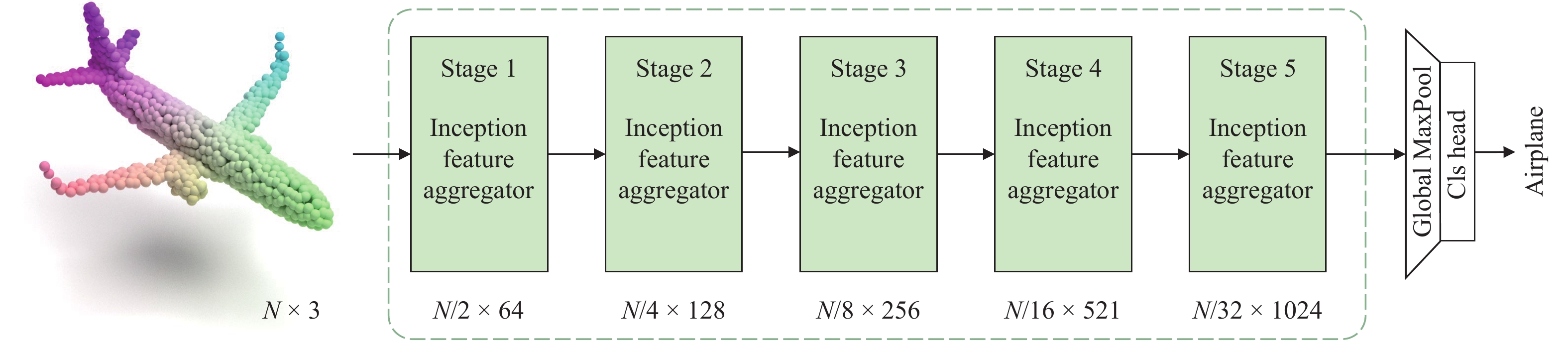
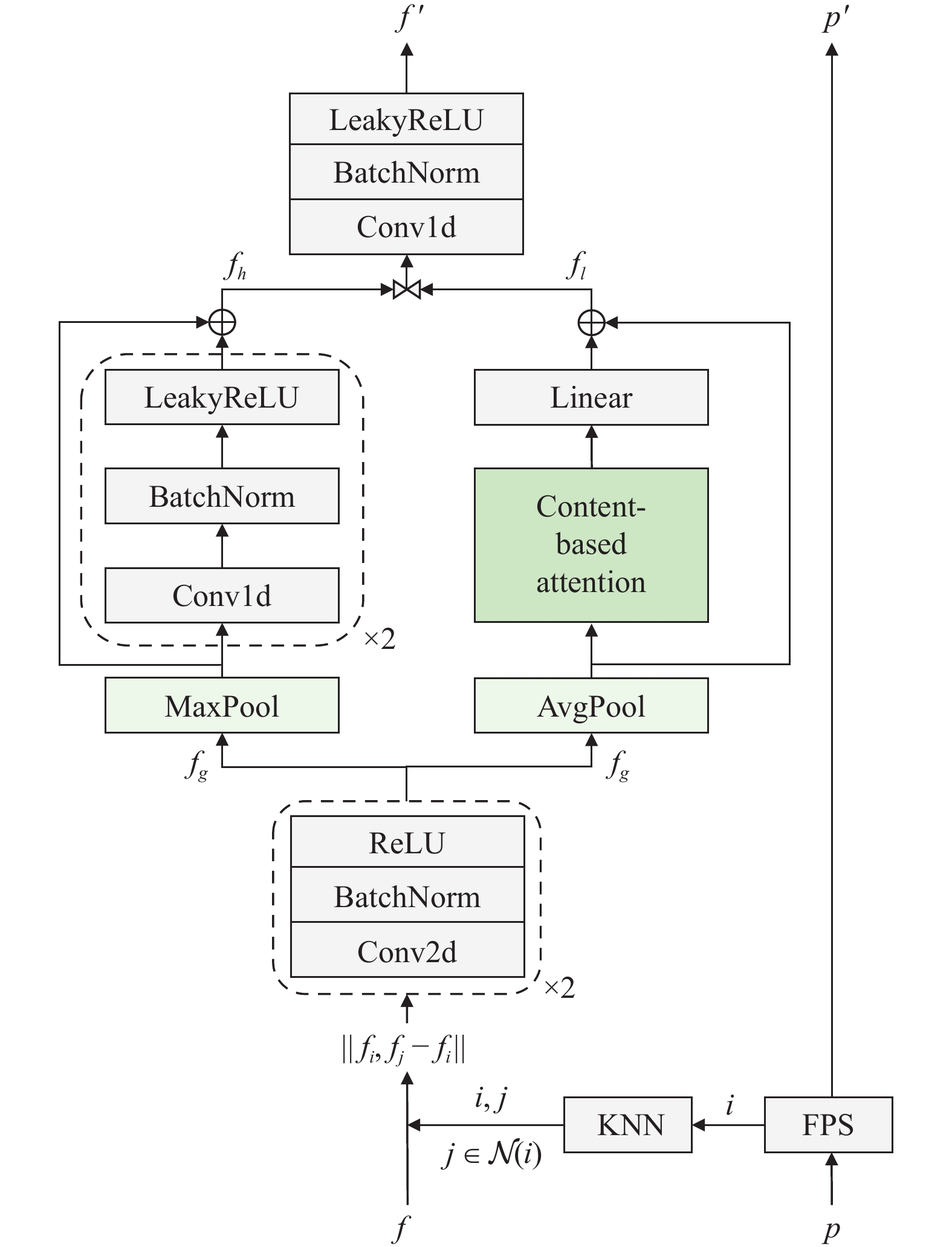
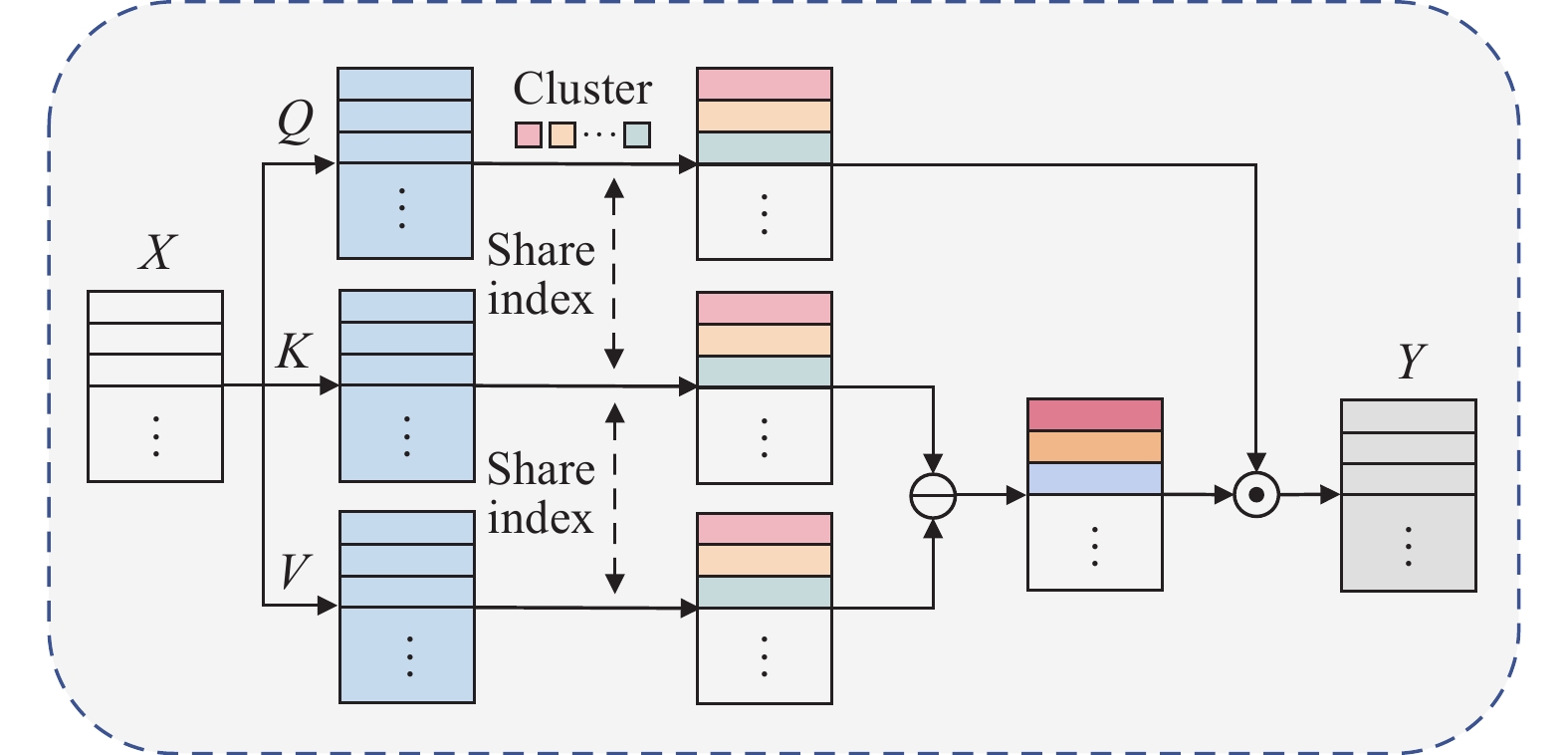
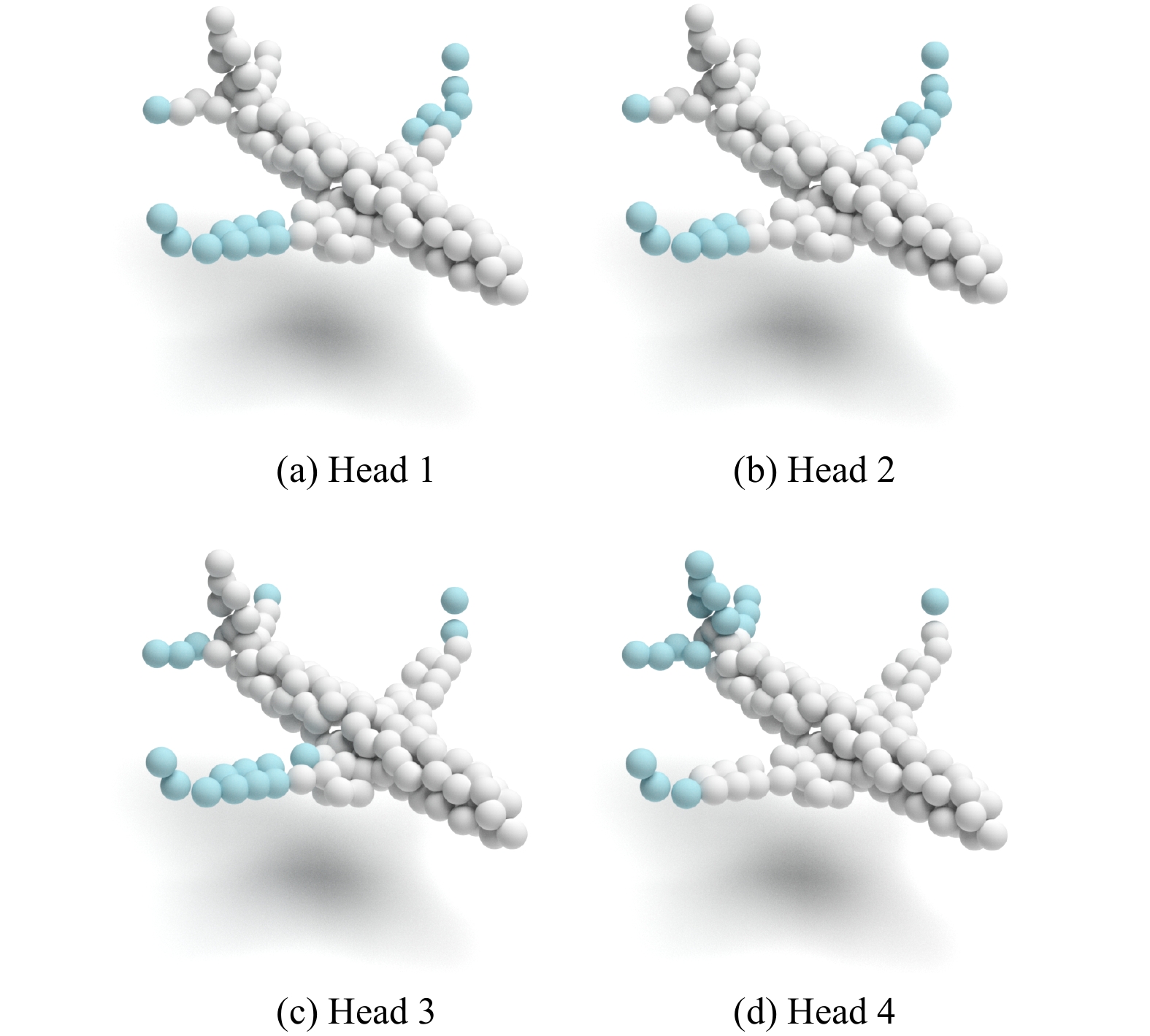
A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 11
Issue 1
Volume 11
Issue 1
IEEE/CAA Journal of Automatica Sinica
| Citation: | Y. Liu, B. Tian, Y. Lv, L. Li, and F.-Y. Wang, “Point cloud classification using content-based Transformer via clustering in feature space,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 1, pp. 231–239, Jan. 2024. doi: 10.1109/JAS.2023.123432

|

| [1] |
O. Schumann, J. Lombacher, M. Hahn, C. Wöhler, and J. Dickmann, “Scene understanding with automotive radar,” IEEE Trans. Intell. Veh., vol. 5, no. 2, pp. 188–203, Jun. 2020. doi: 10.1109/TIV.2019.2955853
|
| [2] |
L. Li, M. Yang, L. D. Guo, C. X. Wang, and B. Wang, “Hierarchical neighborhood based precise localization for intelligent vehicles in urban environments,” IEEE Trans. Intell. Veh., vol. 1, no. 3, pp. 220–229, Sept. 2016. doi: 10.1109/TIV.2017.2654065
|
| [3] |
X. F. Sun, S. H. Shen, H. N. Cui, L. H. Hu, and Z. Y. Hu, “Geographic, geometrical and semantic reconstruction of urban scene from high resolution oblique aerial images,” IEEE/CAA J. Autom. Sinica, vol. 6, no. 1, pp. 118–130, Jan. 2019. doi: 10.1109/JAS.2017.7510673
|
| [4] |
Z. Chen, J. Zhang, and D. C. Tao, “Progressive LiDAR adaptation for road detection,” IEEE/CAA J. Autom. Sinica, vol. 6, no. 3, pp. 693–702, May 2019. doi: 10.1109/JAS.2019.1911459
|
| [5] |
T. H. Chen and T. S. Chang, “RangeSeg: Range-aware real time segmentation of 3D LiDAR point clouds,” IEEE Trans. Intell. Veh., vol. 7, no. 1, pp. 93–101, Mar. 2022. doi: 10.1109/TIV.2021.3085827
|
| [6] |
C. F. Zhao, C. Fu, J. M. Dolan, and J. Wang, “L-shape fitting-based vehicle pose estimation and tracking using 3D-LiDAR,” IEEE Trans. Intell. Veh., vol. 6, no. 4, pp. 787–798, Dec. 2021. doi: 10.1109/TIV.2021.3078619
|
| [7] |
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. 31st Int. Conf. Neural Information Processing Systems, Long Beach, USA, 2017, pp. 6000–6010.
|
| [8] |
H. S. Zhao, L. Jiang, J. Y. Jia, P. Torr, and V. Koltun, “Point transformer,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 16239–16248.
|
| [9] |
M. H. Guo, J. X. Cai, Z. N. Liu, T. J. Mu, R. R. Martin, and S. M. Hu, “PCT: Point cloud transformer,” Comput. Vis. Media, vol. 7, no. 2, pp. 187–199, Jun. 2021. doi: 10.1007/s41095-021-0229-5
|
| [10] |
X. R. Pan, Z. F. Xia, S. J. Song, L. E. Li, and G. Huang, “3D object detection with Pointformer,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 7459–7468.
|
| [11] |
C. Park, Y. Jeong, M. Cho, and J. Park, “Fast point transformer,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 16928–16937.
|
| [12] |
X. Lai, J. H. Liu, L. Jiang, L. W. Wang, H. S. Zhao, S. Liu, X. J. Qi, and J. Y. Jia, “Stratified transformer for 3D point cloud segmentation,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 8490–8499.
|
| [13] |
C. Zhang, H. C. Wan, X. Y. Shen, and Z. Z. Wu, “PVT: Point-voxel transformer for point cloud learning,” Int. J. Intell. Syst., vol. 37, no. 12, pp. 11985–12008, Dec. 2022. doi: 10.1002/int.23073
|
| [14] |
Z. T. Yang, L. Jiang, Y. N. Sun, B. Schiele, and J. Y. Jia, “A unified query-based paradigm for point cloud understanding,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 8531–8541.
|
| [15] |
C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “PointNet++: Deep hierarchical feature learning on point sets in a metric space,” in Proc. 31st Int. Conf. Neural Information Processing Systems, Long Beach, USA, 2017, pp. 5105–5114.
|
| [16] |
N. Park and S. Kim, “How do vision transformers work?” in Proc. 10th Int. Conf. Learning Representations, 2022.
|
| [17] |
C. Y. Si, W. H. Yu, P. Zhou, Y. C. Zhou, X. C. Wang, and S. C. Yan, “Inception transformer,” in Proc. 36th Conf. Neural Information Processing Systems, New Orleans, USA, 2022.
|
| [18] |
C. Szegedy, W. Liu, Y. Q. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Boston, USA, 2015, pp. 1–9.
|
| [19] |
C. Szegedy, S. Ioffe, V. Vanhoucke, and A. A. Alemi, “Inception-v4, Inception-ResNet and the impact of residual connections on learning,” in Proc. 31st AAAI Conf. Artificial Intelligence, San Francisco, USA, 2017, pp. 4278–4284.
|
| [20] |
Z. R. Wu, S. R. Song, A. Khosla, F. Yu, L. G. Zhang, X. O. Tang, and J. X. Xiao, “3D ShapeNets: A deep representation for volumetric shapes,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Boston, USA, 2015, pp. 1912–1920.
|
| [21] |
M. A. Uy, Q. H. Pham, B. S. Hua, T. Nguyen, and S. K. Yeung, “Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea (South), 2019, pp. 1588–1597.
|
| [22] |
Y. Zhou and O. Tuzel, “VoxelNet: End-to-end learning for point cloud based 3D object detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018, pp. 4490–4499.
|
| [23] |
D. Maturana and S. Scherer, “VoxNet: A 3D convolutional neural network for real-time object recognition,” in Proc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems, Hamburg, Germany, 2015, pp. 922–928.
|
| [24] |
G. Riegler, A. O. Ulusoy, and A. Geiger, “OctNet: Learning deep 3D representations at high resolutions,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Honolulu, USA, 2017, pp. 6620–6629.
|
| [25] |
H. Su, S. Maji, E. Kalogerakis, and E. Learned-Miller, “Multi-view convolutional neural networks for 3D shape recognition,” in Proc. IEEE Int. Conf. Computer Vision, Santiago, Chile, 2015, pp. 945–953.
|
| [26] |
A. Goyal, H. Law, B. W. Liu, A. Newell, and J. Deng, “Revisiting point cloud shape classification with a simple and effective baseline,” in Proc. 38th Int. Conf. Machine Learning, 2021, pp. 3809–3820.
|
| [27] |
R. Q. Charles, S. Hao, K. C. Mo, and L. J. Guibas, “PointNet: Deep learning on point sets for 3D classification and segmentation,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Honolulu, USA, 2017, pp. 77–85.
|
| [28] |
Y. Y. Li, R. Bu, M. C. Sun, W. Wu, X. H. Di, and B. Q. Chen, “PointCNN: Convolution on X-transformed points,” in Proc. 32nd Int. Conf. Neural Information Processing Systems, Montreal, Canada, 2018, pp. 828–838.
|
| [29] |
W. X. Wu, Z. A. Qi, and L. Fuxin, “PointConv: Deep convolutional networks on 3D point clouds,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 9613–9622.
|
| [30] |
H. S. Zhao, L. Jiang, C. W. Fu, and J. Y. Jia, “PointWeb: Enhancing local neighborhood features for point cloud processing,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 5560–5568.
|
| [31] |
Y. C. Liu, B. Fan, S. M. Xiang, and C. H. Pan, “Relation-shape convolutional neural network for point cloud analysis,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 8887–8896.
|
| [32] |
Z. Liu, H. Hu, Y. Cao, Z. Zhang, and X. Tong, “A closer look at local aggregation operators in point cloud analysis,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 326–342.
|
| [33] |
Y. F. Xu, T. Q. Fan, M. Y. Xu, L. Zeng, and Y. Qiao, “SpiderCNN: Deep learning on point sets with parameterized convolutional filters,” in Proc. 15th European Conf. Computer Vision, Munich, Germany, 2018, pp. 90–105.
|
| [34] |
H. Thomas, C. R. Qi, J. E. Deschaud, B. Marcotegui, F. Goulette, and L. Guibas, “KPConv: Flexible and deformable convolution for point clouds,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea (South), 2019, pp. 6410–6419.
|
| [35] |
M. T. Xu, R. Y. Ding, H. S. Zhao, and X. J. Qi, “PAConv: Position adaptive convolution with dynamic kernel assembling on point clouds,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 3172–3181.
|
| [36] |
J. X. Li, B. M. Chen, and G. H. Lee, “SO-Net: Self-organizing network for point cloud analysis,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018, pp. 9397–9406.
|
| [37] |
Y. Wang, Y. B. Sun, Z. W. Liu, S. E. Sarma, M. M. Bronstein, and J. M. Solomon, “Dynamic graph CNN for learning on point clouds,” ACM Trans. Graph., vol. 38, no. 5, p. 146, Oct. 2019.
|
| [38] |
C. Wang, B. Samari, and K. Siddiqi, “Local spectral graph convolution for point set feature learning,” in Proc. 15th European Conf. Computer Vision, Munich, Germany, 2018, pp. 56–71.
|
| [39] |
T. G. Xiang, C. Y. Zhang, Y. Song, J. H. Yu, and W. D. Cai, “Walk in the cloud: Learning curves for point clouds shape analysis,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 895–904.
|
| [40] |
M. T. Xu, J. H. Zhang, Z. P. Zhou, M. Y. Xu, X. J. Qi, and Y. Qiao, “Learning geometry-disentangled representation for complementary understanding of 3D object point cloud,” in Proc. 35th AAAI Conf. Artificial Intelligence, 2021, pp. 3056–3064.
|
| [41] |
H. X. Ran, W. Zhuo, J. Liu, and L. Lu, “Learning inner-group relations on point clouds,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 15457–15467.
|
| [42] |
S. Q. Fan, Q. L. Dong, F. H. Zhu, Y. S. Lv, P. J. Ye, and F. Y. Wang, “SCF-Net: Learning spatial contextual features for large-scale point cloud segmentation,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 14499–14508.
|
| [43] |
Z. Liu, Y. T. Lin, Y. Cao, H. Hu, Y. X. Wei, Z. Zhang, S. Lin, and B. N. Guo, “Swin Transformer: Hierarchical vision transformer using shifted windows,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 9992–10002.
|
| [44] |
X. Yan, C. D. Zheng, Z. Li, S. Wang, and S. G. Cui, “PointASNL: Robust point clouds processing using nonlocal neural networks with adaptive sampling,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2020, pp. 5588–5597.
|
| [45] |
X. L. Wang, R. Girshick, A. Gupta, and K. M. He, “Non-local neural networks,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018, pp. 7794–7803.
|
| [46] |
G. C. Qian, Y. C. Li, H. W. Peng, J. J. Mai, H. A. Al Kader Hammoud, M. Elhoseiny, and B. Ghanem, “PointNeXt: Revisiting PointNet++ with improved training and scaling strategies,” in Proc. 36th Conf. Neural Information Processing Systems, New Orleans, USA, 2022.
|
| [47] |
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16 × 16 words: Transformers for image recognition at scale,” in Proc. 9th Int. Conf. Learning Representations, Austria, 2021.
|
| [48] |
W. H. Wang, E. Z. Xie, X. Li, D. P. Fan, K. T. Song, D. Liang, T. Lu, P. Luo, and L. Shao, “Pyramid vision transformer: A versatile backbone for dense prediction without convolutions,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 548–558.
|
| [49] |
W. H. Wang, E. Z. Xie, X. Li, D. Fan, K. T. Song, D. Liang, T. Lu, L uo, and L. Shao, “PVT v2: Improved baselines with pyramid vision transformer,” Comput. Vis. Media, vol. 8, no. 3, pp. 415–424, Sept. 2022. doi: 10.1007/s41095-022-0274-8
|
| [50] |
K. Han, A. Xiao, E. H. Wu, J. Y. Guo, C. J. Xu, and Y. H. Wang, “Transformer in transformer,” in Proc. 35th Conf. Neural Information Processing Systems, 2021, pp. 15908–15919.
|
| [51] |
X. Y. Dong, J. M. Bao, D. D. Chen, W. M. Zhang, N. H. Yu, L. Yuan, D. Chen, and B. N. Guo, “CSWin transformer: A general vision transformer backbone with cross-shaped windows,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 12114–12124.
|
| [52] |
A. Hassani, S. Walton, J. C. Li, S. Li, and H. Shi, Neighborhood attention transformer. 2022. arXiv preprint arXiv: 2204.07143.
|
| [53] |
Z. H. Huang, Y. C. Ben, G. Z. Luo, P. Cheng, G. Yu, and B. Fu, Shuffle transformer: Rethinking spatial shuffle for vision transformer. 2021. arXiv preprint arXiv: 2106.03650.
|
| [54] |
K. Liu, T. Y. Wu, C. Liu, and G. D. Guo, “Dynamic group transformer: A general vision transformer backbone with dynamic group attention,” in Proc. 31st Int. Joint Conf. Artificial Intelligence, Vienna, Austria, 2022, pp. 1187–1193.
|
| [55] |
T. Yu, G. M. Zhao, P. Li, and Y. Z. Yu, “BOAT: Bilateral local attention vision transformer,” in Proc. 33rd British Machine Vision Conf., London, UK, 2022.
|
| [56] |
H. S. Zhao, J. Y. Jia, and V. Koltun, “Exploring self-attention for image recognition,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2020, pp. 10073–10082.
|
| [57] |
D. Lee, J. Lee, J. Lee, H. Lee, M. Lee, S. Woo, and S. Lee, “Regularization strategy for point cloud via rigidly mixed sample,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 15895–15904.
|
| [58] |
X. Ma, C. Qin, H. X. You, H. X. Ran, and Y. Fu, “Rethinking network design and local geometry in point cloud: A simple residual MLP framework,” in Proc. 10th Int. Conf. Learning Representations, 2022.
|
| [59] |
S. Qiu, S. Anwar, and N. Barnes, “Geometric back-projection network for point cloud classification,” IEEE Trans. Multimedia, vol. 24, pp. 1943–1955, Jan. 2022. doi: 10.1109/TMM.2021.3074240
|
| [60] |
S. L. Cheng, X. W. Chen, X. W. He, Z. Liu, and X. Bai, “PRA-Net: Point relation-aware network for 3D point cloud analysis,” IEEE Trans. Image Process., vol. 30, pp. 4436–4448, Apr. 2021. doi: 10.1109/TIP.2021.3072214
|
| [61] |
X. M. Yu, L. L. Tang, Y. M. Rao, T. J. Huang, J. Zhou, and J. W. Lu, “Point-BERT: Pre-training 3D point cloud transformers with masked point modeling,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 19291–19300.
|
| [62] |
Y. T. Pang, W. X. Wang, F. E. H. Tay, W. Liu, Y. H. Tian, and L. Yuan, “Masked autoencoders for point cloud self-supervised learning,” in Proc. 17th European Conf. Computer Vision, Tel Aviv, Israel, 2022, pp. 604–621.
|
| [63] |
L. Hu, S. C. Yang, X. Luo, and M. C. Zhou, “An algorithm of inductively identifying clusters from attributed graphs,” IEEE Trans. Big Data, vol. 8, no. 2, pp. 523–534, Apr. 2022.
|
| [64] |
L. Hu, X. Y. Pan, Z. H. Tang, and X. Luo, “A fast fuzzy clustering algorithm for complex networks via a generalized momentum method,” IEEE Trans. Fuzzy Syst., vol. 30, no. 9, pp. 3473–3485, Sept. 2022. doi: 10.1109/TFUZZ.2021.3117442
|

Figures(6) / Tables(7)






 DownLoad:
DownLoad: