A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 11
Issue 1
Volume 11
Issue 1
IEEE/CAA Journal of Automatica Sinica
| Citation: | L. D’Alfonso, F. Giannini, G. Franzè, G. Fedele, F. Pupo, and G. Fortino, “Autonomous vehicle platoons in urban road networks: A joint distributed reinforcement learning and model predictive control approach,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 1, pp. 141–156, Jan. 2024. doi: 10.1109/JAS.2023.123705

|
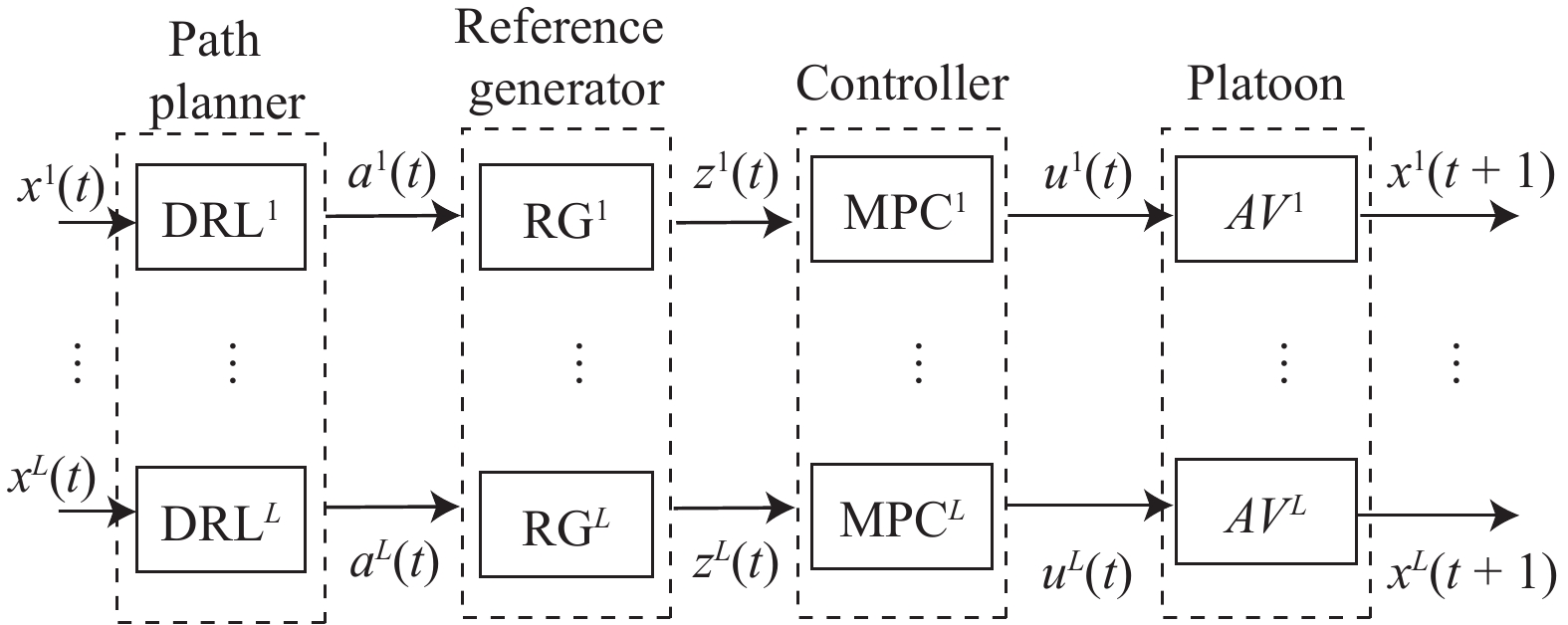
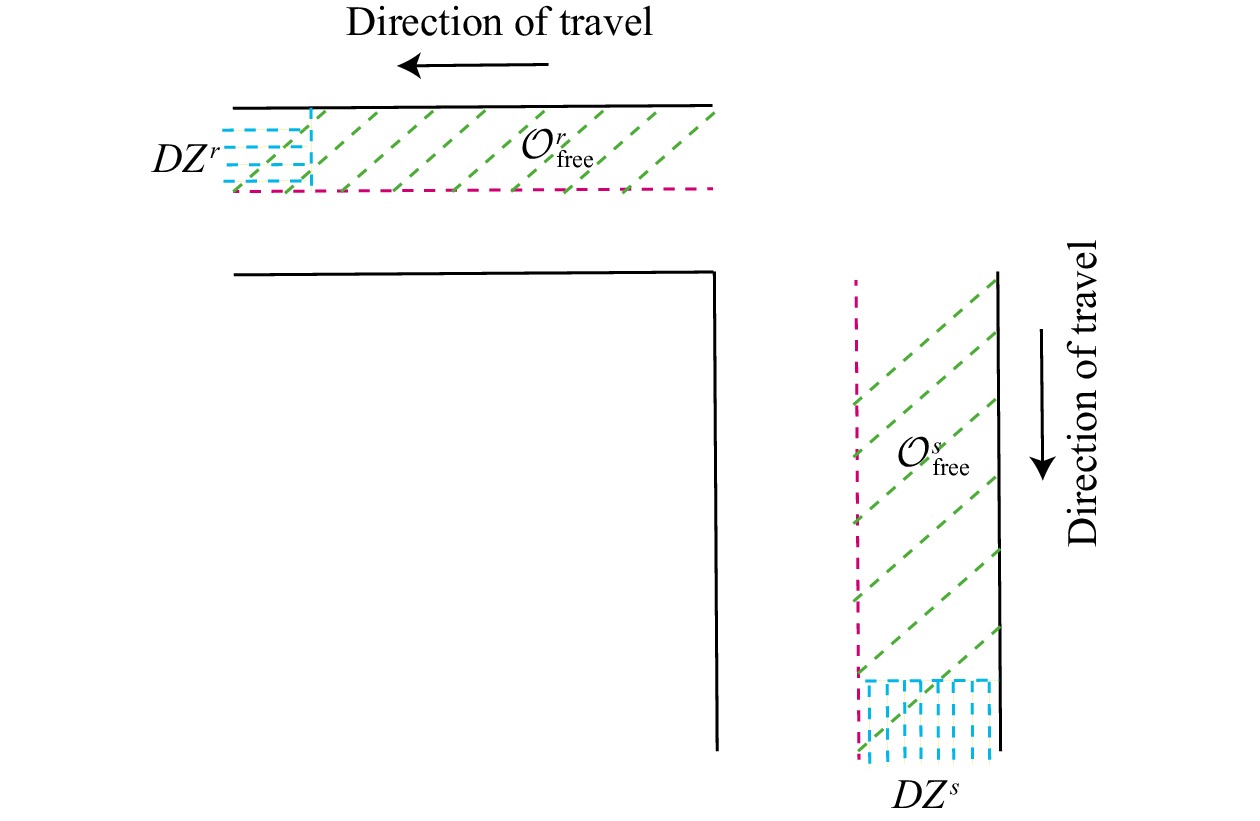
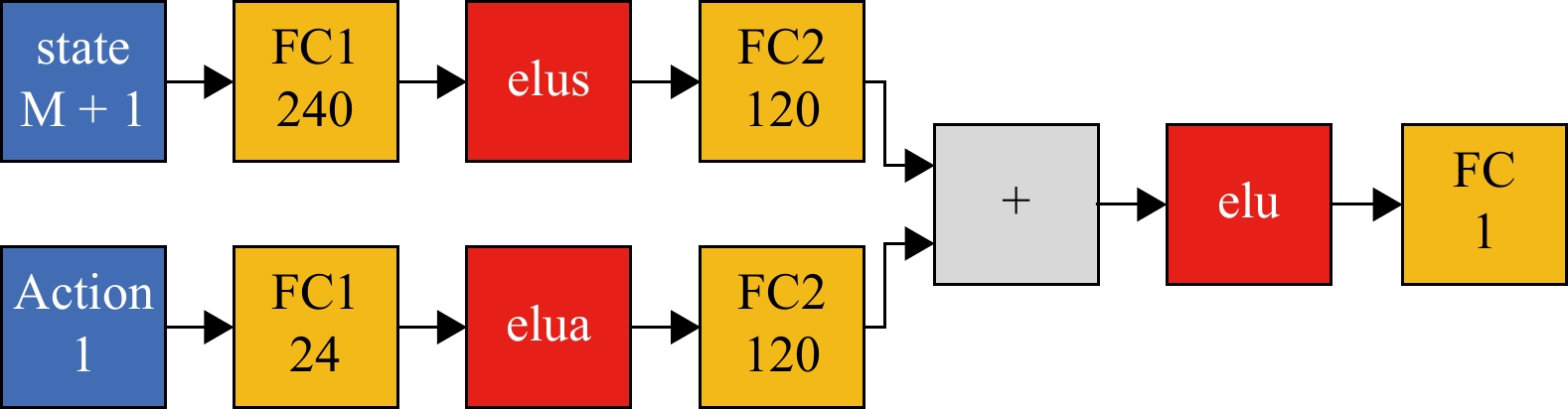
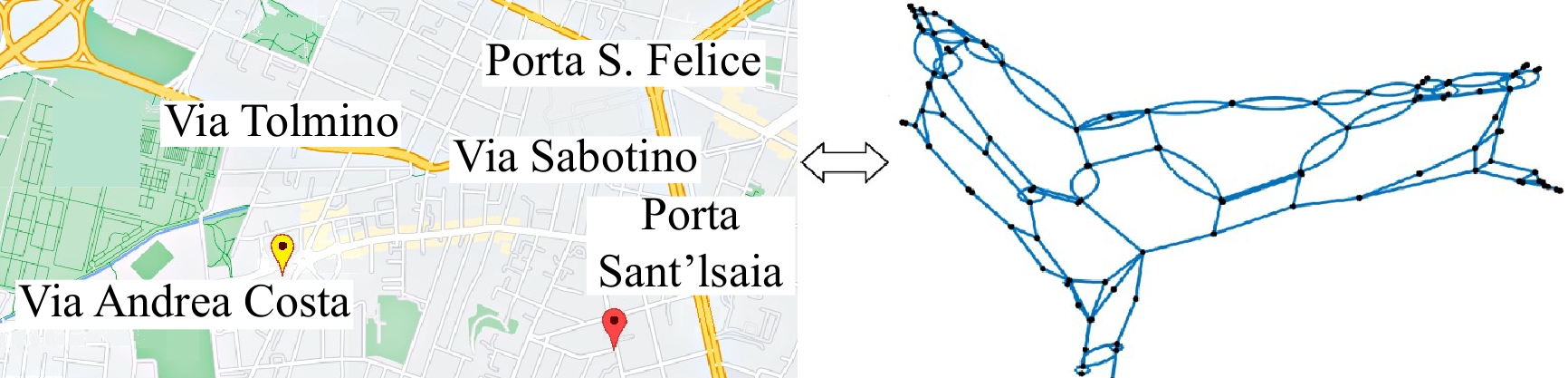
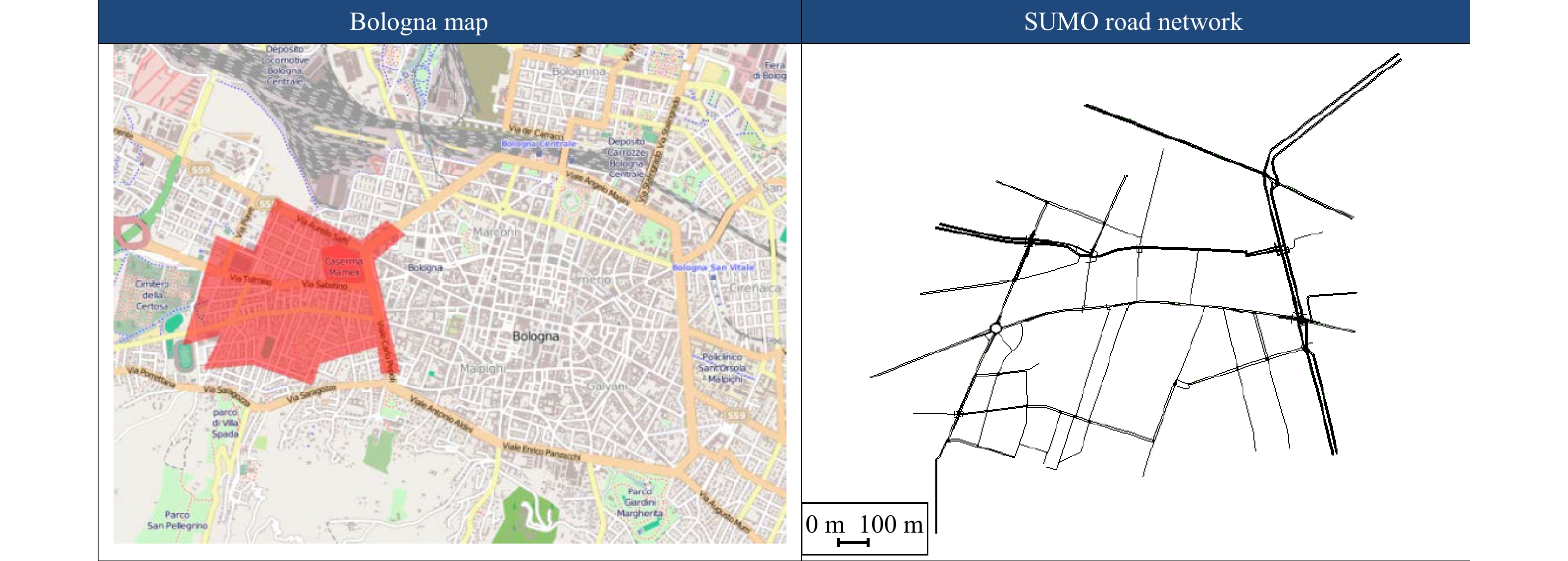
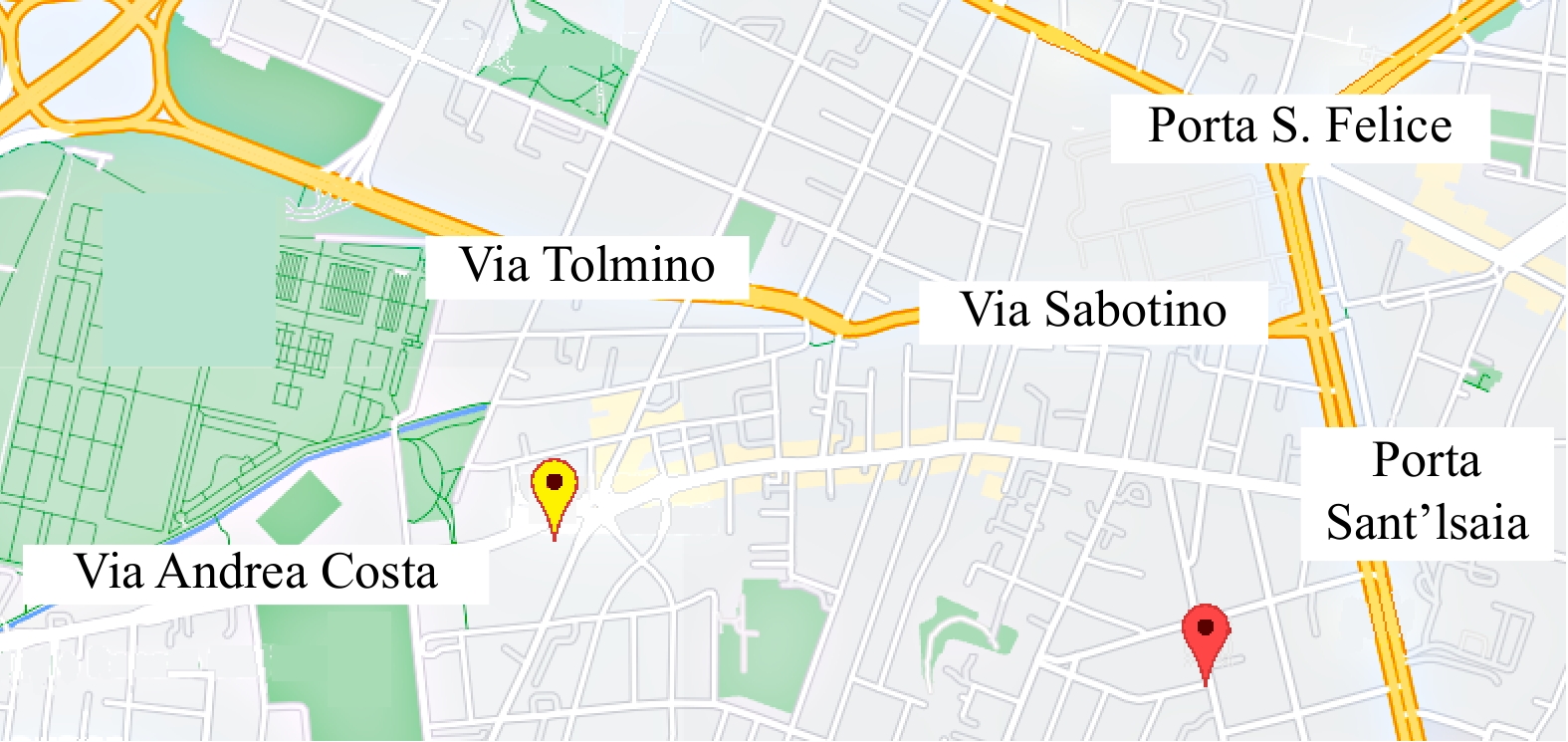
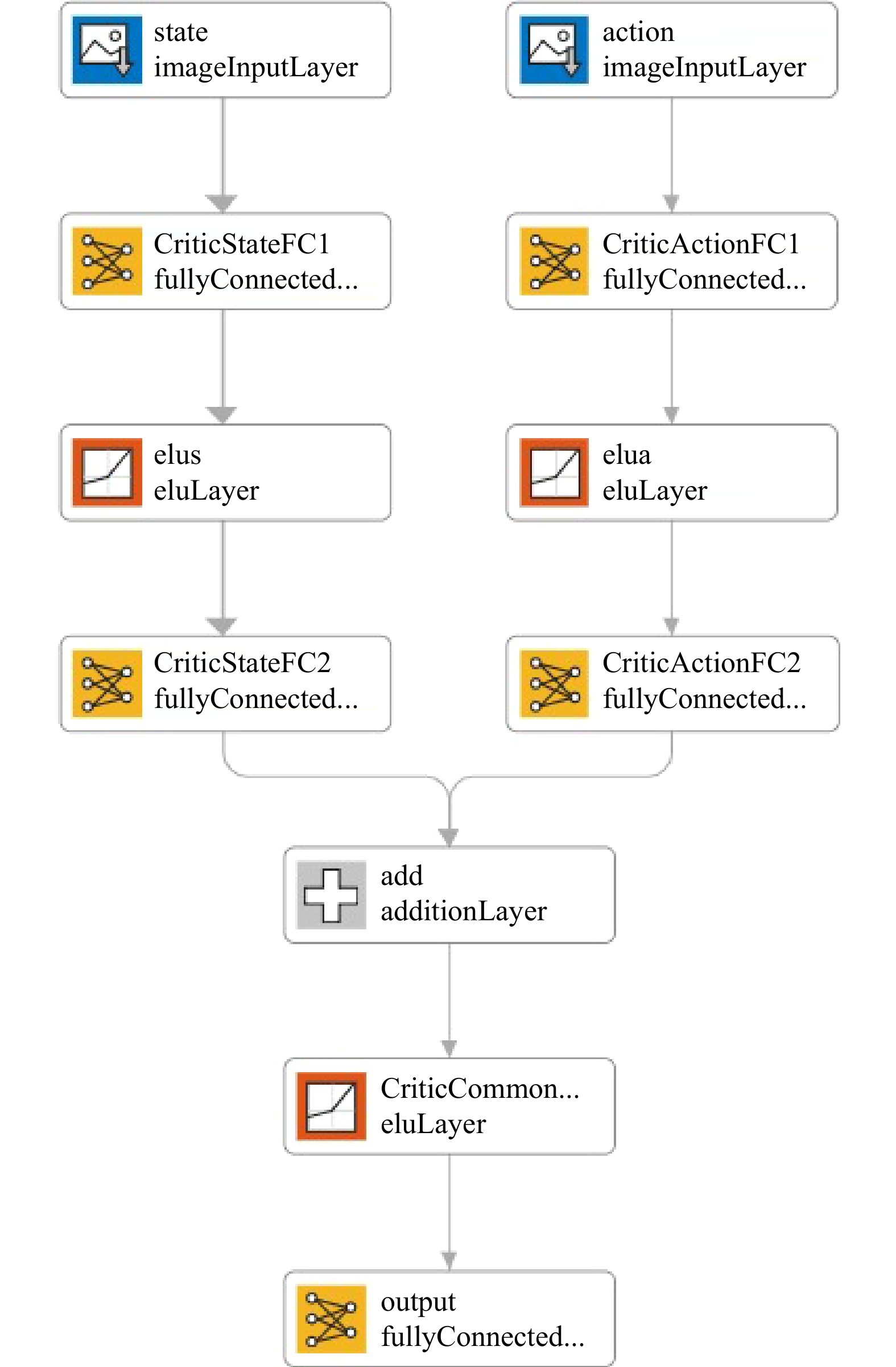
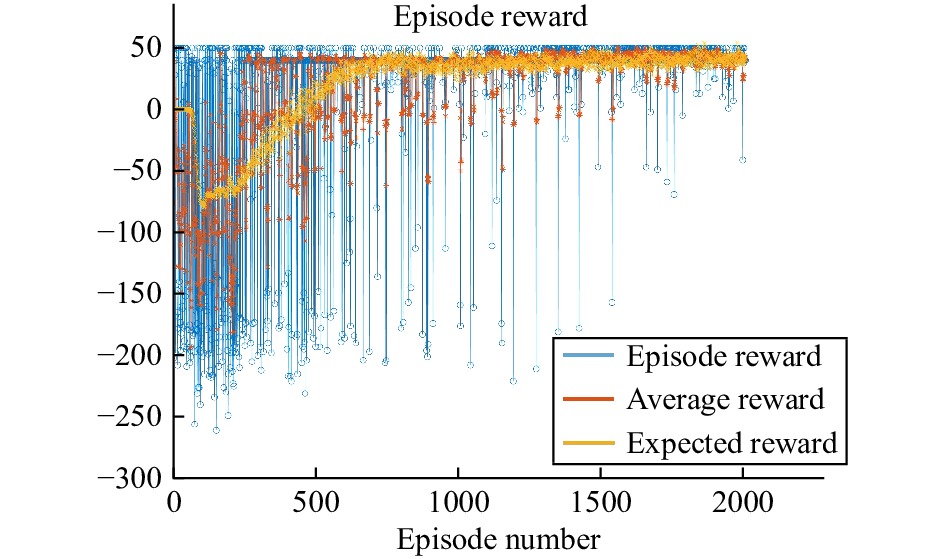
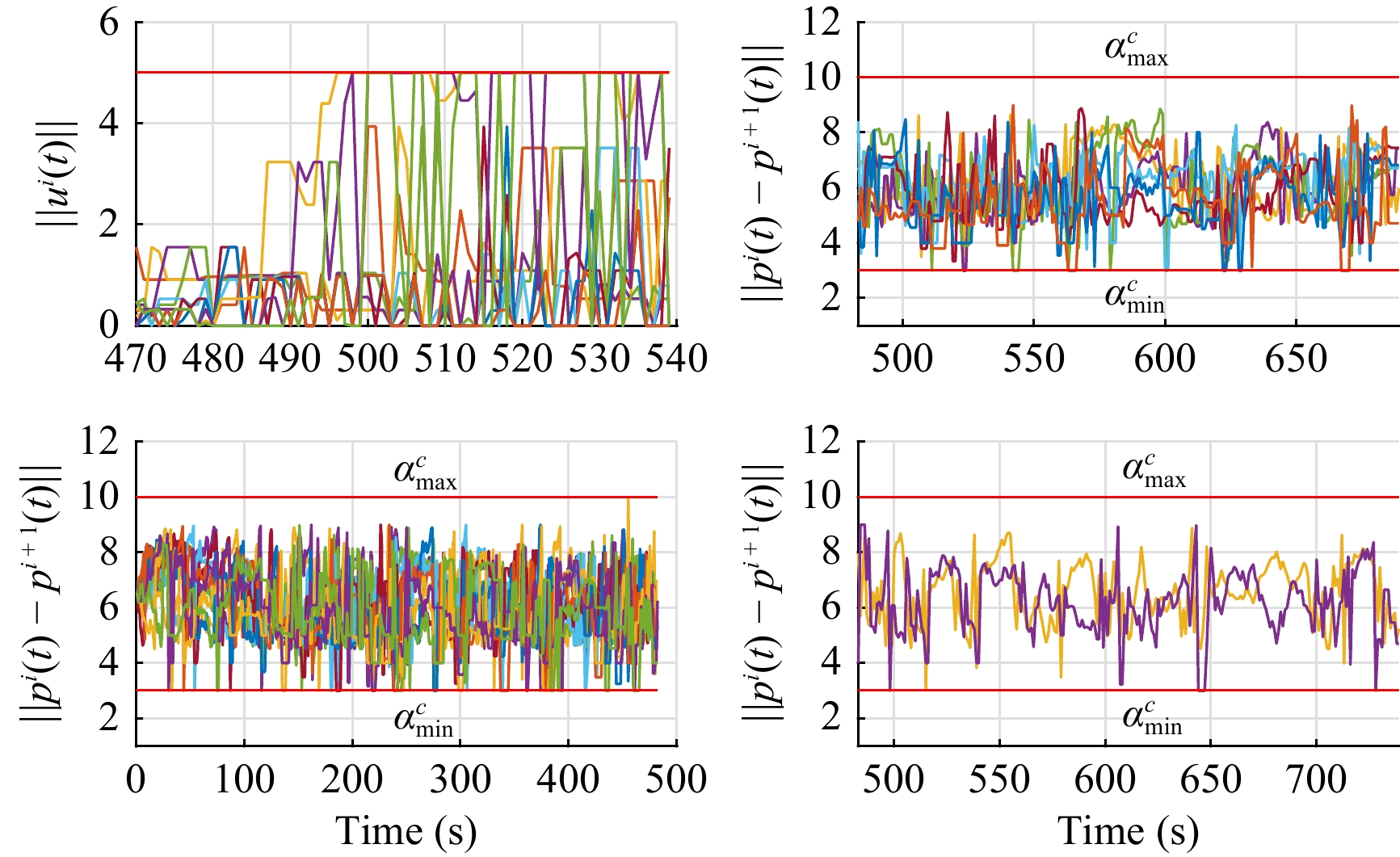
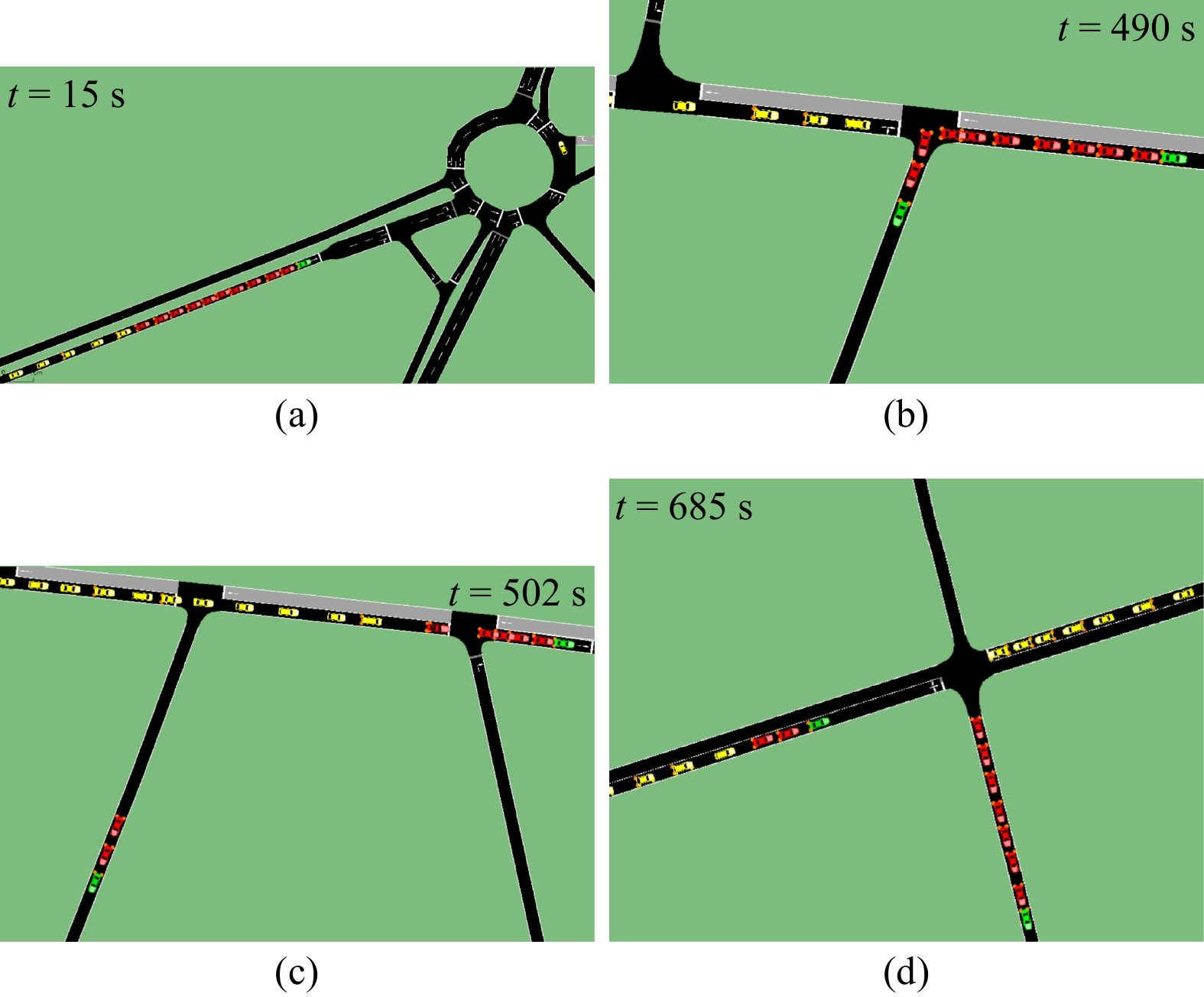
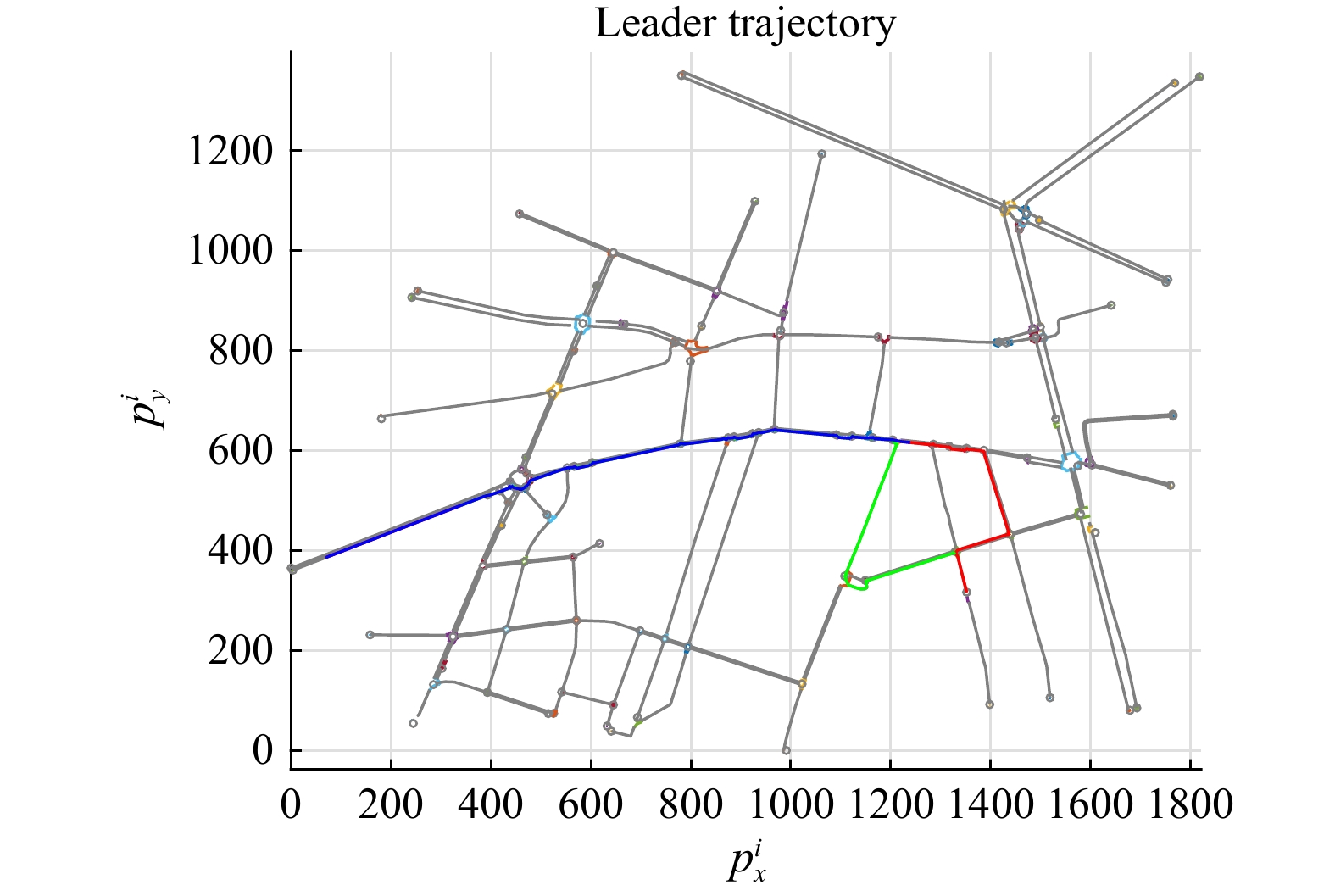
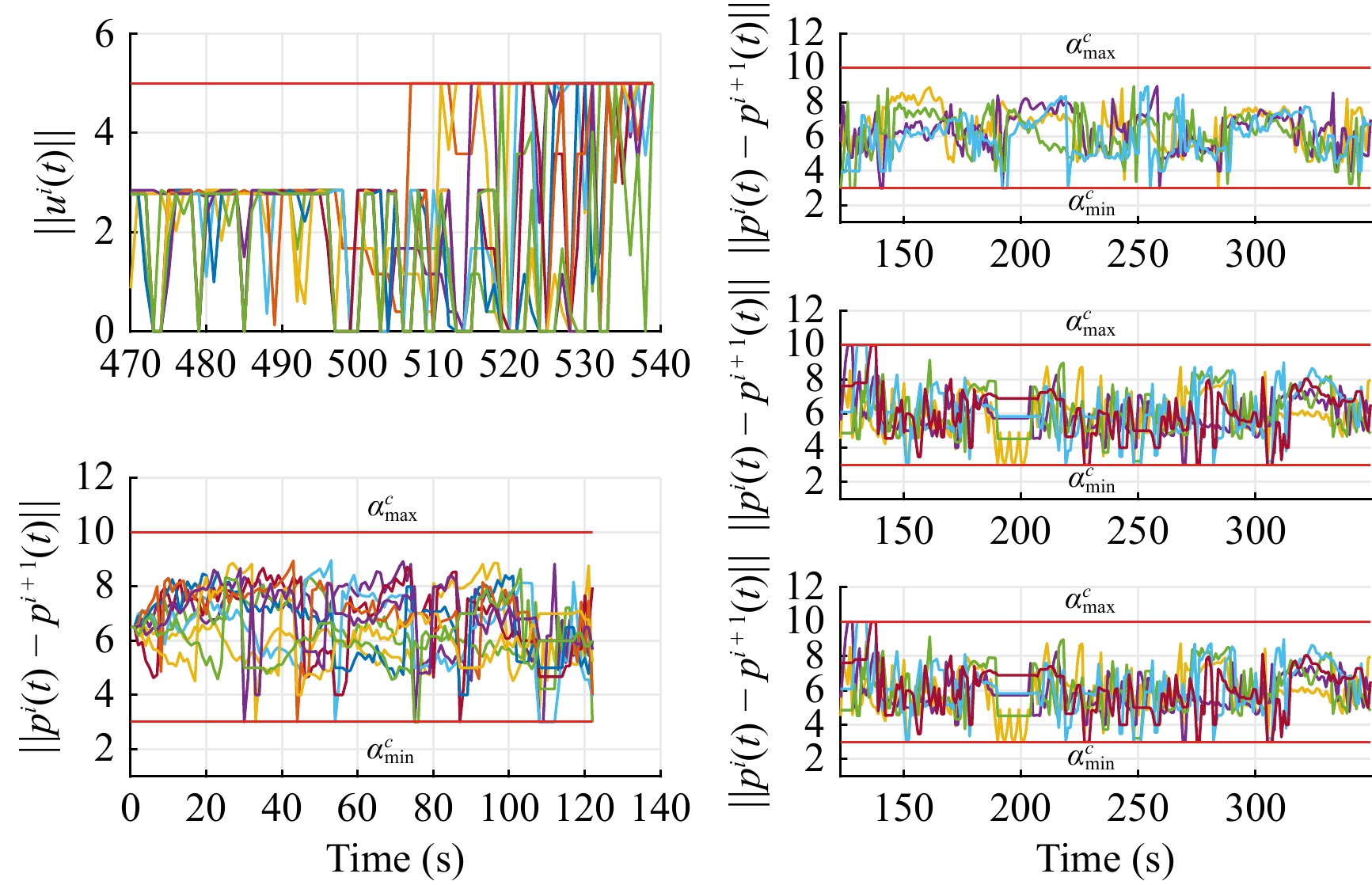
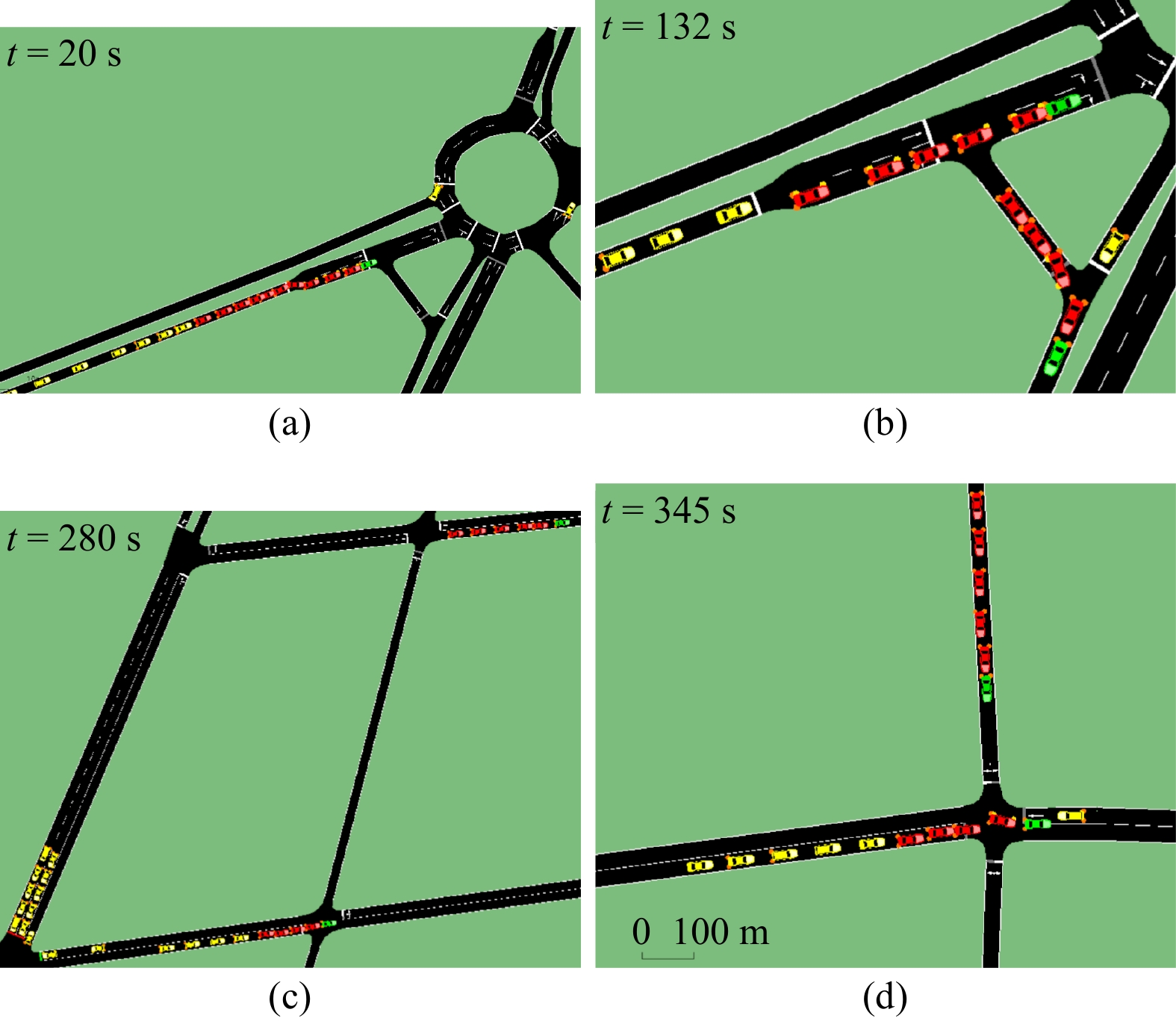
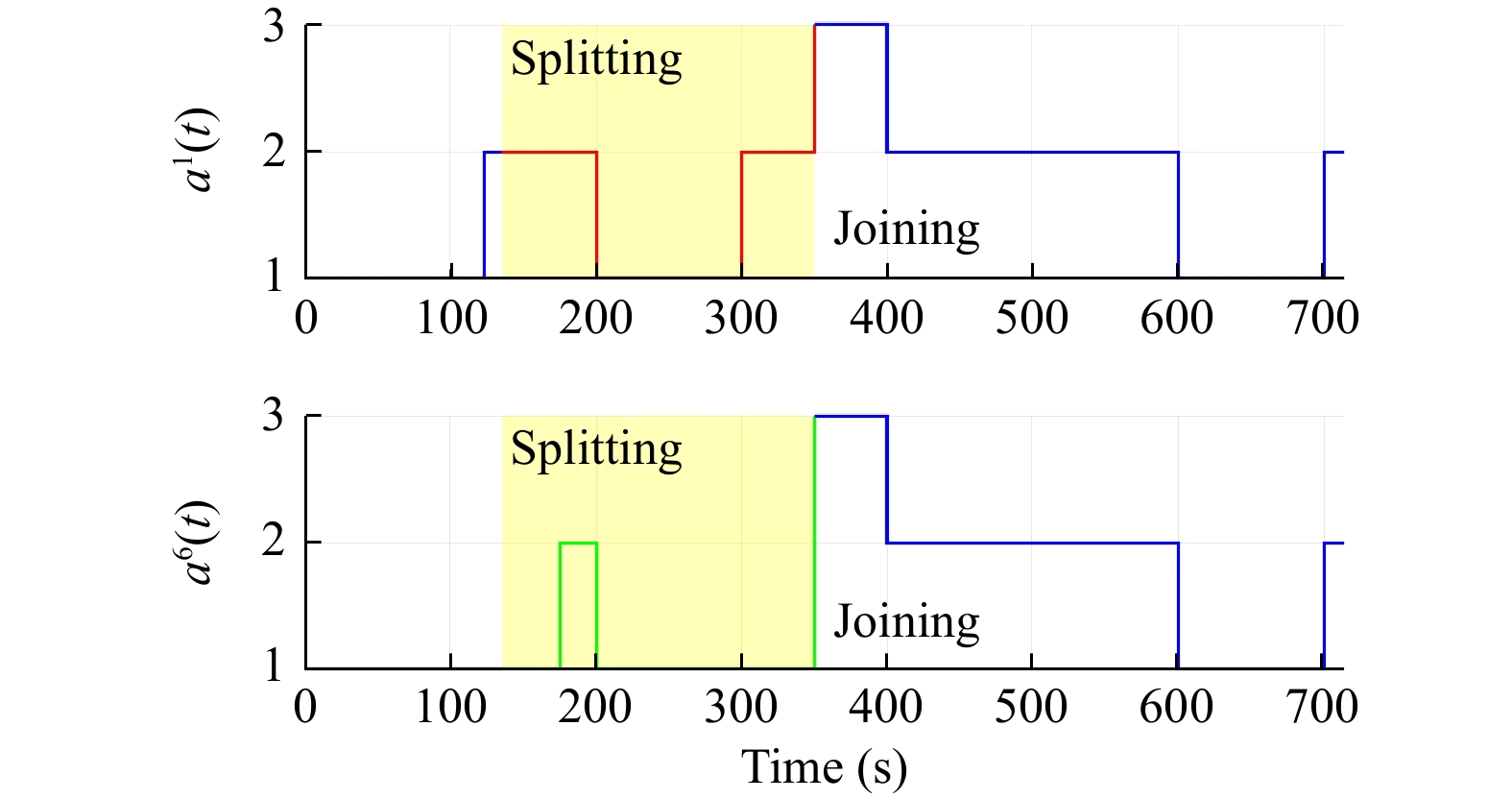
In this paper, platoons of autonomous vehicles operating in urban road networks are considered. From a methodological point of view, the problem of interest consists of formally characterizing vehicle state trajectory tubes by means of routing decisions complying with traffic congestion criteria. To this end, a novel distributed control architecture is conceived by taking advantage of two methodologies: deep reinforcement learning and model predictive control. On one hand, the routing decisions are obtained by using a distributed reinforcement learning algorithm that exploits available traffic data at each road junction. On the other hand, a bank of model predictive controllers is in charge of computing the more adequate control action for each involved vehicle. Such tasks are here combined into a single framework: the deep reinforcement learning output (action) is translated into a set-point to be tracked by the model predictive controller; conversely, the current vehicle position, resulting from the application of the control move, is exploited by the deep reinforcement learning unit for improving its reliability. The main novelty of the proposed solution lies in its hybrid nature: on one hand it fully exploits deep reinforcement learning capabilities for decision-making purposes; on the other hand, time-varying hard constraints are always satisfied during the dynamical platoon evolution imposed by the computed routing decisions. To efficiently evaluate the performance of the proposed control architecture, a co-design procedure, involving the SUMO and MATLAB platforms, is implemented so that complex operating environments can be used, and the information coming from road maps (links, junctions, obstacles, semaphores, etc.) and vehicle state trajectories can be shared and exchanged. Finally by considering as operating scenario a real entire city block and a platoon of eleven vehicles described by double-integrator models, several simulations have been performed with the aim to put in light the main features of the proposed approach. Moreover, it is important to underline that in different operating scenarios the proposed reinforcement learning scheme is capable of significantly reducing traffic congestion phenomena when compared with well-reputed competitors.

| [1] |
Z. Qu, Cooperative Control of Dynamical Systems: Applications to Autonomous Vehicles. London, UK: Springer-Verlag, 2009.
|
| [2] |
Y. Ma, Z. Wang, H. Yang, and L. Yang, “Artificial intelligence applications in the development of autonomous vehicles: A survey,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 2, pp. 315–329, Mar. 2020. doi: 10.1109/JAS.2020.1003021
|
| [3] |
Y. Wang, M. Hou, K. N. Plataniotis, S. Kwong, H. Leung, E. Tunstel, I. J. Rudas, and L. Trajkovic, “Towards a theoretical framework of autonomous systems underpinned by intelligence and systems sciences,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 1, pp. 52–63, Jan. 2021.
|
| [4] |
S. Feng, Y. Zhang, S. E. Li, Z. Cao, H. X. Liu, and L. Li, “String stability for vehicular platoon control: Definitions and analysis methods,” Annu. Rev. Control, vol. 47, pp. 81–97, Mar. 2019. doi: 10.1016/j.arcontrol.2019.03.001
|
| [5] |
A. K. Das, R. Fierro, V. Kumar, J. P. Ostrowski, J. Spletzer, and C. J. Taylor, “A vision-based formation control framework,” IEEE Trans. Rob. Autom., vol. 18, no. 5, pp. 813–825, Oct. 2002. doi: 10.1109/TRA.2002.803463
|
| [6] |
H. G. Tanner, G. J. Pappas, and V. Kumar, “Leader-to-formation stability,” IEEE Trans. Rob. Autom., vol. 120, no. 3, pp. 443–455, Jun. 2004.
|
| [7] |
P. Ogren, M. Egerstedt, and X. Hu, “A control Lyapunov function approach to multiagent coordination,” IEEE Trans. Rob. Autom., vol. 18, no. 5, pp. 847–851, Oct. 2002. doi: 10.1109/TRA.2002.804500
|
| [8] |
P. Barooah, P. G. Mehta, and J. P. Hespanha, “Mistuning-based control design to improve closed-loop stability margin of vehicular platoons,” IEEE Trans. Automat. Control, vol. 54, p. 9, Sept. 2009.
|
| [9] |
V. S. Dolk, J. Ploeg, and W. P. M. H. Heemels, “Event-triggered control for string-stable vehicle platooning,” IEEE Trans. Intell. Transport. Syst., vol. 18, no. 12, pp. 3486–3500, Dec. 2017. doi: 10.1109/TITS.2017.2738446
|
| [10] |
F. Gao, X. Hu, S. E. Li, K. Li, and Q. Sun, “Distributed adaptive sliding mode control of vehicular platoon with uncertain interaction topology,” IEEE Trans. Ind. Electron., vol. 65, no. 8, pp. 6352–6361, Aug. 2018. doi: 10.1109/TIE.2017.2787574
|
| [11] |
A. A. Peters, R. H. Middleton, and O. Mason, “Leader tracking in homogeneous vehicle platoons with broadcast delays,” Automatica, vol. 50, no. 1, pp. 64–74, Jan. 2014. doi: 10.1016/j.automatica.2013.09.034
|
| [12] |
J. Ploeg, N. van de Wouw, and H. Nijmeijer, “Lp string stability of cascaded systems: Application to vehicle platooning,” IEEE Trans. Control Syst. Technol., vol. 22, no. 2, pp. 786–793, Mar. 2014. doi: 10.1109/TCST.2013.2258346
|
| [13] |
S. Stüdli, M. M. Seron, and R. H. Middleton, “Vehicular platoons in cyclic interconnections,” Automatica, vol. 94, pp. 283–293, Aug. 2018. doi: 10.1016/j.automatica.2018.04.033
|
| [14] |
H. Zhang, J. Liu, Z. Wang, H. Yan, and C. Zhang, “Distributed adaptive event-triggered control and stability analysis for vehicular platoon,” IEEE Trans. Intell. Transp. Syst., vol. 22, no. 3, pp. 1627–1638, Mar. 2021. doi: 10.1109/TITS.2020.2974280
|
| [15] |
L. Qi, M. Zhou, and W. Luan, “A dynamic road incident information delivery strategy to reduce urban traffic congestion,” IEEE/CAA J. Autom. Sinica, vol. 5, no. 5, pp. 934–945, Sept. 2018. doi: 10.1109/JAS.2018.7511165
|
| [16] |
S. Wollenstein-Betech, M. Salazar, A. Houshmand, M. Pavone, I. C. Paschalidis, and C. G. Cassandras, “Routing and rebalancing intermodal autonomous mobility-on-demand systems in mixed traffic,” IEEE Trans. Intell. Transp. Syst., vol. 23, no. 8, pp. 12263–12275, Aug. 2022. doi: 10.1109/TITS.2021.3112106
|
| [17] |
H. Bang, B. Chalaki, and A. A. Malikopoulos, “Combined optimal routing and coordination of connected and automated vehicles,” IEEE Control Syst. Lett., vol. 6, pp. 2749–2754, May 2022. doi: 10.1109/LCSYS.2022.3176594
|
| [18] |
W. J. Mitchell, C. E. Borroni-Bird, and L. D. Burns, Reinventing the Automobile: Personal Urban Mobility for the 21st Century. Cambridge, USA: MIT Press, 2010.
|
| [19] |
M. Mesbahi and M. Egerstedt, Graph Theoretic Methods in Multiagent Networks. Princeton, USA: Princeton University Press, 2010.
|
| [20] |
K. K. Oh, M. C. Park, and H. S. Ahn, “A survey of multi-agent formation control,” Automatica, vol. 53, pp. 424–440, Mar. 2015. doi: 10.1016/j.automatica.2014.10.022
|
| [21] |
K. Hengster-Movrić, S. Bogdan, and I. Draganjac, “Multi-agent formation control based on bell-shaped potential functions,” J. Intell. Robot. Syst., vol. 58, no. 2, pp. 165–189, May 2010. doi: 10.1007/s10846-009-9361-7
|
| [22] |
W. Dong, “Robust formation control of multiple wheeled mobile robots,” J. Intell. Robot. Syst., vol. 62, no. 3–4, pp. 547–565, Jun. 2011. doi: 10.1007/s10846-010-9451-6
|
| [23] |
J. Ghommam, H. Mehrjerdi, M. Saad, and F. Mnif, “Formation path following control of unicycle-type mobile robots,” Robot. Auton. Syst., vol. 58, no. 5, pp. 727–736, May 2010. doi: 10.1016/j.robot.2009.10.007
|
| [24] |
W. B. Dunbar and D. S. Caveney, “Distributed receding horizon control of vehicle platoons: Stability and string stability,” IEEE Trans. Autom. Control, vol. 57, no. 3, pp. 620–633, Mar. 2012. doi: 10.1109/TAC.2011.2159651
|
| [25] |
P. Wang and B. Ding, “Distributed RHC for tracking and formation of nonholonomic multi-vehicle systems,” IEEE Trans. Autom. Control, vol. 59, no. 6, pp. 1439–1453, Jun. 2014. doi: 10.1109/TAC.2014.2304175
|
| [26] |
H. Li, Y. Shi, and W. Yan, “Distributed receding horizon control of constrained nonlinear vehicle formations with guaranteed γ-gain stability,” Automatica, vol. 68, pp. 148–154, Jun. 2016. doi: 10.1016/j.automatica.2016.01.057
|
| [27] |
R. Van Parys and G. Pipeleers, “Distributed MPC for multi-vehicle systems moving in formation,” Robot. Auton. Syst., vol. 97, pp. 144–152, Nov. 2017. doi: 10.1016/j.robot.2017.08.009
|
| [28] |
G. Franzè, W. Lucia, and F. Tedesco, “A distributed model predictive control scheme for leader-follower multi-agent systems,” Int. J. Control, vol. 91, no. 2, pp. 369–382, Feb. 2018. doi: 10.1080/00207179.2017.1282178
|
| [29] |
Y. Zheng, S. E. Li, K. Li, F. Borrelli, and J. K. Hedrick, “Distributed model predictive control for heterogeneous vehicle platoons under unidirectional topologies,” IEEE Trans. Control Syst. Technol., vol. 25, no. 3, pp. 899–910, May 2017. doi: 10.1109/TCST.2016.2594588
|
| [30] |
P. Wang, H. Deng, J. Zhang, L. Wang, M. Zhang, and Y. Li, “Model predictive control for connected vehicle platoon under switching communication topology,” IEEE Trans. Intell. Transp. Syst., vol. 23, no. 7, pp. 7817–7830, Jul. 2022. doi: 10.1109/TITS.2021.3073012
|
| [31] |
H. Zhang, S. Seal, D. Wu, F. Bouffard, and B. Boulet, “Building energy management with reinforcement learning and model predictive control: A survey,” IEEE Access, vol. 10, pp. 27853–27862, Mar. 2022. doi: 10.1109/ACCESS.2022.3156581
|
| [32] |
G. Ceusters, R. C. Rodríguez, A. B. García, R. Franke, G. Deconinck, L. Helsen, A. Nowé, M. Messagie, and L. R. Camargo, “Model-predictive control and reinforcement learning in multi-energy system case studies,” Appl. Energy, vol. 303, p. 117634, Dec. 2021. doi: 10.1016/j.apenergy.2021.117634
|
| [33] |
C. Greatwood and A. G. Richards, “Reinforcement learning and model predictive control for robust embedded quadrotor guidance and control,” Auton. Robot., vol. 43, no. 7, pp. 1681–1693, Oct. 2019. doi: 10.1007/s10514-019-09829-4
|
| [34] |
R. R. Hossain and R. Kumar, “Machine learning accelerated real-time model predictive control for power systems,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 4, pp. 916–930, Apr. 2023. doi: 10.1109/JAS.2023.123135
|
| [35] |
C. Liu and Y. L. Murphey, “Optimal power management based on Q-learning and neuro-dynamic programming for plug-in hybrid electric vehicles,” IEEE Trans. Neural Netw. Learn. Syst., vol. 31, no. 6, pp. 1942–1954, Jun. 2020. doi: 10.1109/TNNLS.2019.2927531
|
| [36] |
X. Qu, Y. Yu, M. Zhou, C.-T. Lin, and X. Wang, “Jointly dampening traffic oscillations and improving energy consumption with electric, connected and automated vehicles: A reinforcement learning based approach,” Appl. Energy, vol. 257, p. 114030, Jan. 2020. doi: 10.1016/j.apenergy.2019.114030
|
| [37] |
P. Hernandez-Leal, B. Kartal, and M. E. Taylor, “A survey and critique of multiagent deep reinforcement learning,” Auton. Agents Multi-Agent Syst., vol. 33, no. 6, pp. 750–797, Oct. 2019. doi: 10.1007/s10458-019-09421-1
|
| [38] |
A. OroojlooyJadid and D. Hajinezhad, “A review of cooperative multi-agent deep reinforcement learning,” arXiv preprint arXiv: 1908.03963, 2019.
|
| [39] |
K. Lin, C. Li, Y. Li, C. Savaglio, and G. Fortino, “Distributed learning for vehicle routing decision in software defined internet of vehicles,” IEEE Trans. Intell. Transp. Syst., vol. 22, no. 6, pp. 3730–3741, Jun. 2021. doi: 10.1109/TITS.2020.3023958
|
| [40] |
B. L. Ye, W. Wu, K. Ruan, L. Li, T. Chen, H. Gao, and Y. Chen, “A survey of model predictive control methods for traffic signal control,” IEEE/CAA J. Autom. Sinica, vol. 6, no. 3, pp. 623–640, May 2019. doi: 10.1109/JAS.2019.1911471
|
| [41] |
S. Chen, Z. Wu, D. Rincon, and P. D. Christofides, “Machine learning-based distributed model predictive control of nonlinear processes,” AIChE J., vol. 66, p. 11, Nov. 2020.
|
| [42] |
X. Shen and F. Borrelli, “Reinforcement learning and distributed model predictive control for conflict resolution in highly constrained spaces,” arXiv preprint arXiv: 2302.01586, 2023.
|
| [43] |
F. Giannini, G. Fortino, G. Franzè, and F. Pupo, “Path planning for vehicle platoons under routing decisions: A distributed approach combining deep reinforcement learning and model predictive control,” in Proc. 8th Int. Conf. Control, Decision and Information Technologies, Istanbul, Turkey, 2022, pp. 734–739.
|
| [44] |
F. Giannini, G. Fortino, G. Franzè, and F. Pupo, “A deep Q-Learning-model predictive control approach to vehicle routing and control with platoon constraints,” in Proc. 18th Int. Conf. Automation Science and Engineering, Mexico City, Mexico, 2022, pp. 563–568.
|
| [45] |
P. A. Lopez, M. Behrisch, L. Bieker-Walz, J. Erdmann, Y. P. Flötteröd, R. Hilbrich, L. Lücken, J. Rummel, P. Wagner, and P. Wiessner, “Microscopic traffic simulation using SUMO,” in Proc. 21st Int. Conf. Intelligent Transportation Systems, Maui, USA, 2018, pp. 2575–2582.
|
| [46] |
R. Marino, S. Scalzi, and M Netto, “Nested PID steering control for lane keeping in autonomous vehicles,” Control Eng. Pract., vol. 19, no. 12, pp. 1459–1467, Dec. 2011. doi: 10.1016/j.conengprac.2011.08.005
|
| [47] |
R. Bellman, “The theory of dynamic programming,” Bull. Amer. Math. Soc., vol. 60, no. 6, pp. 503–515, Nov. 1954. doi: 10.1090/S0002-9904-1954-09848-8
|
| [48] |
G. A. Rummery and M. Niranjan, “On-line Q-learning using connectionist systems,” University of Cambridge, Cambridge, UK, 1994.
|
| [49] |
R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction. 2nd ed. Cambridge, USA: MIT Press, 2018.
|
| [50] |
C. J. C. H. Watkins and P. Dayan, “Q-learning,” Mach. Learn., vol. 8, no. 3, pp. 279–292, May 1992.
|
| [51] |
G. Cybenko, R. Gray, and K. Moizumi, “Q-learning: A tutorial and extensions,” in Mathematics of Neural Networks: Models, Algorithms and Applications, S. W. Ellacott, J. C. Mason, and I. J. Anderson, Eds. New York, USA: Springer, 1997, pp. 24–33.
|
| [52] |
Z. Peng, G. Wen, A. Rahmani, and Y. Yu, “Leader-follower formation control of nonholonomic mobile robots based on a bioinspired neurodynamic based approach,” Robot. Auton. Syst., vol. 61, no. 9, pp. 988–996, Sept. 2013. doi: 10.1016/j.robot.2013.05.004
|
| [53] |
M. V. Kothare, V. Balakrishnan, and M. Morari, “Robust constrained model predictive control using linear matrix inequalities,” Automatica, vol. 32, no. 10, pp. 1361–1379, Oct. 1996. doi: 10.1016/0005-1098(96)00063-5
|
| [54] |
A. Casavola, D. Famularo, and G. Franzè, “Robust fault detection of uncertain linear systems via quasi-LMIs,” Automatica, vol. 44, no. 1, pp. 289–295, Jan. 2008. doi: 10.1016/j.automatica.2007.05.010
|
| [55] |
H. G. Nguyen, N. Pezeshkian, M. Raymond, A. Gupta, and J. M. Spector, “Autonomous communication relays for tactical robots,”in Proc. 11th Int. Conf. Advanced Robotics, Coimbra, Portugal, 2003, pp. 35–40.
|
| [56] |
D. Q. Mayne, “Control of constrained dynamic systems,” Eur. J. Control, vol. 7, no. 2–3, pp. 87–99, Dec. 2001. doi: 10.3166/ejc.7.87-99
|
| [57] |
E. Fridman and U. Shaked, “Delay-dependent H∞ control of uncertain discrete delay systems,” Eur. J. Control, vol. 11, no. 1, pp. 29–37, 2005. doi: 10.3166/ejc.11.29-37
|
| [58] |
D. Krajzewicz, J. Erdmann, M. Behrisch, and L. Bieker, “Recent development and applications of SUMO-Simulation of Urban mobility,” Int. J. Adv. Syst. Meas., vol. 5, no. 3-4, pp. 128–138, 2012.
|
| [59] |
M. Behrisch, L. Bieker, J. Erdmann, and D. Krajzewicz, “SUMO-simulation of urban mobility: An overview,” in Proc. 3rd Int. Conf. Advances in System Simulation, Barcelona, Spain, 2011.
|
| [60] |
A. F. Acosta, J. E. Espinosa, and J. Espinosa, “TraCI4Matlab: Enabling the integration of the SUMO road traffic simulator and matlab® through a software Re-engineering process,” in Modeling Mobility with Open Data, M. Behrisch and M. Weber, Eds. Cham, Germany: Springer, 2015, pp. 155–170.
|
| [61] |
MathWorks, “Reinforcement learning toolbox: User’s guide (R2022a),” Jun. 2022. [Online]. Available: http://wwwmathworkscom/help/reinforcement-learning/
|
| [62] |
MathWorks, “Deep learning toolbox: User’s guide (R2022a),” Jun. 2022. [Online]. Available: http://wwwmathworkscom/help/deeplearning/
|
| [63] |
L. Bieker, D. Krajzewicz, A. P. Morra, C. Michelacci, and F. Cartolano, “Traffic simulation for all: A real world traffic scenario from the city of bologna,” in Modeling Mobility with Open Data, M. Behrisch and M. Weber, Eds. Cham, Germany: Springer, 2015, pp. 47–60.
|
| [64] |
D. Krajzewicz, R. Blokpoel, P. Cataldi, L. Bieker, J. Ringel, J. Leguay, and Y. Lopez, “iTETRIS deliverable 3.2-traffic modelling: ITS algorithms,” Apr. 2010.
|
| [65] |
R. M. Rogers, Applied Mathematics in Integrated Navigation Systems. 3rd ed. Reston, USA: American Institute of Aeronautics and Astronautics, 2007.
|
| [66] |
E. W. Dijkstra, “A note on two problems in connexion with graphs,” Numer. Math., vol. 1, no. 1, pp. 269–271, Dec. 1959. doi: 10.1007/BF01386390
|

Figures(17) / Tables(2)






 DownLoad:
DownLoad: