A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 12
Issue 5
Volume 12
Issue 5
IEEE/CAA Journal of Automatica Sinica
| Citation: | L. Xiong, H. Wang, X. Chen, L. Sheng, Y. Xiong, J. Liu, Y. Xiao, H. Chen, Q.-L. Han, and Y. Tang, “DeepSeek: Paradigm shifts and technical evolution in large AI models,” IEEE/CAA J. Autom. Sinica, vol. 12, no. 5, pp. 841–858, May 2025. doi: 10.1109/JAS.2025.125495

|

| [1] |
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al., “DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning,” arXiv preprint arXiv: 2501.12948, 2025.
|
| [2] |
E. Gibney, “China’s cheap, open AI model DeepSeek thrills scientists,” Nature, vol. 638, no. 8049, pp. 13–14, Jan. 2025. doi: 10.1038/d41586-025-00229-6
|
| [3] |
C. Metz, “What to know about DeepSeek and how it is upending A.I.,” [Online]. Available: https://www.nytimes.com/2025/01/27/technology/what-is-deepseek-china-ai.html. Accessed on: January 27, 2025.
|
| [4] |
A. Picchi, “What is DeepSeek, and why is it causing Nvidia and other stocks to slump?” [Online]. Available: https://www.cbsnews.com/news/what-is-deepseek-ai-china-stock-nvidia-nvda-asml/. Accessed on: January 28, 2025.
|
| [5] |
T. Wu, S. He, J. Liu, S. Sun, K. Liu, Q.-L. Han, and Y. Tang, “A brief overview of ChatGPT: The history, status quo and potential future development,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 5, pp. 1122–1136, May 2023. doi: 10.1109/JAS.2023.123618
|
| [6] |
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proc. Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1, Minneapolis, USA, 2018, pp. 4171–4186.
|
| [7] |
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe, “Training language models to follow instructions with human feedback,” in Proc. 36th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2022, pp. 2011.
|
| [8] |
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” in Proc. 38th Int. Conf. Machine Learning, 2021, pp. 8748–8763.
|
| [9] |
J. Li, T. Tang, W. X. Zhao, J.-Y. Nie, and J.-R. Wen, “Pre-trained language models for text generation: A survey,” ACM Comput. Surv., vol. 56, no. 9, p. 230, Sept. 2024.
|
| [10] |
B. Min, H. Ross, E. Sulem, A. P. B. Veyseh, T. H. Nguyen, O. Sainz, E. Agirre, I. Heintz, and D. Roth, “Recent advances in natural language processing via large pre-trained language models: A survey,” ACM Comput. Surv., vol. 56, no. 2, p. 30, Feb. 2024.
|
| [11] |
N. Karanikolas, E. Manga, N. Samaridi, E. Tousidou, and M. Vassilakopoulos, “Large language models versus natural language understanding and generation,” in Proc. 27th Pan-Hellenic Conf. Progress in Computing and Informatics, Lamia, Greece, 2023, pp. 278–290.
|
| [12] |
R. Sarikaya, G. E. Hinton, and A. Deoras, “Application of deep belief networks for natural language understanding,” IEEE/ACM Trans. Audio Speech Lang. Process., vol. 22, no. 4, pp. 778–784, Apr. 2014. doi: 10.1109/TASLP.2014.2303296
|
| [13] |
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, P. Schuh, K. Shi, S. Tsvyashchenko, J. Maynez, A. Rao, P. Barnes, Y. Tay, N. Shazeer, V. Prabhakaran, E. Reif, N. Du, B. Hutchinson, R. Pope, J. Bradbury, J. Austin, M. Isard, G. Gur-Ari, P. Yin, T. Duke, A. Levskaya, S. Ghemawat, S. Dev, H. Michalewski, X. Garcia, V. Misra, K. Robinson, L. Fedus, D. Zhou, D. Ippolito, D. Luan, H. Lim, B. Zoph, A. Spiridonov, R. Sepassi, D. Dohan, S. Agrawal, M. Omernick, A. M. Dai, T. S. Pillai, M. Pellat, A. Lewkowycz, E. Moreira, R. Child, O. Polozov, K. Lee, Z. Zhou, X. Wang, B. Saeta, M. Diaz, O. Firat, M. Catasta, J. Wei, K. Meier-Hellstern, D. Eck, J. Dean, S. Petrov, and N. Fiedel, “PaLM: Scaling language modeling with pathways,” J. Mach. Learn. Res., vol. 24, no. 1, p. 240, Jan. 2023.
|
| [14] |
M. Nadeem, S. S. Sohail, L. Javed, F. Anwer, A. K. J. Saudagar, and K. Muhammad, “Vision-enabled large language and deep learning models for image-based emotion recognition,” Cogn. Comput., vol. 16, no. 5, pp. 2566–2579, 2024. doi: 10.1007/s12559-024-10281-5
|
| [15] |
K. Bayoudh, R. Knani, F. Hamdaoui, and A. Mtibaa, “A survey on deep multimodal learning for computer vision: Advances, trends, applications, and datasets,” Vis. Comput., vol. 38, no. 8, pp. 2939–2970, Aug. 2022. doi: 10.1007/s00371-021-02166-7
|
| [16] |
R. Archana and P. S. E. Jeevaraj, “Deep learning models for digital image processing: A review,” Artif. Intell. Rev., vol. 57, no. 1, p. 11, Jan. 2024. doi: 10.1007/s10462-023-10631-z
|
| [17] |
“AI Action Summit (10 and 11 February 2025),” [Online]. Available: https://onu.delegfrance.org/ai-action-summit-10-and-11-february-2025. Accessed on: May 1, 2025.
|
| [18] |
Y. Tan, D. Min, Y. Li, W. Li, N. Hu, Y. Chen, and G. Qi, “Can ChatGPT replace traditional KBQA models? An in-depth analysis of the question answering performance of the GPT LLM family,” in Proc. 22nd Int. Semantic Web Conf., Athens, Greece, 2023, pp. 348–367.
|
| [19] |
M. M. Lucas, J. Yang, J. K. Pomeroy, and C. C. Yang, “Reasoning with large language models for medical question answering,” J. Am. Med. Inform. Assoc., vol. 31, no. 9, pp. 1964–1975, Sept. 2024. doi: 10.1093/jamia/ocae131
|
| [20] |
L. Liao, G. H. Yang, and C. Shah, “Proactive conversational agents in the post-ChatGPT world,” in Proc. 46th Int. ACM SIGIR Conf. Research and Development in Information Retrieval, Taipei, China, 2023, pp. 3452–3455.
|
| [21] |
D. Choi, S. Lee, S.-I. Kim, K. Lee, H. J. Yoo, S. Lee, and H. Hong, “Unlock life with a chat (GPT): Integrating conversational AI with large language models into everyday lives of autistic individuals,” in Proc. CHI Conf. Human Factors in Computing Systems, Honolulu, USA, 2024, pp. 72.
|
| [22] |
A. Casheekar, A. Lahiri, K. Rath, K. S. Prabhakar, and K. Srinivasan, “A contemporary review on chatbots, AI-powered virtual conversational agents, ChatGPT: Applications, open challenges and future research directions,” Comput. Sci. Rev., vol. 52, p. 100632, May 2024. doi: 10.1016/j.cosrev.2024.100632
|
| [23] |
Y. Dong, X. Jiang, Z. Jin, and G. Li, “Self-collaboration code generation via ChatGPT,” ACM Trans. Softw. Eng. Methodol., vol. 33, no. 7, p. 189, Sept. 2024.
|
| [24] |
J. Liu, C. S. Xia, Y. Wang, and L. Zhang, “Is your code generated by ChatGPT really correct? Rigorous evaluation of large language models for code generation,” in Proc. 37th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2023, pp. 943.
|
| [25] |
Gemini Team, Google, “Gemini: A family of highly capable multimodal models,” arXiv preprint arXiv: 2312.11805, 2023.
|
| [26] |
“Introducing Claude 2.1,” [Online]. Available: https://www.anthropic.com/news/claude-2-1. Accessed on: May 1, 2025.
|
| [27] |
Meta AI, “Introducing llama 3.1: Our most capable models to date,” 2024. [Online]. Available: https://ai.meta.com/blog/meta-llama-3-1/. Accessed on: May 1, 2025.
|
| [28] |
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. Le Scao, T. Lavril, T. Wang, T. Lacroix, and W. El Sayed, “Mistral 7B,” arXiv preprint arXiv: 2310.06825, 2023.
|
| [29] |
F. Zhuang, Z. Qi, K. Duan, D. Xi, Y. Zhu, H. Zhu, H. Xiong, and Q. He, “A comprehensive survey on transfer learning,” Proc. IEEE, vol. 109, no. 1, pp. 43–76, Jan. 2021. doi: 10.1109/JPROC.2020.3004555
|
| [30] |
P. Xu, X. Zhu, and D. A. Clifton, “Multimodal learning with transformers: A survey,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 10, pp. 12113–12132, Oct. 2023. doi: 10.1109/TPAMI.2023.3275156
|
| [31] |
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al., “GPT-4 technical report,” arXiv preprint arXiv: 2303.08774, 2023.
|
| [32] |
“DALL·E 2,” [Online]. Available: https://openai.com/dall-e-2/. Accessed on: May 1, 2025.
|
| [33] |
X. Chen, Z. Wu, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, and C. Ruan, “Janus-pro: Unified multimodal understanding and generation with data and model scaling,” arXiv preprint arXiv: 2501.17811, 2025.
|
| [34] |
“Introducing OpenAI o1,” [Online]. Available: https://openai.com/o1/. Accessed on: May 1, 2025.
|
| [35] |
P. Wang, L. Li, Z. Shao, R. Xu, D. Dai, Y. Li, D. Chen, Y. Wu, and Z. Sui, “Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations,” in Proc. 62nd Annu. Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 2024, pp. 9426–9439.
|
| [36] |
“Grok 3 beta — the age of reasoning agents,” [Online]. Available: https://x.ai/blog/grok-3. Accessed on: May 1, 2025.
|
| [37] |
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, et al., “DeepSeek-V3 technical report,” arXiv preprint arXiv: 2412.19437, 2024.
|
| [38] |
X. Bi, D. Chen, G. Chen, S. Chen, D. Dai, C. Deng, H. Ding, K. Dong, Q. Du, Z. Fu, H. Gao, K. Gao, W. Gao, R. Ge, K. Guan, D. Guo, J. Guo, G. Hao, Z. Hao, Y. He, W. Hu, P. Huang, E. Li, G. Li, J. Li, Y. Li, Y. K. Li, W. Liang, F. Lin, A. X. Liu, B. Liu, W. Liu, X. Liu, X. Liu, Y. Liu, H. Lu, S. Lu, F. Luo, S. Ma, X. Nie, T. Pei, Y. Piao, J. Qiu, H. Qu, T. Ren, Z. Ren, C. Ruan, Z. Sha, Z. Shao, J. Song, X. Su, J. Sun, Y. Sun, M. Tang, B. Wang, P. Wang, S. Wang, Y. Wang, Y. Wang, T. Wu, Y. Wu, X. Xie, Z. Xie, Z. Xie, Y. Xiong, H. Xu, R. X. Xu, Y. Xu, D. Yang, Y. You, S. Yu, X. Yu, B. Zhang, H. Zhang, L. Zhang, L. Zhang, M. Zhang, M. Zhang, W. Zhang, Y. Zhang, C. Zhao, Y. Zhao, S. Zhou, S. Zhou, Q. Zhu, and Y. Zou, “DeepSeek LLM: Scaling open-source language models with longtermism,” arXiv preprint arXiv: 2401.02954, 2024.
|
| [39] |
D. Dai, C. Deng, C. Zhao, R. X. Xu, H. Gao, D. Chen, J. Li, W. Zeng, X. Yu, Y. Wu, Z. Xie, Y. K. Li, P. Huang, F. Luo, C. Ruan, Z. Sui, and W. Liang, “DeepSeekMoE: Towards ultimate expert specialization in mixture-of-experts language models,” in Proc. 62nd Annu. Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 2024, pp. 1280–1297.
|
| [40] |
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. K. Li, Y. Wu, and D. Guo, “DeepSeekMath: Pushing the limits of mathematical reasoning in open language models,” arXiv preprint arXiv: 2402.03300, 2024.
|
| [41] |
A. Liu, B. Feng, B. Wang, B. Wang, B. Liu, C. Zhao, C. Dengr, C. Ruan, D. Dai, D. Guo, et al., “Deepseek-V2: A strong, economical, and efficient mixture-of-experts language model,” arXiv preprint arXiv: 2405.04434, 2024.
|
| [42] |
P. Blunsom, “Hidden Markov models,” Lecture Notes, vol. 15, no. 18–19, pp. 48, 2004.
|
| [43] |
T. Brants, A. C. Popat, P. Xu, F. J. Och, and J. Dean, “Large language models in machine translation,” in Proc. Joint Conf. Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Prague, Czech Republic, 2007, pp. 858–867.
|
| [44] |
T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” in Proc. 27th Int. Conf. Neural Information Processing Systems, Lake Tahoe, USA, 2013, pp. 3111–3119.
|
| [45] |
J. Pennington, R. Socher, and C. D. Manning, “GloVe: Global vectors for word representation,” in Proc. Conf. Empirical Methods in Natural Language Processing, Doha, Qatar, 2014, pp. 1532–1543.
|
| [46] |
A. Sherstinsky, “Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network,” Physica D, vol. 404, p. 132306, Mar. 2020. doi: 10.1016/j.physd.2019.132306
|
| [47] |
S. Meshram and M. Anand Kumar, “Long short-term memory network for learning sentences similarity using deep contextual embeddings,” Int. J. Inf. Technol., vol. 13, no. 4, pp. 1633–1641, Aug. 2021.
|
| [48] |
Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “RoBERTa: A robustly optimized BERT pretraining approach,” arXiv preprint arXiv: 1907.11692, 2019.
|
| [49] |
V. Sanh, L. Debut, J. Chaumond, and T. Wolf, “DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter,” arXiv preprint arXiv: 1910.01108, 2019.
|
| [50] |
J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C. H. So, and J. Kang, “BioBERT: A pre-trained biomedical language representation model for biomedical text mining,” Bioinformatics, vol. 36, no. 4, pp. 1234–1240, Feb. 2020. doi: 10.1093/bioinformatics/btz682
|
| [51] |
Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut, “ALBERT: A lite BERT for self-supervised learning of language representations,” in Proc. 8th Int. Conf. Learning Representations, Addis Ababa, Ethiopia, 2020.
|
| [52] |
A. Askell, Y. Bai, A. Chen, D. Drain, D. Ganguli, T. Henighan, A. Jones, N. Joseph, B. Mann, N. DasSarma, N. Elhage, Z. Hatfield-Dodds, D. Hernandez, J. Kernion, K. Ndousse, C. Olsson, D. Amodei, T. Brown, J. Clark, S. McCandlish, C. Olah, and J. Kaplan, “A general language assistant as a laboratory for alignment,” arXiv preprint arXiv: 2112.00861, 2021.
|
| [53] |
Y. Sun, S. Wang, S. Feng, S. Ding, C. Pang, J. Shang, J. Liu, X. Chen, Y. Zhao, Y. Lu, W. Liu, Z. Wu, W. Gong, J. Liang, Z. Shang, P. Sun, W. Liu, X. Ouyang, D. Yu, H. Tian, H. Wu, and H. Wang, “Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation,” arXiv preprint arXiv: 2107.02137, 2021.
|
| [54] |
V. Sanh, A. Webson, C. Raffel, S. Bach, L. Sutawika, Z. Alyafeai, A. Chaffin, A. Stiegler, A. Raja, M. Dey, M. S. Bari, C. Xu, U. Thakker, S. S. Sharma, E. Szczechla, T. Kim, G. Chhablani, N. Nayak, D. Datta, J. Chang, M. T.-J. Jiang, H. Wang, M. Manica, S. Shen, Z. X. Yong, H. Pandey, R. Bawden, T. Wang, T. Neeraj, J. Rozen, A. Sharma, A. Santilli, T. Fevry, J. A. Fries, R. Teehan, T. Le Scao, S. Biderman, L. Gao, T. Wolf, and A. M. Rush, “Multitask prompted training enables zero-shot task generalization,” in Proc. 10th Int. Conf. Learning Representations, 2022.
|
| [55] |
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” 2019. [Online]. Available: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf. Accessed on: May 1, 2025.
|
| [56] |
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Herbert-Voss, W. H. Guss, A. Nichol, A. Paino, N. Tezak, J. Tang, I. Babuschkin, S. Balaji, S. Jain, W. Saunders, C. Hesse, A. N. Carr, J. Leike, J. Achiam, V. Misra, E. Morikawa, A. Radford, M. Knight, M. Brundage, M. Murati, K. Mayer, P. Welinder, B. McGrew, D. Amodei, S. McCandlish, I. Sutskever, and W. Zaremba, “Evaluating large language models trained on code,” arXiv preprint arXiv: 2107.03374, 2021.
|
| [57] |
Q. Zheng, X. Xia, X. Zou, Y. Dong, S. Wang, Y. Xue, L. Shen, Z. Wang, A. Wang, Y. Li, T. Su, Z. Yang, and J. Tang, “CodeGeeX: A pre-trained model for code generation with multilingual benchmarking on HumanEval-X,” in Proc. 29th ACM SIGKDD Conf. Knowledge Discovery and Data Mining, Long Beach, USA, 2023, pp. 5673–5684.
|
| [58] |
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “LLaMA: Open and efficient foundation language models,” arXiv preprint arXiv: 2302.13971, 2023.
|
| [59] |
S. Biderman, H. Schoelkopf, Q. G. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raff, A. Skowron, L. Sutawika, and O. Van Der Wal, “Pythia: A suite for analyzing large language models across training and scaling,” in Proc. 40th Int. Conf. Machine Learning, Honolulu, USA, 2023, pp. 2397–2430.
|
| [60] |
Gemini Team, Google, “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,” arXiv preprint arXiv: 2403.05530, 2024.
|
| [61] |
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” J. Mach. Learn. Res., vol. 21, no. 1, p. 140, Jan. 2020.
|
| [62] |
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” in Proce. 34th Int. Conf. Neural Information Processing Systems, Vancouver, Canada, 2020, pp. 159.
|
| [63] |
J. W. Rae, S. Borgeaud, T. Cai, K. Millican, J. Hoffmann, F. Song, J. Aslanides, S. Henderson, R. Ring, S. Young, E. Rutherford, T. Hennigan, J. Menick, A. Cassirer, R. Powell, G. van den Driessche, L. A. Hendricks, M. Rauh, P.-S. Huang, A. Glaese, J. Welbl, S. Dathathri, S. Huang, J. Uesato, J. Mellor, I. Higgins, A. Creswell, N. McAleese, A. Wu, E. Elsen, S. Jayakumar, E. Buchatskaya, D. Budden, E. Sutherland, K. Simonyan, M. Paganini, L. Sifre, L. Martens, X. L. Li, A. Kuncoro, A. Nematzadeh, E. Gribovskaya, D. Donato, A. Lazaridou, A. Mensch, J.-B. Lespiau, M. Tsimpoukelli, N. Grigorev, D. Fritz, T. Sottiaux, M. Pajarskas, T. Pohlen, Z. Gong, D. Toyama, C. de Masson d’Autume, Y. Li, T. Terzi, V. Mikulik, I. Babuschkin, A. Clark, D. de Las Casas, A. Guy, C. Jones, J. Bradbury, M. Johnson, B. Hechtman, L. Weidinger, I. Gabriel, W. Isaac, E. Lockhart, S. Osindero, L. Rimell, C. Dyer, O. Vinyals, K. Ayoub, J. Stanway, L. Bennett, D. Hassabis, K. Kavukcuoglu, and G. Irving, “Scaling language models: Methods, analysis & insights from training gopher,” arXiv preprint arXiv: 2112.11446, 2021.
|
| [64] |
T. L. Scao, A. Fan, C. Akiki, E. Pavlick, S. Ilic, D. Hesslow, R. Castagne, A. S. Luccioni, F. Yvon, M. Gallé, et al., “BLOOM: A 176B-parameter open-access multilingual language model,” arXiv preprint arXiv: 2211.05100, 2022.
|
| [65] |
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. van den Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, O. Vinyals, J. W. Rae, and L. Sifre, “Training compute-optimal large language models,” in Proce. 36th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2022, pp. 2176.
|
| [66] |
N. Du, Y. Huang, A. M. Dai, S. Tong, D. Lepikhin, Y. Xu, M. Krikun, Y. Zhou, A. W. Yu, O. Firat, B. Zoph, L. Fedus, M. P. Bosma, Z. Zhou, T. Wang, E. Wang, K. Webster, M. Pellat, K. Robinson, K. Meier-Hellstern, T. Duke, L. Dixon, K. Zhang, Q. Le, Y. Wu, Z. Chen, and C. Cui, “GLaM: Efficient scaling of language models with mixture-of-experts,” in Proc. 39th Int. Conf. Machine Learning, Baltimore, USA, 2022, pp. 5547–5569.
|
| [67] |
R. Thoppilan, D. De Freitas, J. Hall, N. Shazeer, A. Kulshreshtha, H.-T. Cheng, A. Jin, T. Bos, L. Baker, Y. Du, Y. G. Li, H. Lee, H. S. Zheng, A. Ghafouri, M. Menegali, Y. Huang, M. Krikun, D. Lepikhin, J. Qin, D. Chen, Y. Xu, Z. Chen, A. Roberts, M. Bosma, V. Zhao, Y. Zhou, C.-C. Chang, I. Krivokon, W. Rusch, M. Pickett, P. Srinivasan, L. Man, K. Meier-Hellstern, M. R. Morris, T. Doshi, R. D. Santos, T. Duke, J. Soraker, B. Zevenbergen, V. Prabhakaran, M. Diaz, B. Hutchinson, K. Olson, A. Molina, E. Hoffman-John, J. Lee, L. Aroyo, R. Rajakumar, A. Butryna, M. Lamm, V. Kuzmina, J. Fenton, A. Cohen, R. Bernstein, R. Kurzweil, B. Aguera-Arcas, C. Cui, M. Croak, E. Chi, and Q. Le, “Lamda: Language models for dialog applications,” arXiv preprint arXiv: 2201.08239, 2022.
|
| [68] |
S. Smith, M. Patwary, B. Norick, P. LeGresley, S. Rajbhandari, J. Casper, Z. Liu, S. Prabhumoye, G. Zerveas, V. Korthikanti, E. Zhang, R. Child, R. Y. Aminabadi, J. Bernauer, X. Song, M. Shoeybi, Y. He, M. Houston, S. Tiwary, and B. Catanzaro, “Using DeepSpeed and megatron to train megatron-turing NLG 530B, a large-scale generative language model,” arXiv preprint arXiv: 2201.11990, 2022.
|
| [69] |
S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V. Lin, T. Mihaylov, M. Ott, S. Shleifer, K. Shuster, D. Simig, P. S. Koura, A. Sridhar, T. Wang, and L. Zettlemoyer, “OPT: Open pre-trained transformer language models,” arXiv preprint arXiv: 2205.01068, 2022.
|
| [70] |
S. Wu, O. Irsoy, S. Lu, V. Dabravolski, M. Dredze, S. Gehrmann, P. Kambadur, D. Rosenberg, and G. Mann, “BloombergGPT: A large language model for finance,” arXiv preprint arXiv: 2303.17564, 2023.
|
| [71] |
Llama Team, “The Llama 3 herd of models,” arXiv preprint arXiv: 2407.21783, 2024.
|
| [72] |
J. Bai, S. Bai, Y. Chu, Z. Cui, K. Dang, X. Deng, Y. Fan, W. Ge, Y. Han, F. Huang, B. Hui, L. Ji, M. Li, J. Lin, R. Lin, D. Liu, G. Liu, C. Lu, K. Lu, J. Ma, R. Men, X. Ren, X. Ren, C. Tan, S. Tan, J. Tu, P. Wang, S. Wang, W. Wang, S. Wu, B. Xu, J. Xu, A. Yang, H. Yang, J. Yang, S. Yang, Y. Yao, B. Yu, H. Yuan, Z. Yuan, J. Zhang, X. Zhang, Y. Zhang, Z. Zhang, C. Zhou, J. Zhou, X. Zhou, and T. Zhu, “Qwen technical report,” arXiv preprint arXiv: 2309.16609, 2023.
|
| [73] |
Team GLM, “ChatGLM: A family of large language models from GLM-130B to GLM-4 all tools,” arXiv preprint arXiv: 2406.12793, 2024.
|
| [74] |
Kimi Team, “Kimi k1.5: Scaling reinforcement learning with LLMs,” arXiv preprint arXiv: 2501.12599, 2025.
|
| [75] |
Gemma Team, “Gemma: Open models based on Gemini research and technology,” arXiv preprint arXiv: 2403.08295, 2024.
|
| [76] |
“Grok-2 beta release,” [Online]. Available: https://x.ai/blog/grok-2. Accessed on: May 1, 2025.
|
| [77] |
R. Vavekanand and K. Sam, “Llama 3.1: An in-depth analysis of the next-generation large language model,” 2024.
|
| [78] |
Y. Wang, H. Wu, J. Zhang, Z. Gao, J. Wang, P. S. Yu, and M. Long, “PredRNN: A recurrent neural network for spatiotemporal predictive learning,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 2, pp. 2208–2225, Feb. 2022.
|
| [79] |
S. Liu, I. Ni’mah, V. Menkovski, D. C. Mocanu, and M. Pechenizkiy, “Efficient and effective training of sparse recurrent neural networks,” Neural Comput. Appl., vol. 33, no. 15, pp. 9625–9636, Aug. 2021. doi: 10.1007/s00521-021-05727-y
|
| [80] |
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. 31st Int. Conf. Neural Information Processing Systems, Long Beach, USA, 2017, pp. 6000–6010.
|
| [81] |
J. Wang, “A tutorial on LLM reasoning: Relevant methods behind ChatGPT o1,” arXiv preprint arXiv: 2502.10867, 2025.
|
| [82] |
E. Zelikman, Y. Wu, J. Mu, and N. D. Goodman, “STaR: Bootstrapping reasoning with reasoning,” in Proc. 36th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2022, pp. 15476–15488.
|
| [83] |
Z. Wan, X. Feng, M. Wen, S. M. McAleer, Y. Wen, W. Zhang, and J. Wang, “AlphaZero-like tree-search can guide large language model decoding and training,” in Proc. 41st Int. Conf. Machine Learning, Vienna, Austria, 2023, pp. 2040.
|
| [84] |
L. Luo, Y. Liu, R. Liu, S. Phatale, M. Guo, H. Lara, Y. Li, L. Shu, Y. Zhu, L. Meng, J. Sun, and A. Rastogi, “Improve mathematical reasoning in language models by automated process supervision,” arXiv preprint arXiv: 2406.06592, vol. 2, 2024.
|
| [85] |
Y. Li, Z. Lin, S. Zhang, Q. Fu, B. Chen, J.-G. Lou, and W. Chen, “Making large language models better reasoners with step-aware verifier,” arXiv preprint arXiv: 2206.02336, 2022.
|
| [86] |
Y. Wu, Z. Sun, S. Li, S. Welleck, and Y. Yang, “An empirical analysis of compute-optimal inference for problem-solving with language models,” arXiv preprint arXiv: 2408.00724, 2024.
|
| [87] |
C. Snell, J. Lee, K. Xu, and A. Kumar, “Scaling LLM test-time compute optimally can be more effective than scaling model parameters,” arXiv preprint arXiv: 2408.03314, 2024.
|
| [88] |
R. Bellman, “Dynamic programming and stochastic control processes,” Inf. Control, vol. 1, no. 3, pp. 228–239, Sept. 1958. doi: 10.1016/S0019-9958(58)80003-0
|
| [89] |
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” in Proc. 36th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2022, pp. 1800.
|
| [90] |
F. Christianos, G. Papoudakis, M. Zimmer, T. Coste, Z. Wu, J. Chen, K. Khandelwal, J. Doran, X. Feng, J. Liu, Z. Xiong, Y. Luo, J. Hao, K. Shao, H. Bou-Ammar, and J. Wang, “Pangu-agent: A fine-tunable generalist agent with structured reasoning,” arXiv preprint arXiv: 2312.14878, 2023.
|
| [91] |
Qwen Team, “Qwen2.5: A party of foundation models,” 2024. [Online]. Available: https://qwenlm.github.io/blog/qwen2.5/. Accessed on: May 1, 2025.
|
| [92] |
Z. Wu, X. Chen, Z. Pan, X. Liu, W. Liu, D. Dai, H. Gao, Y. Ma, C. Wu, B. Wang, Z. Xie, Y. Wu, K. Hu, J. Wang, Y. Sun, Y. Li, Y. Piao, K. Guan, A. Liu, X. Xie, Y. You, K. Dong, X. Yu, H. Zhang, L. Zhao, Y. Wang, and C. Ruan, “Deepseek-VL2: Mixture-of-experts vision-language models for advanced multimodal understanding,” arXiv preprint arXiv: 2412.10302, 2024.
|
| [93] |
H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” in Proc. 37th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2024, pp. 1516.
|
| [94] |
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Paris, France, 2023, pp. 11941–11952.
|
| [95] |
C. Wu, X. Chen, Z. Wu, Y. Ma, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, C. Ruan, and P. Luo, “Janus: Decoupling visual encoding for unified multimodal understanding and generation,” arXiv preprint arXiv: 2410.13848, 2024.
|
| [96] |
J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu, “RoFormer: Enhanced transformer with rotary position embedding,” Neurocomputing, vol. 568, p. 127063, Feb. 2024. doi: 10.1016/j.neucom.2023.127063
|
| [97] |
J. Cai and Y. Chen, “MHA-Net: Multipath hybrid attention network for building footprint extraction from high-resolution remote sensing imagery,” IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., vol. 14, pp. 5807–5817, 2021.
|
| [98] |
D. Xiao, Q. Meng, S. Li, and X. Yuan, “Improving transformers with dynamically composable multi-head attention,” in Proc. 41st Int. Conf. Machine Learning, Vienna, Austria, 2024.
|
| [99] |
L. Shi, H. Zhang, Y. Yao, Z. Li, and H. Zhao, “Keep the cost down: A review on methods to optimize LLM’s KV-cache consumption,” arXiv preprint arXiv: 2407.18003, 2024.
|
| [100] |
N. Shazeer, “Fast transformer decoding: One write-head is all you need,” arXiv preprint arXiv: 1911.02150, 2019.
|
| [101] |
W. Brandon, M. Mishra, A. Nrusimha, R. Panda, and J. Ragan-Kelley, “Reducing transformer key-value cache size with cross-layer attention,” in Proc. 38th Int. Conf. Neural Information Processing Systems, Vancouver, Canada, 2024, pp. 86927–86957.
|
| [102] |
J. Ainslie, J. Lee-Thorp, M. de Jong, Y. Zemlyanskiy, F. Lebrón, and S. Sanghai, “GQA: Training generalized multi-query transformer models from multi-head checkpoints,” in Proc. Conf. Empirical Methods in Natural Language Processing, Singapore, Singapore, 2023, pp. 4895–4901.
|
| [103] |
V. Joshi, P. Laddha, S. Sinha, O. J. Omer, and S. Subramoney, “QCQA: Quality and capacity-aware grouped query attention,” arXiv preprint arXiv: 2406.10247, 2024.
|
| [104] |
Z. Zhang, Y. Lin, Z. Liu, P. Li, M. Sun, and J. Zhou, “MoEfication: Transformer feed-forward layers are mixtures of experts,” in Proc. Findings of the Association for Computational Linguistics, Dublin, Ireland, 2022, pp. 877–890.
|
| [105] |
L. Wang, H. Gao, C. Zhao, X. Sun, and D. Dai, “Auxiliary-loss-free load balancing strategy for mixture-of-experts,” arXiv preprint arXiv: 2408.15664, 2024.
|
| [106] |
S. Shi, X. Pan, Q. Wang, C. Liu, X. Ren, Z. Hu, Y. Yang, B. Li, and X. Chu, “ScheMoE: An extensible mixture-of-experts distributed training system with tasks scheduling,” in Proc. Nineteenth European Conf. Computer Systems, Athens Greece, 2024, pp. 236–249.
|
| [107] |
M. Qorib, G. Moon, and H. T. Ng, “Are decoder-only language models better than encoder-only language models in understanding word meaning?,” in Proc. Findings of the Association for Computational Linguistics, Bangkok, Thailand, 2024, pp. 16339–16347.
|
| [108] |
W. Xu, W. Hu, F. Wu, and S. Sengamedu, “DeTiME: Diffusion-enhanced topic modeling using encoder-decoder based LLM,” in Proc. Findings of the Association for Computational Linguistics, Singapore, Singapore, 2023, pp. 9040–9057.
|
| [109] |
H. You, Y. Fu, Z. Wang, A. Yazdanbakhsh, and Y. C. Lin, “When linear attention meets autoregressive decoding: Towards more effective and efficient linearized large language models,” in Proc. 41st Int. Conf. Machine Learning, Vienna, Austria, 2024.
|
| [110] |
L. Guo, Y. Fang, F. Chen, P. Liu, and S. Xu, “Large language models with adaptive token fusion: A novel approach to reducing hallucinations and improving inference efficiency,” Authorea, 2024, DOI: 10.22541/au.172979407.71044427/v1.
|
| [111] |
K. Yue, B.-C. Chen, J. Geiping, H. Li, T. Goldstein, and S.-N. Lim, “Object recognition as next token prediction,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2024, pp. 16645–16656.
|
| [112] |
F. Gloeckle, B. Y. Idrissi, B. Roziere, D. Lopez-Paz, and G. Synnaeve, “Better & faster large language models via multi-token prediction,” in Proc. 41st Int. Conf. Machine Learning, Vienna, Austria, 2024.
|
| [113] |
G. Bachmann and V. Nagarajan, “The pitfalls of next-token prediction,” in Proc. 41st Int. Conf. Machine Learning, Vienna, Austria, 2024.
|
| [114] |
S. Tuli, C.-H. Lin, Y.-C. Hsu, N. K. Jha, Y. Shen, and H. Jin, “DynaMo: Accelerating language model inference with dynamic multi-token sampling,” in Proc. Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Mexico City, Mexico, 2024, pp. 3322–3345.
|
| [115] |
J. Zhang, Z. Zhang, S. Han, and S. Lü, “Proximal policy optimization via enhanced exploration efficiency,” Inf. Sci., vol. 609, pp. 750–765, Sept. 2022. doi: 10.1016/j.ins.2022.07.111
|
| [116] |
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv: 1707.06347, 2017.
|
| [117] |
Y. Wang, H. He, and X. Tan, “Truly proximal policy optimization,” in Proc. 35th Uncertainty in Artificial Intelligence Conf., Tel Aviv, Israel, 2020, pp. 113–122.
|
| [118] |
Y. Gu, Y. Cheng, C. P. Chen, and X. Wang, “Proximal policy optimization with policy feedback,” IEEE Trans. Sys. Man Cybern. Syst., vol. 52, no. 7, pp. 4600–4610, Jul. 2022. doi: 10.1109/TSMC.2021.3098451
|
| [119] |
S. S. Ramesh, Y. Hu, I. Chaimalas, V. Mehta, P. G. Sessa, H. B. Ammar, and I. Bogunovic, “Group robust preference optimization in reward-free RLHF,” in Proc. 38th Int. Conf. Neural Information Processing Systems, Vancouver, Canada, 2024.
|
| [120] |
G. Cui, L. Yuan, Z. Wang, H. Wang, W. Li, B. He, Y. Fan, T. Yu, Q. Xu, W. Chen, J. Yuan, H. Chen, K. Zhang, X. Lv, S. Wang, Y. Yao, X. Han, H. Peng, Y. Cheng, Z. Liu, M. Sun, B. Zhou, and N. Ding, “Process reinforcement through implicit rewards,” arXiv preprint arXiv: 2502.01456, 2025.
|
| [121] |
S. Sane, “Hybrid group relative policy optimization: A multi-sample approach to enhancing policy optimization,” arXiv preprint arXiv: 2502.01652, 2025.
|
| [122] |
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,” arXiv preprint arXiv: 2001.08361, 2020.
|
| [123] |
T. Dettmers, M. Lewis, Y. Belkada, and L. Zettlemoyer, “GPT3.int8(): 8-bit matrix multiplication for transformers at scale,” in Proc. 36th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2022, pp. 30318–30332.
|
| [124] |
B. Noune, P. Jones, D. Justus, D. Masters, and C. Luschi, “8-bit numerical formats for deep neural networks,” arXiv preprint arXiv: 2206.02915, 2022.
|
| [125] |
H. Peng, K. Wu, Y. Wei, G. Zhao, Y. Yang, Z. Liu, Y. Xiong, Z. Yang, B. Ni, J. Hu, R. Li, M. Zhang, C. Li, J. Ning, R. Wang, Z. Zhang, S. Liu, J. Chau, H. Hu, and P. Cheng, “FP8-LM: Training FP8 large language models,” arXiv preprint arXiv: 2310.18313, 2023.
|
| [126] |
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “GPTQ: Accurate post-training quantization for generative pre-trained transformers,” arXiv preprint arXiv: 2210.17323, 2022.
|
| [127] |
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “SmoothQuant: Accurate and efficient post-training quantization for large language models,” in Proc. 40th Int. Conf. Machine Learning, Honolulu, USA, 2023, pp. 38087–38099.
|
| [128] |
M. Fishman, B. Chmiel, R. Banner, and D. Soudry, “Scaling FP8 training to trillion-token LLMs,” arXiv preprint arXiv: 2409.12517, 2024.
|
| [129] |
B. He, L. Noci, D. Paliotta, I. Schlag, and T. Hofmann, “Understanding and minimising outlier features in transformer training,” in Proc. Thirty-Eighth Int. Conf. Neural Information Processing Systems, Vancouver, Canada, 2024.
|
| [130] |
M. Sun, X. Chen, J. Z. Kolter, and Z. Liu, “Massive activations in large language models,” arXiv preprint arXiv: 2402.17762, 2024.
|
| [131] |
C. Zhao, L. Zhao, J. Li, and Z. Xu, “DeepGEMM: Clean and efficient FP8 GEMM kernels with fine-grained scaling,” [Online]. Available: https://github.com/deepseek-ai/DeepGEMM, Accessed on: May 1, 2025.
|
| [132] |
J. Li and S. Wu, “FlashMLA: Efficient MLA decoding kernel,” [Online]. Available: https://github.com/deepseek-ai/FlashMLA, Accessed on: May 1, 2025.
|
| [133] |
D. Lepikhin, H. Lee, Y. Xu, D. Chen, O. Firat, Y. Huang, M. Krikun, N. Shazeer, and Z. Chen, “GShard: Scaling giant models with conditional computation and automatic sharding,” in Proc. 9th Int. Conf. Learning Representations, Austria, 2021.
|
| [134] |
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “The sparsely-gated mixture-of-experts layer,” Outrageously Large Neural Networks, 2017.
|
| [135] |
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,” J. Mach. Learn. Res., vol. 23, no. 1, p. 120, Jan. 2022.
|
| [136] |
P. Qi, X. Wan, G. Huang, and M. Lin, “Zero bubble pipeline parallelism,” arXiv preprint arXiv: 2401.10241, 2023.
|
| [137] |
C. Zhao, S. Zhou, L. Zhang, C. Deng, Z. Xu, Y. Liu, K. Yu, J. Li, and L. Zhao, “DeepEP: An efficient expert-parallel communication library,” [Online]. Available: https://github.com/deepseek-ai/DeepEP, Accessed on: May 1, 2025.
|
| [138] |
S. Hao, S. Sukhbaatar, D. J. Su, X. Li, Z. Hu, J. Weston, and Y. Tian, “Training large language models to reason in a continuous latent space,” arXiv preprint arXiv: 2412.06769, 2024.
|
| [139] |
F. Jiang, Z. Xu, Y. Li, L. Niu, Z. Xiang, B. Li, B. Y. Lin, and R. Poovendran, “SafeChain: Safety of language models with long chain-of-thought reasoning capabilities,” arXiv preprint arXiv: 2502.120252025.
|
| [140] |
Z. Ying, D. Zhang, Z. Jing, Y. Xiao, Q. Zou, A. Liu, S. Liang, X. Zhang, X. Liu, and D. Tao, “Reasoning-augmented conversation for multi-turn jailbreak attacks on large language models,” arXiv preprint arXiv: 2502.11054, 2025.
|
| [141] |
N. Jones, “OpenAI’s' ’deep research’ tool: Is it useful for scientists?,” Nature, 2025, DOI: 10.1038/d41586-025-00377-9.
|
| [142] |
“Introducing operator,” [Online]. Available: https://openai.com/index/introducing-operator/. Accessed on: May 1, 2025.
|
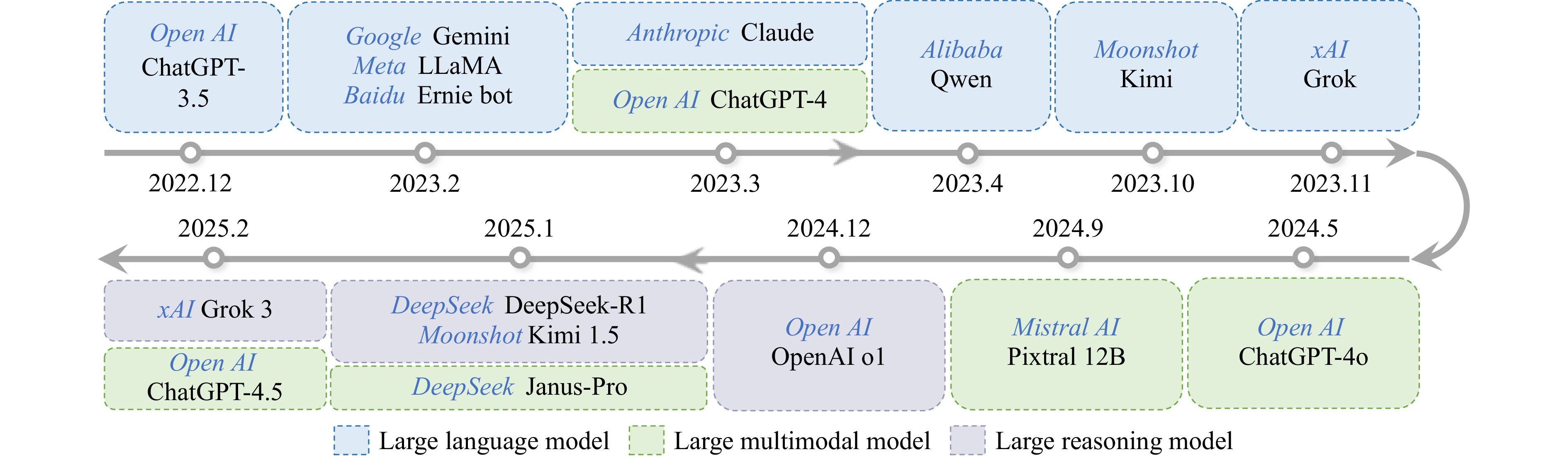
Figures(5) / Tables(2)






 DownLoad:
DownLoad: