A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 9
Issue 3
Volume 9
Issue 3
IEEE/CAA Journal of Automatica Sinica
| Citation: | L. N. Xia, Q. Li, R. Z. Song, and H. Modares, “Optimal synchronization control of heterogeneous asymmetric input-constrained unknown nonlinear MASs via reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 3, pp. 520–532, Mar. 2022. doi: 10.1109/JAS.2021.1004359

|

| [1] |
S. R. Oh and S. K. Agrawal, “The feasible workspace analysis of a set point control for a cable-suspended robot with input constraints and disturbances,” IEEE Trans. Control Syst. Technol., vol. 14, no. 4, pp. 735–742, Jul. 2006. doi: 10.1109/TCST.2006.872515
|
| [2] |
R. W. Beard, J. Ferrin, and J. Humpherys, “Fixed wing UAV path following in wind with input constraints,” IEEE Trans. Control Syst. Technol., vol. 22, no. 6, pp. 2103–2117, Nov. 2014. doi: 10.1109/TCST.2014.2303787
|
| [3] |
F. L. Lewis, H. Zhang, K. Hengster-Movric, and A. Das, Cooperative Control of Multi-Agent Systems: Optimal and Adaptive Design Approaches. London, UK: Springer-Verlag, 2013.
|
| [4] |
R. Z. Song and L. Zhu, “Optimal fixed-point tracking control for discrete-time nonlinear systems via ADP,” IEEE/CAA Journal of Automatica Sinica, vol. 6, no. 3, pp. 657–666, May 2019. doi: 10.1109/JAS.2019.1911453
|
| [5] |
Y. L. Yang, H. Modares, D. C. Wunsch, and Y. X. Yin, “Leader-follower output synchronization of linear heterogeneous systems with active leader using reinforcement learning,” IEEE Trans. Neural Netw. Learn. Syst., vol. 29, no. 6, pp. 2139–2153, Jun. 2018. doi: 10.1109/TNNLS.2018.2803059
|
| [6] |
M. Abu-Khalaf and F. L. Lewis, “Nearly optimal control laws for nonlinear systems with saturating actuators using a neural network HJB approach,” Automatica, vol. 41, no. 5, pp. 779–791, 2005. doi: 10.1016/j.automatica.2004.11.034
|
| [7] |
H. Modares, F. L. Lewis, and M. B. Naghibi-Sistani, “Adaptive optimal control of unknown constrained-input systems using policy iteration and neural networks,” IEEE Trans. Neural Netw. Learn. Syst., vol. 24, no. 10, pp. 1513–1525, Oct. 2013. doi: 10.1109/TNNLS.2013.2276571
|
| [8] |
Y. H. Zhu, D. B. Zhao, H. B. He, and J. H. Ji, “Event-triggered optimal control for partially unknown constrained-input systems via adaptive dynamic programming,” IEEE Trans. Ind. Electron., vol. 64, no. 5, pp. 4101–4109, May 2017. doi: 10.1109/TIE.2016.2597763
|
| [9] |
X. X. Guo, W. S. Yan, and R. X. Cui, “Reinforcement learning-based nearly optimal control for constrained-input partially unknown systems using differentiator,” IEEE Trans. Neural Netw. Learn. Syst., vol. 31, no. 11, pp. 4713–4725, Nov. 2020. doi: 10.1109/TNNLS.2019.2957287
|
| [10] |
X. Yuan, L. Dong, and C. Y. Sun, “Solver-critic: A reinforcement learning method for discrete-time-constrained-input systems,” IEEE Trans. Cybern., to be published. DOI: 10.1109/TCYB.2020.2978088
|
| [11] |
J. L. Du, X. Hu, and Y. Q. Sun, “Adaptive robust nonlinear control design for course tracking of ships subject to external disturbances and input saturation,” IEEE Trans. Syst. Man Cybern.:Syst., vol. 50, no. 1, pp. 193–202, Jan. 2020. doi: 10.1109/TSMC.2017.2761805
|
| [12] |
H. G. Zhang, G. Y. Xiao, Y. Liu, and L. Liu, “Value iteration-based H∞ controller design for continuous-time nonlinear systems subject to input constraints,” IEEE Trans. Syst. Man Cybern.:Syst., vol. 50, no. 11, pp. 3986–3995, Nov. 2020. doi: 10.1109/TSMC.2018.2853091
|
| [13] |
X. L. Wang, D. R. Ding, H. L. Dong, and X. M. Zhang, “Neural-network-based control for discrete-time nonlinear systems with input saturation under stochastic communication protocol,” IEEE/CAA Journal of Automatica Sinica, vol. 8, no. 4, pp. 766–778, Apr. 2021. doi: 10.1109/JAS.2021.1003922
|
| [14] |
W. W. Bai, Q. Zhou, T. S. Li, and H. Y. Li, “Adaptive reinforcement learning neural network control for uncertain nonlinear system with input saturation,” IEEE Trans. Cybern., vol. 50, no. 8, pp. 3433–3443, Aug. 2020. doi: 10.1109/TCYB.2019.2921057
|
| [15] |
L. Wang, H. J. Gong, and C. S. Liu, “Disturbance observer-based adaptive fault-tolerant dynamic surface control of nonlinear system with asymmetric input saturation,” Int. J. Control Autom. Syst., vol. 17, no. 3, pp. 617–629, Mar. 2019. doi: 10.1007/s12555-018-0099-5
|
| [16] |
L. H. Kong, W. He, Y. T. Dong, L. Cheng, C. G. Yang, and Z. J. Li, “Asymmetric bounded neural control for an uncertain robot by state feedback and output feedback,” IEEE Trans. Syst. Man Cybern.:Syst., vol. 51, no. 3, pp. 1735–1746, Mar. 2021.
|
| [17] |
X. Yang and B. Zhao, “Optimal neuro-control strategy for nonlinear systems with asymmetric input constraints,” IEEE/CAA Journal of Automatica Sinica, vol. 7, no. 2, pp. 575–583, Mar. 2020. doi: 10.1109/JAS.2020.1003063
|
| [18] |
W. Zhou, H. C. Liu, H. B. He, J. Yi, and T. F. Li, “Neuro-optimal tracking control for continuous stirred tank reactor with input constraints,” IEEE Trans. Ind. Inform., vol. 15, no. 8, pp. 4516–4524, Aug. 2019. doi: 10.1109/TII.2018.2884214
|
| [19] |
M. T. Cao, F. Xiao, and L. Wang, “Event-based second-order consensus control for multi-agent systems via synchronous periodic event detection,” IEEE Trans. Automat. Control, vol. 60, no. 9, pp. 2452–2457, Sep. 2015. doi: 10.1109/TAC.2015.2390553
|
| [20] |
J. Liu, Y. L. Zhang, Y. Yu, and C. Y. Sun, “Fixed-time leader-follower consensus of networked nonlinear systems via event/self-triggered control,” IEEE Trans. Neural Netw. Learn. Syst., vol. 31, no. 11, pp. 5029–5037, Nov. 2020. doi: 10.1109/TNNLS.2019.2957069
|
| [21] |
A. Shariati and M. Tavakoli, “A descriptor approach to robust leader-following output consensus of uncertain multi-agent systems with delay,” IEEE Trans. Automat. Control, vol. 62, no. 10, pp. 5310–5317, Oct. 2017. doi: 10.1109/TAC.2016.2643444
|
| [22] |
Z. Q. Zuo, J. Zhang, and Y. J. Wang, “Adaptive fault-tolerant tracking control for linear and lipschitz nonlinear multi-agent systems,” IEEE Trans. Ind. Electron., vol. 62, no. 6, pp. 3923–3931, Jun. 2015.
|
| [23] |
H. Modares, S. P. Nageshrao, G. A. D. Lopes, R. Babuška, and F. L. Lewis, “Optimal model-free output synchronization of heterogeneous systems using off-policy reinforcement learning,” Automatica, vol. 71, pp. 334–341, Sep. 2016. doi: 10.1016/j.automatica.2016.05.017
|
| [24] |
Z. T. Li, L. X. Gao, W. H. Chen, and Y. Xu, “Distributed adaptive cooperative tracking of uncertain nonlinear fractional-order multi-agent systems,” IEEE/CAA Journal of Automatica Sinica, vol. 7, no. 1, pp. 292–300, Jan. 2020. doi: 10.1109/JAS.2019.1911858
|
| [25] |
G. H. Wen, Y. Zhao, Z. S. Duan, W. W. Yu, and G. R. Chen, “Containment of higher-order multi-leader multi-agent systems: A dynamic output approach,” IEEE Trans. Automat. Control, vol. 61, no. 4, pp. 1135–1140, Apr. 2016. doi: 10.1109/TAC.2015.2465071
|
| [26] |
H. Z. Xiao, Z. J. Li, and C. L. P. Chen, “Formation control of leader–follower mobile robots’ systems using model predictive control based on neural-dynamic optimization,” IEEE Trans. Ind. Electron., vol. 63, no. 9, pp. 5752–5762, Sep. 2016. doi: 10.1109/TIE.2016.2542788
|
| [27] |
G. X. Wen, C. L. P. Chen, and B. Li, “Optimized formation control using simplified reinforcement learning for a class of multiagent systems with unknown dynamics,” IEEE Trans. Ind. Electron., vol. 67, no. 9, pp. 7879–7888, Sep. 2020. doi: 10.1109/TIE.2019.2946545
|
| [28] |
J. J. Fu, G. H. Wen, W. W. Yu, T. W. Huang, and X. H. Yu, “Consensus of second-order multiagent systems with both velocity and input constraints,” IEEE Trans. Ind. Electron., vol. 66, no. 10, pp. 7946–7955, Oct. 2019. doi: 10.1109/TIE.2018.2879292
|
| [29] |
X. Li, C. C. Li, and Y. K. Yang, “Heterogeneous linear multi-agent consensus with nonconvex input constraints and switching graphs,” Inform. Sci., vol. 501, pp. 397–405, Oct. 2019. doi: 10.1016/j.ins.2019.06.013
|
| [30] |
R. P. Zou, J. Sun, J. L. Sun, T. Long, and A. L. Wei, “Leader-following constrained distributed adaptive dynamic programming design for multiagent systems,” in Proc. Chinese Automation Congress (CAC), Hangzhou, China, 2019, pp. 5345–5349.
|
| [31] |
H. Sun, Y. G. Liu, X. L. Niu, and H. J. Liang, “Optimal leader-following consensus of nonlinear heterogeneous multi-agent systems with input constraints,” in Proc. 37th Chinese Control Conf. (CCC), Wuhan, China, 2018, pp. 7130–7135.
|
| [32] |
M. Imani and S. F. Ghoreishi, “Optimal finite-horizon perturbation policy for inference of gene regulatory networks,” IEEE Intell. Syst., vol. 36, no. 1, pp. 54–63, Jan.-Feb. 2021. doi: 10.1109/MIS.2020.3017155
|
| [33] |
Z. C. Cao, Q. Xiao, R. Huang, and M. C. Zhou, “Robust neuro-optimal control of underactuated snake robots with experience replay,” IEEE Trans. Neural Netw. Learn. Syst., vol. 29, no. 1, pp. 208–217, Jan. 2018. doi: 10.1109/TNNLS.2017.2768820
|
| [34] |
H. G. Zhang, C. B. Qin, B. Jiang, and Y. H. Luo, “Online adaptive policy learning algorithm for H∞ state feedback control of unknown affine nonlinear discrete-time systems,” IEEE Trans. Cybern., vol. 44, no. 12, pp. 2706–2718, Dec. 2014. doi: 10.1109/TCYB.2014.2313915
|
| [35] |
D. R. Liu, Y. C. Xu, Q. L. Wei, and X. L. Liu, “Residential energy scheduling for variable weather solar energy based on adaptive dynamic programming,” IEEE/CAA Journal of Automatica Sinica, vol. 5, no. 1, pp. 36–46, Jan. 2018. doi: 10.1109/JAS.2017.7510739
|
| [36] |
Q. L. Wei, D. R. Liu, Y. Liu, and R. Z. Song, “Optimal constrained self-learning battery sequential management in microgrid via adaptive dynamic programming,” IEEE/CAA Journal of Automatica Sinica, vol. 4, no. 2, pp. 168–176, Apr. 2017. doi: 10.1109/JAS.2016.7510262
|
| [37] |
M. Imani and U. M. Braga-Neto, “Control of gene regulatory networks using bayesian inverse reinforcement learning,” IEEE/ACM Trans. Comput. Biol. Bioinform., vol. 16, no. 4, pp. 1250–1261, Jul.-Aug. 2019. doi: 10.1109/TCBB.2018.2830357
|
| [38] |
H. Y. Li, Y. Wu, and M. Chen, “Adaptive fault-tolerant tracking control for discrete-time multiagent systems via reinforcement learning algorithm,” IEEE Trans. Cybern., vol. 51, no. 3, pp. 1163–1174, Mar. 2021. doi: 10.1109/TCYB.2020.2982168
|
| [39] |
M. Imani and S. F. Ghoreishi, “Scalable inverse reinforcement learning through multifidelity Bayesian optimization,” IEEE Trans. Neural Netw. Learn. Syst., to be published. DOI: 10.1109/TNNLS.2021.3051012
|
| [40] |
W. W. Bai, T. S. Li, and S. C. Tong, “NN reinforcement learning adaptive control for a class of nonstrict-feedback discrete-time systems,” IEEE Trans. Cybern., vol. 50, no. 11, pp. 4573–4584, Nov. 2020. doi: 10.1109/TCYB.2020.2963849
|
| [41] |
M. Abu-Khalaf, F. L. Lewis, and J. Huang, “Policy iterations on the Hamilton–Jacobi–Isaacs equation for H∞ state feedback control with input saturation,” IEEE Trans. Automat. Control, vol. 51, no. 12, pp. 1989–1995, Dec. 2006. doi: 10.1109/TAC.2006.884959
|
| [42] |
C. X. Mu, K. Wang, and C. Y. Sun, “Policy-iteration-based learning for nonlinear player game systems with constrained inputs,” IEEE Trans. Systems,Man,and Cybernetics:Systems, vol. 51, no. 10, pp. 6488–6502, Oct. 2021. doi: 10.1109/TSMC.2019.2962629
|
| [43] |
H. Modares, F. L. Lewis, and M. B. Naghibi-Sistani, “Integral reinforcement learning and experience replay for adaptive optimal control of partially-unknown constrained-input continuous-time systems,” Automatica, vol. 50, no. 1, pp. 193–202, Jan. 2014. doi: 10.1016/j.automatica.2013.09.043
|
| [44] |
H. G. Zhang, K. Zhang, G. Y. Xiao, and H. Jiang, “Robust optimal control scheme for unknown constrained-input nonlinear systems via a plug-n-play event-sampled critic-only algorithm,” IEEE Trans. Syst. Man Cybern.:Syst., vol. 50, no. 9, pp. 3169–3180, Sep. 2020. doi: 10.1109/TSMC.2018.2889377
|
| [45] |
B. Kiumarsi and F. L. Lewis, “Actor–critic-based optimal tracking for partially unknown nonlinear discrete-time systems,” IEEE Trans. Neural Netw. Learn. Syst., vol. 26, no. 1, pp. 140–151, Jan. 2015. doi: 10.1109/TNNLS.2014.2358227
|
| [46] |
R. Z. Song, F. L. Lewis, Q. L. Wei, and H. G. Zhang, “Off-policy actor-critic structure for optimal control of unknown systems with disturbances,” IEEE Trans. Cybern., vol. 46, no. 5, pp. 1041–1050, May 2016. doi: 10.1109/TCYB.2015.2421338
|
| [47] |
G. X. Wen, C. L. P. Chen, S. S. Ge, H. L. Yang, and X. G. Liu, “Optimized adaptive nonlinear tracking control using actor–critic reinforcement learning strategy,” IEEE Trans. Ind. Inform., vol. 15, no. 9, pp. 4969–4977, Sep. 2019. doi: 10.1109/TII.2019.2894282
|
| [48] |
W. Zhu and Z. P. Jiang, “Event-based leader-following consensus of multi-agent systems with input time delay,” IEEE Trans. Automat. Control, vol. 60, no. 5, pp. 1362–1367, May 2015. doi: 10.1109/TAC.2014.2357131
|
| [49] |
W. Zhu, W. J. Cao, and Z. P. Jiang, “Distributed event-triggered formation control of multiagent systems via complex-valued Laplacian,” IEEE Trans. Cybern., vol. 51, no. 4, pp. 2178–2187, Apr. 2021. doi: 10.1109/TCYB.2019.2908190
|
| [50] |
H. Modares, B. Kiumarsi, F. L. Lewis, F. Ferrese, and A. Davoudi, “Resilient and robust synchronization of multiagent systems under attacks on sensors and actuators,” IEEE Trans. Cybern., vol. 50, no. 3, pp. 1240–1250, Mar. 2020. doi: 10.1109/TCYB.2019.2903411
|
| [51] |
Z. K. Li, G. H. Wen, Z. S. Duan, and W. Ren, “Designing fully distributed consensus protocols for linear multi-agent systems with directed graphs,” IEEE Trans. Automat. Control, vol. 60, no. 4, pp. 1152–1157, Apr. 2015. doi: 10.1109/TAC.2014.2350391
|
| [52] |
H. Modares, F. L. Lewis, and Z. P. Jiang, “H∞ tracking control of completely unknown continuous-time systems via off-policy reinforcement learning,” IEEE Trans. Neural Netw. Learn. Syst., vol. 26, no. 10, pp. 2550–2562, Oct. 2015. doi: 10.1109/TNNLS.2015.2441749
|
| [53] |
H. G. Zhang, Y. L. Liang, H. G. Su, and C. Liu, “Event-driven guaranteed cost control design for nonlinear systems with actuator faults via reinforcement learning algorithm,” IEEE Trans. Syst. Man Cybern.:Syst., vol. 50, no. 11, pp. 4135–4150, Nov. 2020. doi: 10.1109/TSMC.2019.2946857
|
| [54] |
H. W. Lin, B. Zhao, D. R. Liu, and C. Alippi, “Data-based fault tolerant control for affine nonlinear systems through particle swarm optimized neural networks,” IEEE/CAA Journal of Automatica Sinica, vol. 7, no. 4, pp. 954–964, Jul. 2020. doi: 10.1109/JAS.2020.1003225
|
| [55] |
H. Wang and M. Li, “Model-free reinforcement learning for fully cooperative consensus problem of nonlinear multiagent systems,” IEEE Trans. Neural Netw. Learn. Syst., to be published. DOI: 10.1109/TNNLS.2020.3042508
|
| [56] |
H. Modares, F. L. Lewis, W. Kang, and A. Davoudi, “Optimal synchronization of heterogeneous nonlinear systems with unknown dynamics,” IEEE Trans. Automat. Control, vol. 63, no. 1, pp. 117–131, Jan. 2018. doi: 10.1109/TAC.2017.2713339
|
| [57] |
M. Green and D. J. N. Limebeer, Linear Robust Control. Englewood Cliffs, NJ: Prentice-Hall, 1995.
|
| [58] |
D. R. Liu and Q. L. Wei, “Policy iteration adaptive dynamic programming algorithm for discrete-time nonlinear systems,” IEEE Trans. Neural Netw. Learn. Syst., vol. 25, no. 3, pp. 621–634, Mar. 2014. doi: 10.1109/TNNLS.2013.2281663
|
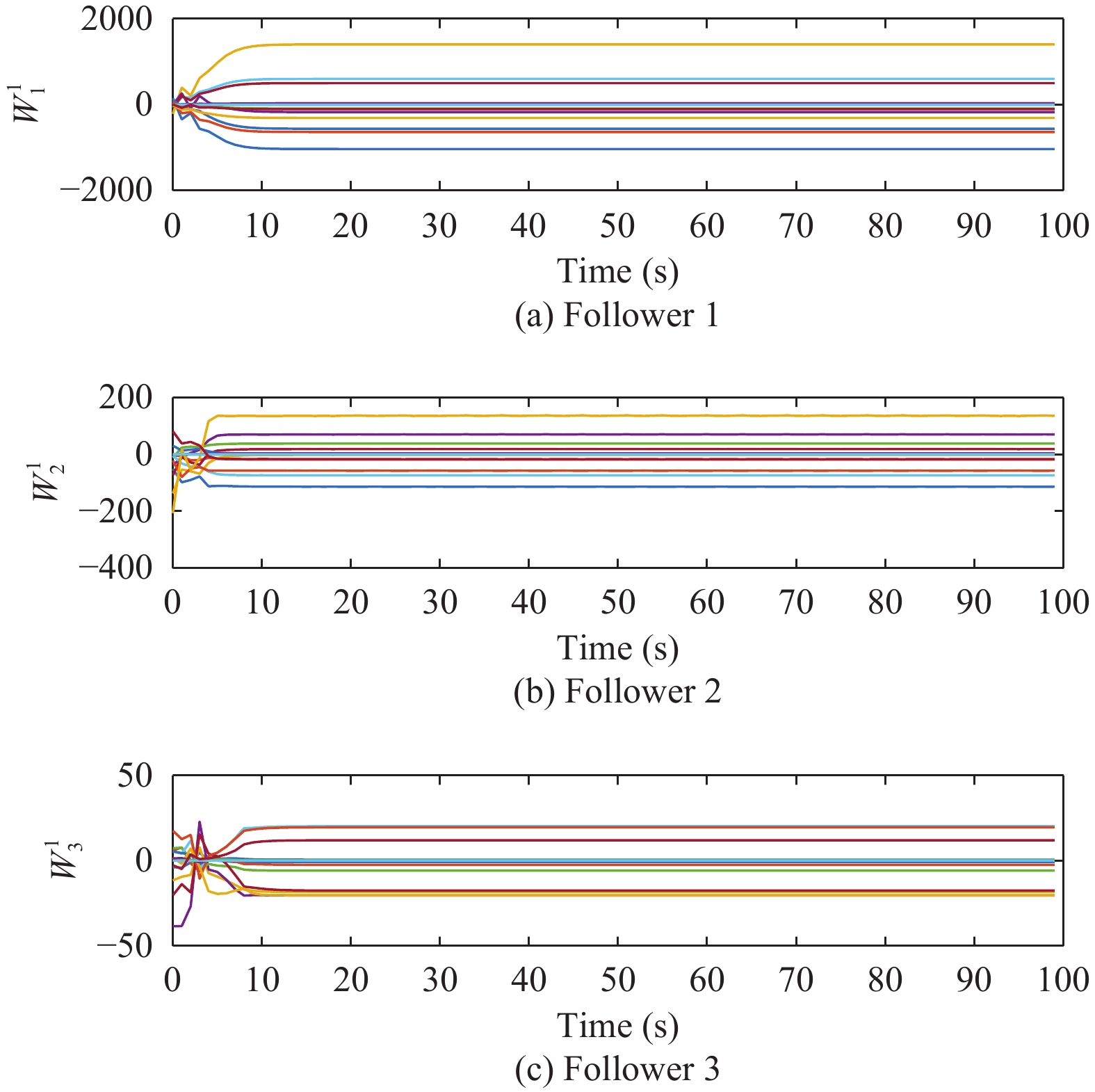
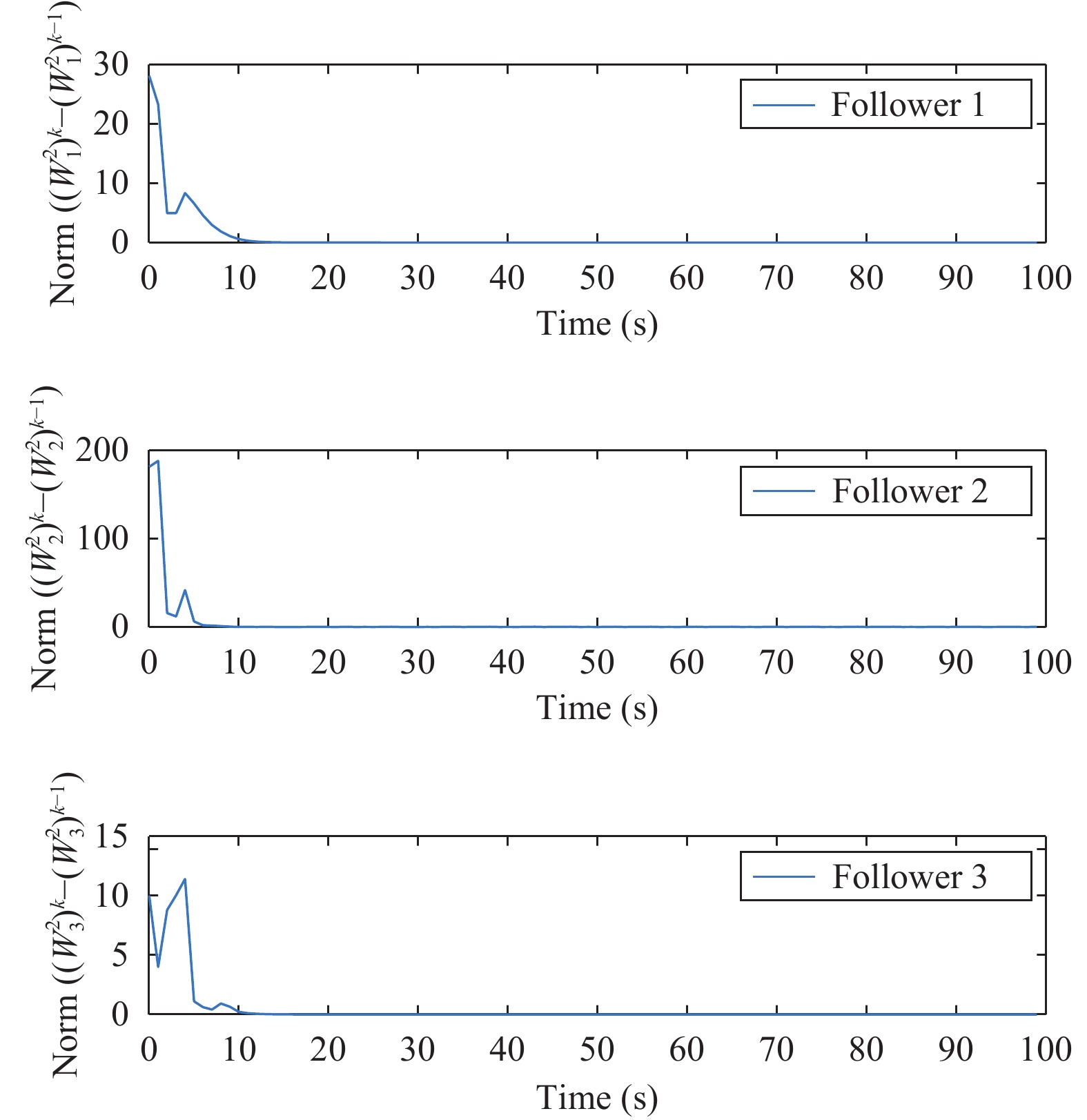
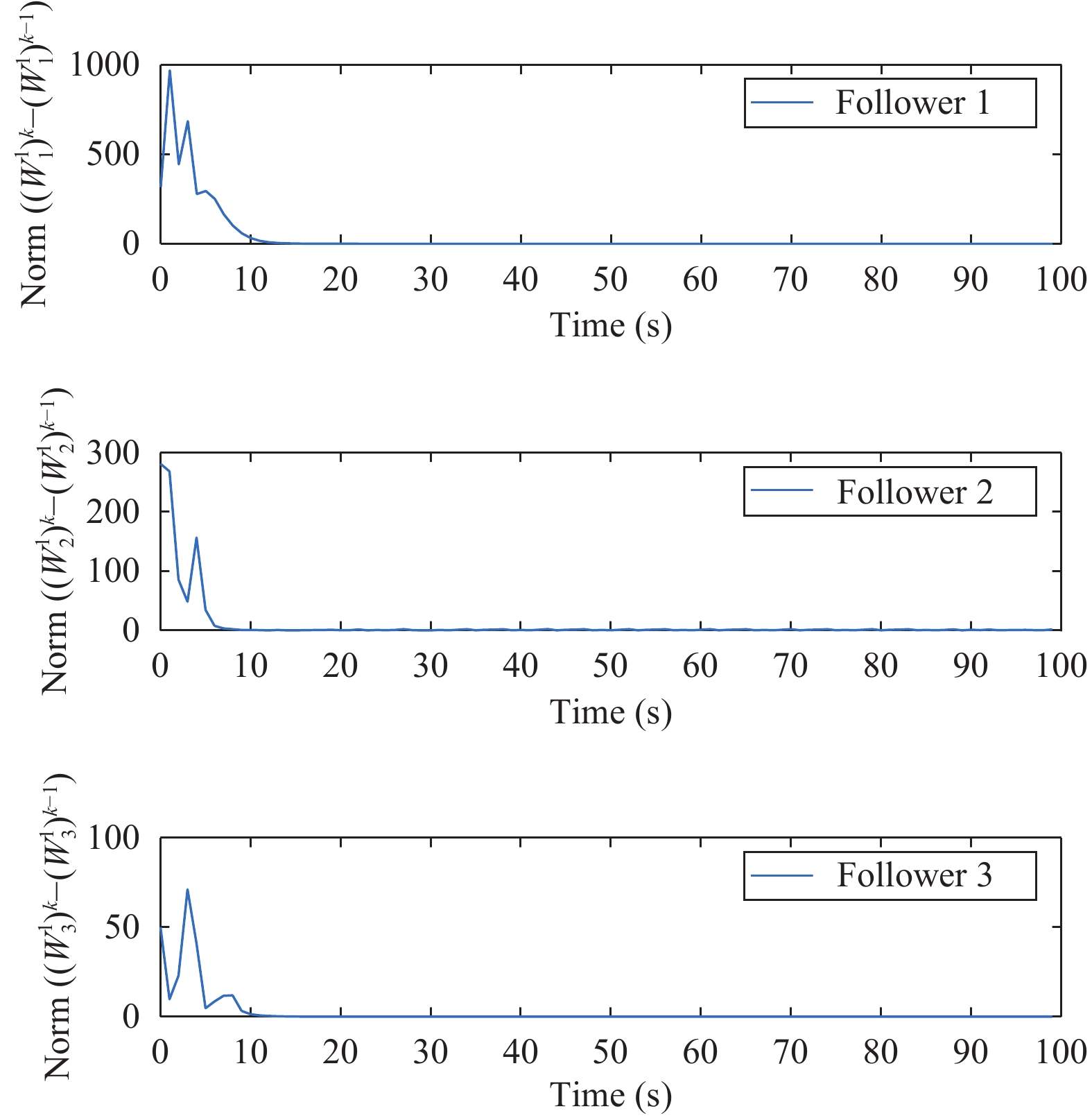
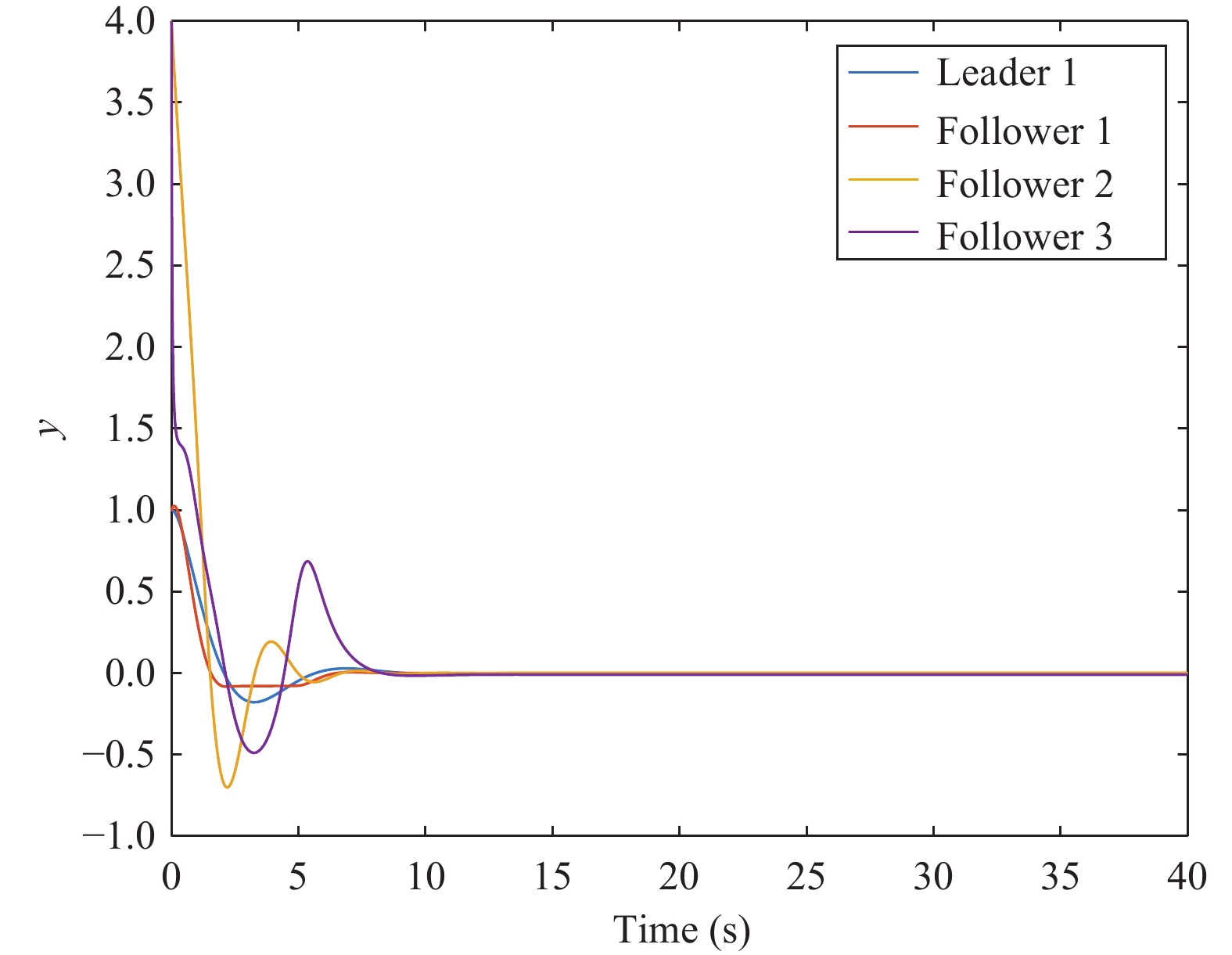
Figures(11)






 DownLoad:
DownLoad: