A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 10
Issue 10
Volume 10
Issue 10
IEEE/CAA Journal of Automatica Sinica
| Citation: | F. Y. Zhang, Q. Y. Yang, and D. An, “Privacy preserving demand side management method via multi-agent reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 10, pp. 1984–1999, Oct. 2023. doi: 10.1109/JAS.2023.123321

|
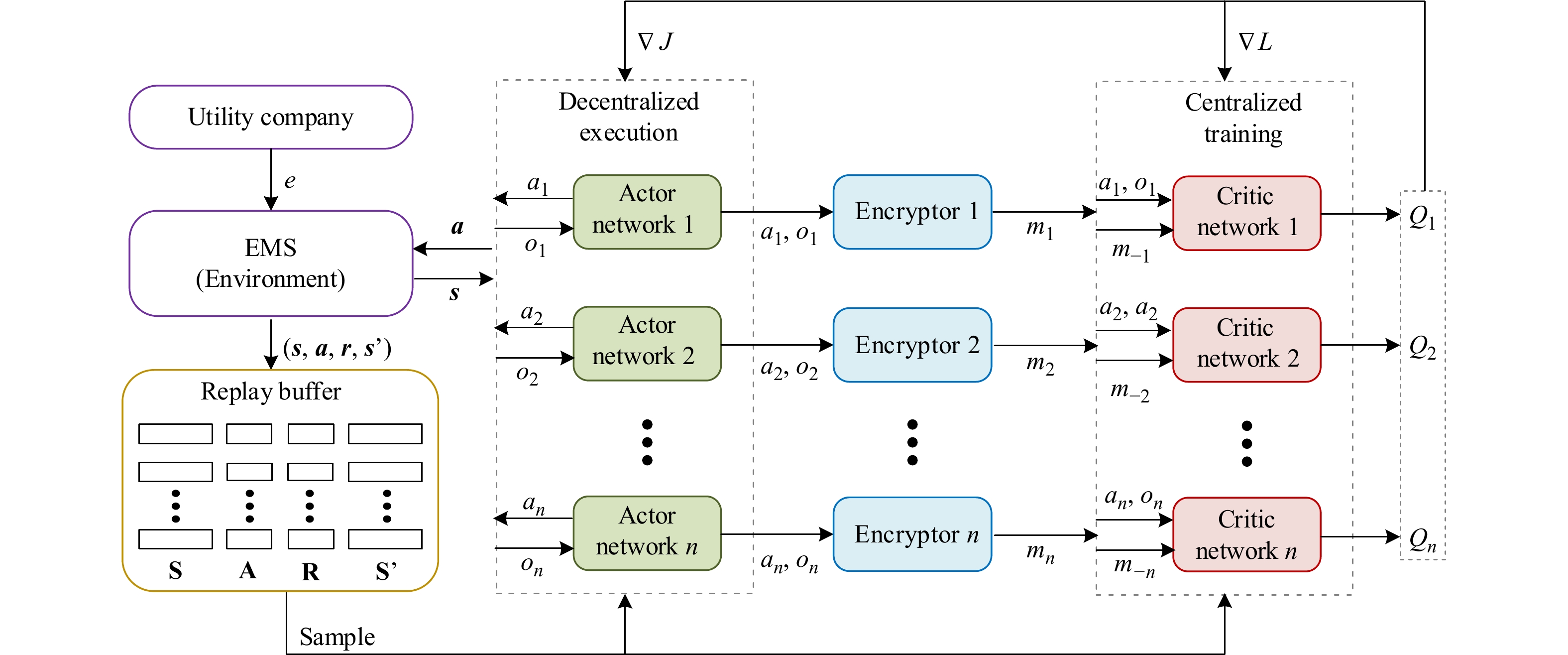
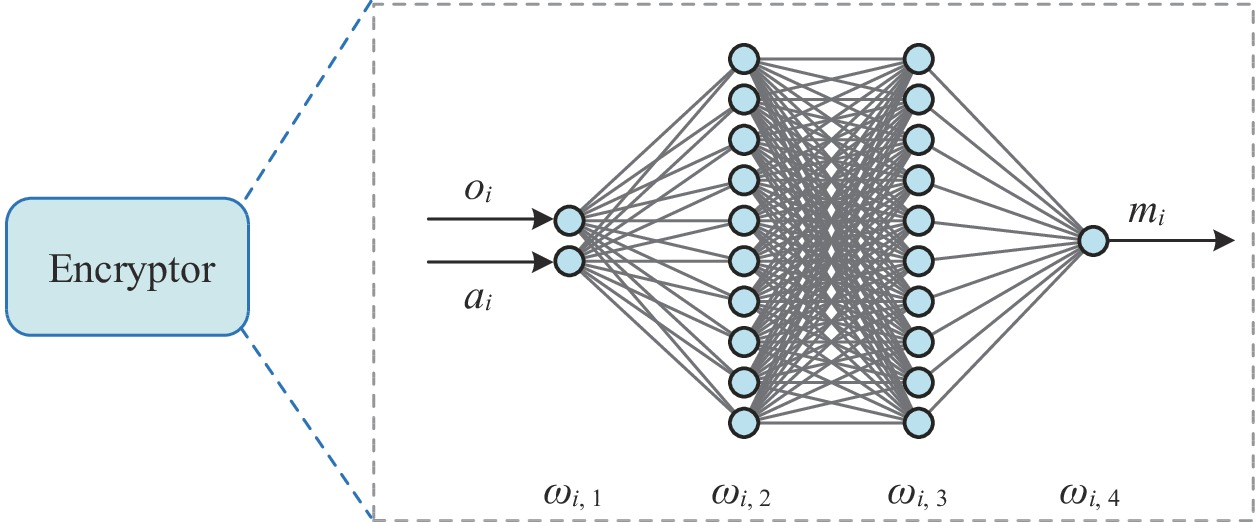
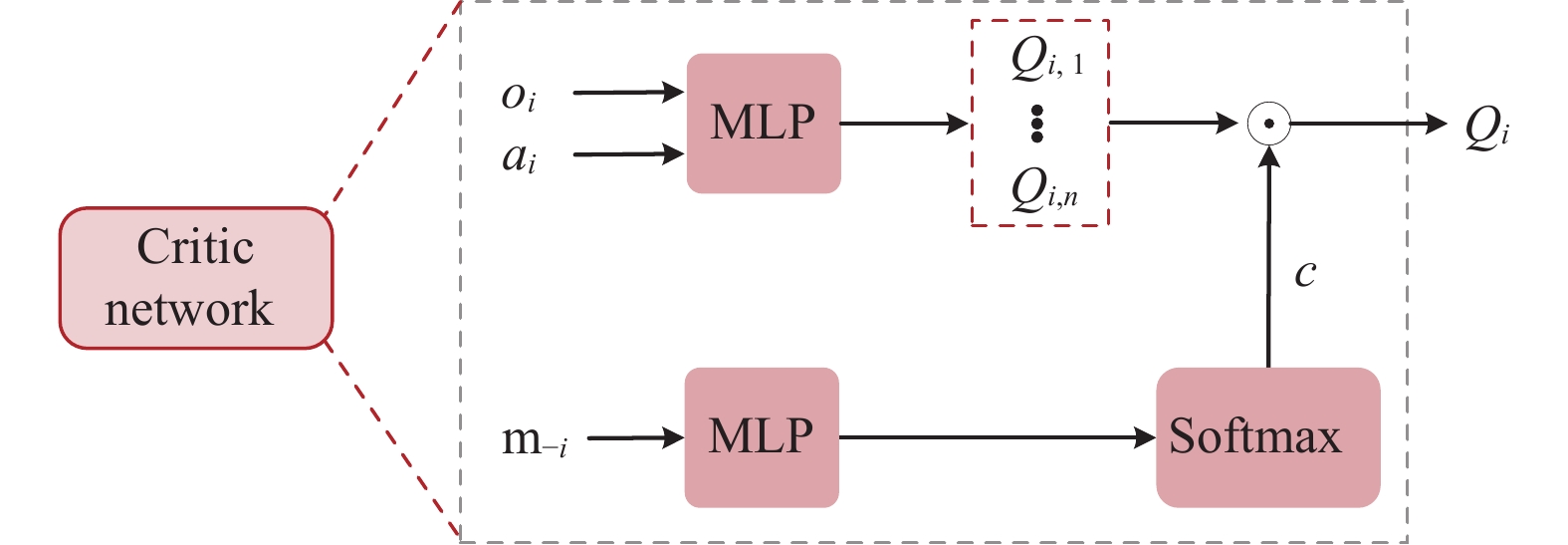
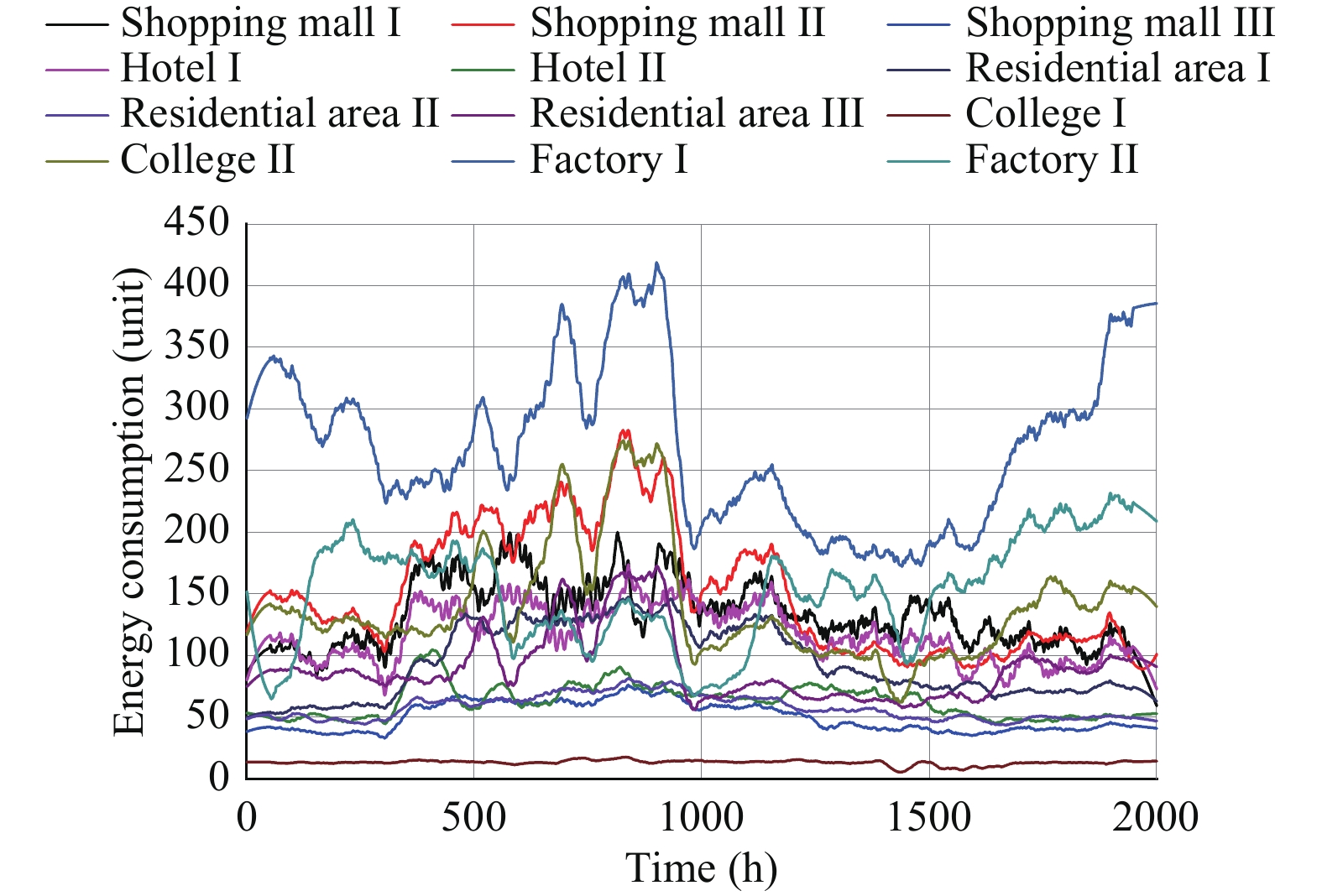
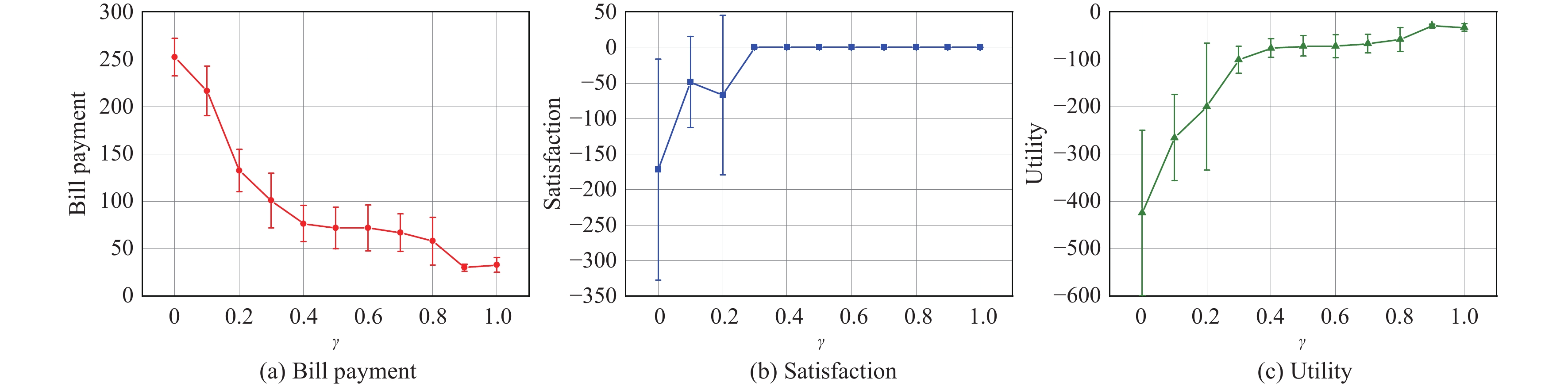
The smart grid utilizes the demand side management technology to motivate energy users towards cutting demand during peak power consumption periods, which greatly improves the operation efficiency of the power grid. However, as the number of energy users participating in the smart grid continues to increase, the demand side management strategy of individual agent is greatly affected by the dynamic strategies of other agents. In addition, the existing demand side management methods, which need to obtain users’ power consumption information, seriously threaten the users’ privacy. To address the dynamic issue in the multi-microgrid demand side management model, a novel multi-agent reinforcement learning method based on centralized training and decentralized execution paradigm is presented to mitigate the damage of training performance caused by the instability of training experience. In order to protect users’ privacy, we design a neural network with fixed parameters as the encryptor to transform the users’ energy consumption information from low-dimensional to high-dimensional and theoretically prove that the proposed encryptor-based privacy preserving method will not affect the convergence property of the reinforcement learning algorithm. We verify the effectiveness of the proposed demand side management scheme with the real-world energy consumption data of Xi’an, Shaanxi, China. Simulation results show that the proposed method can effectively improve users’ satisfaction while reducing the bill payment compared with traditional reinforcement learning (RL) methods (i.e., deep Q learning (DQN), deep deterministic policy gradient (DDPG), QMIX and multi-agent deep deterministic policy gradient (MADDPG)). The results also demonstrate that the proposed privacy protection scheme can effectively protect users’ privacy while ensuring the performance of the algorithm.

| [1] |
D. Li, Q. Yang, W. Yu, D. An, Y. Zhang, and W. Zhao, “Towards differential privacy-based online double auction for smart grid,” IEEE Trans. Information Forensics and Security, vol. 15, pp. 971–986, 2020. doi: 10.1109/TIFS.2019.2932911
|
| [2] |
V. C. Gungor, D. Sahin, T. Kocak, S. Ergut, C. Buccella, C. Cecati, and G. Hancke, “Smart grid technologies: Communication technologies and standards,” IEEE Trans. Industrial Informatics, vol. 7, no. 4, pp. 529–539, 2011. doi: 10.1109/TII.2011.2166794
|
| [3] |
P. Palensky and D. Dietrich, “Demand side management: Demand response, intelligent energy systems, and smart loads,” IEEE Trans. Industrial Informatics, vol. 7, no. 3, pp. 381–388, 2011. doi: 10.1109/TII.2011.2158841
|
| [4] |
Z. Zhao, L. Wu, and G. Song, “Convergence of volatile power markets with price-based demand response,” IEEE Trans. Power Systems, vol. 29, no. 5, pp. 2107–2118, 2014. doi: 10.1109/TPWRS.2014.2307872
|
| [5] |
M. Zhang, Y. Xiong, H. Cai, M. Bo, and J. Wang, “Study on the standard calculation model of power demand response incentive subsidy based on master-slave game,” in Proc. IEEE 5th Conf. Energy Internet and Energy System Integration, 2021, pp. 1923–1927.
|
| [6] |
N. Liu, X. Yu, C. Wang, C. Li, L. Ma, and J. Lei, “Energy-sharing model with price-based demand response for microgrids of peer-to-peer prosumers,” IEEE Trans. Power Systems, vol. 32, no. 5, pp. 3569–3583, 2017. doi: 10.1109/TPWRS.2017.2649558
|
| [7] |
N. H. Tran, T. Z. Oo, S. Ren, Z. Han, E.-N. Huh, and C. S. Hong, “Reward-to-reduce: An incentive mechanism for economic demand response of colocation datacenters,” IEEE J. Selected Areas in Commun., vol. 34, no. 12, pp. 3941–3953, 2016. doi: 10.1109/JSAC.2016.2611958
|
| [8] |
F. Zhang, Q. Yang, and D. An, “CDDPG: A deep-reinforcement-learning-based approach for electric vehicle charging control,” IEEE Internet of Things J., vol. 8, no. 5, pp. 3075–3087, 2021. doi: 10.1109/JIOT.2020.3015204
|
| [9] |
A. Kumari and S. Tanwar, “A reinforcement-learning-based secure demand response scheme for smart grid system,” IEEE Internet of Things J., vol. 9, no. 3, pp. 2180–2191, 2022. doi: 10.1109/JIOT.2021.3090305
|
| [10] |
W. Hu, “Transforming thermal comfort model and control in the tropics: A machine-learning approach,” Ph.D. dissertation, School of Computer Science and Engineering, Nanyang Technological University, Singapore, 2020.
|
| [11] |
L. Yu, S. Qin, M. Zhang, C. Shen, T. Jiang, and X. Guan, “A review of deep reinforcement learning for smart building energy management,” IEEE Internet of Things J., vol. 8, no. 15, pp. 12046–12063, 2021. doi: 10.1109/JIOT.2021.3078462
|
| [12] |
R. Pal, H ui, and V. Prasanna, “Privacy engineering for the smart micro-grid,” IEEE Trans. Knowledge and Data Engineering, vol. 31, no. 5, pp. 965–980, 2019. doi: 10.1109/TKDE.2018.2846640
|
| [13] |
Z. Bilgin, E. Tomur, M. A. Ersoy, and E. U. Soykan, “Statistical appliance inference in the smart grid by machine learning,” in Proc. IEEE 30th Int. Symp. Personal, Indoor and Mobile Radio Commun. (PIMRC Workshops), 2019, pp. 1–7.
|
| [14] |
L. Lyu, K. Nandakumar, B. Rubinstein, J. Jin, J. Bedo, and M. Palaniswami, “PPFA: Privacy preserving fog-enabled aggregation in smart grid,” IEEE Trans. Industrial Informatics, vol. 14, no. 8, pp. 3733–3744, 2018. doi: 10.1109/TII.2018.2803782
|
| [15] |
L. Zhu, M. Li, Z. Zhang, C. Xu, R. Zhang, X. Du, and N. Guizani, “Privacy-preserving authentication and data aggregation for fog-based smart grid,” IEEE Commun. Magazine, vol. 57, no. 6, pp. 80–85, 2019. doi: 10.1109/MCOM.2019.1700859
|
| [16] |
W. Han and Y. Xiao, “Privacy preservation for V2G networks in smart grid: A survey,” Computer Commun., vol. 91–92, pp. 17–28, 2016. doi: 10.1016/j.comcom.2016.06.006
|
| [17] |
S. Bahrami, Y. C. Chen, and V. W. S. Wong, “Deep reinforcement learning for demand response in distribution networks,” IEEE Trans. Smart Grid, vol. 12, no. 2, pp. 1496–1506, 2021. doi: 10.1109/TSG.2020.3037066
|
| [18] |
Z. Qin, D. Liu, H. Hua, and J. Cao, “Privacy preserving load control of residential microgrid via deep reinforcement learning,” IEEE Trans. Smart Grid, vol. 12, no. 5, pp. 4079–4089, 2021. doi: 10.1109/TSG.2021.3088290
|
| [19] |
O. Erdinç, A. Taşcıkaraoğlu, N. G. Paterakis, Y. Eren, and J. S. Catalão, “End-user comfort oriented day-ahead planning for responsive residential HVAC demand aggregation considering weather forecasts,” IEEE Trans. Smart Grid, vol. 8, no. 1, pp. 362–372, 2017. doi: 10.1109/TSG.2016.2556619
|
| [20] |
H. Wu, M. Shahidehpour, A. Alabdulwahab, and A. Abusorrah, “Demand response exchange in the stochastic day-ahead scheduling with variable renewable generation,” IEEE Trans. Sustainable Energy, vol. 6, no. 2, pp. 516–525, 2015. doi: 10.1109/TSTE.2015.2390639
|
| [21] |
F. Elghitani and W. Zhuang, “Aggregating a large number of residential appliances for demand response applications,” IEEE Trans. Smart Grid, vol. 9, no. 5, pp. 5092–5100, 2018. doi: 10.1109/TSG.2017.2679702
|
| [22] |
Y. Liu, D. Zhang, and H. B. Gooi, “Optimization strategy based on deep reinforcement learning for home energy management,” CSEE J. Power and Energy Systems, vol. 6, no. 3, pp. 572–582, 2020.
|
| [23] |
Y. Du and F. Li, “Intelligent multi-microgrid energy management based on deep neural network and model-free reinforcement learning,” IEEE Trans. Smart Grid, vol. 11, no. 2, pp. 1066–1076, 2020. doi: 10.1109/TSG.2019.2930299
|
| [24] |
L. Yu, W. Xie, D. Xie, Y. Zou, D. Zhang, Z. Sun, L. Zhang, Y. Zhang, and T. Jiang, “Deep reinforcement learning for smart home energy management,” IEEE Internet of Things J., vol. 7, no. 4, pp. 2751–2762, 2020. doi: 10.1109/JIOT.2019.2957289
|
| [25] |
X. Zhang, D. Biagioni, M. Cai, P. Graf, and S. Rahman, “An edge-cloud integrated solution for buildings demand response using reinforcement learning,” IEEE Trans. Smart Grid, vol. 12, no. 1, pp. 420–431, 2021. doi: 10.1109/TSG.2020.3014055
|
| [26] |
C. Zhang, S. R. Kuppannagari, C. Xiong, R. Kannan, and V. K. Prasanna, “A cooperative multi-agent deep reinforcement learning framework for real-time residential load scheduling,” in Proc. Int. Conf. Internet of Things Design and Implementation, 2019, pp. 59–69.
|
| [27] |
L. Yu, Y. Sun, Z. Xu, C. Shen, D. Yue, T. Jiang, and X. Guan, “Multi-agent deep reinforcement learning for HVAC control in commercial buildings,” IEEE Trans. Smart Grid, vol. 12, no. 1, pp. 407–419, 2021. doi: 10.1109/TSG.2020.3011739
|
| [28] |
Y. Wan, J. Qin, X. Yu, T. Yang, and Y. Kang, “Price-based residential demand response management in smart grids: A reinforcement learning-based approach,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 1, pp. 123–134, 2021.
|
| [29] |
B. Wang, C. Zhang, and Z. Y. Dong, “Interval optimization based coordination of demand response and battery energy storage system considering SOC management in a microgrid,” IEEE Trans. Sustainable Energy, vol. 11, no. 4, pp. 2922–2931, 2020. doi: 10.1109/TSTE.2020.2982205
|
| [30] |
Y. Li, R. Wang, and Z. Yang, “Optimal scheduling of isolated microgrids using automated reinforcement learning-based multi-period forecasting,” IEEE Trans. Sustainable Energy, vol. 13, no. 1, pp. 159–169, 2022. doi: 10.1109/TSTE.2021.3105529
|
| [31] |
D. Xu, B. Zhou, K. W. Chan, C. Li, Q. Wu, B. Chen, and S. Xia, “Distributed multienergy coordination of multimicrogrids with biogas-solar-wind renewables,” IEEE Trans. Industrial Informatics, vol. 15, no. 6, pp. 3254–3266, 2019. doi: 10.1109/TII.2018.2877143
|
| [32] |
N. Priyadarshi, S. Padmanaban, M. S. Bhaskar, F. Blaabjerg, J. B. Holm-Nielsen, F. Azam, and A. K. Sharma, “A hybrid photovoltaic-fuel cell-based single-stage grid integration with Lyapunov control scheme,” IEEE Systems J., vol. 14, no. 3, pp. 3334–3342, 2020. doi: 10.1109/JSYST.2019.2948899
|
| [33] |
D. Bertsimas, D. B. Brown, and C. Caramanis, “Theory and applications of robust optimization,” SIAM Review, vol. 53, no. 3, pp. 464–501, 2011. doi: 10.1137/080734510
|
| [34] |
G. Shani, J. Pineau, and R. Kaplow, “A survey of point-based pomdp solvers,” Autonomous Agents and Multi-Agent Systems, vol. 27, no. 1, pp. 1–51, 2013. doi: 10.1007/s10458-012-9200-2
|
| [35] |
C. Szepesvári, “Algorithms for reinforcement learning,” Synthesis Lectures on Artificial Intelligence and Machine Learning, vol. 4, no. 1, pp. 1–103, 2010.
|
| [36] |
V. Mnih, K. Kavukcuoglu, D. Silver, et al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, 2015. doi: 10.1038/nature14236
|
| [37] |
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” arXiv preprin arXiv: 1509.02971, 2019.
|
| [38] |
J. R. Vázquez-Canteli and Z. Nagy, “Reinforcement learning for demand response: A review of algorithms and modeling techniques,” Applied Energy, vol. 235, pp. 1072–1089, 2019. doi: 10.1016/j.apenergy.2018.11.002
|
| [39] |
R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative-competitive environ- ments,” arXiv preprint arXiv: 1706.02275, 2020.
|
| [40] |
D. W. Ruck, S. K. Rogers, and M. Kabrisky, “Feature selection using a multilayer perceptron,” J. Neural Network Computing, vol. 2, no. 2, pp. 40–48, 1990.
|
| [41] |
H. Tang, R. Houthooft, D. Foote, A. Stooke, X. Chen, Y. Duan, J. Schulman, F. De Turck, and P. Abbeel, “exploration: A study of count-based exploration for deep reinforcement learning,” in Proc. 31st Conf. Neural Information Processing Systems, vol. 30, 2017, pp. 1–18.
|
| [42] |
Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, 2015. doi: 10.1038/nature14539
|
| [43] |
R. Sutton and A. Barto, Reinforcement Learning: An Introduction. Cambridge, USA: MIT Press, 1998.
|
| [44] |
V. Konda and J. Tsitsiklis, “Actor-critic algorithms,” in Proc. 12th Conf.Neural Information Processing Systems, 1999, vol. 12, pp.1008–1014.
|
| [45] |
J. Chorowski, D. Bahdanau, D. Serdyuk, K. Cho, and Y. Bengio, “Attention-based models for speech recognition,” arXiv preprint arXiv: 1506.07503, 2015.
|
| [46] |
T. Rashid, M. Samvelyan, C. Schroeder, G. Farquhar, J. Foerster, and S. Whiteson, “QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning,” in Proc. Int. Conf. Machine Learning, 2018, pp. 4295–4304.
|
| [47] |
H. Wang, T. Huang, X. Liao, H. Abu-Rub, and G. Chen, “Reinforcement learning for constrained energy trading games with incomplete information,” IEEE Trans. Cyber., vol. 47, no. 10, pp. 3404–3416, 2016.
|
| [48] |
T. Kurutach, I. Clavera, Y. Duan, A. Tamar, and P. Abbeel, “Model-ensemble trust-region policy optimization,” arXiv preprint arXiv: 1802.10592, 2018.
|
| [49] |
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv: 1503.02531, 2015.
|
Figures(11) / Tables(5)






 DownLoad:
DownLoad: