9] |
S. Peng, “A generalized dynamic programming principle and Hamilton-Jacobi-Bellman equation,” Stochastics: An Int. J. Probability and Stochastic Processes, vol. 38, no. 2, pp. 119–134, 1992.
|
| [10] |
S. J. Bradtke, B. E. Ydstie, and A. G. Barto, “Adaptive linear quadratic control using policy iteration,” in Proc. Amer. Control Conf., vol. 24, 1994, pp. 3475–3479.
|
| [11] |
F. L. Lewis and K. G. Vamvoudakis, “Reinforcement learning for partially observable dynamic processes: Adaptive dynamic programming using measured output data,” IEEE Trans. Syst.,Man,Cybern. B,Cybern., vol. 41, no. 1, pp. 14–25, Feb. 2011. doi: 10.1109/TSMCB.2010.2043839
|
| [12] |
Y. Jiang and Z.-P. Jiang, “Global adaptive dynamic programming for continuous-time nonlinear systems,” IEEE Trans. Autom. Control, vol. 60, no. 11, pp. 2917–2929, Nov. 2015. doi: 10.1109/TAC.2015.2414811
|
| [13] |
J. Lu, Q. Wei, and F.-Y. Wang, “Parallel control for optimal tracking via adaptive dynamic programming,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 6, pp. 1662–1674, Nov. 2020. doi: 10.1109/JAS.2020.1003426
|
| [14] |
D. Liu, S. Xue, B. Zhao, B. Luo, and Q. Wei, “Adaptive dynamic programming for control: A survey and recent advances,” IEEE Trans. Syst.,Man,Cybern. B,Cybern., vol. 51, no. 1, pp. 142–160, Jan. 2021. doi: 10.1109/TSMC.2020.3042876
|
| [15] |
X. Yang and H. He, “Adaptive dynamic programming for decentralized stabilization of uncertain nonlinear large-scale systems with mismatched interconnections,” IEEE Trans. Syst.,Man,Cybern. B,Cybern., vol. 50, no. 8, pp. 142–160, Aug. 2020.
|
| [16] |
Z. Shi and Z. Wang, “Optimal control for a class of complex singular system based on adaptive dynamic programming,” IEEE/CAA J. Autom. Sinica, vol. 6, no. 1, pp. 188–197, Jan. 2019. doi: 10.1109/JAS.2019.1911342
|
| [17] |
Y. Jiang and Z.-P. Jiang, “Computational adaptive optimal control for continuous-time linear systems with completely unknown dynamics,” Automatica, vol. 48, no. 10, pp. 2699–2704, 2012. doi: 10.1016/j.automatica.2012.06.096
|
| [18] |
Z. Wang, Y. Yu, W. Gao, M. Davari, and C. Deng, “Adaptive, optimal, virtual synchronous generator control of three-phase grid-connected inverters under different grid conditions — An adaptive dynamic programming approach,” IEEE Trans. Ind. Inform., vol. 18, no. 11, pp. 7388–7399, Nov. 2022. doi: 10.1109/TII.2021.3138893
|
| [19] |
Q. Wei, D. Liu, Y. Liu, and R. Song, “Optimal constrained self-learning battery sequential management in microgrid via adaptive dynamic programming,” IEEE/CAA J. Autom. Sinica, vol. 4, no. 2, pp. 168–176, Apr. 2017. doi: 10.1109/JAS.2016.7510262
|
| [20] |
T. Sun and X. M. Sun, “An adaptive dynamic programming scheme for nonlinear optimal control with unknown dynamics and its application to turbofan engines,” IEEE Trans. Ind. Inform., vol. 17, no. 1, pp. 367–376, Jan. 2021. doi: 10.1109/TII.2020.2979779
|
| [21] |
W. Gao and Z.-P. Jiang, “Adaptive dynamic programming and adaptive optimal output regulation of linear systems,” IEEE Trans. Autom. Control, vol. 61, no. 12, pp. 4164–4169, Dec. 2016. doi: 10.1109/TAC.2016.2548662
|
| [22] |
Z. Shi and Z. Wang, “Adaptive output-feedback optimal control for continuous-time linear systems based on adaptive dynamic programming approach,” Neurocomputing, vol. 438, pp. 334–344, May 2021. doi: 10.1016/j.neucom.2021.01.070
|
| [23] |
K. Xie, X. Yu, and W. Lan, “Optimal output regulation for unknown continuous-time linear systems by internal model and adaptive dynamic programming,” Automatica, vol. 146, p. 10564, 2022.
|
| [24] |
H. Modares, F. L. Lewis, and Z.-P. Jiang, “Optimal output-feedback control of unknown continuous-time linear systems using off-policy reinforcement learning,” IEEE Trans. Cybern., vol. 46, no. 1, pp. 2401–2410, Nov. 2016.
|
| [25] |
Y. Jiang, B. Kiumarsi, J. L. Fan, T. Y. Chai, J. N. Li, and F. L. Lewis, “Optimal output regulation of linear discrete-time systems with unknown dynamics using reinforcement learning,” IEEE Trans. Cybern., vol. 50, no. 7, pp. 3147–3156, Jul. 2020. doi: 10.1109/TCYB.2018.2890046
|
| [26] |
Y. Jiang, J. L. Fan, W. Gao, T. Y. Chai, and F. L. Lewis, “Cooperative adaptive optimal output regulation of discrete-time nonlinear multi-agent systems,” Automatica, vol. 121, p. 109149, Nov. 2020. doi: 10.1016/j.automatica.2020.109149
|
| [27] |
X. Cai, C. Wang, S. Liu, G. Chen, and G. Wang, “Optimal output tracking control of linear discrete-time systems with unknown dynamics by adaptive dynamic programming and output feedback,” Int. J. Systems Scienc, vol. 53, no. 16, pp. 3426–3448, Jun. 2022. doi: 10.1080/00207721.2022.2085343
|
| [28] |
J. Zhao, C. Yang, W. Gao, and L. Zhou, “Reinforcement learning and optimal setpoint tracking control of linear systems with external disturbances,” IEEE Trans. Ind. Inform., vol. 18, no. 11, pp. 7770–7779, Nov. 2022. doi: 10.1109/TII.2022.3151797
|
| [29] |
W. Gao and Z.-P. Jiang, “Adaptive optimal output regulation of time-delay systems via measurement feedback,” IEEE Trans. Neural Netw. Learn. Syst., vol. 30, no. 3, pp. 938–945, Dec. 2018.
|
| [30] |
S. Xiong, W. Wang, X. Liu, Z. Chen, and S. Wang, “A novel extended state observer,” ISA Transactions, vol. 58, pp. 309–317, Sept. 2015. doi: 10.1016/j.isatra.2015.07.012
|
| [31] |
W. Gao, Y. Liu, A. Odekunle, Y. Yu, and P. Lu, “Adaptive dynamic programming and cooperative output regulation of discrete-time multi-agent systems,” Int. J. Control Autom. Syst., vol. 16, pp. 2273–2281, 2018. doi: 10.1007/s12555-017-0635-8
|
| [32] |
F. Zhao, W. Gao, Z.-P. Jiang, and T Liu, “Event-triggered adaptive optimal control with output feedback: An adaptive dynamic programming approach,” IEEE Trans. Neural Netw. Learn. Syst., vol. 32, no. 11, pp. 5208–5221, Nov. 2021. doi: 10.1109/TNNLS.2020.3027301
|
| [33] |
J. Huang, Nonlinear Output Regulation: Theory and Applications. SIAM, Philadelphia, PA, 2004.
|
| [34] |
S. A. A. Rizvi and Z. Lin, “Reinforcement learning-based linear quadratic regulation of continuous-time systems using dynamic output feedback,” IEEE Trans. Cybern., vol. 50, no. 11, pp. 4670–4679, Nov. 2020. doi: 10.1109/TCYB.2018.2886735
|
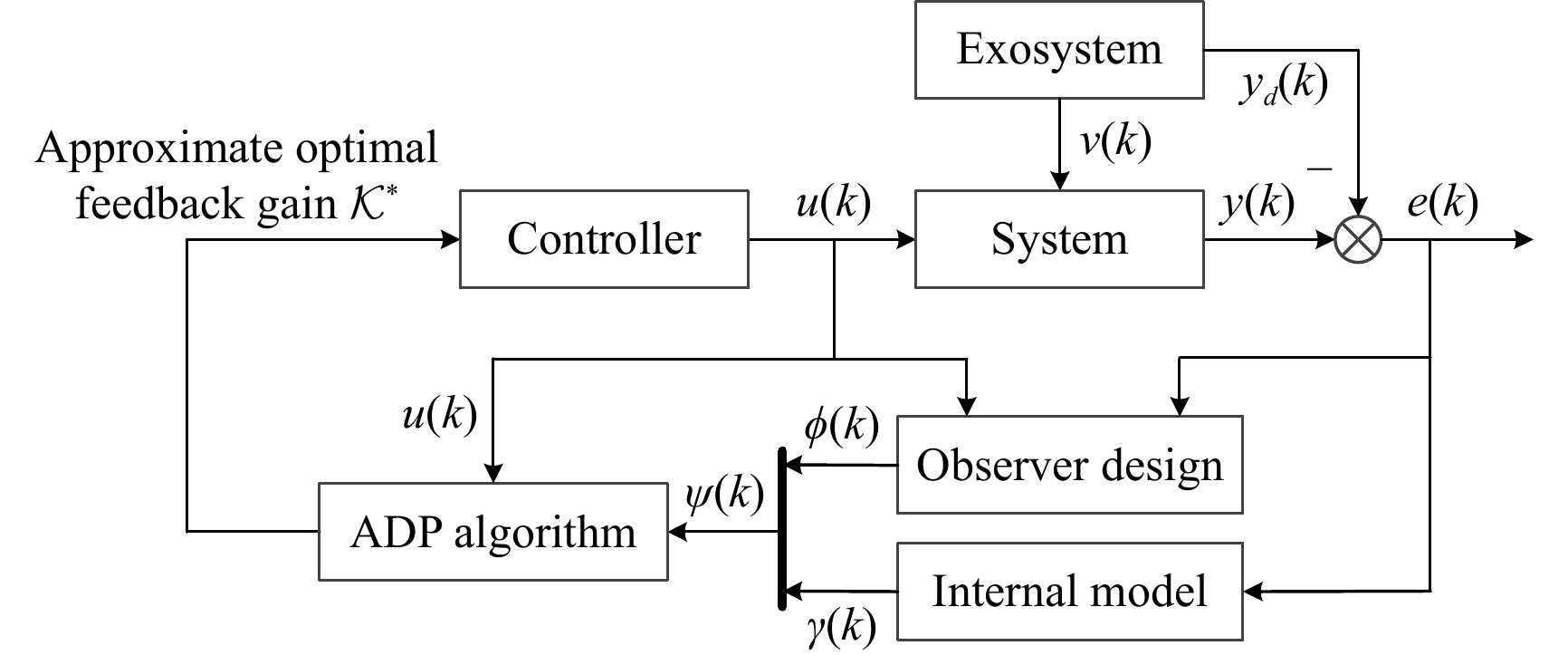
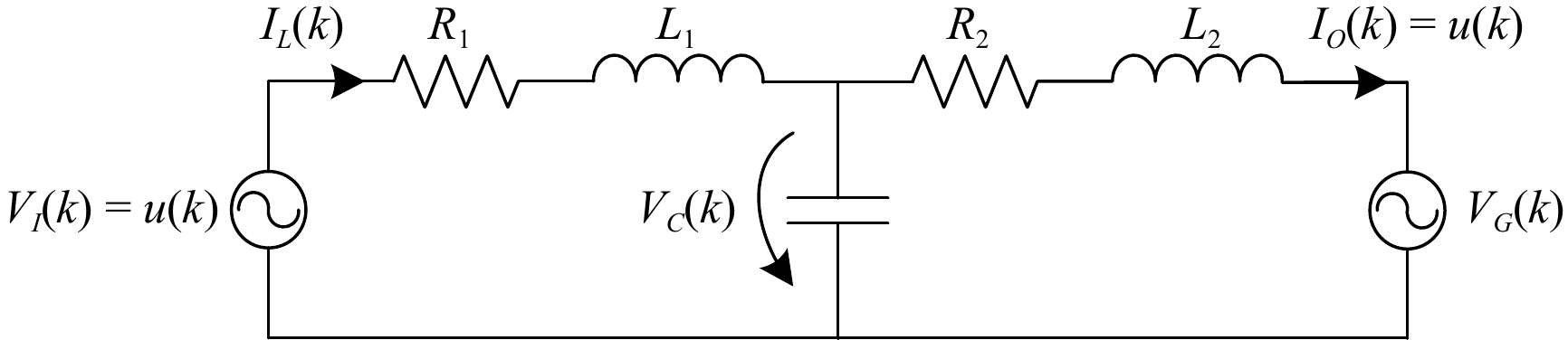
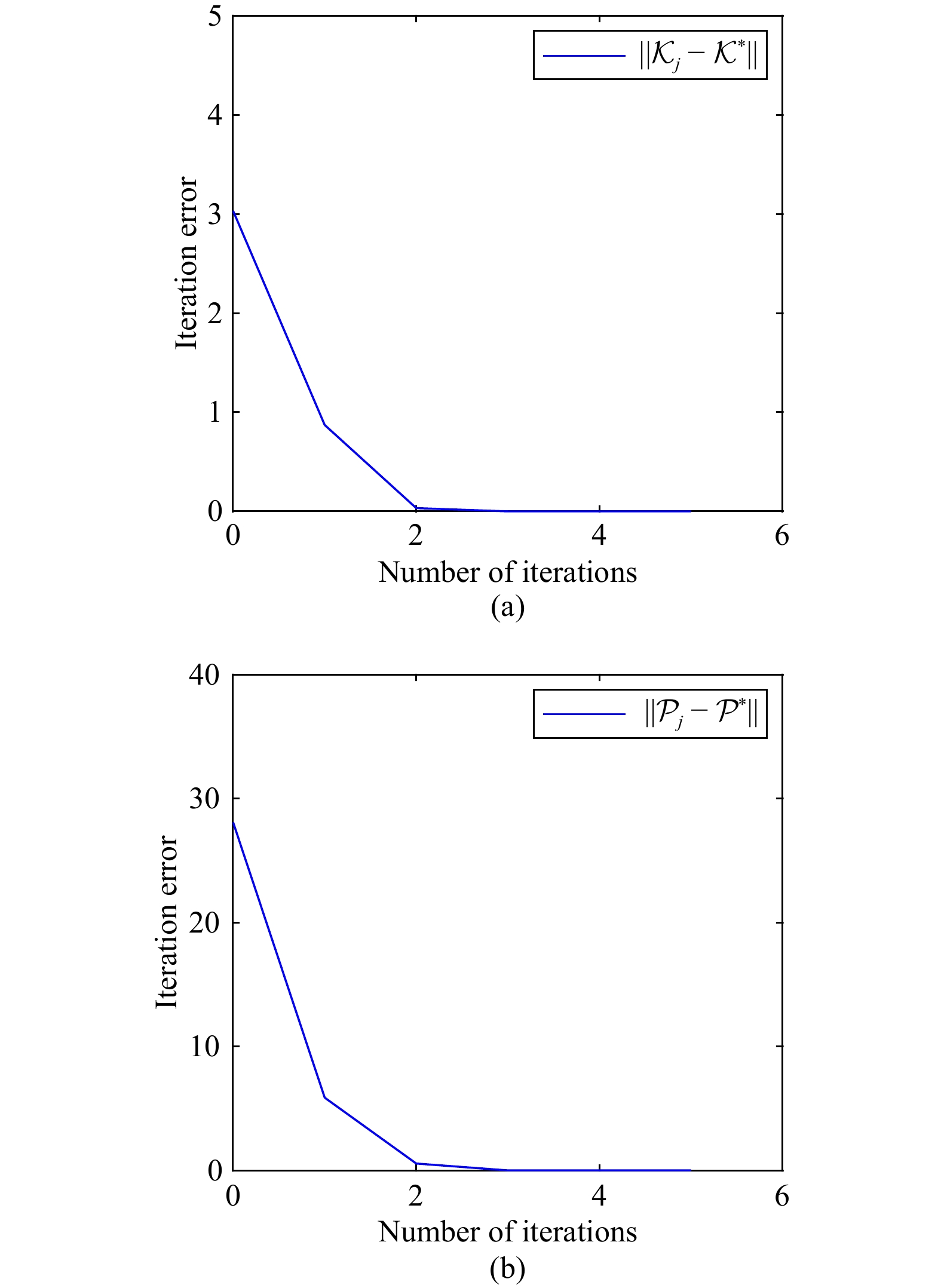
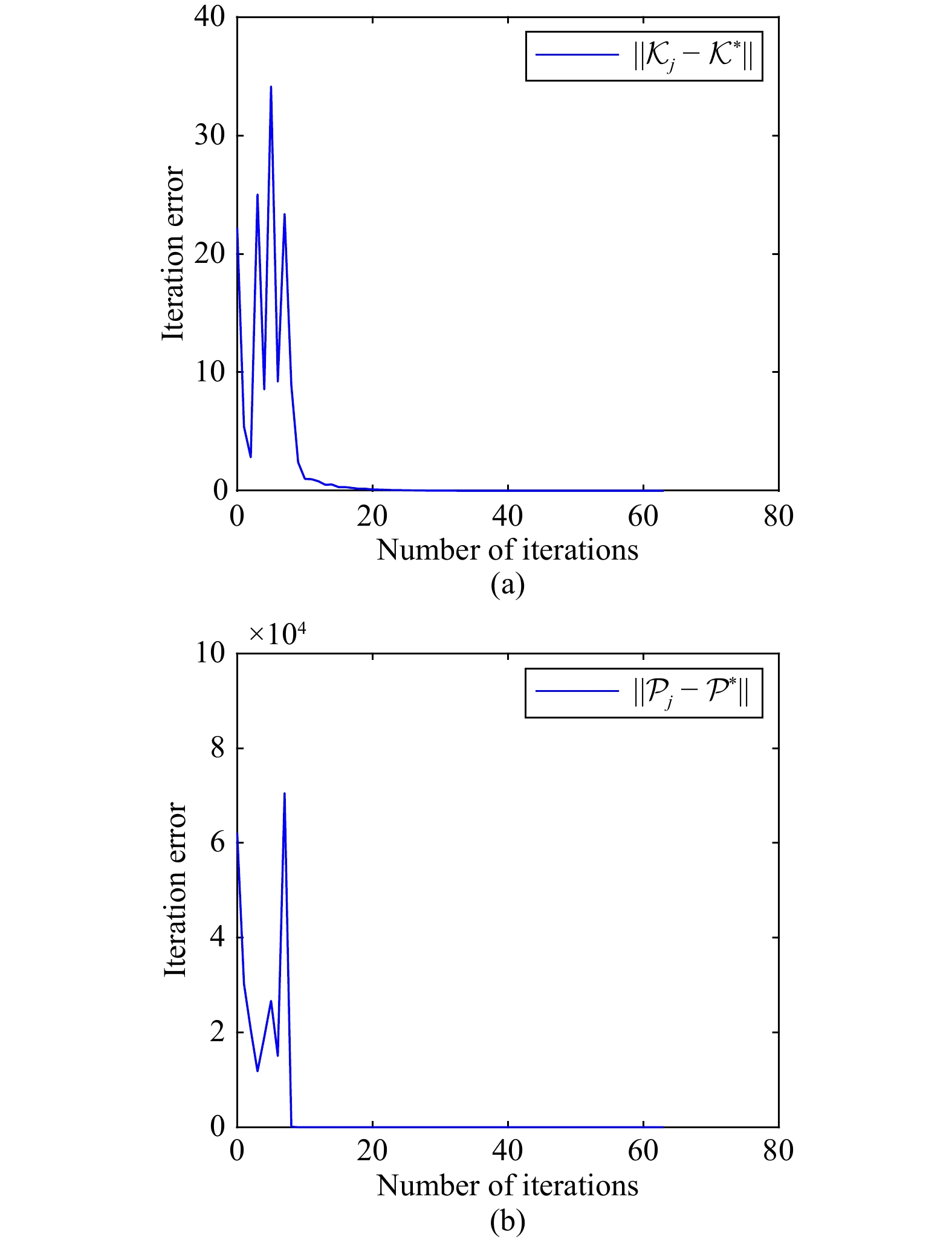
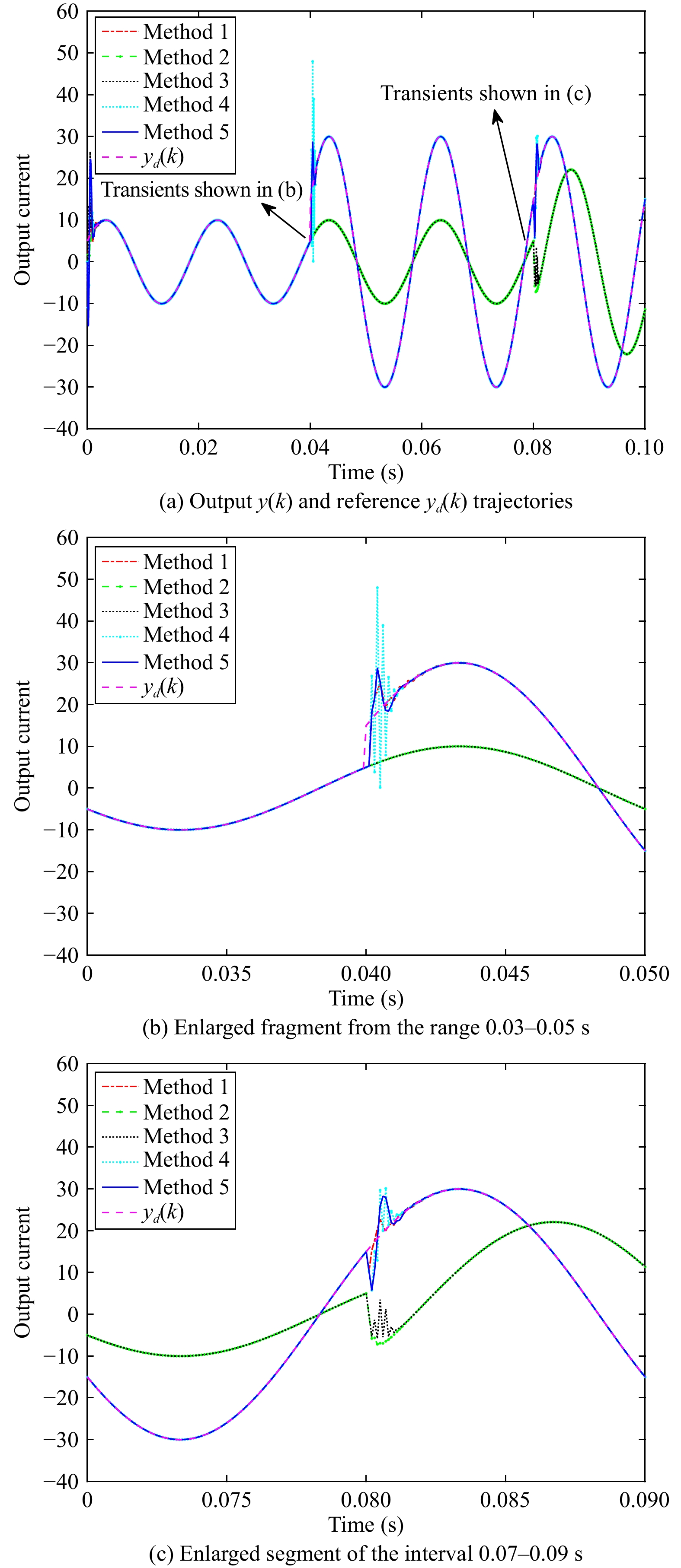
Figures(5)






 DownLoad:
DownLoad: