A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 11
Issue 3
Volume 11
Issue 3
IEEE/CAA Journal of Automatica Sinica
| Citation: | C. Pan, J. Peng, and Z. Zhang, “Depth-guided vision transformer with normalizing flows for monocular 3D object detection,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 3, pp. 673–689, Mar. 2024. doi: 10.1109/JAS.2023.123660

|
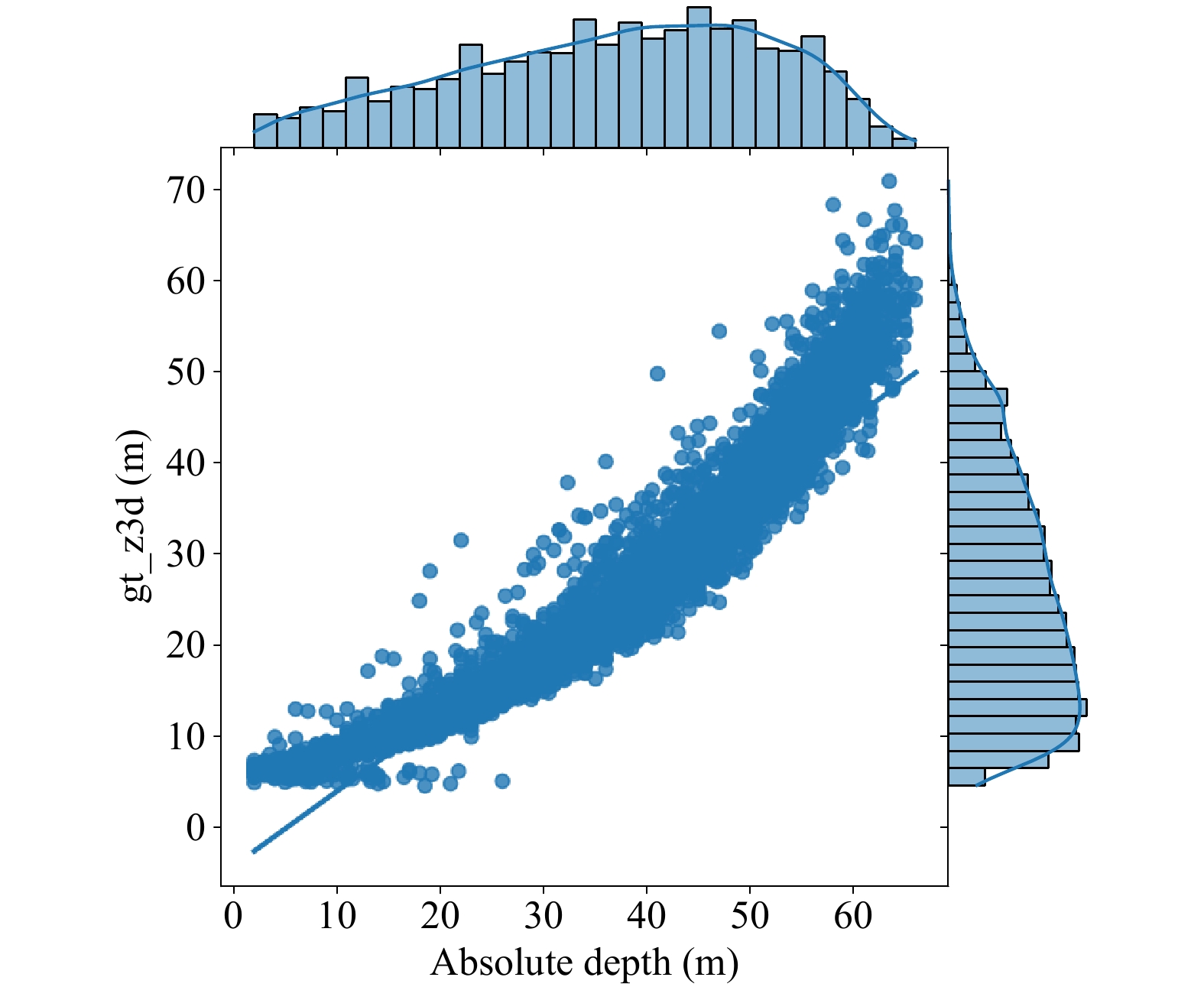
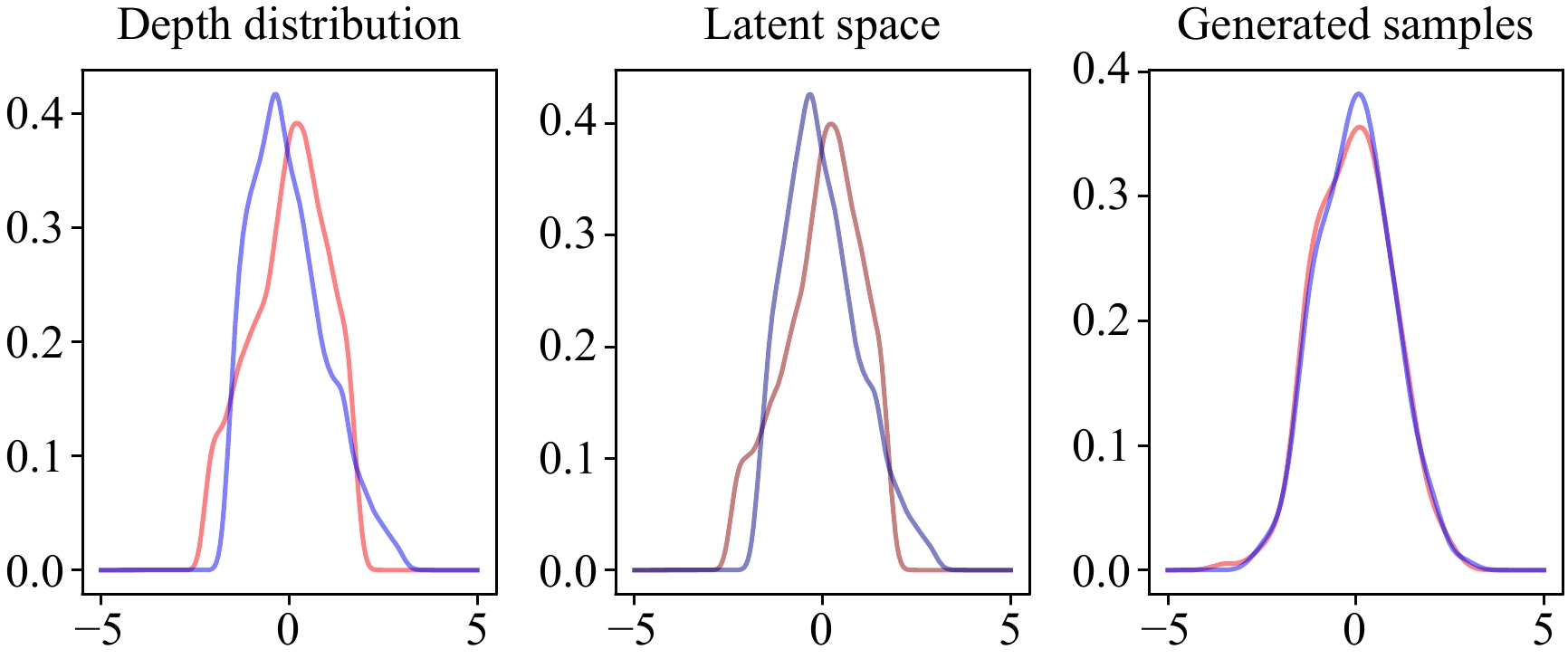
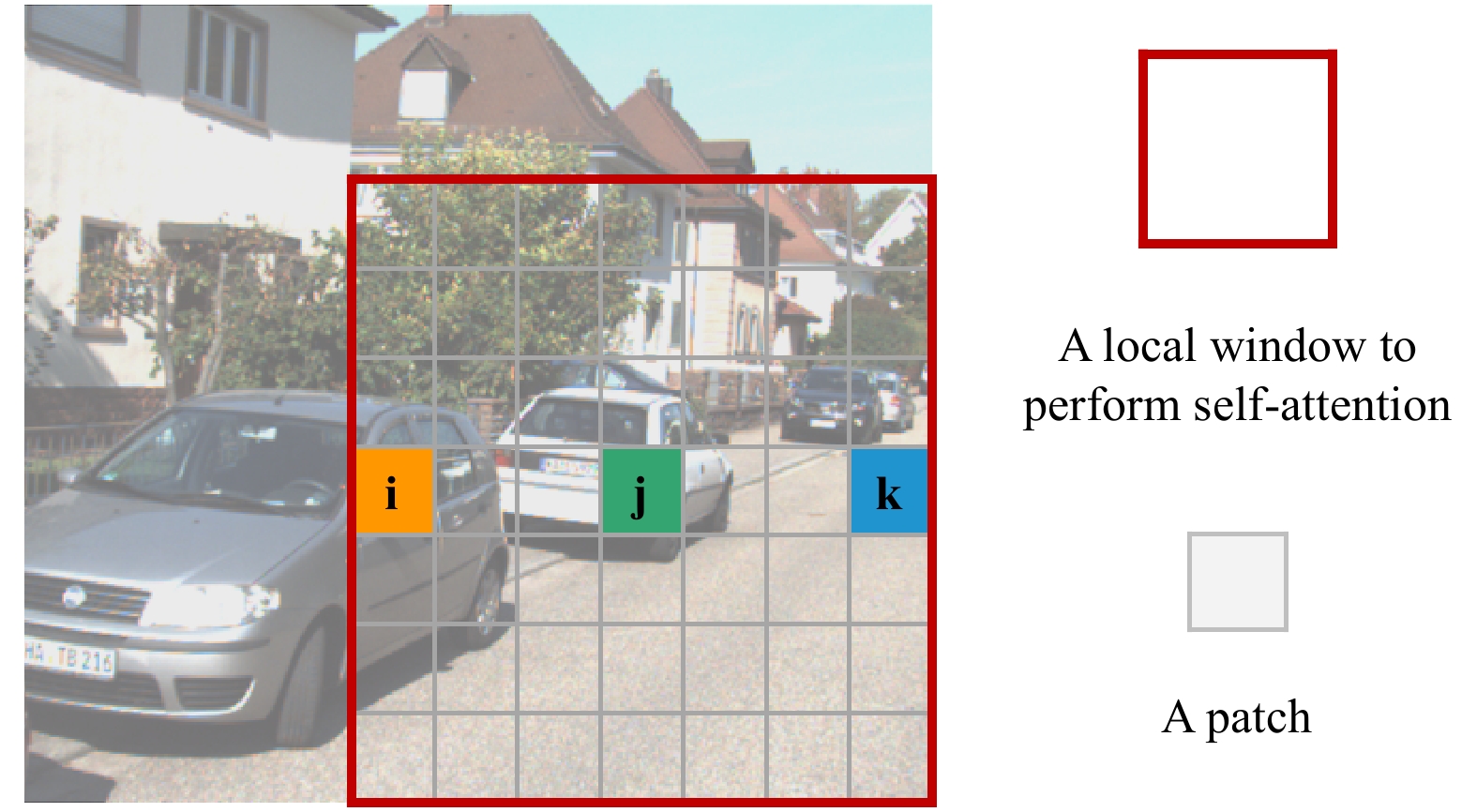
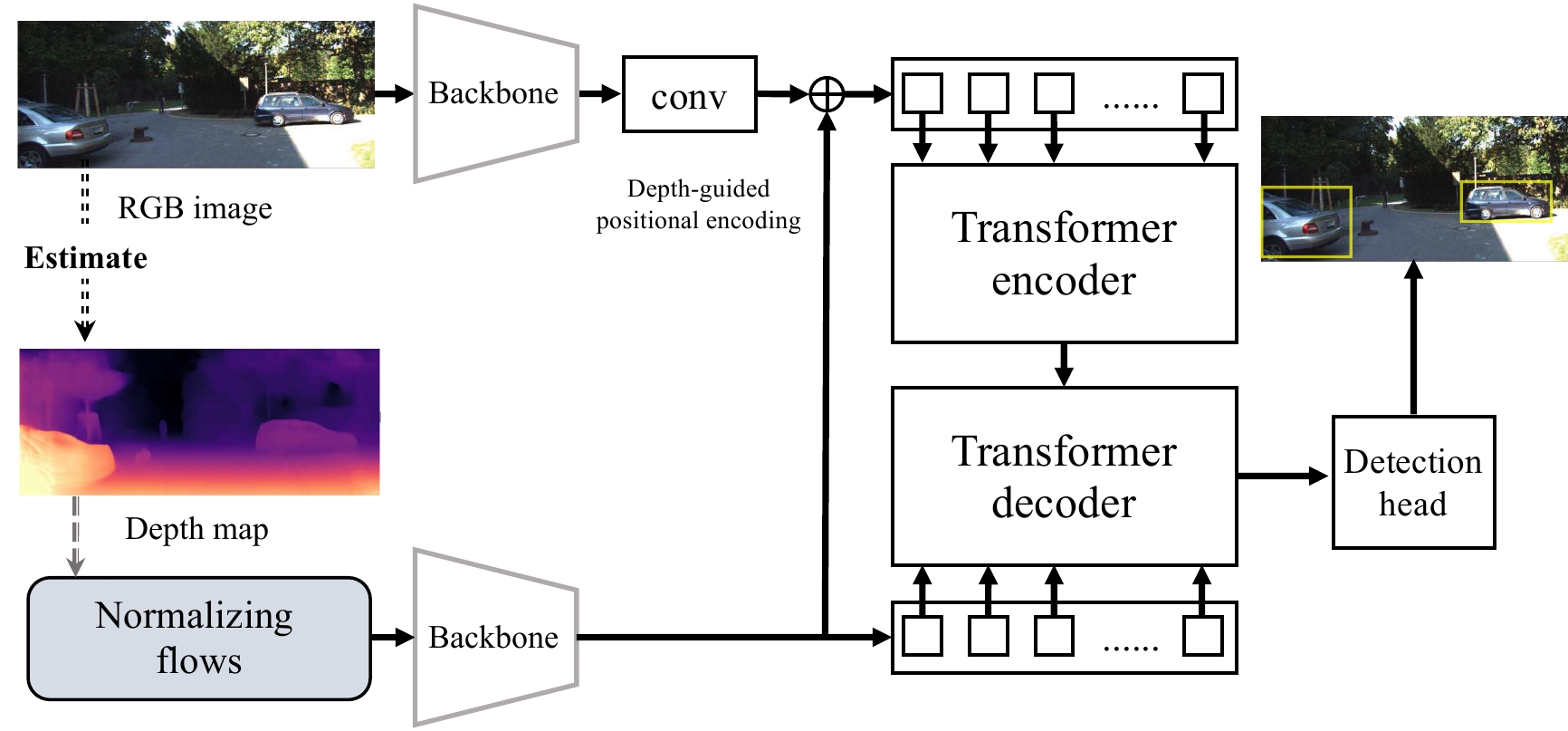
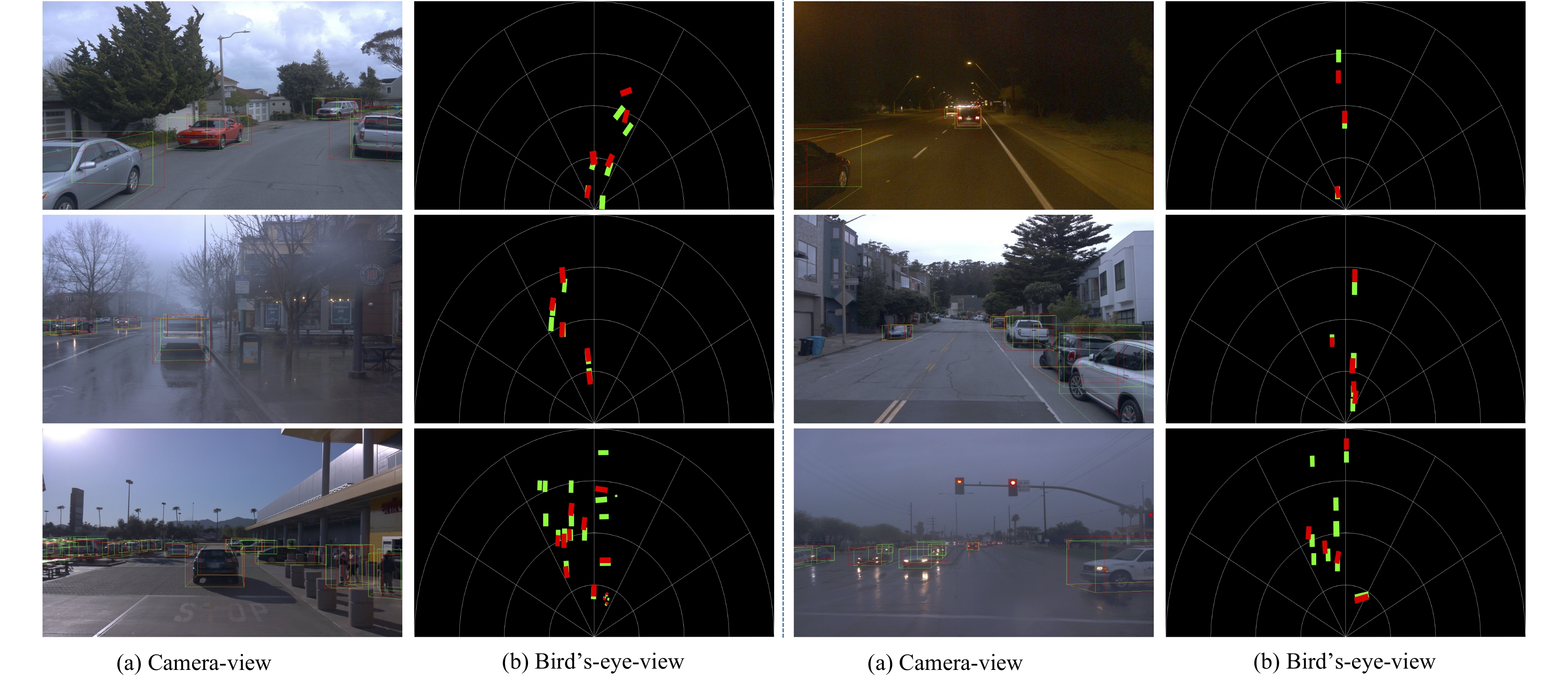
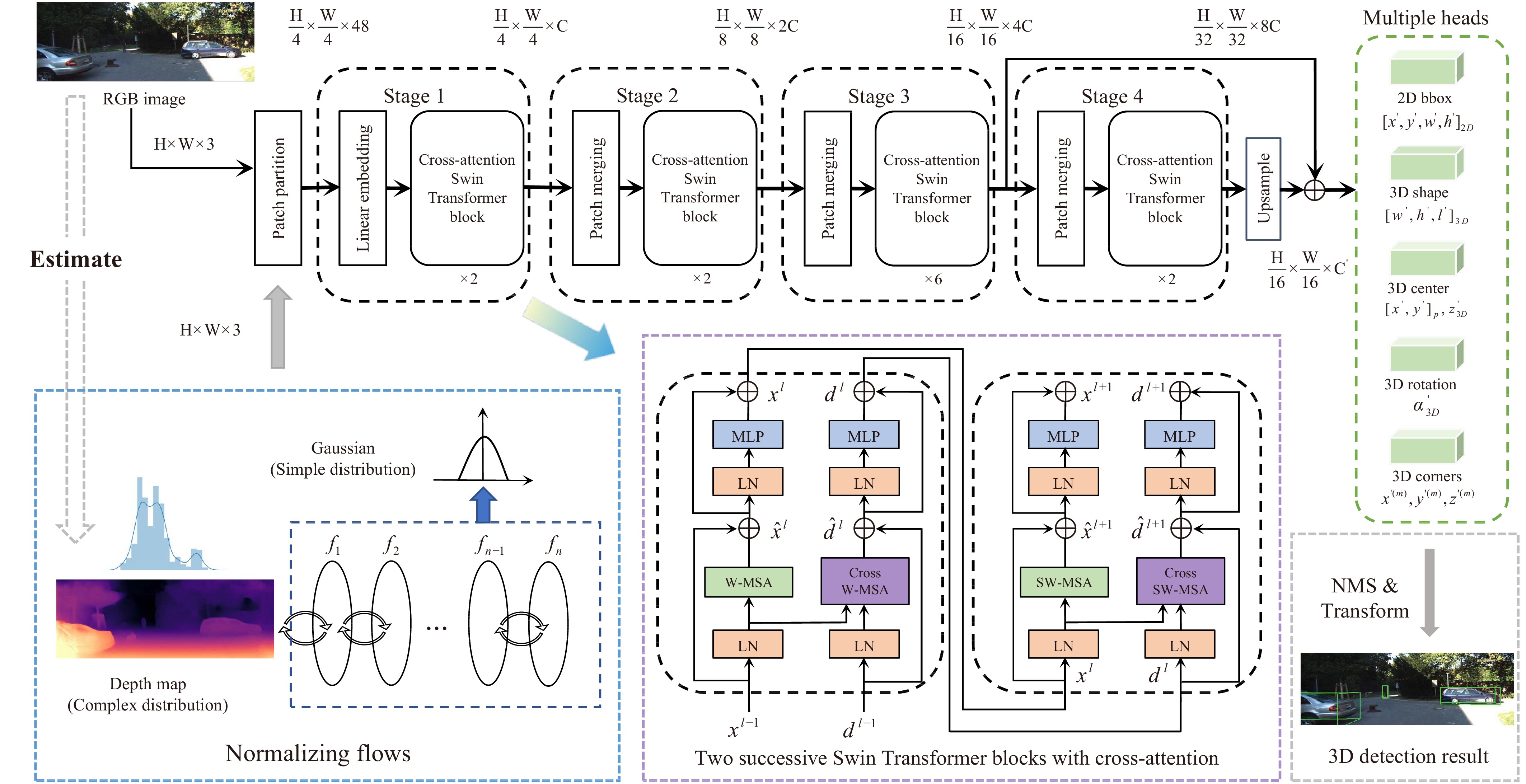
Monocular 3D object detection is challenging due to the lack of accurate depth information. Some methods estimate the pixel-wise depth maps from off-the-shelf depth estimators and then use them as an additional input to augment the RGB images. Depth-based methods attempt to convert estimated depth maps to pseudo-LiDAR and then use LiDAR-based object detectors or focus on the perspective of image and depth fusion learning. However, they demonstrate limited performance and efficiency as a result of depth inaccuracy and complex fusion mode with convolutions. Different from these approaches, our proposed depth-guided vision transformer with a normalizing flows (NF-DVT) network uses normalizing flows to build priors in depth maps to achieve more accurate depth information. Then we develop a novel Swin-Transformer-based backbone with a fusion module to process RGB image patches and depth map patches with two separate branches and fuse them using cross-attention to exchange information with each other. Furthermore, with the help of pixel-wise relative depth values in depth maps, we develop new relative position embeddings in the cross-attention mechanism to capture more accurate sequence ordering of input tokens. Our method is the first Swin-Transformer-based backbone architecture for monocular 3D object detection. The experimental results on the KITTI and the challenging Waymo Open datasets show the effectiveness of our proposed method and superior performance over previous counterparts.

| [1] |
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Las Vegas, USA, 2016, pp. 770–778.
|
| [2] |
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” Proc. 3rd Int. Conf. Learning Representations, San Diego, USA, 2014.
|
| [3] |
S. Liu, Y. Xia, Z. Shi, H. Yu, Z. Li, and J. Lin, “Deep learning in sheet metal bending with a novel theory-guided deep neural network,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 3, pp. 565–581, Mar. 2021. doi: 10.1109/JAS.2021.1003871
|
| [4] |
I. Ahmed, S. Din, G. Jeon, F. Piccialli, and G. Fortino, “Towards collaborative robotics in top view surveillance: A framework for multiple object tracking by detection using deep learning,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 7, pp. 1253–1270, Jul. 2021. doi: 10.1109/JAS.2020.1003453
|
| [5] |
R. Girshick, “Fast R-CNN,” in Proc. IEEE Int. Conf. Computer Vision, Santiago, Chile, 2015, pp. 1440–1448.
|
| [6] |
S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” in Proc. 28th Int. Conf. Neural Information Processing Systems, Montreal, Canada, 2015, pp. 9–99.
|
| [7] |
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y. Fu, and A. C. Berg, “SSD: Single shot MultiBox detector,” in Proc. 14th European Conf. Computer Vision, Amsterdam, The Netherlands, 2016, pp. 21–37.
|
| [8] |
T. Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Honolulu, USA, 2017, pp. 936–944.
|
| [9] |
T. Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” in Proc. IEEE Int. Conf. Computer Vision, Venice, Italy, 2017, pp. 2999–3007.
|
| [10] |
Z. Tian, C. Shen, H. Chen, and T. He, “FCOS: Fully convolutional one-stage object detection,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea, 2019, pp. 9626–9635.
|
| [11] |
G. P. Meyer, A. Laddha, E. Kee, C. Vallespi-Gonzalez, and C. K. Wellington, “LaserNet: An efficient probabilistic 3D object detector for autonomous driving,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 12669–12678.
|
| [12] |
C. R. Qi, O. Litany, K. He, and L. Guibas, “Deep Hough voting for 3D object detection in point clouds,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea, 2019, pp. 9276–9285.
|
| [13] |
S. Shi, X. Wang, and H. Li, “PointRCNN: 3D object proposal generation and detection from point cloud,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 770–779.
|
| [14] |
Z. Yang, Y. Sun, S. Liu, X. Shen, and J. Jia, “STD: Sparse-to-dense 3D object detector for point cloud,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea, 2019, pp. 1951–1960.
|
| [15] |
A. H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “PointPillars: Fast encoders for object detection from point clouds,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 12689–12697.
|
| [16] |
Y. Zhou and O. Tuzel, “VoxelNet: End-to-end learning for point cloud based 3D object detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018, pp. 4490–4499.
|
| [17] |
G. Brazil and X. Liu, “M3D-RPN: Monocular 3D region proposal network for object detection,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea, 2019, pp. 9286–9295.
|
| [18] |
M. Ding, Y. Huo, H. Yi, Z. Wang, J. Shi, Z. Lu, and P. Luo, “Learning depth-guided convolutions for monocular 3D object detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2020, pp. 11669–11678.
|
| [19] |
Y. Wang, W. L. Chao, D. Garg, B. Hariharan, M. Campbell, and K. Q. Weinberger, “Pseudo-LiDAR from visual depth estimation: Bridging the gap in 3D object detection for autonomous driving,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 8437–8445.
|
| [20] |
H. Fu, M. Gong, C. Wang, K. Batmanghelich, and D. Tao, “Deep ordinal regression network for monocular depth estimation,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018, pp. 2002–2011.
|
| [21] |
J. H. Lee, M. K. Han, D. W. Ko, and I. H. Suh, “From big to small: Multi-scale local planar guidance for monocular depth estimation,” arXiv preprint arXiv: 1907.10326, 2019.
|
| [22] |
Y. You, Y. Wang, W. L. Chao, D. Garg, G. Pleiss, B. Hariharan, M. E. Campbell, and K. Q. Weinberger, “Pseudo-LiDAR++: Accurate depth for 3D object detection in autonomous driving,” in Proc. 8th Int. Conf. Learning Representations, Addis Ababa, Ethiopia, 2020.
|
| [23] |
A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? The KITTI vision benchmark suite,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Providence, USA, 2012, pp. 3354–3361.
|
| [24] |
X. Ma, Z. Wang, H. Li, P. Zhang, W. Ouyang, and X. Fan, “Accurate monocular 3D object detection via color-embedded 3D reconstruction for autonomous driving,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea, 2019, pp. 6850–6859.
|
| [25] |
L. Wang, L. Du, X. Q. Ye, Y. W. Fu, G. D. Guo, X. Y. Xue, J. F. Feng, and L. Zhang, “Depth-conditioned dynamic message propagation for monocular 3D object detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 454–463.
|
| [26] |
Z. Liu, Y. T. Lin, Y. Cao, H. Hu, Y. X. Wei, Z. Zhang, S. Lin, and B. N. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 9992–10002.
|
| [27] |
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V. Patnaik, P. Tsui, J. Guo, Y. Zhou, Y. N. Chai, B. Caine, V. Vasudevan, W. Han, J. Ngiam, H. Zhao, A. Timofeev, S. Ettinger, M. Krivokon, A. Gao, A. Joshi, Y. Zhang, J. Shlens, Z. Chen, and D. Anguelov, “Scalability in perception for autonomous driving: Waymo open dataset,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2020, pp. 2443–2451.
|
| [28] |
A. Mousavian, D. Anguelov, J. Flynn, and J. Košecká, “3D bounding box estimation using deep learning and geometry,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Honolulu, USA, 2017, pp. 5632–5640.
|
| [29] |
X. Chen, K. Kundu, Z. Zhang, H. Ma, S. Fidler, and R. Urtasun, “Monocular 3D object detection for autonomous driving,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Las Vegas, UAS, 2016, pp. 2147–2156.
|
| [30] |
B. Li, W. Ouyang, L. Sheng, X. Zeng, and X. Wang, “GS3D: An efficient 3D object detection framework for autonomous driving,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 1019–1028.
|
| [31] |
Z. Qin, J. Wang, and Y. Lu, “MonoGRNet: A geometric reasoning network for monocular 3D object localization,” in Proc. 33rd AAAI Conf. Artificial Intelligence, Honolulu, USA, 2019, pp. 8851–8858.
|
| [32] |
Z. Liu, Z. Wu, and R. Tóth, “SMOKE: Single-stage monocular 3D object detection via keypoint estimation,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition Workshops, Seattle, USA, 2020, pp. 4289–4298.
|
| [33] |
X. Shi, Q. Ye, X. Chen, C. Chen, Z. Chen, and T. K. Kim, “Geometry-based distance decomposition for monocular 3D object detection,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 15152–15161.
|
| [34] |
J. Gu, B. Wu, L. Fan, J. Huang, S. Cao, Z. Xiang, and X.-S. Hua, “Homography loss for monocular 3D object detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, UAS, 2022, pp. 1070–1079.
|
| [35] |
Y. Chen, L. Tai, K. Sun, and M. Li, “MonoPair: Monocular 3D object detection using pairwise spatial relationships,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2020, pp. 12090–12099.
|
| [36] |
A. Simonelli, S. R. Bulò, L. Porzi, M. Lopez-Antequera, and P. Kontschieder, “Disentangling monocular 3D object detection,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea, 2019, pp. 1991–1999.
|
| [37] |
Y. Zhang, W. Zheng, Z. Zhu, G. Huang, D. Du, J. Zhou, and J. Lu, “Dimension embeddings for monocular 3D object detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 1579–1588.
|
| [38] |
X. Liu, N. Xue, and T. Wu, “Learning auxiliary monocular contexts helps monocular 3D object detection,” in Proc. 36th AAAI Conf. Artificial Intelligence, 2022, pp. 1810–1818.
|
| [39] |
F. Chabot, M. Chaouch, J. Rabarisoa, C. Teulière, and T. Chateau, “Deep manta: A coarse-to-fine many-task network for joint 2D and 3D vehicle analysis from monocular image,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Honolulu, USA, 2017, pp. 1827–1836.
|
| [40] |
L. Peng, F. Liu, Z. Yu, S. Yan, D. Deng, Z. Yang, H. Liu, and D. Cai, “Lidar point cloud guided monocular 3D object detection,” in Proc. 17th European Conf. Computer Vision, Tel Aviv, Israel, 2022, pp. 123–139.
|
| [41] |
X. Weng and K. Kitani, “Monocular 3D object detection with pseudo-LiDAR point cloud,” in Proc. IEEE/CVF Int. Conf. Computer Vision Workshop, Seoul, Korea, 2019, pp. 857–866.
|
| [42] |
X. Ye, L. Du, Y. Shi, Y. Li, X. Tan, J. Feng, E. Ding, and S. Wen, “Monocular 3D object detection via feature domain adaptation,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 17–34.
|
| [43] |
D. Park, R. Ambruş, V. Guizilini, J. Li, and A. Gaidon, “Is pseudo-LiDAR needed for monocular 3D object detection?” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 3122–3132.
|
| [44] |
E. Ouyang, L. Zhang, M. Chen, A. Arnab, and Y. Fu, “Dynamic depth fusion and transformation for monocular 3D object detection,” in Proc. 15th Asian Conf. Computer Vision, Kyoto, Japan, 2020, pp. 349–364.
|
| [45] |
C. Reading, A. Harakeh, J. Chae, and S. L. Waslander, “Categorical depth distribution network for monocular 3D object detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 8551–8560.
|
| [46] |
A. Kumar, G. Brazil, E. Corona, A. Parchami, and X. Liu, “DEVIANT: Depth EquiVariAnt NeTwork for monocular 3D object detection,” in Proc. 17th European Conf. Computer Vision, Tel Aviv, Israel, 2022, pp. 664–683.
|
| [47] |
L. Peng, X. Wu, Z. Yang, H. Liu, and D. Cai, “DID-M3D: Decoupling instance depth for monocular 3D object detection,” in Proc. 17th European Conf. Computer Vision, Tel Aviv, Israel, 2022, pp. 71–88.
|
| [48] |
Z. Li, Z. Qu, Y. Zhou, J. Liu, H. Wang, and L. Jiang, “Diversity matters: Fully exploiting depth clues for reliable monocular 3D object detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 2781–2790.
|
| [49] |
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. 31st Int. Conf. Neural Information Processing Systems, Long Beach, USA, 2017, pp. 6000–6010.
|
| [50] |
J. Devlin, M. W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proc. Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, Minnesota, 2019, pp. 4171–4186.
|
| [51] |
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16×16 words: Transformers for image recognition at scale,” in Proc. 9th Int. Conf. Learning Representations, 2021.
|
| [52] |
C. F. R. Chen, Q. Fan, and R. Panda, “CrossViT: Cross-attention multi-scale vision transformer for image classification,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 347–356.
|
| [53] |
L. Yuan, Y. Chen, T. Wang, W. Yu, Y. Shi, Z. H. Jiang, F. E. H. Tay, J. Feng, and S. Yan, “Tokens-to-token ViT: Training vision transformers from scratch on ImageNet,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 538–547.
|
| [54] |
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 213–229.
|
| [55] |
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable DETR: Deformable transformers for end-to-end object detection,” in Proc. 9th Int. Conf. Learning Representations, 2021.
|
| [56] |
E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Álvarez, and P. Luo, “SegFormer: Simple and efficient design for semantic segmentation with transformers,” in Proc. 34th Neural Information Processing Systems, 2021, pp. 12077–12090.
|
| [57] |
S. Zheng, J. Lu, H. Zhao, X. Zhu, Z. Luo, Y. Wang, Y. Fu, J. Feng, T. Xiang, P. H. S. Torr, and L. Zhang, “Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 6877–6886.
|
| [58] |
A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lučić, and C. Schmid, “ViViT: A video vision transformer,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 6816–6826.
|
| [59] |
R. Girdhar, J. J. Carreira, C. Doersch, and A. Zisserman, “Video action transformer network,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 244–253.
|
| [60] |
J. Ma, L. Tang, F. Fan, J. Huang, X. Mei, and Y. Ma, “SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 7, pp. 1200–1217, Jul. 2022. doi: 10.1109/JAS.2022.105686
|
| [61] |
S. He, H. Luo, P. Wang, F. Wang, H. Li, and W. Jiang, “TransReID: Transformer-based object re-identification,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 14993–15002.
|
| [62] |
K. C. Huang, T. H. Wu, H. T. Su, and W. H. Hsu, “MonoDTR: Monocular 3D object detection with depth-aware transformer,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 4002–4011.
|
| [63] |
D. J. Rezende and S. Mohamed, “Variational inference with normalizing flows,” in Proc. 32nd Int. Conf. Int. Conf. Machine Learning, Lille, France, 2015, pp. 1530–1538.
|
| [64] |
L. Dinh, J. Sohl-Dickstein, and S. Bengio, “Density estimation using real NVP,” in Proc. 5th Int. Conf. Learning Representations, Toulon, France, 2017.
|
| [65] |
G. Papamakarios, I. Murray, and T. Pavlakou, “Masked autoregressive flow for density estimation,” in Proc. Neural Information Processing Systems, Long Beach, USA, 2017, pp. 2338–2347.
|
| [66] |
S. Kim, S.-G. Lee, J. Song, J. Kim, and S. Yoon, “FloWaveNet: A generative flow for raw audio,” in Proc. 36th Int. Conf. Machine Learning, Long Beach, USA, 2018, pp. 3370–3378.
|
| [67] |
D. P. Kingma and P. Dhariwal, “Glow: Generative flow with invertible 1×1 convolutions,” in Proc. 32nd Int. Conf. Neural Information Processing Systems, Montréal, Canada, 2018, pp. 10236–10245.
|
| [68] |
M. Kumar, M. Babaeizadeh, D. Erhan, C. Finn, S. Levine, L. Dinh, and D. Kingma, “VideoFlow: A flow-based generative model for video,” arXiv preprint arXiv: 1903.01434, 2019.
|
| [69] |
J. Li, S. Bian, A. Zeng, C. Wang, B. Pang, W. Liu, and C. Lu, “Human pose regression with residual log-likelihood estimation,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 11005–11014.
|
| [70] |
H. Xu, E. G. Bazavan, A. Zanfir, W. T. Freeman, R. Sukthankar, and C. Sminchisescu, “GHUM & GHUML: Generative 3D human shape and articulated pose models,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2020, pp. 6183–6192.
|
| [71] |
A. Zanfir, E. G. Bazavan, H. Xu, W. T. Freeman, R. Sukthankar, and C. Sminchisescu, “Weakly supervised 3D human pose and shape reconstruction with normalizing flows,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 465–481.
|
| [72] |
C. Durkan, A. Bekasov, I. Murray, and G. Papamakarios, “Neural spline flows,” in Proc. Conf. Neural Information Processing Systems, Vancouver, Canada, 2019.
|
| [73] |
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Miami, USA, 2009, pp. 248–255.
|
| [74] |
E. Jörgensen, C. Zach, and F. Kahl, “Monocular 3D object detection and box fitting trained end-to-end using intersection-over-union loss,” arXiv preprint arXiv: 1906.08070, 2019.
|
| [75] |
P. Li, H. Zhao, P. Liu, and F. Cao, “RTM3D: Real-time monocular 3D detection from object keypoints for autonomous driving,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 644–660.
|
| [76] |
S. Luo, H. Dai, L. Shao, and Y. Ding, “M3DSSD: Monocular 3D single stage object detector,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 6141–6150.
|
| [77] |
T. Wang, X. Zhu, J. Pang, and D. Lin, “Probabilistic and geometric depth: Detecting objects in perspective,” in Proc. 5th Conf. Robot Learning, London, UK, 2021, pp. 1475–1485.
|
| [78] |
X. Ma, Y. Zhang, D. Xu, D. Zhou, S. Yi, H. Li, and W. Ouyang, “Delving into localization errors for monocular 3D object detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 4719–4728.
|
| [79] |
A. Kumar, G. Brazil, and X. Liu, “GrooMeD-NMS: Grouped mathematically differentiable NMS for monocular 3D object detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 8969–8979.
|
| [80] |
Y. Zhang, J. Lu, and J. Zhou, “Objects are different: Flexible monocular 3D object detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 3288–3297.
|
| [81] |
F. Manhardt, W. Kehl, and A. Gaidon, “ROI-10D: Monocular lifting of 2D detection to 6D pose and metric shape,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 2064–2073.
|
| [82] |
L. Wang, L. Zhang, Y. Zhu, Z. Zhang, T. He, M. Li, and X. Xue, “Progressive coordinate transforms for monocular 3D object detection,” in Proc. 34th Conf. Neural Information Processing Systems, 2021, pp. 13364–13377.
|
| [83] |
X. Chen, K. Kundu, Y. Zhu, A. Berneshawi, H. Ma, S. Fidler, and R. Urtasun, “3D object proposals for accurate object class detection,” in Proc. 28th Int. Conf. Neural Information Processing Systems, Montreal, Canada, 2015, pp. 424–432.
|
| [84] |
Y. Lu, X. Ma, L. Yang, T. Zhang, Y. Liu, Q. Chu, J. Yan, and W. Ouyang, “Geometry uncertainty projection network for monocular 3D object detection,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 3091–3101.
|
| [85] |
Y. Liu, Y. Yuan, and M. Liu, “Ground-aware monocular 3D object detection for autonomous driving,” IEEE Rob. Autom. Lett., vol. 6, no. 2, pp. 919–926, Apr. 2021. doi: 10.1109/LRA.2021.3052442
|
| [86] |
S. F. Bhat, I. Alhashim, and P. Wonka, “AdaBins: Depth estimation using adaptive bins,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 4008–4017.
|
| [87] |
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” in Proc. 7th Int. Conf. Learning Representations, New Orleans, USA, 2019.
|
| [88] |
Q. Lian, P. Li, and X. Chen, “MonoJSG: Joint semantic and geometric cost volume for monocular 3D object detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 1060–1069.
|
| [89] |
X. Ma, S. Liu, Z. Xia, H. Zhang, X. Zeng, and W. Ouyang, “Rethinking pseudo-LiDAR representation,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 311–327.
|
| [90] |
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The KITTI dataset,” Int. J. Rob. Res., vol. 32, no. 11, pp. 1231–1237, Sept. 2013. doi: 10.1177/0278364913491297
|
| [91] |
D. Eigen, C. Puhrsch, and R. Fergus, “Depth map prediction from a single image using a multi-scale deep network,” in Proc. 27th Int. Conf. Neural Information Processing Systems, Montreal, Canada, 2014, pp. 2366–2374.
|
Figures(8) / Tables(12)






 DownLoad:
DownLoad: